해당 포스팅은 이기창님의 📒 '한국어 임베딩' 책을 바탕으로 개념을 정리합니다.
따라서 책에서 정의 내리고 쓰는 용어가 기준이므로 기존 용어와 살짝 다른 부분이 있을 수도 있습니다. (없을 것 같긴 하지만요)

이기창님의 관련 자료
목차
임베딩(Imbedding)이란?
만약 컴퓨터가 인간을 속여 자신을 마치 인간인 것처럼 믿게 할 수 있다면 컴퓨터를 '인텔리전트'하다고 부를 만한 가치가 충분히 있다. - 앨런 튜링*Alan Maathison Turing,. 1912~1954)
인간이 사용하는 언어를 자연어(Natural language)라고 합니다.
컴퓨터는 이를 이해하기 위해 숫자로 변형된 말이나 글을 통해 계산합니다. 기계의 자연어 이해와 생성은 연산(computation)이나 처리(processing)의 영역입니다.
자연어 처리(Natural Language Processing) 분야에서 임베딩(Imbedding)이란 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과와 그 일련의 과정을 일컫습니다.
단어나 문장 각각을 벡터로 변환해 벡터 공간(Vector space)으로 끼워넣는다는 의미에서 임베딩이라고 합니다.
가장 간단한 형태의 임베딩은 단어의 빈도를 기준으로 벡터로 변환하는 것입니다.
| 구분 | 메밀꽃 필 무렵 | 운수 좋은 날 | 사랑 손님과 어머니 | 삼포 가는 길 |
|---|---|---|---|---|
| 기차 | 0 | 2 | 10 | 7 |
| 막걸리 | 0 | 1 | 0 | 0 |
| 선술집 | 0 | 1 | 0 | 0 |
<표 1-1>
위와 같은 표를 단어-문서 행렬(Document-Term Matrix)라고 부릅니다.
행(row): 단어열(column): 문장
으로 이루어져 있고, 오픈소스 mecab을 사용하여 명사(noun)를 추출해 계산했습니다.
<표 1-1>을 살펴보면 운수 좋은 날이라는 문서의 임베딩은 입니다.
막걸리라는 단어의 임베딩은 입니다.
표를 살펴보면, '사랑 손님과 어머니'의 작품과 '삼포 가는 길'의 작품의 단어 목록 중 '기차'라는 소재를 공유하고 겹친다는 것을 볼 수 있습니다.
또 '막걸리'와 '선술집'이란 단어는 '운수 좋은 날'에만 나온 것으로 확인됩니다.
이러한 결과를 바탕으로 '막걸리'-'선술집'의 의미 차이는 '막걸리'-'기차'보다 작을 것이라 추측합니다.
임베딩의 역할
임베딩의 역할을 3가지로 요약할 수 있습니다.
- 단어/문장 간 관련도 계산
- 의미적/문법적 정보 함축
- 전이 학습
1. 단어/문장 간 관련도 계산
위에서 살펴본 단어-문서 행렬은 가장 단순한 형태의 임베딩입니다.
현업에서는 더 복잡한 형태의 임베딩을 사용합니다. 2013년에 구글에서 발표한 Word2Vec이라는 기법이 있습니다.
Mecab을 통해 형태소 분석을 한 뒤 100차원으로 학습한 Word2Vec임베딩을 살펴봅니다.
- '희망'의 Word2Vec의 임베딩
[-0.00209, -0.03918, 0.02419, ... 0.01715, -0.04975, -0.09300]
위 수식은 100차원으로 임베딩하였으므로 모두 100개의 숫자입니다.
단어를 벡터로 임베딩하면 단어 벡터들 사이의 유사도(Similarity)를 계산하는 일이 가능합니다.
각 쿼리 단어별로 벡터 간 유사도 측정 기법의 일종인 코사인 유사도(Cosine similarity)를 계산합니다.
| 희망 | 절망 | 학교 | 학생 |
|---|---|---|---|
| 소망 | 체념 | 초등 | 대학생 |
| 희망찬 | 절망감 | 중학교 | 대학원생 |
| 꿈 | 상실감 | 야학교 | 교직원 |
| 열망 | 번민 | 중학 | 학부모 |
'희망'과 코사인 유사도가 가장 높은 것은 '소망'이라는 단어입니다.
마찬가지로 '절망'은 '체념', '학교'는 '초등', '학생'은 '대학생'입니다.
자연어일 때는 불가능한 코사인 유사도 개념이 임베딩 과정 후에 가능해졌습니다.
Word2Vec 임베딩을 가지고 코사인 유사도를 구해볼 수 있으며, 이를 시각화할 수 있습니다.
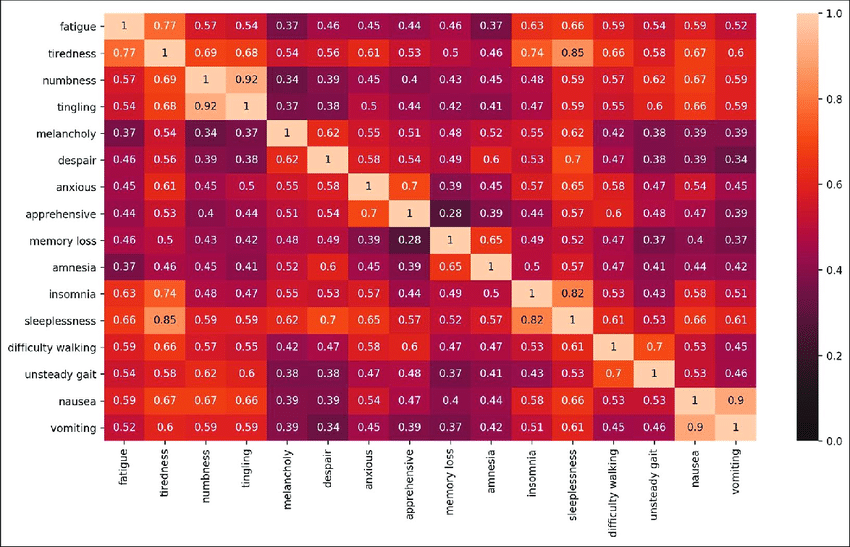
- 위 표와는 다른 예시 이미지입니다.
- 색이 더 진할 수록 코사인 유사도가 높다고 생각할 수 있습니다.
임베딩을 수행하면 벡터 공간을 기하학적으로 나타낸 시각화 역시 가능하며, t-SNE라는 차원 축소(dimension reduction) 기법으로 100차원의 단어 벡터를 2차원으로 줄여 시각화 가능합니다.
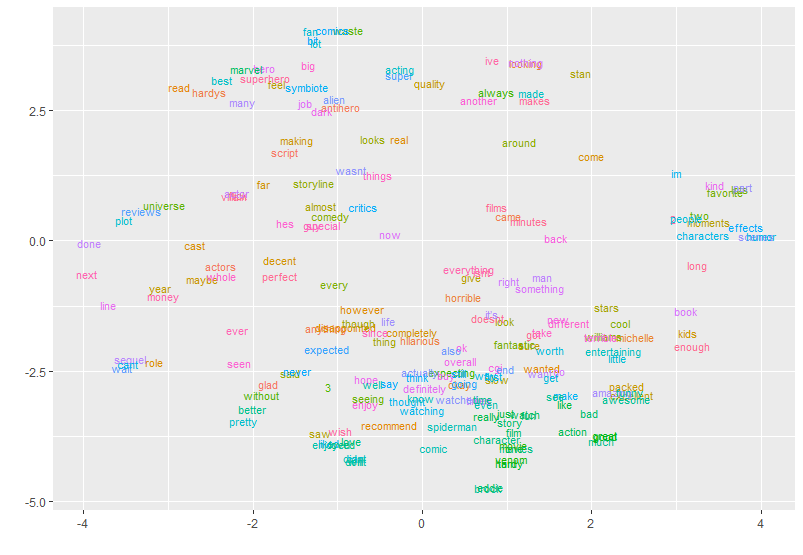
- 위 표와는 다른 예시 이미지입니다.
- 관련성이 높은 단어들이 주변에 몰려 있습니다.
2. 의미적/문법적 정보 함축
임베딩은 벡터이기 때문에 사칙연산이 가능합니다. 이 의미는 단어들 사이의 의미적, 문법적 관계를 도출할 수 있다는 뜻입니다.
첫 번째 단어 벡터-두번째 단어 벡터+세 번째 단어 벡터를 계산해 보겠습니다.
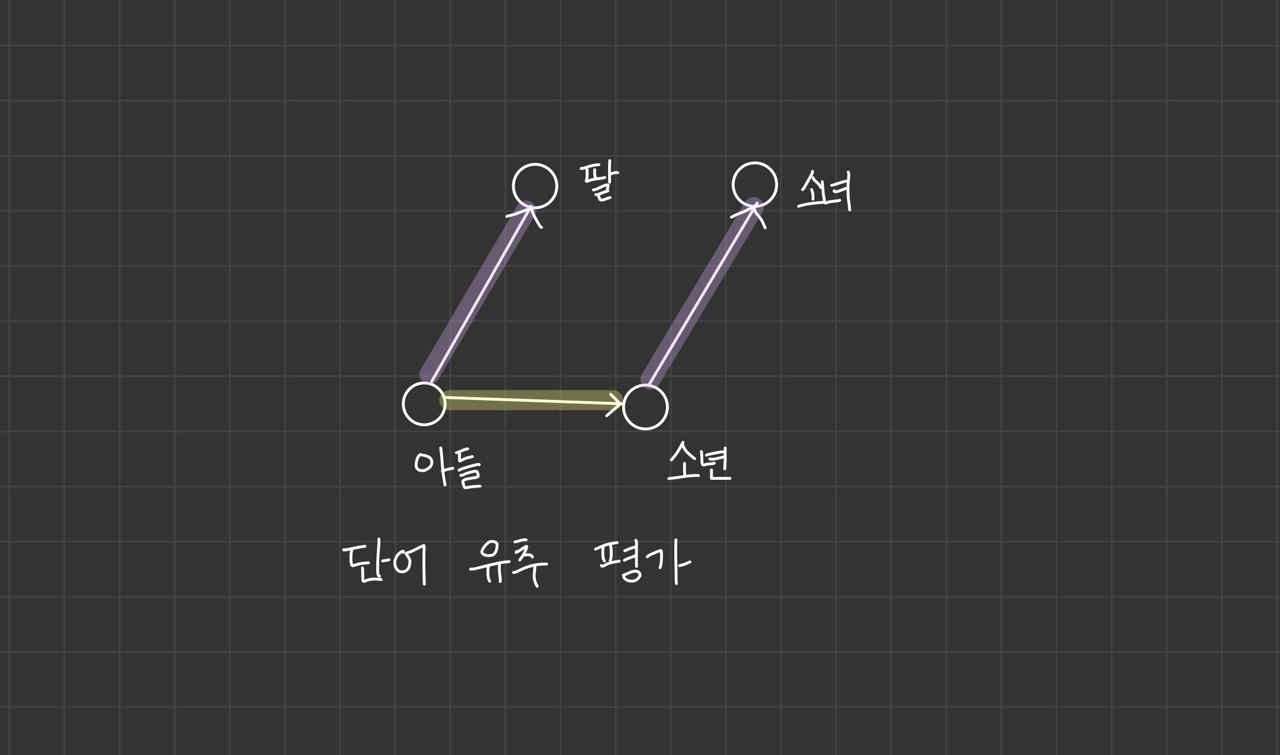
아들-딸+소녀=소년이 성립됩니다.
'아들-딸' 사이의 관계와 '소년-소녀' 사이의 의미 차이가 임베딩에 함축되어 있다면 좋은 품질의 임베딩이라 말할 수 있습니다.
이런 식으로 임베딩을 평가하는 방법을 단어 유추 평가(word analogy test)라고 합니다.
한국어 위키백과, KorQuAD, 네이버 영화 리뷰 말뭉치 등 공개된 데이터로 학습한 Word2Vec 임베딩에 단어 유추 평가를 수행한 결과가 아래 표로 나타내집니다.
| 단어1 | 단어2 | 단어3 | 결과 |
|---|---|---|---|
| 아들 | 딸 | 소년 | 소녀 |
| 아들 | 딸 | 아빠 | 엄마 |
| 아들 | 딸 | 남성 | 여성 |
| 남동생 | 여동생 | 소년 | 소녀 |
| 남동생 | 여동생 | 아빠 | 엄마 |
| 남동생 | 여동생 | 남성 | 여성 |
| 신랑 | 신부 | 왕 | 여왕 |
| 신랑 | 신부 | 손자 | 손녀 |
| 신랑 | 신부 | 아빠 | 엄마 |
<표 1-3> Word2Vec 임베딩에 단어 유추 평가를 수행한 결과
3. 전이 학습
임베딩은 다른 딥러닝 모델의 입력값으로 주로 쓰입니다.
만약 '문서 분류'를 위한 딥러닝 모델을 만든다고 하면, 단어 임베딩이 좋은 성능을 내는데 영향을 끼치고 품질 좋은 임베딩을쓰면 문서 분류 정확도와 학습 속도가 올라갑니다.
임베딩을 다른 딥러닝 모델의 입력값으로 쓰는 기법을 전이 학습(transfer learning)이라고 합니다.
대규모 말뭉치를 활영해 임베딩을 미리 만들어두고, 이 임베딩을 입력값으로 쓰는 전이 학습 모델은 문서 분류 task를 빠르게 잘 처리합니다.
임베딩에는 의미적, 문법적 정보가 녹아있기 때문입니다.
이번 예시에서는 양방향 LSTM(Bidirectional Long Short-Term Memory)에 어텐션(attention) 매커니즘을 적용했다고 합니다.
- 이 영화 꿀잼 +
- 이 영화 노잼 +
전이 학습 모델은 문장을 입력받으면 해당 문장이 긍정인지 부정인지를 출력합니다.
문장을 형태소 분석한 뒤 각 형태소에 해당하는 FastText 단어 임베딩이 모델의 입력값이 됩니다.
- FastText는 Word2Vec의 개선된 버전입니다.
첫 번째 문장은 '이', '영화', '꿀잼' 임베딩 세 개가 순차적으로 들어가며, 두 번째 문장은 '이', '영화', '노잼' 임베딩이 차례대로 들어갑니다.
아래의 그림은 모델의 학습 과정별 단순 정확도(accuracy)를 나타낸 것입니다.
데이터로는 네이버 영화 리뷰를 사용했고, 문장과 극성이 쌍으로 정리되어 있어 문서 극성 분류 모델의 학습 데이터로 적절하다고 합니다.
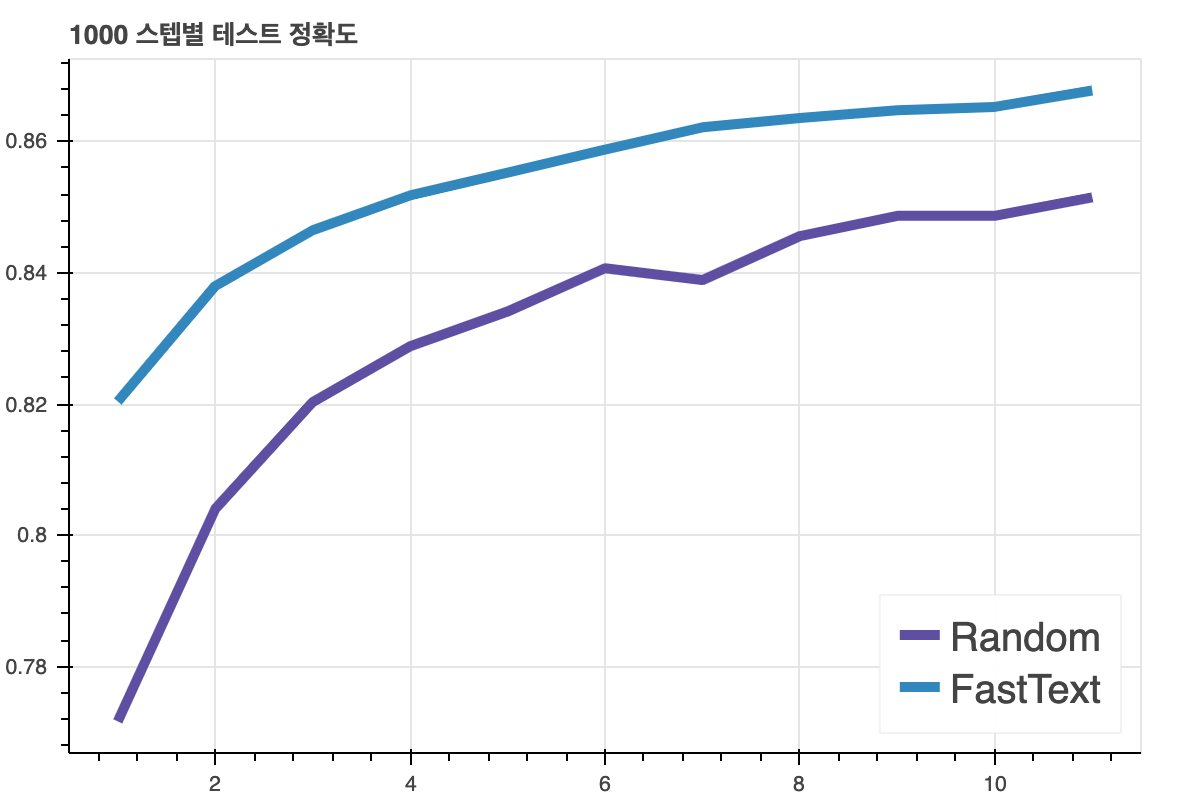
위 그림에서 파란선은 FastText는 모델의 입력값으로 임베딩을 사용하였고, Random은 입력 벡터를 랜덤 초기화한 다음 모델을 학습한 방식입니다.
비교해보면 FastText가 모델의 성능이 훨씬 더 좋습니다. 임베딩의 품질이 좋으면 수행하려는 Task의 성능이 올라간다는 것을 확인할 수 있습니다.
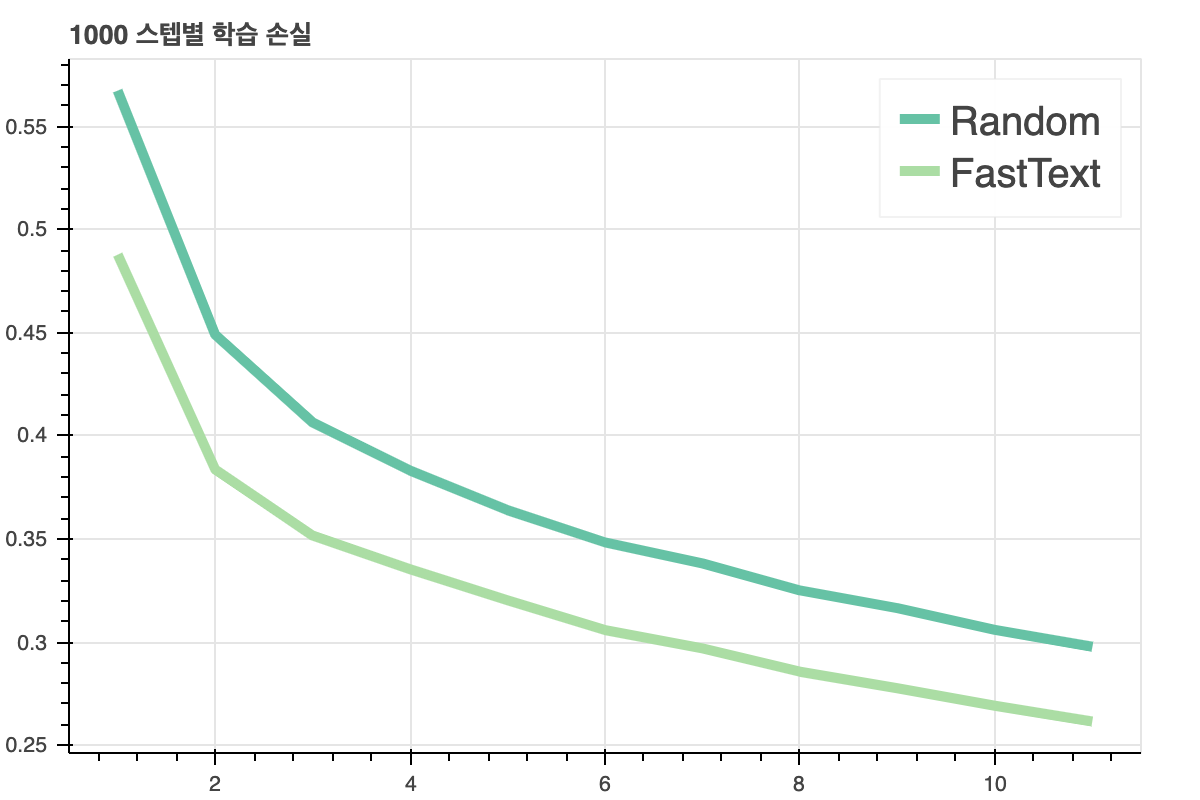
위 그림은 문서 극성 분류 모델의 학습 과정별 학습 손실(training loss)을 그래프로 나타낸 것입니다.
학습 손실이 FastTest가 Random보다 훨씬 더 작고 빠르게 감소하는 것을 볼 수 있습니다.
임베딩 품질이 좋으면 모델의 수렴(converge)이 빨라진다는 것을 확인했습니다.
임베딩 기법 역사
임베딩 기법의 발전 흐름과 종류를 살펴볼 예정인데요. 크게 4가지 관점으로 나눠 정리하려고 합니다.
- 통계 기반에서 뉴럴 네트워크 기반으로
- 단어 수준에서 문장 수준으로
- 룰 → 엔드투엔드 → 프리트레인/파인튜닝
- 임베딩의 종류와 성능
1. 통계 기반에서 뉴럴 네트워크 기반으로
초기 임베딩은 통계량을 기반으로 사용한 기법이었습니다.
대표적으로 LSA(Latent Semantic Analysis, 잠재의미분석)이 있습니다.
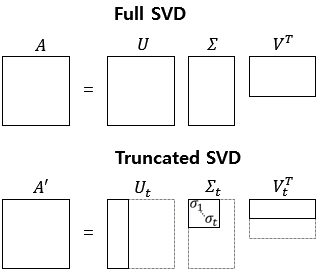
LSA는 단어 사용 빈도 등 말뭉치의 통계량 정보가 들어 있는 Matrix에 SVD(Singular Value Decomposition, 특이값 분해) 등 수학적 기법을 적용해 행렬에 속한 벡터들의 차원을 축소하는 방법입니다.
| 구분 | 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 |
|---|---|---|---|---|---|---|---|---|---|
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
단어-문서 행렬에 잠재 의미 분석을 적용했다고 가정합니다.
그런데 단어-문서 행렬을 행의 개수가 훨씬 더 많습니다. 어휘 수는 대개 10~20만 개가 될 것입니다.
행렬의 대부분 요소 값은 0이 되는데요. 이유는 문서 하나에 모든 어휘가 쓰이는 경우는 매우 드물기 때문입니다.
이렇게 대부분의 요소 값이 0인 행렬을 희소 행렬(sparse matrix)이라고 합니다.

- 희소행렬 예시 이미지입니다.
이런 희소 행렬을 다른 모델의 입력값으로 쓰는 경우, 계산량과 메모리 소비량이 쓸데 없이 너무 큽니다.
그래서 원래 행렬의 차원을 축소해서 사용해야 합니다.
기준은 단어와 문서를 기준으로 줄이게 됩니다.
잠재 의미 분석 행렬 수행 대상 행렬은 여러 종류가 있습니다.
- TF-IDF 행렬
- 단어-문맥 행렬
- 점별 상호 정보량 행렬
이는 책에서 뒷장에서 더 자세히 다루고 있습니다.
최근에는 뉴럴 네트워크 기반의 임베딩 기법들이 주목받고 있습니다.
이전 단어들이 주어졌을 때 다음 단어가 뭐가 될지 예측하거나 문장 내 일부분에 구멍을 뚫어 놓고 해당 단어가 무엇일지 맞추는 과정에서 학습됩니다.
2. 단어 수준에서 문장 수준으로
2017년 이전의 임베딩 기법들은 대게 단어 수준 모델이었습니다.
그 예시로 NPLM, Word2Vec, Glove, FastText, Swivel 등이 있습니다.
단어 수준 임베딩 기법의 단점은 동음이의어(homonym)을 구분하기 어렵다는 점인데요.
단어 형태가 같다면 동일한 단어로 보고, 문맥 정보를 해당 단어 벡터에 전달하기 때문입니다.
다행히도 ELMo(Embeddings from Language Modles)가 발표된 후 문장 수준 임베딩 기법이 주목받았습니다!
3. 룰 → 엔드투엔드 → 프리트레인/파인튜닝
-
1990년 : 사람이 feature를 직접 뽑음
- feature란 모델의 입력값을 의미
- 예를 들어, 한국어 문장을 구문 분석(parsing)하는 모델을 만든다고 하면, feature 추출은 언어학적 지식을 활용합니다.
-
2000년 중반 : 딥러닝 모델 주목, 입출력의 관계를 사람의 개입 없이 모델 스스로 처음부터 끝까지 이해하도록 유도
- 이런 기법을 엔드투엔드 모델(end-to-end model)이라고 합니다.
- 기계 번역에 널리 쓰인 sequence-to-sequence 모델이 대표 사례입니다.
-
2018년 : 의미적, 문법적 맥락이 포함된 말뭉치로 임베딩을 만듦. 구체적 문제에 맞는 소규모 데이터에 맞게 임베딩을 포함한 모델 전체를 업데이트함
- ELMo 모델이 제안된 이후 end-to-end 모델에서 pretrain과 finetuning 방식으로 발전하고 있습니다.
자연어 처리의 구체적 문제들을 다운스트림 태스크(Downstream task)라고 합니다.
대비되는 개념이 업스트림 태스크(unstream task)입니다. 이는 다운스트림 태스크 이전에 해결해야 할 과제라는 뜻입니다.
다운스트림 태스크를 살펴보겠습니다.
예를 들어, 품사판별(Part-of Speech tagging), 개체명 인식(Named Entity Recognition), 의미역 분석(Semantic Role Labeling) 등이 있습니다.
- 품사 판별 : 나는 네가 지난 여름에 한 [일]을 알고 있다. → 일: 명사(Noun)
- 문장 성분 분석 : 나는 [네가 지난 여름에 한 일]을 알고 있다. → 네가 지난 여름에 한 일 : 명사구(Noun Phrase)
- 의존 관계 분석 : [자연어 처리는] 늘 그렇듯이 [재미있다]. → 자언어 처리는, 재미있다 : 주격명사구(Nsub)
- 의미역 분석 : 나는 [네가 지난 여름에 한 일]을 알고 있다. → 네가 지난 여름에 한 일 : 피행위주역(Patient)
- 상호 참조 해결 : 나는 어제 [성빈이]를 만났다. [그]는 스웨터를 입고 있었다. → 그=성빈이
4. 임베딩의 종류와 성능
임베딩 기법은 크게 3가지로 나뉩니다.
- 행렬 분해
- 예측
- 토픽 기반
1) 행렬 분해 기반 방법
말뭉치 정보가 들어 있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식의 임베딩 기법을 의미
분해한 이후에 둘 중 하나의 행렬만 쓰거나 둘을 add 하거나 concatenate 임베딩으로 사용합니다.
GloVe, Swivel 등이 여기에 속합니다.
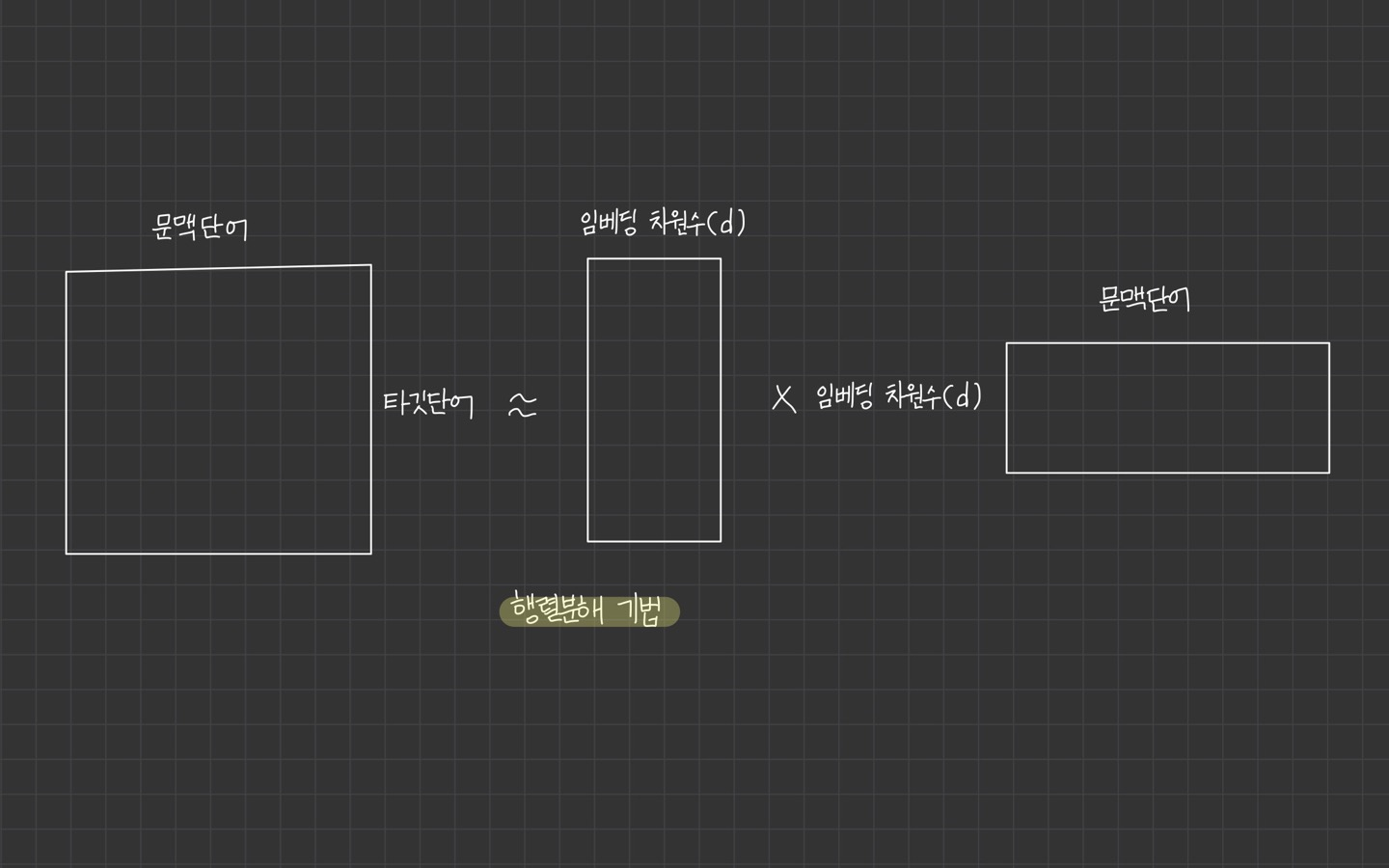
-행렬 분해 기반 방법
2) 예측 기반 방법
어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 이전 단어들이 주어졌을 때 다음 단어가 무엇일지 예측하거나, 문장 내 일부 단어를 지우고 해당 단어가 무엇일지 맞추는 과정에서 학습하는 방법
뉴럴 네트워크 방법들이 예측 기반 방법에 속합니다.
예를 들어, Word2Vec, FastText, BERT, ELMo, GPT 등이 예측 기반 방법에 속합니다.
3) 토픽 기반 방법
주어진 문서에 잠재된 주제를 추론 inference하는 방식으로 임베딩을 수행하는 기법
LDA 같은 모델은 학습이 완료되면 각 문서가 어떤 주제 분포(topic distribution)을 갖는지 확률 벡터 형태로 반환하기 때문에 임베딩 기법의 일종으로 이해할 수 있습니다.
4) 임베딩 성능 평가
성능 측정 대상 다운스트림 태스크는 형태소 분석, 문장 성분 분석, 의존 관계 분석, 의미역 분석, 상호 참조 해결 등이 있습니다.
문장 임베딩 기법인 ELMo, GPT, BERT가 단어 임베딩 기법인 Glove를 크게 앞서고, BERT-large 모델이 가장 좋은 성능을 보여준다고 합니다.
한국어는 공개되어 있는 데이터가 많지 않아 품질 측정이 어렵다고 적혀 있습니다.
용어 정리
- 자연어 처리의 데이터는
텍스트(Text)형태의 자연어입니다. 말뭉치(Corpus)란 임베딩 학습이라는 특정한 목적을 가지고 수집한 표본(sample)입니다.컬렉션(Collection): 말뭉치에 속한 각각의 집합문장(sentence): 데이터의 기본 단위- 생각이나 감정을 말과 글로 표현할 때 완결된 내용을 나타내는 최소의 독립적인 형식 단위
문서(Document): 생각이나 감정, 정보를 공유하는 문서 집합 (단락(paragraph))토큰(token): 텍스트 데이터의 가장 작은 단위- 때로
단어(word),형태소(morpheme),서브워드(subword)라고 부를 수도 있습니다.
- 토큰 분리 기준은 오픈소스 형태소 분석기에 따라 다릅니다. 예로는 Mecan, Kkma 등이 있습니다.
- 때로
토크나이즈(tokenize): 문장을 이처럼 토큰 시퀀스로 분석하는 과정형태소 분석(morphhological analysis): 문장을 형태소 시퀀스로 나누는 과정. 한국어는 토큰화와 품사 판별(Part Of Speech Tagging)이 밀접한 관계를 가집니다.어휘 집합(Vocabulary)는 말뭉치에 있는 모든 문서를 문장으로 나누고 여기에 토크나이즈를 실시한 후 중복을 제거한 토큰들의 집합입니다.미등록 단어(unknown word): 어휘 집합에 없는 토큰
요약
임베딩의 정의와 역할, 역사와 종류 등에 대해 정리했습니다.
책에서 주요 내용을 정리한 것을 참고하여 요약을 적겠습니다.
- 임베딩이란 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정을 가리킨다.
- 임베딩을 사용하면 단어/문장 간 관련도 계산 가능 (ex. 코사인 유사도)
- 임베딩에는 의미적/문법적 정보 함축
- 임베딩은 다른 딥러닝 모델의 입력값으로 사용됨
- 통계 기반에서 뉴럴 네트워크 기반으로, 단어 수준에서 문장 수준으로, 엔드투엔드에서 프리트레인/파인튜닝 방식으로 발전
- 크게 행렬 분해 모델, 예측 기반 모델, 토픽 기반 기법 등으로 나뉨
- 데이터의 최소 단위
토큰< 토큰의 집합문장< 문장의 집합문서< 문서의 집합말뭉치 - 토크나이즈란 문장을 토큰으로 분석하는 과정을 의미
어휘 집합은 말뭉치에 있는 모든 문서를 문장으로 나누고 여기에 토크나이즈를 실시한 후 중복을 제거한 토큰들의 집합을 말합니다.
