
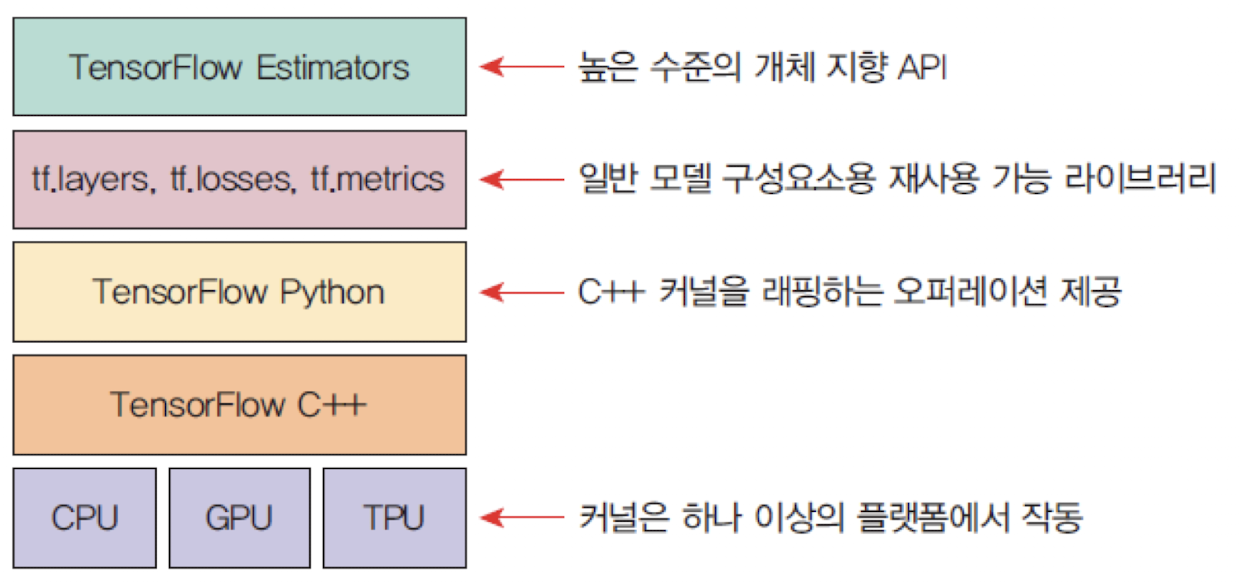
텐서플로우 (Tensorflow)
딥러닝 프레임워크의 일종
- 내부적으로
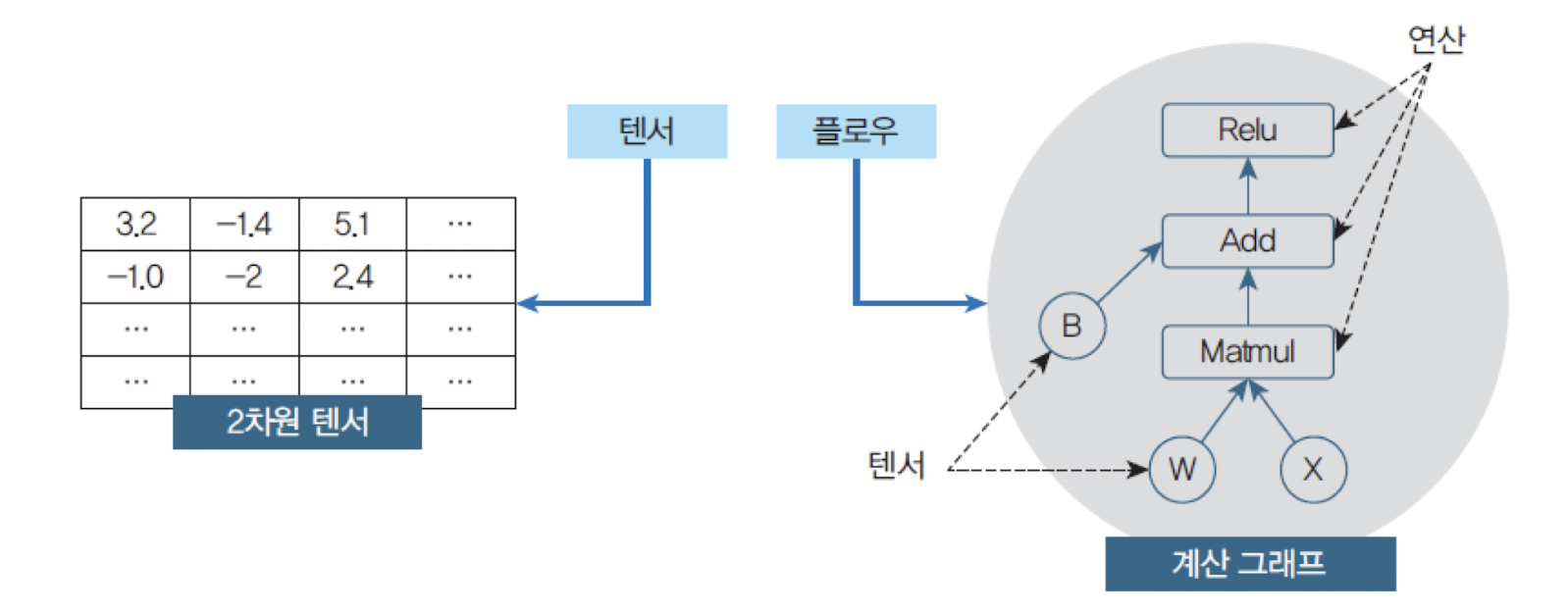
C/C++로 구현되어 있고 파이썬을 비롯하여 여러 가지 언어에서 접근할 수 있도록 인터페이스를 제공한다. - 텐서(Tensor)와 플로우(Flow)가 합쳐진 용어로
텐서는다차원 배열(스칼라, 벡터, 행렬 텐서)을 나타내며플로우는Data Flow의 의미로 유닛들 사이로 텐서들이 흘러다닌다는 뜻이다.
케라스 (Keras)
파이썬으로 작성되었으며, 고수준 딥러닝 API이다.
- 여러 가지 백엔드를 선택할 수 있지만, 가장 많이 선택되는 백엔드는
텐서플로우이다. - 쉽고 빠른 프로토타이핑이 가능하다.
피드포워드 신경망,컨볼루션 신경망과순환 신경망은 물론, 여러 가지의 조합도 지원한다.CPU및GPU에서 원활하게 실행된다.- 케라스는 업계와 학계에서 폭넓게 사용되고 있으며
파이토치(pytorch)는 연구자들이 선호한다.

🔗 케라스로 신경망 작성
- 케라스의 핵심 데이터 구조는
모델(model)이며 레이어를 구성하는 방법을 나타낸다. - 가장 간단한 모델 유형은
Sequential선형 스택 모델이다. Sequential 모델은 레이어를 선형으로 쌓을 수 있는 신경망 모델이다.
📦 code: 케라스로 신경망 작성
# (1) 라이브러리 포함
import numpy as np
import tensorflow as tf
# (2) 입력데이터와 정답 레이블을 준비 (Numpy 배열이나 Python list형식으로 준비)
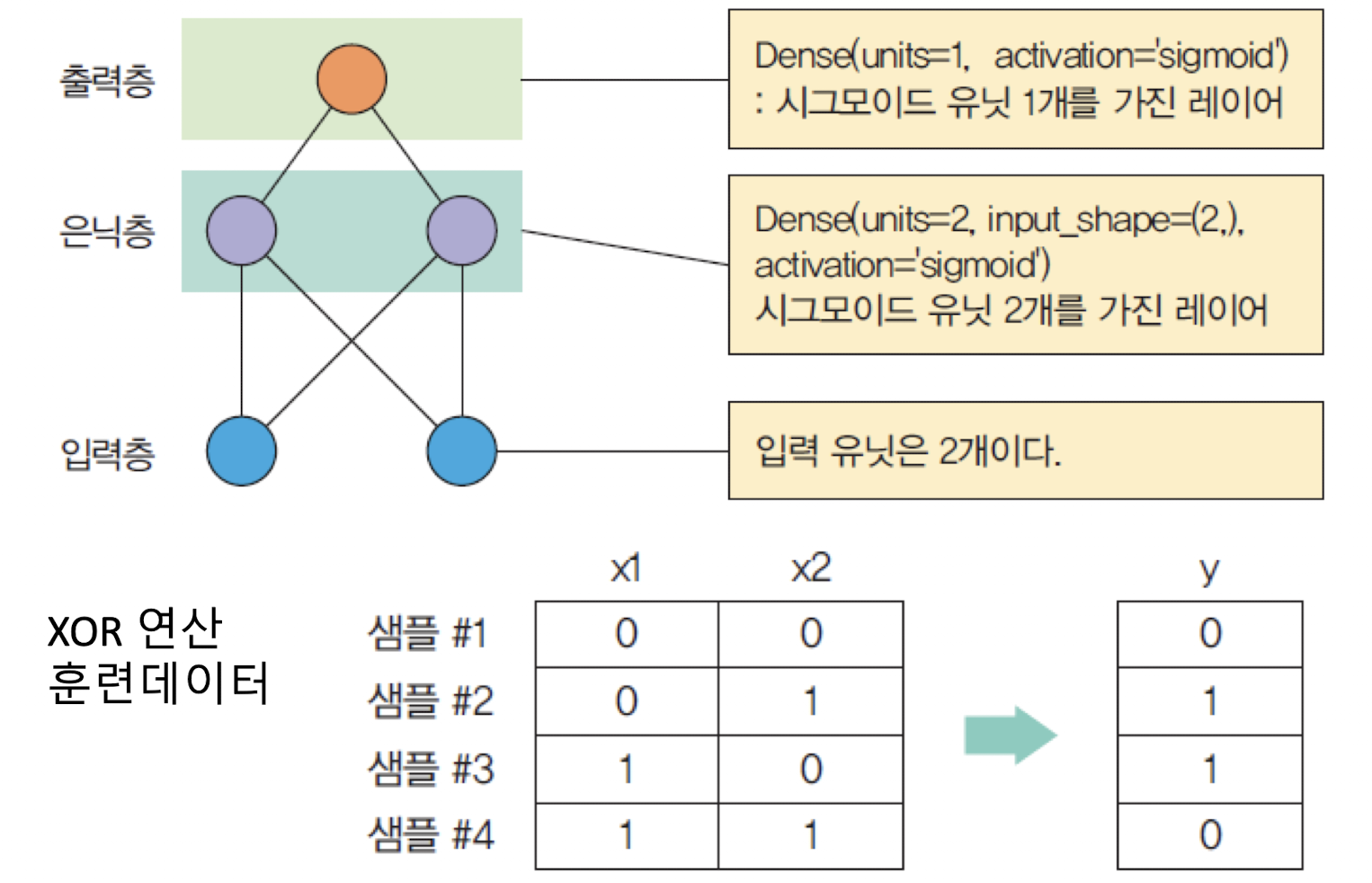
X = np.array([[0,0], [0,1], [1,0], [1,1]]) # XOR 문제의 입력 데이터
y = np.array([[0], [1], [1], [0]]) # XOR 문제의 정답 레이블
# (3) Sequential 모델을 생성
model = tf.keras.models.Sequential()
# (4) Sequential 모델에 add() 함수를 이용하여 필요한 레이어를 추가
model.add(tf.keras.layers.Dense(units=2, input_shape=(2,), activation='sigmoid')) # 첫 번째 은닉층, 2개의 유닛
model.add(tf.keras.layers.Dense(units=1, activation='sigmoid')) # 출력층, 1개의 유닛
# (5) compile() 함수를 호출하여 Sequential 모델을 컴파일
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.SGD(learning_rate=0.3))
# loss function은 MSE, learning rate=0.3
# (6) fit()를 호출하여서 학습을 수행
model.fit(X, y, batch_size=1, epochs=1000) # 배치 크기 1, 에포크 1000번
# (7) predict()를 호출하여 모델을 테스트
print(model.predict(X)) # 예측된 출력 값
# (8) summary()함수로 모델 파라미터 수 점검
print(model.summary()) # 모델 요약 정보 출력
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 2) 6
_________________________________________________________________
dense_1 (Dense) (None, 1) 3
=================================================================
Total params: 9
Trainable params: 9
Non-trainable params: 0
_________________________________________________________________🔍 케라스를 사용하는 3가지 방법
✅ Sequential 모델에 필요한 레이어를 추가하는 방법
model = Sequential()
model.add(Dense(units=2, input_shape=(2,), activation='sigmoid'))
model.add(Dense(units=1, activation='sigmoid'))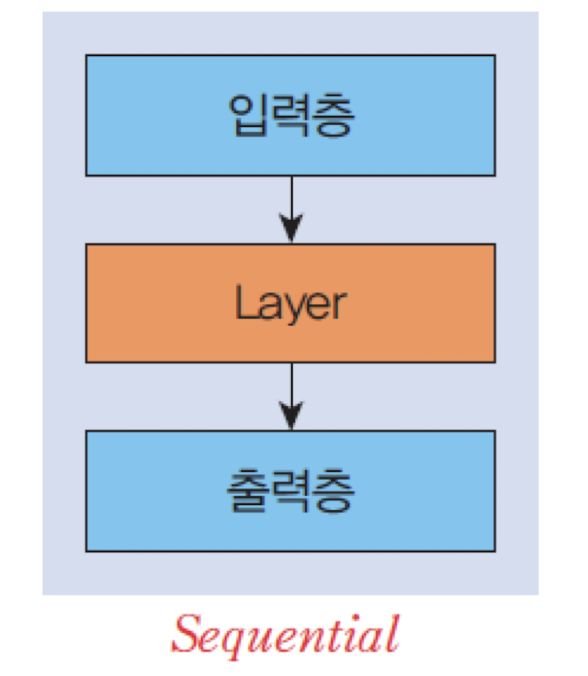
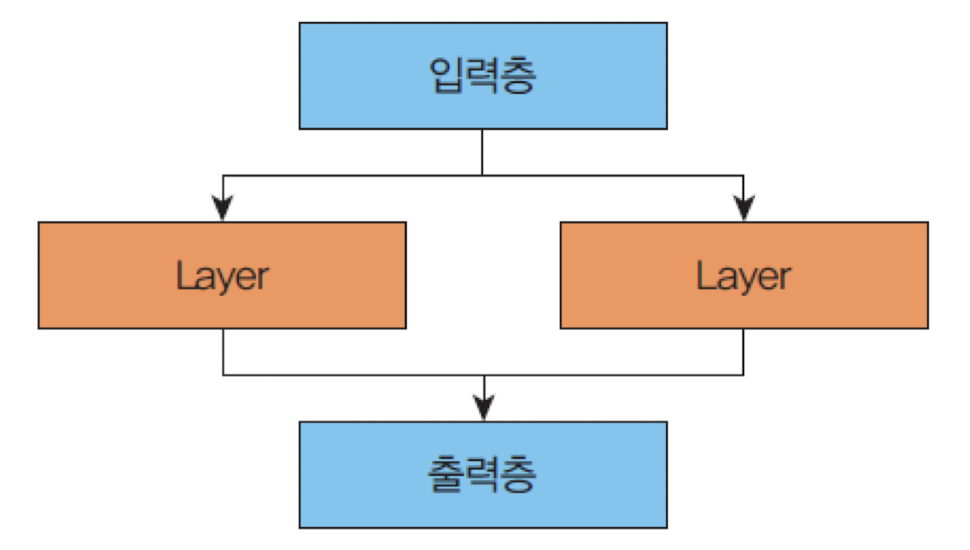
✅ 함수형 API를 사용하는 방법
inputs = Input(shape=(2,)) # 입력층
x = Dense(2, activation="sigmoid")(inputs) # 은닉층
prediction = Dense(1, activation="sigmoid")(x) # 출력층
model = Model(inputs=inputs, outputs=prediction)함수형 API를 사용하면 우리가 원하는 방식으로 객체들을 연결할 수 있으며 레이어가다중 입력이나다중 출력을 가지도록 연결할 수도 있다.
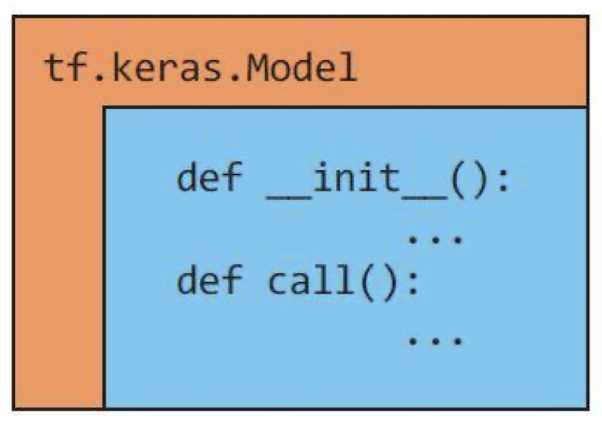
✅ Model 클래스를 상속받아서 각자의 클래스를 정의하는 방법
class SimpleMLP(Model):
def __init__(self, num_classes): # 생성자 작성
super(SimpleMLP, self).__init__(name='mlp')
self.num_classes = num_classes
self.dense1 = Dense(32, activation='sigmoid')
self.dense2 = Dense(num_classes, activation='sigmoid')
def call(self, inputs): # 순방향 호출을 구현한다
x = self.dense1(inputs)
return self.dense2(x)
model = SimpleMLP()
model.compile(...) # 손실함수, 최적화기, 평가지표 등 설정
model.fit(...) # 학습 수행
📦 케라스(Keras)를 이용한 MNIST 숫자 인식
1980년대에 미국의 국립표준 연구소(NIST)에서 수집한 데이터 세트로
6만개의 훈련 이미지와1만개의 테스트 이미지로 이루어져 있다.
MNIST 필기체 숫자 데이터
# 숫자 데이터 가저오기
import matplotlib.pyplot as plt
import tensorflow as tf
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()# numpy 배열 형태 출력
train_images.shape
#(60000, 28, 28)
train_labels
#array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
test_images.shape
#(10000, 28, 28)
plt.imshow(train_images[0], cmap="Greys")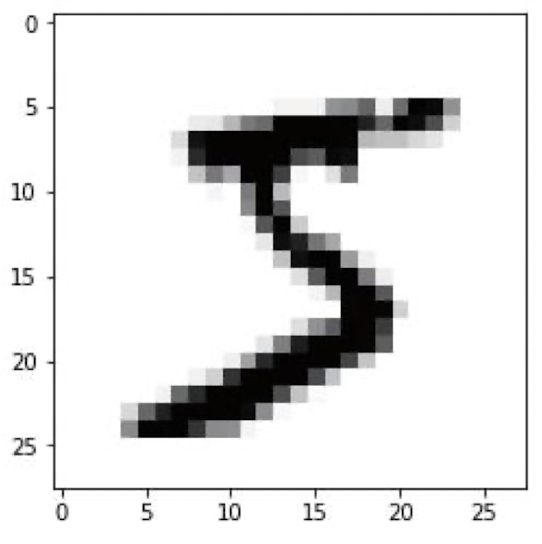
신경망 모델 구축하기
# 신경망 모델 구축
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(512, activation='relu', input_shape=(784,))) # 512 units, input shape 28*28=784
model.add(tf.keras.layers.Dense(10, activation='sigmoid')) # 10 units, sigmoid activation functionmodel.compile(optimizer='rmsprop',loss='mse', metrics=['accuracy'])손실함수(loss function): 신경망의 출력과 정답 간의 오차를 계산하는 함수[mse]옵티마이저(optimizer): 손실 함수를 기반으로 신경망의 파라미터를 최적화하는 알고리즘[rmsprop]지표(metric): 훈련과 테스트 과정에서 사용되는 척도[accuracy]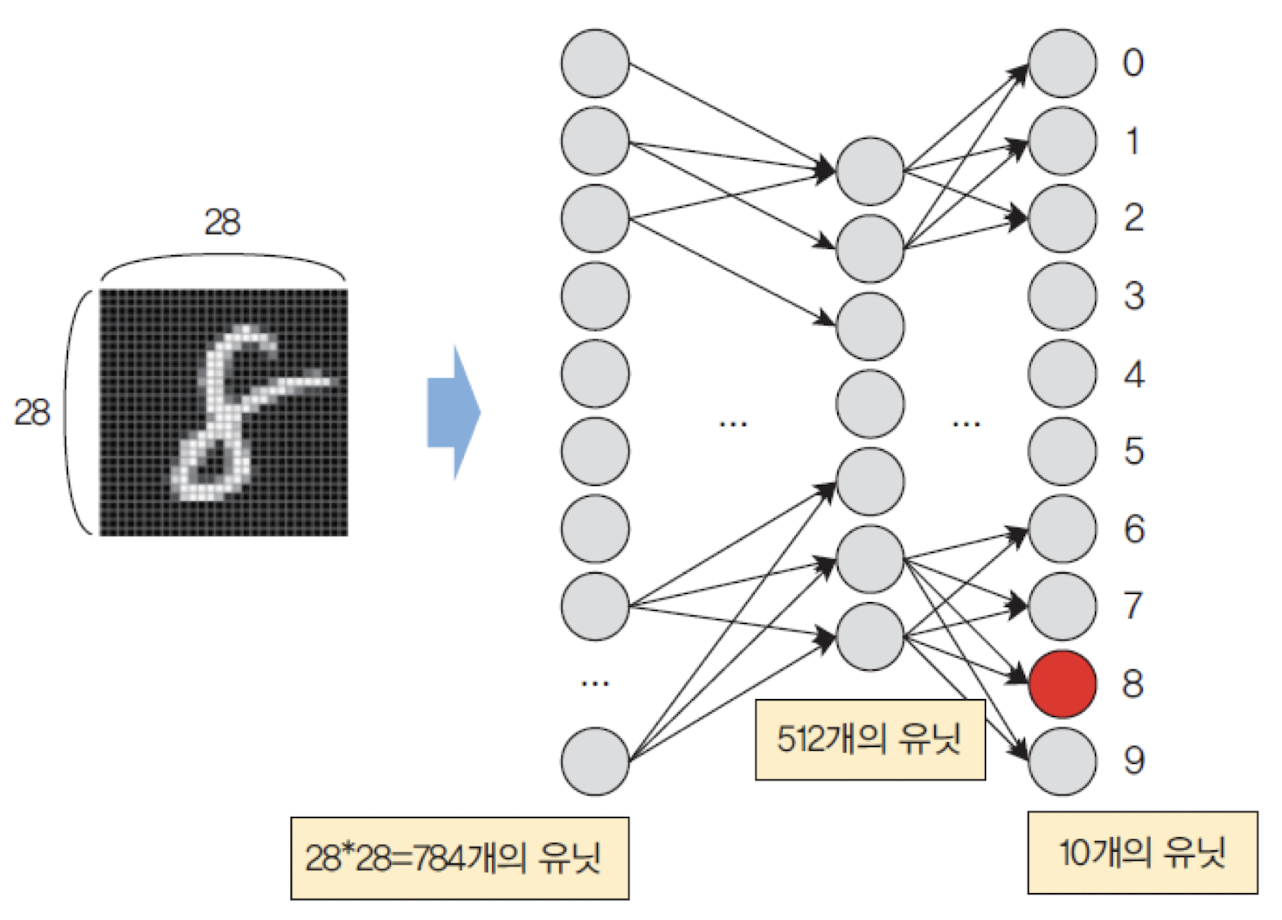
데이터 전처리
# 데이터 전처리
train_images = train_images.reshape((60000, 784))
train_images = train_images.astype('float32') / 255.0
test_images = test_images.reshape((10000, 784))
test_images = test_images.astype('float32') / 255.0
# 정답 레이블 형태 변경(원핫 인코딩)
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# train_labels[0]
# array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)
학습 및 테스트
# 학습
history = model.fit(train_images, train_labels, epochs=5, batch_size=128)Epoch 1/5
469/469 [==============================] - 2s 3ms/step - loss: 0.0158 - accuracy: 0.9168
...
Epoch 5/5
469/469 [==============================] - 2s 3ms/step - loss: 0.0027 - accuracy: 0.9867# 테스트
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('테스트 정확도:', test_acc)313/313 [==============================] - 0s 892us/step - loss: 0.0039 - accuracy: 0.9788
테스트 정확도: 0.9787999987602234그래프 그리기 및 실제 이미지로 테스트 (Google drive)
# 그래프 그리기
loss = history.history['loss']
acc = history.history['accuracy']
epochs = range(1, len(loss)+1)
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, acc, 'r', label='Accuracy')
plt.xlabel('epochs’)
plt.ylabel('loss/acc’)
plt.show()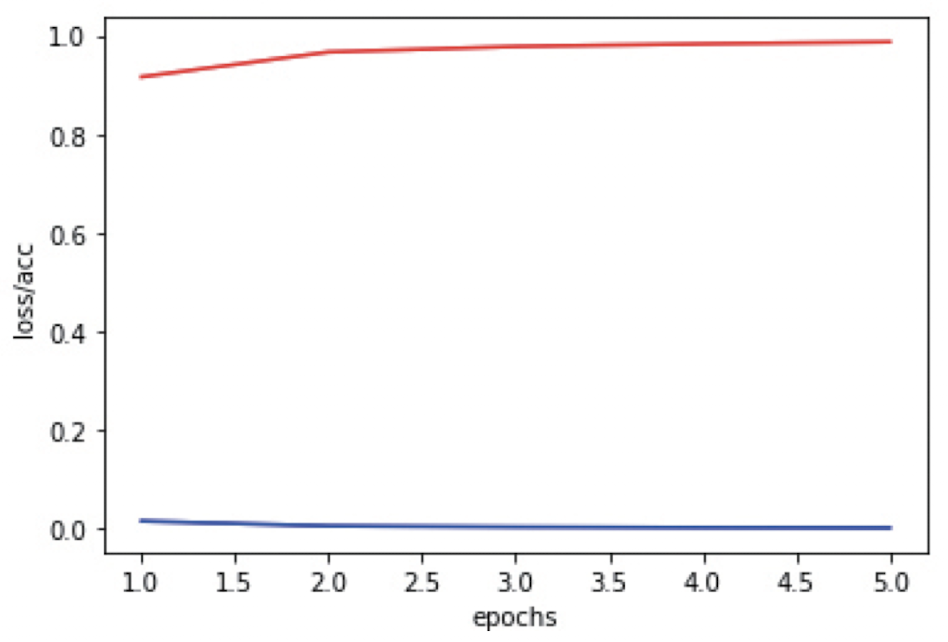
# 실제 이미지로 테스트하기
from google.colab import drive
drive.mount('/content/drive')
# Mounted at /content/drive
import os
print(os.listdir('/content/drive/MyDrive’))
# ['Colab Notebooks', 'Google Form’,…]# 실제 이미지로 테스트하기
import cv2 as cv
image = cv.imread('test.png', cv.IMREAD_GRAYSCALE)
image = cv.resize(image, (28, 28))
image = image.astype('float32')
image = image.reshape(1, 784)
image = 255-image
image /= 255.0
plt.imshow(image.reshape(28, 28),cmap='Greys')
plt.show()
pred = model.predict(image.reshape(1, 784), batch_size=1)
print("추정된 숫자=", pred.argmax())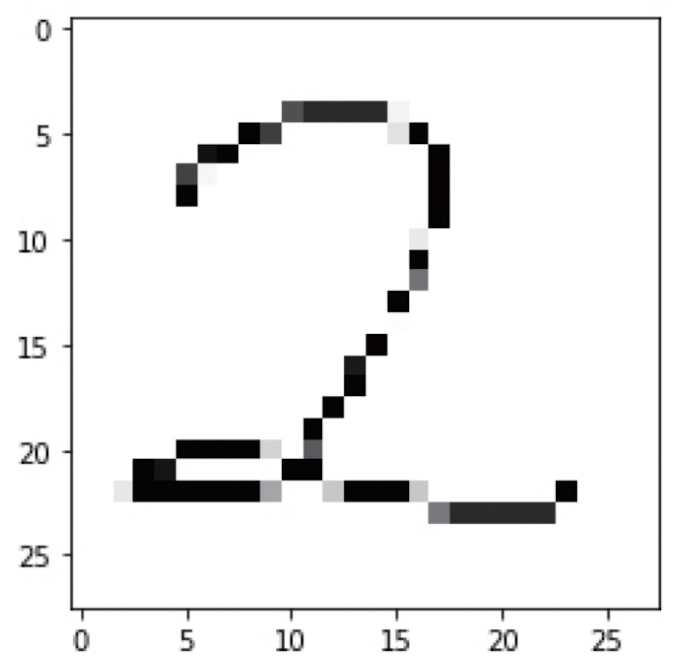
추정된 숫자= 2케라스(Keras)의 데이터, 클래스, 매개변수
케라스의 입력 데이터
넘파이 배열: 메모리에 적제 가능하면 좋은 선택이다.TensorFlow Dataset 객체: 크기가 커서, 메모리에 한 번에 적재될 수 없는 경우에디스크또는분산 파일 시스템에서 스트리밍될 수 있다.파이썬 제너레이터: 예를 들어서keras.utils.Sequence클래스는 하드 디스크에 위치한 파일을 읽어서 순차적으로 케라스 모델로 공급할 수 있다.
💡 텐서(Tensor)
텐서(tensor)는 다차원 넘파이 배열이다.
- 2차원은 행렬(matrix),
3차원 이상을 전통적으로텐서(tensor)라고 불려왔다. - 텐서는 데이터(실수)를 저장하는
컨테이너라고 생각하면 된다. - 텐서에서는 배열의 차원을 축(axis)이라고 부른다.
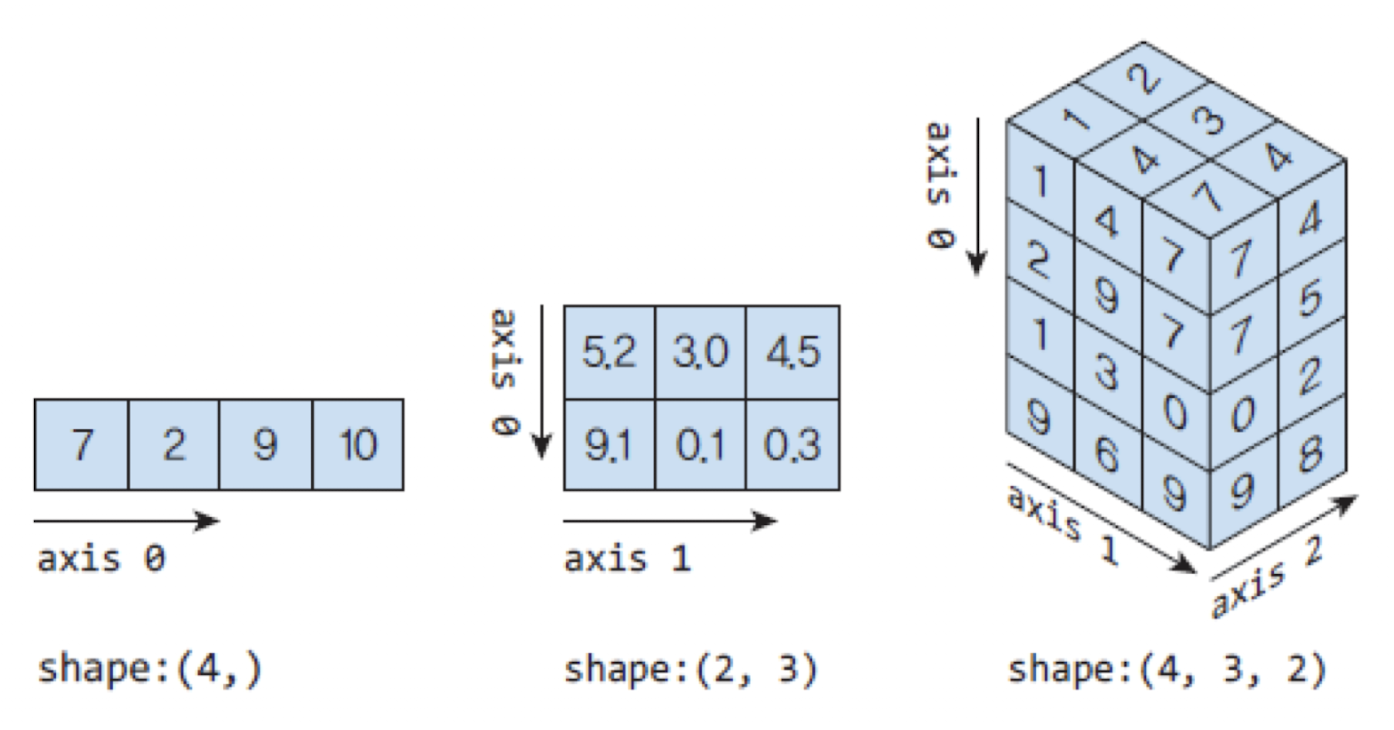
- 예를 들어서 3차원 텐서는 다음과 같이 생성할 수 있다.
텐서(tensor)의 속성
텐서의 차원(축의 개수): 텐서에 존재하는 축의 개수로 3차원 텐서에는 3개의 축이 있다.[x.ndim]형상(shape): 텐서의 각 축으로 얼마나 데이터가 있는지를 파이썬의 튜플로 나타낸 것이다.[x.shape]데이터 타입(data type): 텐서 요소의 자료형[x.dtype]
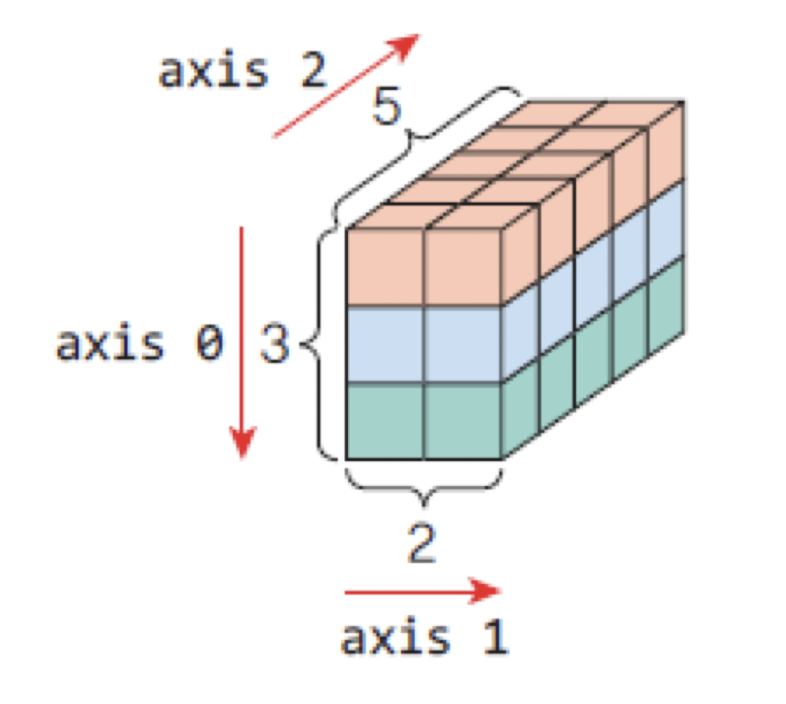
import numpy as np
x = np.array(
[[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]],
[[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]]
)
x.ndim
# 3
x.shape
# (3, 2, 5)
x.dtype
# dtype('int64')
💡 훈련 데이터의 형상
벡터 데이터: (배치 크기, 특징수) 형상의 2차원 넘파이 텐서에 저장된다.
(batch_size, features)=(365,3)
이미지 데이터: (배치 크기, 이미지 높이, 이미지 너비, 채널수) 형상의 4차원 넘파이 텐서에 저장된다
(batch_size, height, width, channels)=c(365,28,28,3)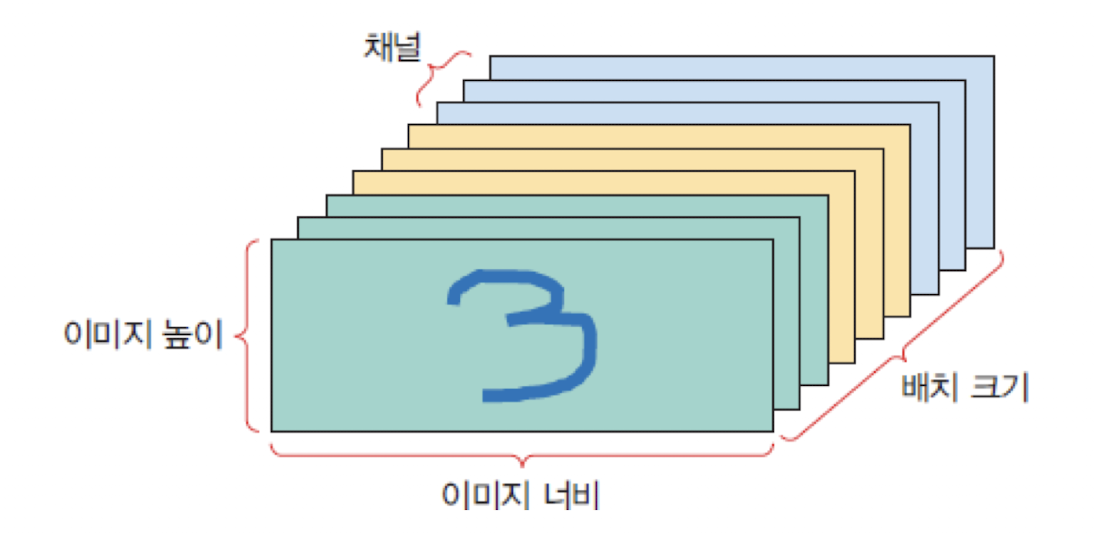
시계열 데이터: (배치 크기, 타입 스텝, 특징수) 형상의 3차원 넘파이 텐서에 저장된다.
(batch_size, timesteps, features)=(365,24,2)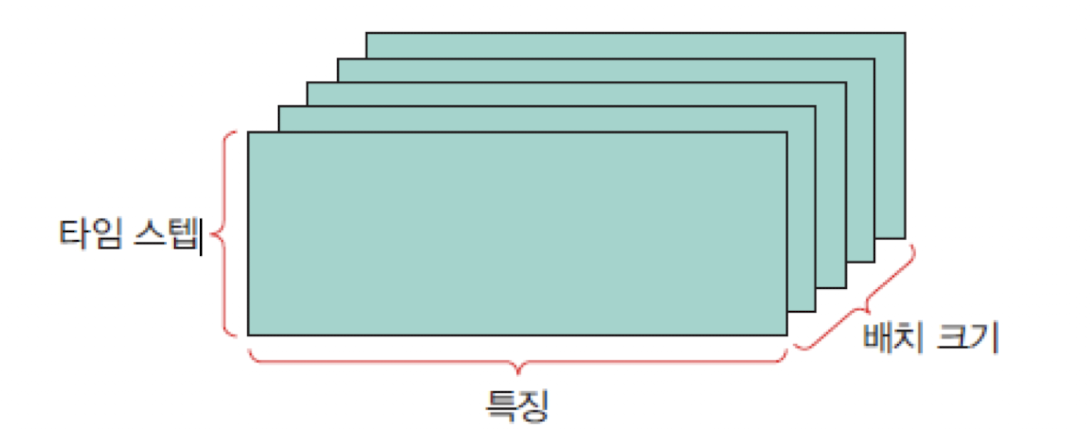
동영상 데이터: (배치 크기, 프레임수, 이미지 높이, 이미지 너비, 채널수) 형상의 5차원 넘파이 텐서에 저장된다.
(batch_size, frame, height, width, channels)=c(365,100,28,28,3)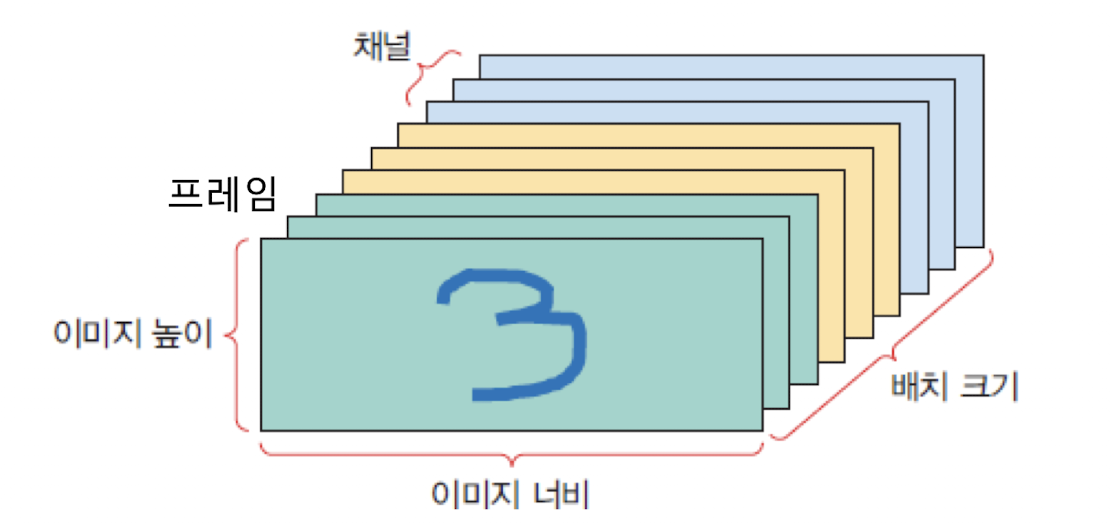
💡 케라스의 클래스
케라스로 신경망을 구축할 때 필요한 요소들:
모델: 하나의 신경망을 나타낸다.레이어: 신경망에서 하나의 층이다.입력 데이터: 텐서플로우 텐서 형식이다.손실 함수: 신경망의출력과정답 레이블간의 차이를 측정하는 함수이다.옵티마이저: 학습을 수행하는 최적화 알고리즘이다.학습률과모멘텀을 동적으로 변경한다
케라스에는 이런 요소들을 구현한 여러 클래스 존재한다.
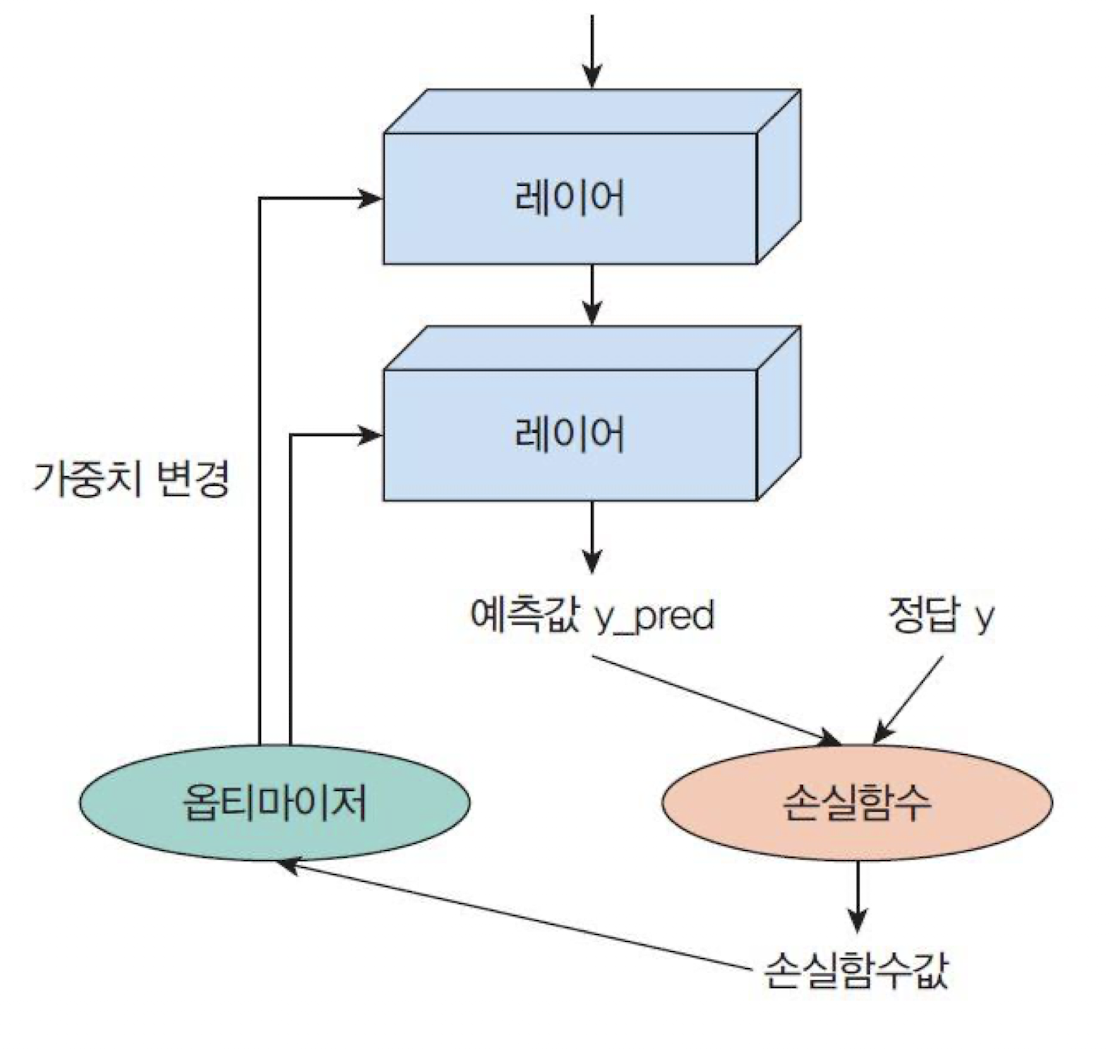
Sequential 모델
입력신호가 한 방향으로만 전달되는 피드 포워드 신경망을 구현하는 가장 기초적인 신경망
✅ compile(optimizer, loss=None, metrics=None): 훈련을 위해서 모델을 구성하는 메소드
- optimizer: 옵티마이저 이름
- loss: 손실함수 이름
- metrics: 성능 측정항목 (ex. metrics=[‘accuracy’])
✅ fit(x=None, y=None, batch_size=None, epochs=1, verbose=1): 훈련 메소드
- batch_size: 가중치 업데이트시 처리하는 샘플 수
- epochs: 데이터 세트 몇 번 반복하는지
✅ evaluate(x=None, y=None): 테스트 모드에서 모델의 손실 함수 값과 측정 항목 값을 반환
✅ predict(x, batch_size=None): 입력 샘플에 대한 예측값을 생성
✅ add(layer): 레이어를 모델에 추가
layer 클래스
✅ Input(shape, batch_size, name): 입력을 받아서 케라스 텐서를 생성하는 객체
✅ Dense(units, activation=None, use_bias=True, input_shape): 유닛들이 전부 연결된 레이어
- use_bias: 바이어스 사용 유무
✅ Embedding(input_dim, output_dim): 자연어 처리의 첫단계에 사용되는 임베딩 레이어
손실 함수(loss function)
✅ MeanSquaredError: 정답 레이블과 예측값 사이의 평균 제곱 오차를 계산한다. [‘mse’]
MeanSquaredError
(1st sample) 1 + 0 = 1
(2nd sample) 1 + 0 = 1
전체 합 = 1 + 1 = 2
전체 요소 수 = 4
MSE = 2 / 4 = 0.5
✅ BinaryCrossentropy: 정답 레이블과 예측 레이블 간의 교차 엔트로피 손실을 계산한다(예를 들어서 강아지, 강아지 아님). [‘binary_crossentropy’]
BinaryCrossentropy
(1) y=0, p=0.6 -> -log(0.4) ≈ 0.916
(2) y=1, p=0.4 -> -log(0.4) ≈ 0.916
(3) y=0, p=0.4 -> -log(0.6) ≈ 0.511
(4) y=0, p=0.6 -> -log(0.4) ≈ 0.916
총합 = 3.259 / 4 = 0.8149
import matplotlib.pyplot as plt
import tensorflow as tf; import numpy as np
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
mse = tf.keras.losses.MeanSquaredError()
print(mse(y_true, y_pred).numpy()) # 0.5
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
bce = tf.keras.losses.BinaryCrossentropy()
print(bce(y_true, y_pred).numpy()) # 0.8149245✅ CategoricalCrossentropy: 정답 레이블과 예측 레이블 간의 교차 엔트로피 손실을 계산한다(예를 들어서 강아지, 고양이, 호랑이). 정답 레이블은 원핫 인코딩으로 제공 [‘categorical_crossentropy’]
CategoricalCrossentropy
(1st sample) y = [0,1,0], p = [0.05, 0.95, 0]
--> -log(0.95) ≈ 0.051
(2nd sample) y = [0,0,1], p = [0.1, 0.8, 0.1]
--> -log(0.1) ≈ 2.302
총합 = 0.051 + 2.302 = 2.353 / 2 = 1.1769
✅ SparseCategoricalCrossentropy: 정답 레이블과 예측 레이블 간의 교차 엔트로피 손실을 계산한다. (예를 들어서 강아지, 고양이, 호랑이)
정답 레이블은 정수로 제공 [‘sparse_categorical_crossentropy’]
SparseCategoricalCrossentropy
(1st sample) y=1 → p=0.95 → -log(0.95) ≈ 0.051
(2nd sample) y=2 → p=0.1 → -log(0.1) ≈ 2.302
평균 = (0.051 + 2.302) / 2 = 1.1769
y_true = [[0, 1, 0], [0, 0, 1]] # 원-핫 표현으로 부류를 나타낸다.
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
cce = tf.keras.losses.CategoricalCrossentropy()
print(cce(y_true, y_pred).numpy()) # 1.1769392
y_true = np.array([1, 2]) # 정수로 부류를 나타낸다.
y_pred = np.array([[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
scce = tf.keras.losses.SparseCategoricalCrossentropy()
print(scce(y_true, y_pred).numpy()) # 1.1769392측정 항목(metrics)
Accuracy: 정확도이다. 예측값이 정답 레이블과 같은 횟수를 계산한다.categorical_accuracy: 범주형 정확도이다. 신경망의 예측값이 원-핫 레이블과 일치하는 빈도를 계산한다.
m = tf.keras.metrics.Accuracy()
m.update_state( [[1], [2], [3], [4]], [[0], [2], [3], [4]])
print(m.result().numpy()) # 0.75
m = tf.keras.metrics.CategoricalAccuracy()
m.update_state([[0, 0, 1], [0, 1, 0]], [[0.1, 0.9, 0.8], [0.05, 0.95, 0]])
print(m.result().numpy()) # 0.5옵티마이저(optimizer)
손실 함수를 미분하여서 가중치를 변경하는 변경하는 객체
SGD: 확률적 경사 하강법(Stochastic Gradient Descent, SGD), Nesterov 모멘텀을 지원, 얕은 신경망 적합
opt = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9)Adagrad: 가변 학습률을 사용하는 방법, SGD를 진보시킨 최적화 방법Adadelta: 모멘텀을 이용하여 감소하는 학습률 문제를 처리하는 Adagrad의 변형RMSprop: Adagrad에 대한 수정판Adam: 기본적으로 (RMSprop + 모멘텀), 인기있음
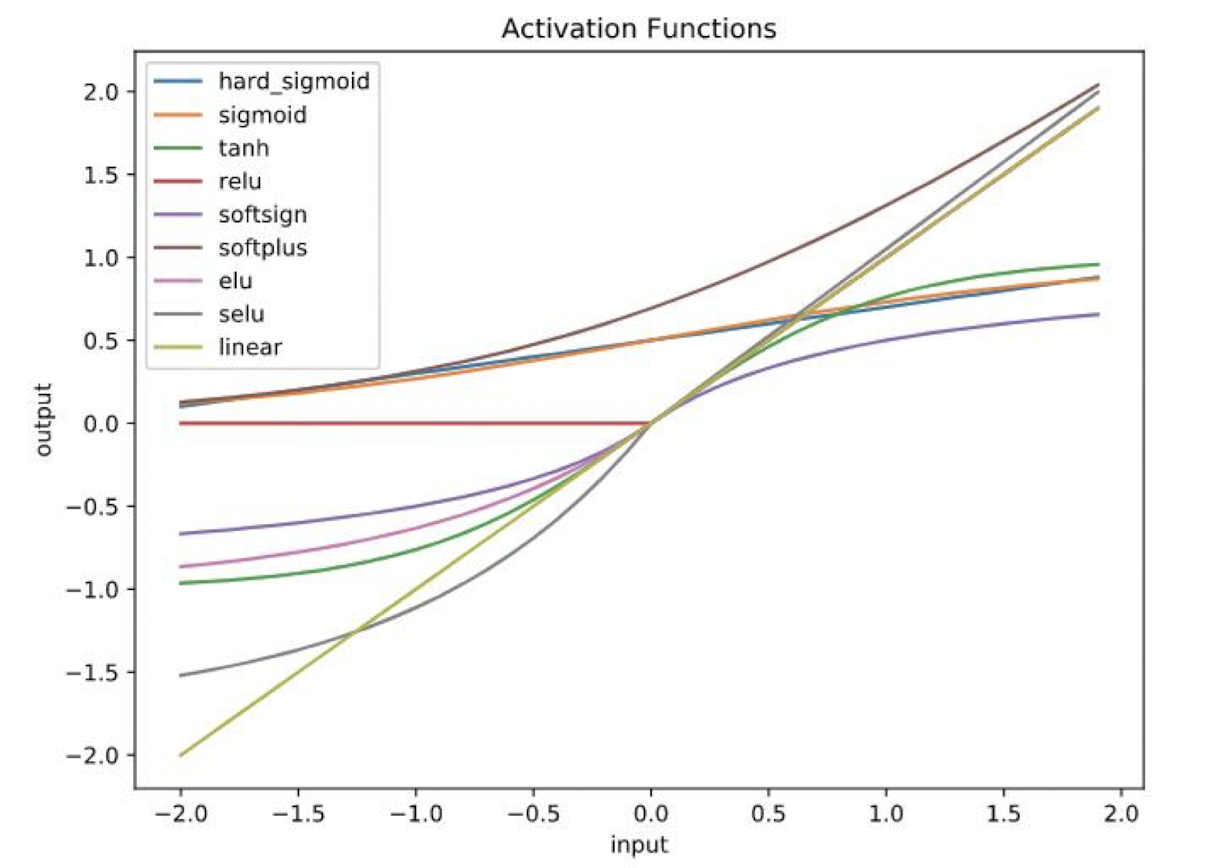
활성화 함수(activation function)
sigmoidrelu(Rectified Linear Unit)softmaxtanhselu(Scaled Exponential Linear Unit)softplus
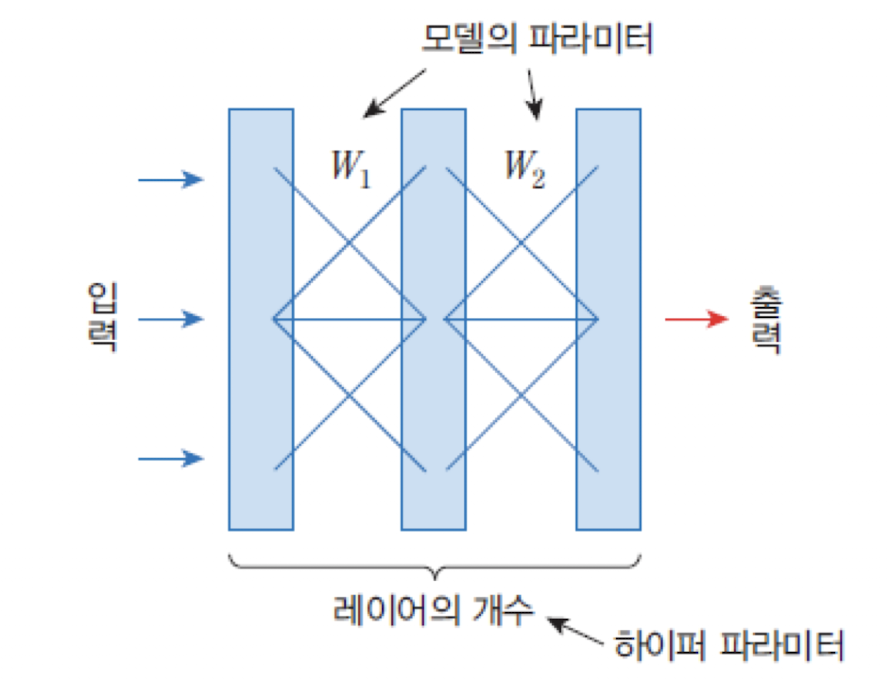
💡 하이퍼 매개변수
신경망에서 학습 전에 사용자가 직접 설정해야 하는 값들을 하이퍼파라미터라고 한다.
이 값들은 모델의 성능과 학습 효율에 큰 영향을 미친다.
대표적인 하이퍼파라미터
| 하이퍼파라미터 | 설명 |
|---|---|
| 은닉층의 개수 | 오차가 더 이상 개선되지 않을 때까지 레이어를 추가한다. |
| 유닛의 개수 | 유닛 수가 많을수록 표현력이 좋아지지만 과적합에 주의해야 한다. |
| 학습률 (learning rate) | 너무 크면 발산하고, 너무 작으면 학습이 느리다. 적응적 학습률이 효과적이다. |
| 모멘텀 (momentum) | 진동을 방지하여 안정적인 학습을 도와준다. 보통 0.5~0.9 사이의 값을 사용한다. |
| 미니 배치 크기 | 일반적으로 32를 기본으로, 64, 128, 256 등도 사용된다. |
| 에포크 수 (epochs) | 검증 정확도가 감소하기 시작할 때까지 반복한다. |
🔍 하이퍼파라미터 탐색 방법
-
기본값 사용
프레임워크(예: Keras, sklearn)에서 제공하는 기본값을 그대로 사용한다. -
수동 검색
사용자가 직접 값을 지정하면서 경험적으로 조정한다. -
그리드 검색(Grid Search)
각 하이퍼파라미터에 대해 여러 개의 후보 값을 정하고, 모든 조합을 실험하여 가장 성능이 좋은 조합을 찾는다.
sklearn의 GridSearchCV를 통해 손쉽게 구현할 수 있다.
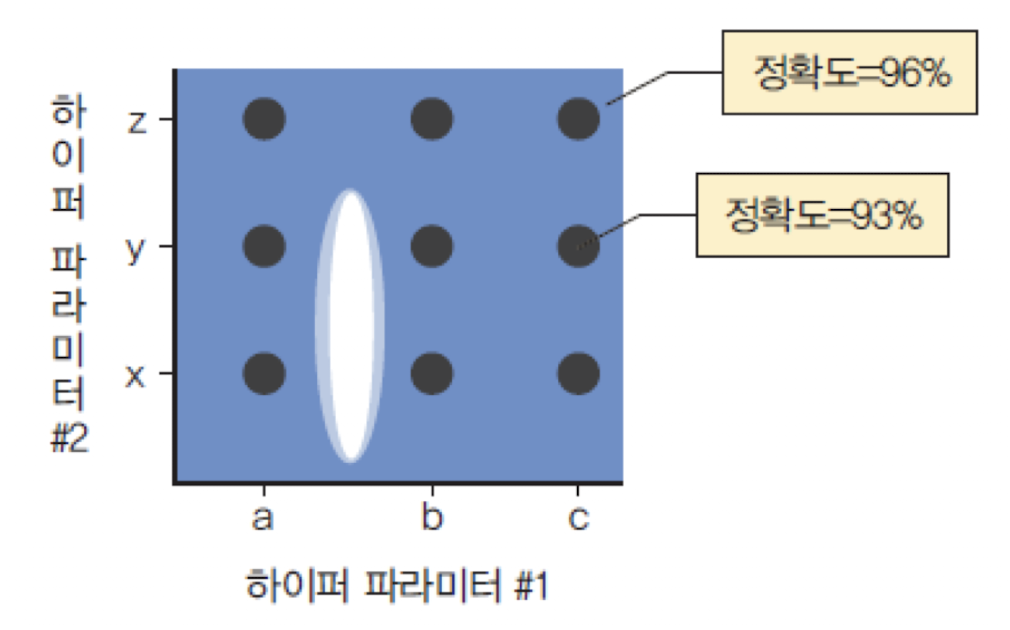
랜덤 검색(Random Search)
하이퍼파라미터 값을 무작위로 선택하여 여러 조합을 실험한다.
그리드 검색보다 빠르고 효율적일 수 있다.
📦 그리드 검색 예제
# 라이브러리 로드
# !pip install scikeras
# !pip install scikit-learn==1.3.2
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.model_selection import GridSearchCV
from scikeras.wrappers import KerasClassifier
# 데이터 세트 준비
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)# 신경망 모델 구축
def build_model():
network = tf.keras.models.Sequential()
network.add(tf.keras.layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(tf.keras.layers.Dense(10, activation='sigmoid'))
network.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']
)
return network
# 하이퍼 매개변수 딕셔너리
param_grid = {
'epochs': [1, 2, 3], # 에포크 수: 1, 2, 3
'batch_size': [32, 64] # 배치 크기: 32, 64
}
# 케라스 모델을 sklearn에서 사용하도록 포장한다.
model = KerasClassifier(build_fn=build_model, verbose=1)
# 그리드 검색
gs = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=3,
n_jobs=-1
)
# 그리드 검색 결과 출력
grid_result = gs.fit(train_images, train_labels)
print(grid_result.best_score_)
print(grid_result.best_params_)
...
Epoch 3/3
938/938 [==============================] - 3s 4ms/step - loss: 0.0664 - accuracy: 0.9799
157/157 [==============================] - 0s 939us/step
0.968666672706604
{'batch_size': 64, 'epochs': 3}🏷️ Summary
케라스를 활용한 신경망 모델 구성과 하이퍼파라미터
Sequential 모델은 케라스에서 가장 간단한 신경망 구성 방식이며, Dense 레이어를 통해 완전 연결 구조를 만든다.
하이퍼파라미터는 은닉층 수, 유닛 수, 학습률 등 모델 외부에서 개발자가 설정하는 값이며, 그리드 검색 등을 통해 최적값을 탐색할 수 있다.
