👩🔬 이번에는 혼공머 책의 챕터 4-2 파트입니다.
참고 자료
📚 혼자공부하는머신러닝+딥러닝, 한빛미디어
🔗 서포트 벡터머신, SVM - (2)
이번 단원에서 나오는 키워드
- 확률적 경사 하강법(SGD)
- 미니배치 경사 하강법(Minibatch gradient descent)
- 배치 경사하강법(Batch gradient descent)
- 손실 함수(loss function)
- 로지스틱 손실함수(logistic loss function)
- 크로스 엔트로피 손실함수(cross entropy loss function)
- 조기 종료(early stopping)
- 힌지 손실(hinge loss)
- 서포트 벡터 머신(support vector machine)
우와! 차라리 죽여줘!🥺
저번 게시글에서는 경사 하강법🗻에 대해 정리하였습니다.
이번 게시글에서는 손실함수부터 다뤄보도록 하겠습니다.
손실함수에 대해 더 자세히 알고 싶다고 하시는 분은 손실 함수(loss function) 정의 - MAE, MSE, MLE 글을 참고해보시면 좋겠습니다.
손실 함수(loss function)
손실 함수(loss function)은 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수입니다.
더 쉽게 말하면, 손실 함수는 실제값과 예측값의 차이(loss, cost)를 수치화해주는 함수입니다.
자연스럽게 클수록 손실 함수의 값이 크고, 오차가 작을수록 손실 함수의 값이 작아집니다.
어쨌든 손실 함수의 값을 최소화 하는 W, b를 찾아가는것이 학습 목표입니다.
회귀의 경우에는 평균 제곱 오차(mean square error)를 사용하고, 분류의 경우에는 크로스 엔트로피를 사용합니다.
이진 분류: logistic loss function, binart cross entropy loss function다중 분류: 크로스엔트로피 손실 함수
보충 설명
다범주 분류 문제를 풀기 위한 딥러닝 모델 출력에 소프트맥스 함수가 적용됩니다.
소프트맥스 함수는 범주 수만큼의 차원을 갖는 입력 벡터를 받아서 확률(요소의 합이 1)로 변환해 주는 역할입니다.
이후 손실 함수로는 크로스엔트로피(cross entropy)가 쓰입니다.
크로스 엔트로피는 소프트맥스 확률의 분포와 정답 분포와의 차이를 나타냅니다.
이를 기본으로 손실(오차)을 최소화하는 방향으로 모델의 각 파라메터를 업데이트하는 과정이 바로 딥러닝 모델의 학습 과정입니다.
*설명 출처:https://ratsgo.github.io/deep%20learning/2017/10/02/softmax
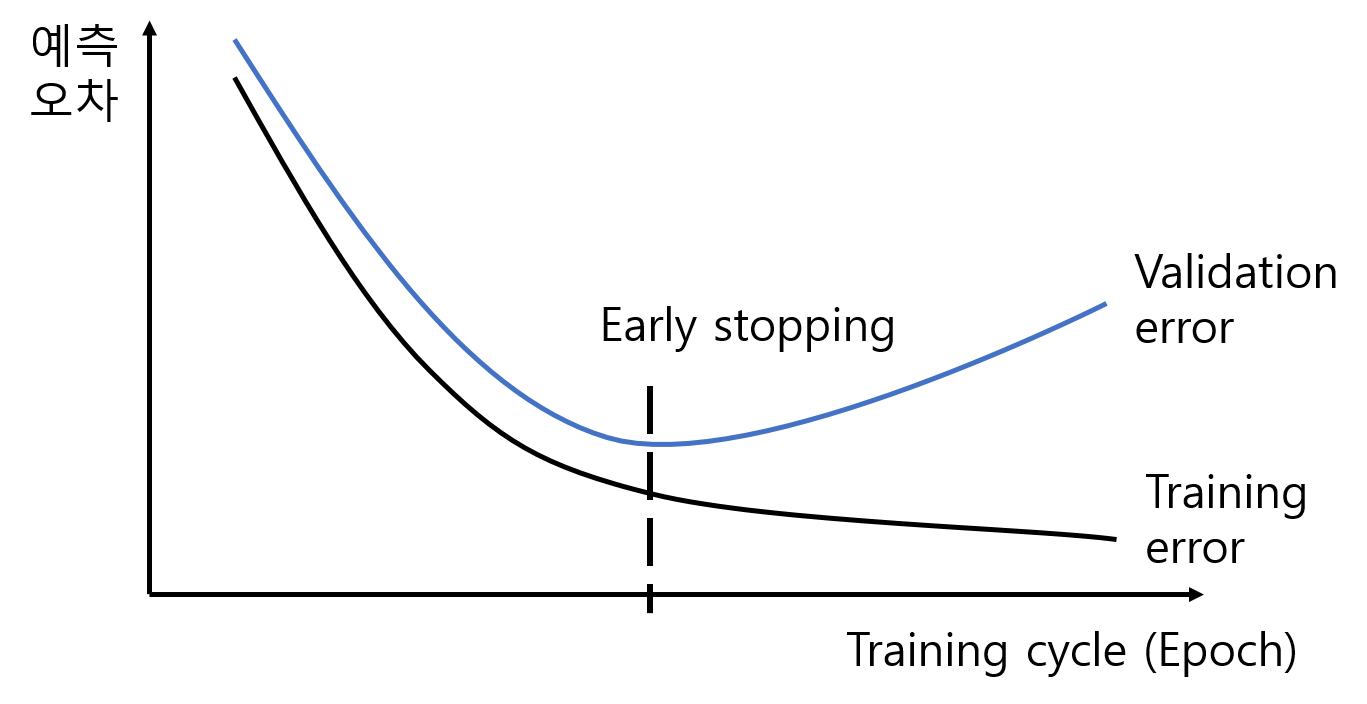
조기 종료(early stopping)
조기 종료(early stopping)의 개념은 과대 적합이 시작하기 전 훈련을 멈추는 것을 의미합니다.
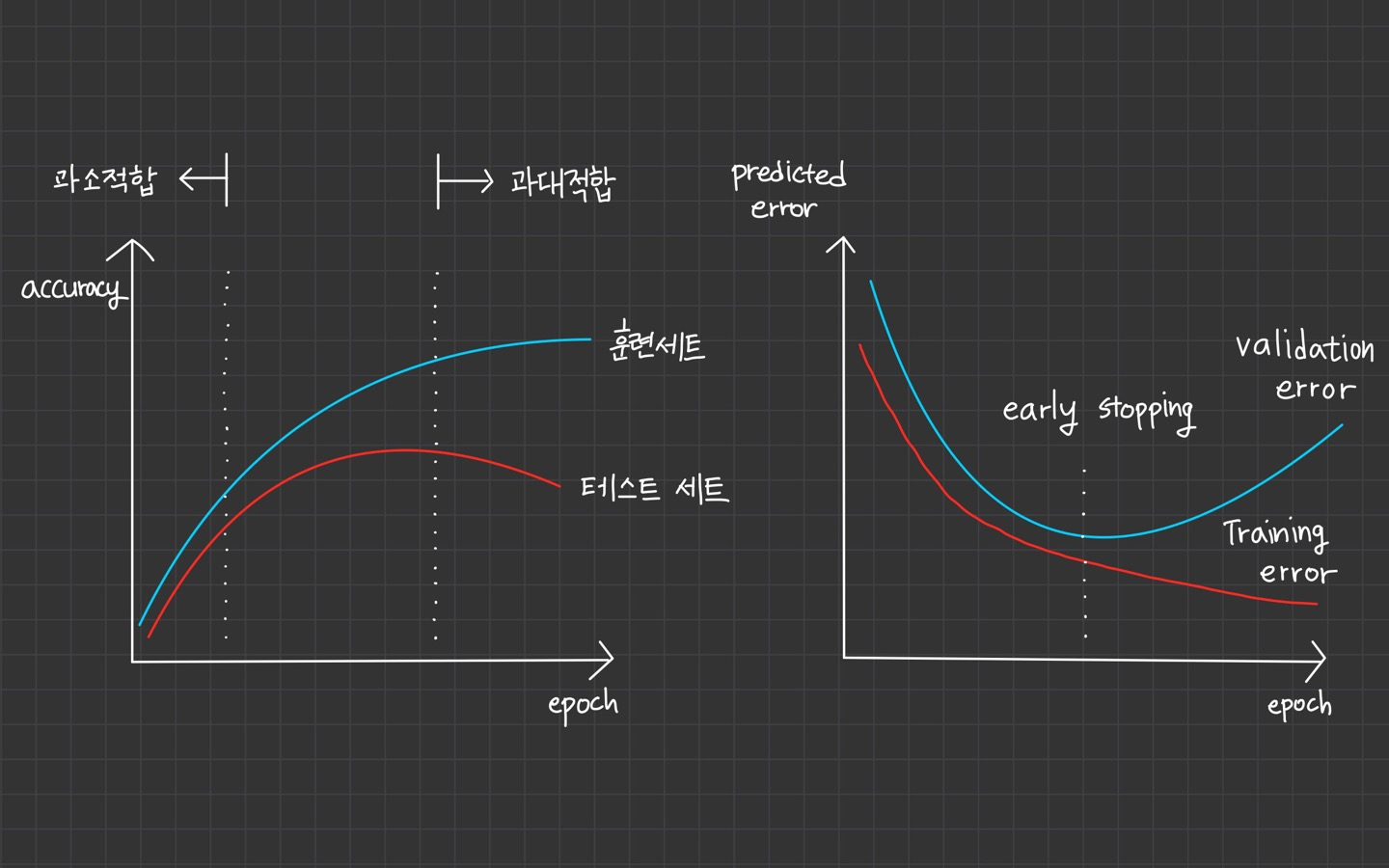
과소 적합, 과대 적합을 기준으로
훈련 세트와 테스트 점수가 낮은 부분이 과소 적합이고, 훈련 세트의 점수는 높아지나 테스트 점수가 떨어지는 지점을 과대 적합이라 봅니다.
오른쪽 그래프의 경우는 training error는 계속 떨어지지만, validation error가 높아지는 지점에서 과대 적합이 일어난다고 볼 수 있기 때문에 early stopping 지점이 됩니다.
hinge loss
hinge loss는 서포트 벡터 머신(SVM, support vector machine) 알고리즘을 위한 손실 함수입니다.
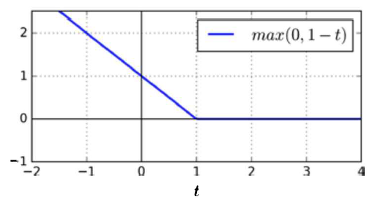
max 0, 1-t의 형태를 갖고 있습니다.
cs231의 lecture 3 slide에도 나오는데

라고 하네요.
example 가 주어졌을 때, 는 이미지이고 가 label일 때, score vector를 위해 사용한다고 합니다.
SVM loss는 그래서
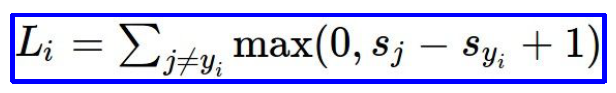
이렇게 식으로 나타내집니다.
SVM과 loss에 대한 건 cs231을 공부하며 한 번 더 정리할까 합니다.
혼공머 책 같은 경우엔 SVM이 널리 쓰이는 머신러닝 알고리즘 중 하나라는 점과 여러 종류의 손실 함수를 loss 매개변수에 지정하여 다양한 머신러닝 알고리즘을 지원해준다는 점을 언급하고 있습니다.
여기서 hinge loss가 loss 매개변수 기본값이라고 합니다.
정리
확률적 경사 하강법은 손실 함수라는 산을 정의하고 가장 가파른 경사를 따라 조금씩 내려오는 알고리즘이었습니다.
충분히 반복 훈련하면 훈련 세트에서 높은 점수를 얻는 모델을 만들 수 있습니다.
하지만 훈련을 반복할수록 모델이 훈련 세트에만 높은 점수를 얻는 과대 적합 현상이 일어날 수 있으며, 테스트 정확도는 떨어질 수 있습니다.
여기서 과대 적합 전 학습을 멈춰주는 조기 종료(early stopping) 개념이 나왔고, 반복한다는 것은 훈련 세트를 한 번 모두 사용하는 과정 epoch를 여러 번 한다는 것의 의미입니다.
4장까지 회귀와 분류에 사용되는 알고리즘을 배웠습니다.
최근접 이웃(K-NN) 알고리즘, 선형 회귀(linear regression), 릿지(Ridge), 라쏘(lasso), 로지스틱 회귀(logistic regression), 확률적 경사 하강법(SGD) 등이 있었습니다.
어쩜 공부할 수록 공부할게 계속 늘죠? 당황스럽네요;;; ^^ 오늘도 수고하셨습니다.
