이번 포스팅은 RNN과 LSTM에 대해 공부하고 정리하려고 합니다.🚀
이전에 RNN과 LSTM에 대해 따로 정리한 자료가 있습니다. 해당 자료는 일러스트를 이용해서 정리한 자료이니 필요하신 분은 참고하세요.
🔗 Recurrent Neural Networks (순환 신경망)
🔗 Long Short-Term Memory(LSTM) and GRU
Recurrent Neural Networks
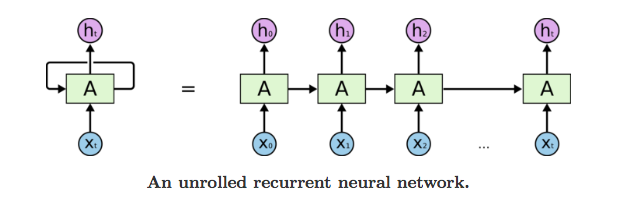
Recurrent Neural Networks은 이전의 inputs을 memory에 기억하는 최초의 algorithms입니다.
RNN 아이디어의 시작은 sequential information의 이용이었습니다. 전통적 신경망에서는 모든 inputs과 outputs이 서로 독립적이라 가정합니다.
그러나 많은 task에서 이 가정이 좋지는 못했습니다. 예를 들어, 문장에서 단어를 예측하려면 그 앞에 어떤 단어가 왔는지를 알아야 더 잘 예측할 수 있습니다.
RNN에는 sequence의 모든 요소에 대해 동일한 작업을 수행하여 recurrent라고 합니다. Output은 이전 계산에 의존하고 지금까지 계산된 정보를 capture하는 memory가 있습니다.
RNN은 음성 인식, 언어 번역, 주식 예측 등에도 사용되고 이미지 인식에서 사진의 내용을 설명하는데도 사용됩니다.
Different Types of RNN’s
RNN의 유형은 다양합니다. RNN은 recurrent network가 vector sequence(input or output)에 대해 연산을 수행할 수 있습니다.
몇 가지 예를 들겠습니다.
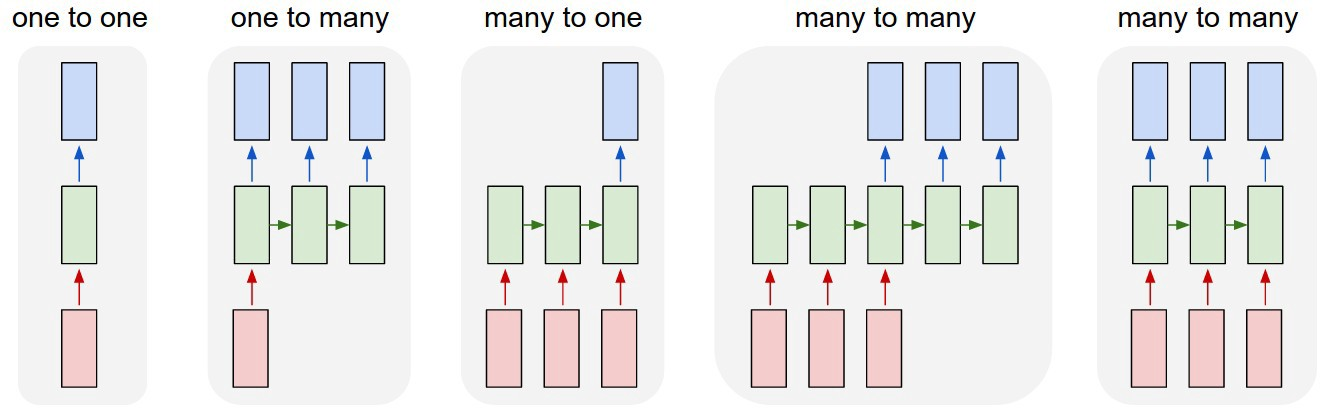
해당 그림에서 각 사각형은 vector이며 화살표는 function을 의미합니다.
- 빨간색 box는 input vector
- 파란색 box는 output vector
- 녹색 box는 RNN state
-
one to one
RNN이 없는 Vanilla mode이며, fixed-sized output에 대한 fixed-sized input을 처리합니다.
예를 들어 image classification이 있습니다. -
one to many
input을 받고 output으로 data sequence를 제공합니다. (e.g. Image Captioning, image -> sequence of words)
*image caption은 image를 input으로 받아 sentence를 출력합니다
-
many to one
Sequence of information을 input으로 받아 fixed-sized output을 제공합니다. (Sequence Unit, e.g. Sentiment Classification, sequence of words -> sentiment) -
many to many
Sequence input으로 sequence output를 제공합니다. (e.g. Machine Translation, seq of words in English -> seq of words in French) -
Bidirectional Many-to-Many
Synced sequence input and output. recurrent transformation이 고정되어 있고, 원하는 만큼 여러 번 적용할 수 있습니다. (e.g. Video Classification on frame level)
CNN vs RNN
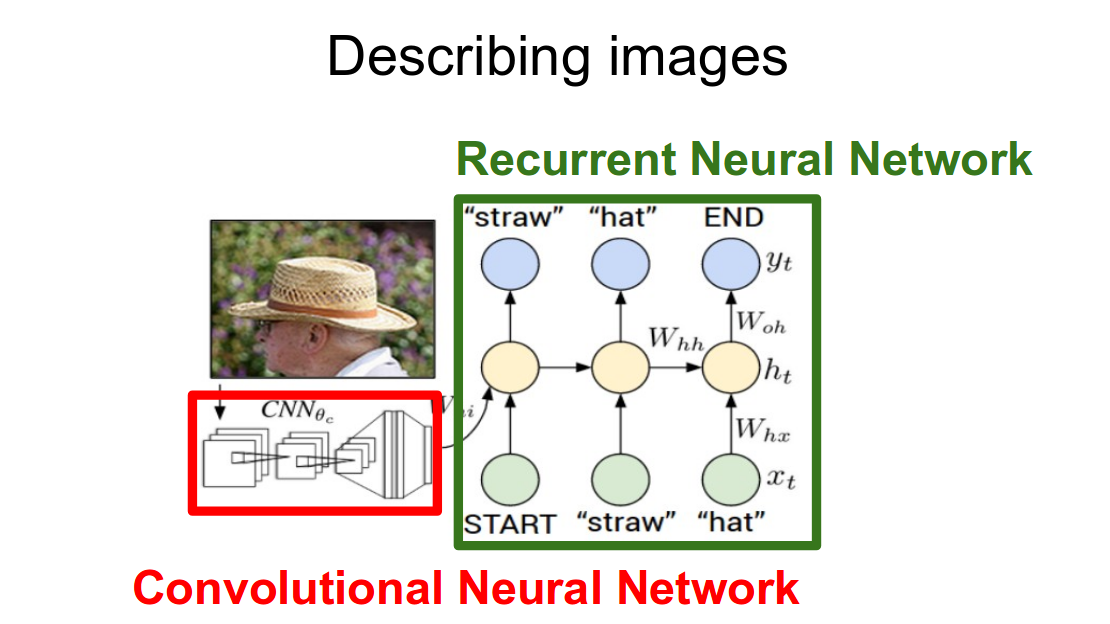
*Difference in Describing images using CNN , RNN.
CNN(Convolutional Neural Network)은 심층 신경망의 한 종류입니다. 시각적 이미지 분석에 가장 일반적으로 사용됩니다.
입력이 vector인 신경망과 달리 여기에서는 입력이 multi-channeled image입니다. CNN은 최소한의 전처리가 필요하도록 설계된 multilayer perceptrons의 변형을 사용합니다.
RNN(Recurrent Neural Networks) 은 text, genome(유전체), handwriting, spoken word, numerical times series data와 같은 데이터 시퀀스의 패턴을 인식하도록 설계된 일종의 인공 신경망입니다.
Recurrent Neural Networks는 훈련을 위해 역전파 알고리즘을 사용합니다. 내부 메모리 내부 메모리로 인해 RNN은 입력에 대한 중요한 정보를 기억할 수 있으므로 다음에 올 내용을 매우 정확하게 예측할 수 있습니다.
CNN과 RNN의 주요 차이점은 문장과 같이 순서대로 오는 data인 시간 정보를 처리하는 능력입니다. RNN은 이런 목적을 위해 설계된 반면, convolution neural network는 시간 정보를 효과적으로 해석할 수 없습니다. 결과적으로 CNN과 RNN은 다른 용도로 사용되며, 사용 사례가 다른 만큼 신경망 자체의 구조에 차이가 있습니다.
CNN은 데이터를 변환하기 위해 Convolution layer에서 filter를 사용하는 반면, RNN은 sequence의 다른 data point에서 활성화 함수를 재사용하여 series의 다음 출력을 생성하는 예측 모델입니다.
Deep view into RNN’s
simple neural network에서는 이전 정보와 관련 없이 독립적으로 정보를 처리하는 input unit, hidden unit을 가졌습니다.
또한, 여기서 우리는 정보를 기억할 기회를 주지 않는 hidden unit에 대해 다른 weight과 bias를 줬습니다.
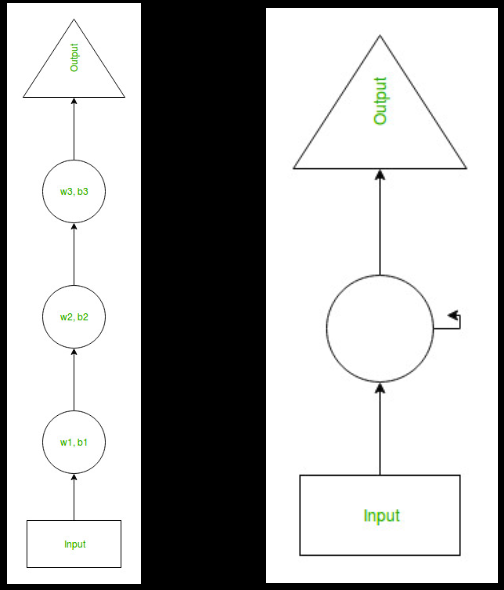
RNN의 hidden layer는 process 전반에 걸쳐 동일한 weight과 bias를 갖고 있고, 이를 통해 처리된 정보를 외울 기회를 제공합니다.
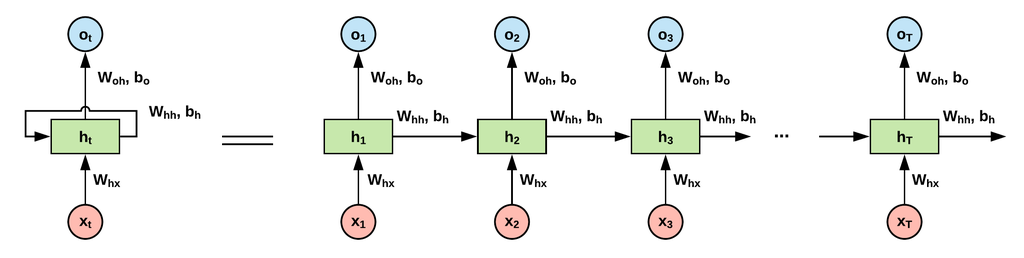
위 그림의 구조를 하나씩 살펴보겠습니다.
Current time stamp
위 그림에서 는 output state입니다.
output state
: current time stamp
: previous time stamp
: input state
Applying activation function
: weight
: single hidden vector
: weight at previous hidden state
: weight at current input state
여기서 tanh는 활성화 함수로, 활성화 범위를 [-1, 1]로 squash하는 비선형을 구현합니다.
Output
: output state
: weight at the output state
Character level language model
이제 예를 통해 이해해보겠습니다.
RNN에 엄청나게 큰 텍스트 데이터를 제공합니다.
이전 문자 sequence가 주어질 때, 그 sequence에서 다음 문자의 확률 분포를 모델링하도록 합니다.
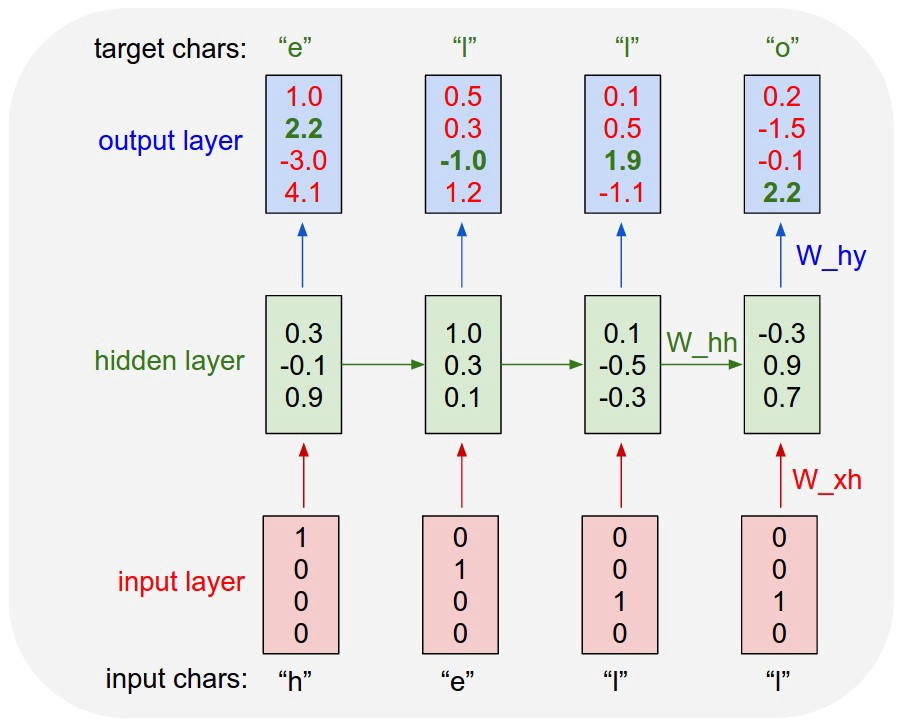
'hello' 라는 단어를 사용할 것이고, 이는 'h', 'e', 'l', 'o'란 네 글자 vocab을 사용합니다.
각 알파벳을 입력했을 때, 'e', 'l', 'o' 등을 예측한 값을 확인할 수 있습니다.
Back propogation through time(BTT)
RNN은 시간을 통해 backpropagation합니다.
weight을 update하기 위해 every time stamp로 되돌아 가는 것을 Back propogation through time이라고 합니다.
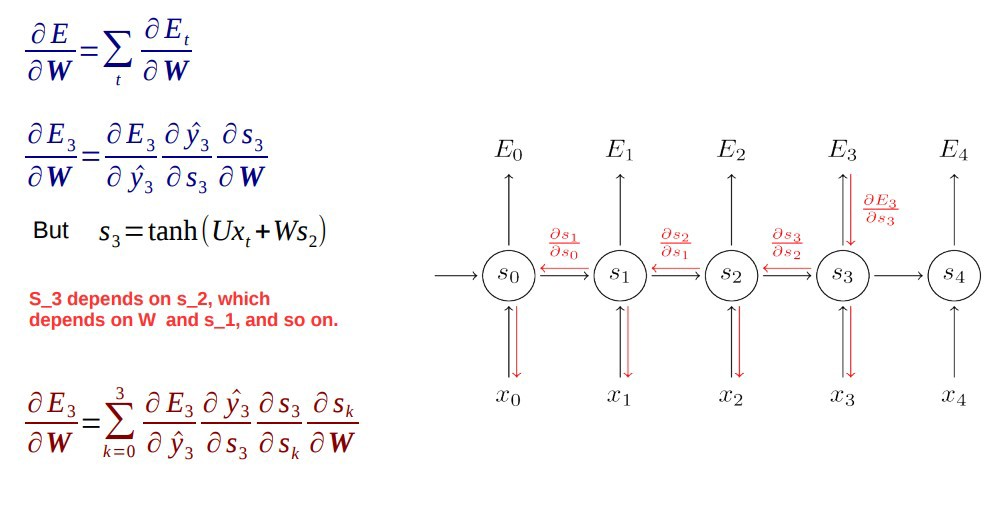
일반적으로 전체 sequence(단어)를 하나의 training example로 보기 때문에 전체 error는 각 time step의 error 합입니다.
여기서 가중치는 각 time step에서 동일합니다.
time에 따른 backpropagation 단계를 하나씩 살펴보겠습니다.
- cross entropy error는 먼저 현재 출력과 실제 출력을 사용하여 계산합니다. (두 값의 차를 이용)
- network는 모든 time step에 펼쳐져 있습니다.
- 펼쳐진 network의 경우, weight parameter에 대해 각 time step에 대한 gradient가 계산됩니다.
- 모든 time step에 대한 weight이 동일하므로, 모든 time step에 대한 gradient를 합할 수 있습니다.
- 그 다음 ecurrent neuron과 dense layers에 대해 weight이 업데이트됩니다.
Issues of RNN’s?
모든 time stamp로 돌아가서 weight을 업데이트하는 과정은 실제로 연산이 많이 느린 편이고, vanishing or exploding gradient 문제가 발생합니다.
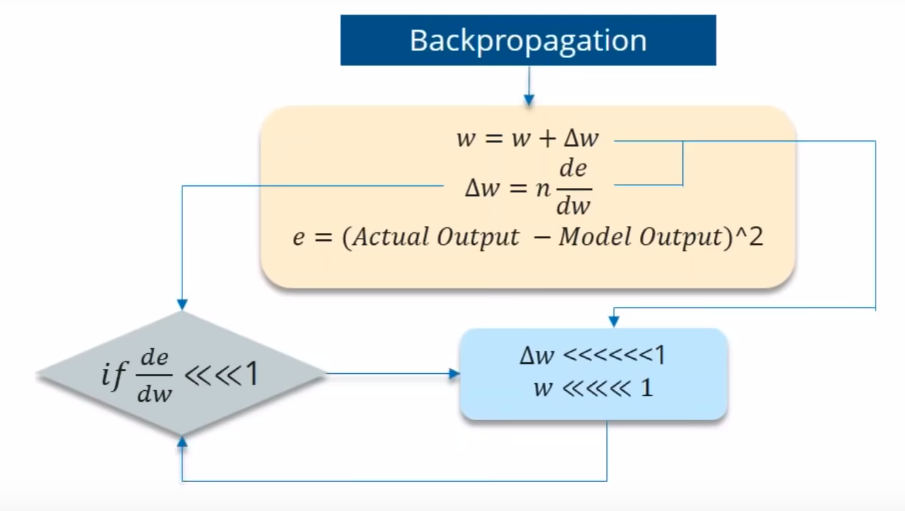
만약 미분값이 1보다 작다면 gradient를 계속 유도하는 과정에서 값은 계속해서 작아집니다.
예를 들어 값이 0.863 →0.532 →0.356 →0.192 →0.117 →0.086 →0.023 →0.019와 같이 줄어들었다고 가정하겠습니다.
이전 단계의 영향이 점점 줄어들고, 이 문제로 인해 training 중 long-term dependency가 무시됩니다.
반대로 미분값이 1보다 큰 경우는 exploding gradient 문제로 이어집니다.
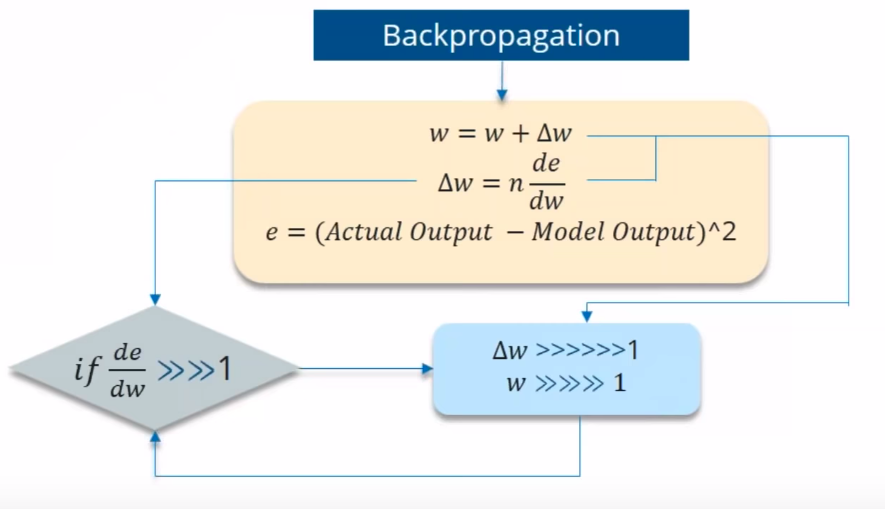
vanishing과 exploding 문제를 어떻게 극복할 수 있을까요?
- Vanishing gradient 문제의 경우
- ReLU activation function
- LSTM, GRU
- Exploding gradient 문제의 경우
- Truncated BTT
- gradient를 threshold로 자르기
- learning rate를 조절하는 RMSProp 사용
Advantages & Disadvantages of RNN
ANN에 비해 RNN의 주요 장점은
- RNN이 data sequence data를 모델링 할 수 있으므로, 각 sample이 이전 sample에 종속된다고 가정할 수 있습니다.
- RNN은 효과적인 pixel neighborhood를 늘리기 위해CNN과 같이 사용되기도 합니다.
단점은
- vanishing or exploding gradient
- RNN training이 어렵다.
- tanh or ReLU를 activation function으로 사용하는 것은 매우 긴 sequence를 처리할 수 없다.
Why LSTM’s?
LSTM은 오랜 기간 동안 정보를 기억하는 특성을 갖고 있습니다.
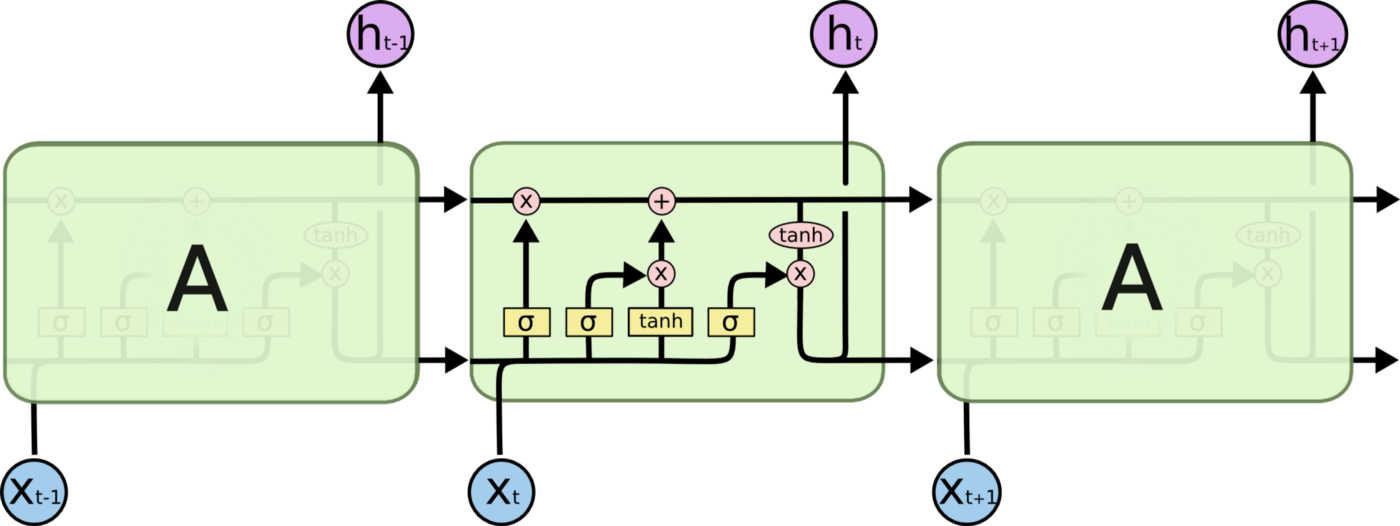
LSTM의 글을 보면 위와 같은 다양한 그림으로 표현되는데, LSTM은 gate가 있는 반복 모듈이기 때문입니다.
LSTM에는 3단계 과정이 있습니다.
Forget gate, Input gate, Output gate
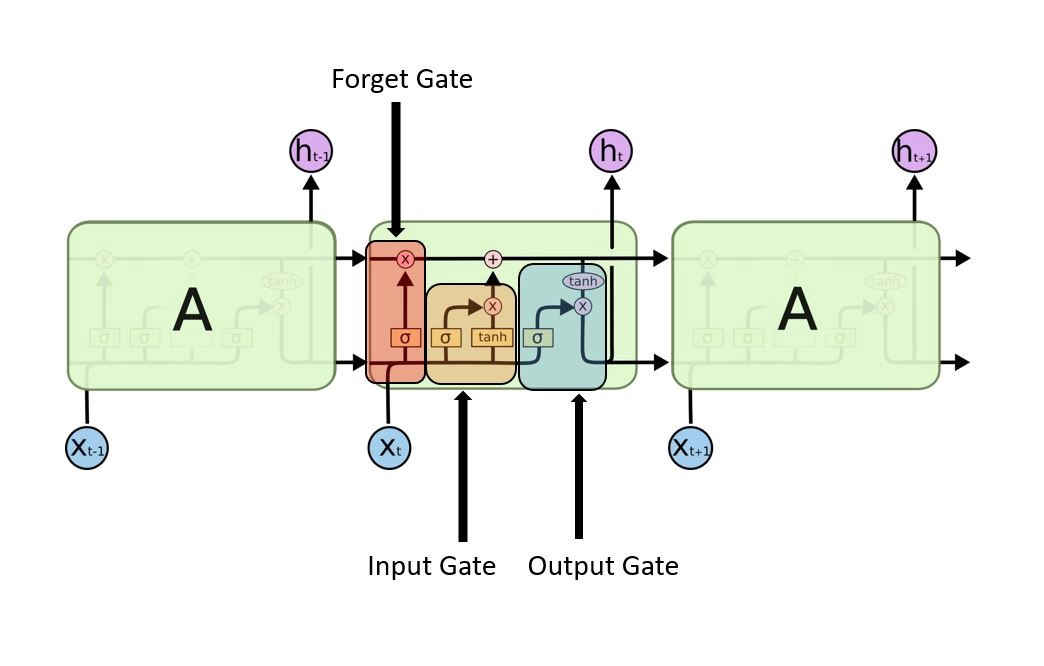
이 3가지 gate를 살펴보겠습니다.
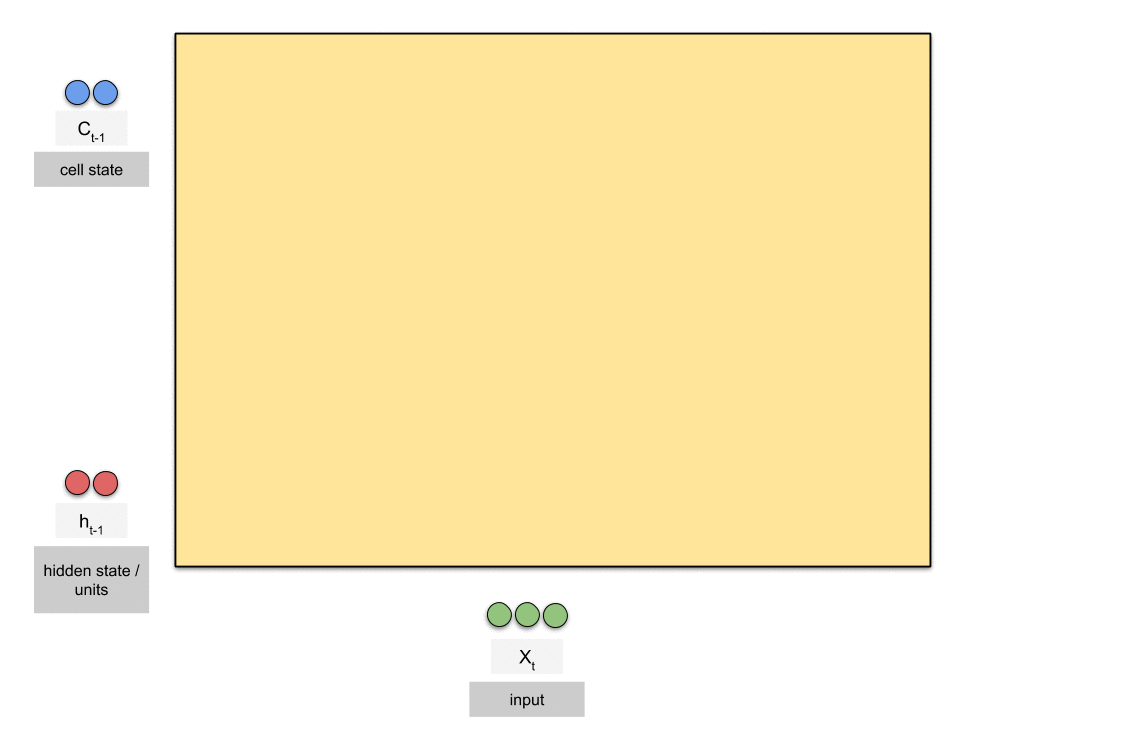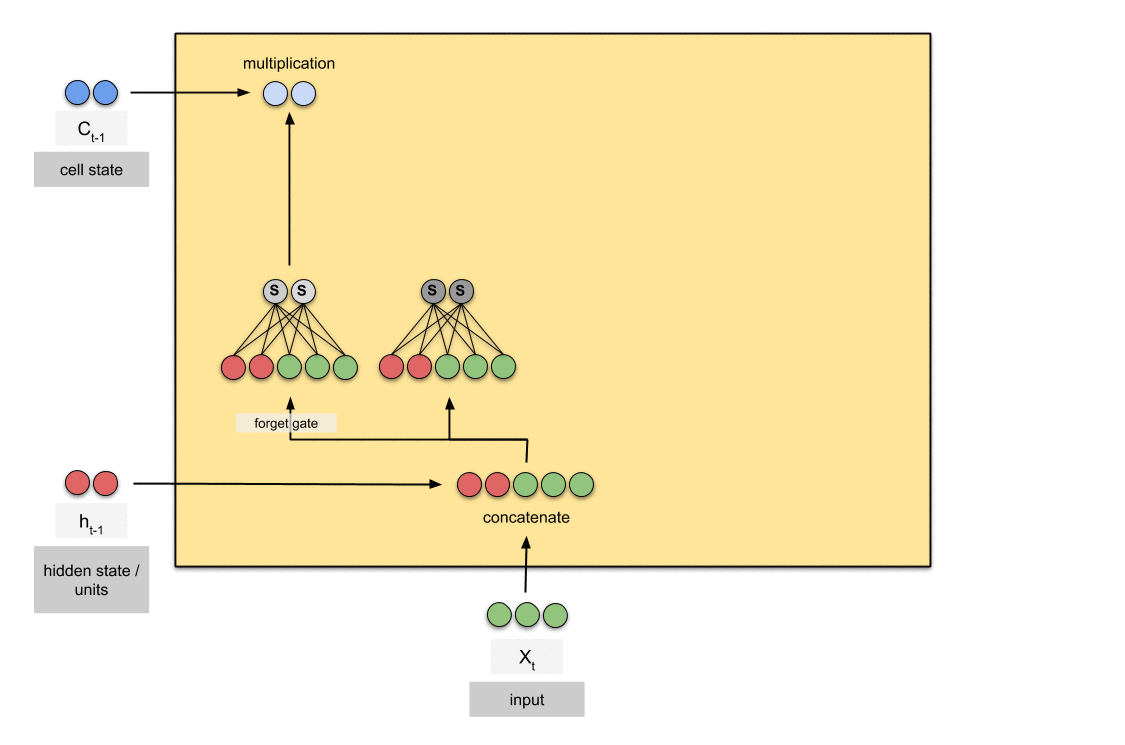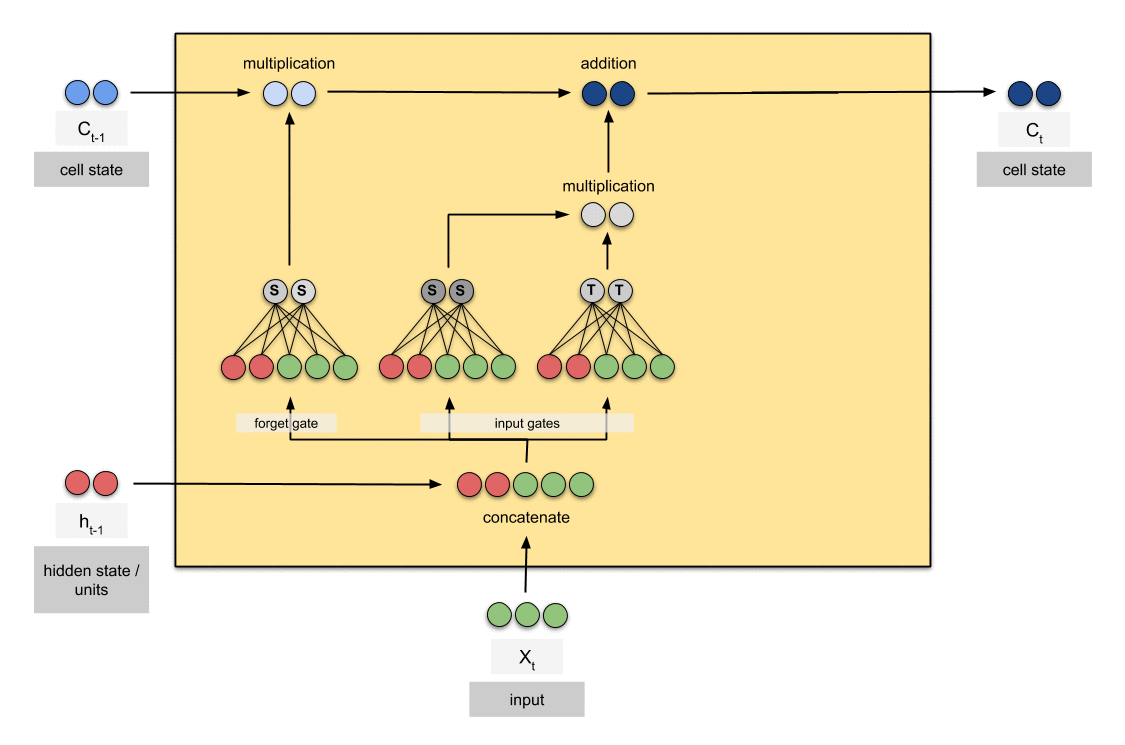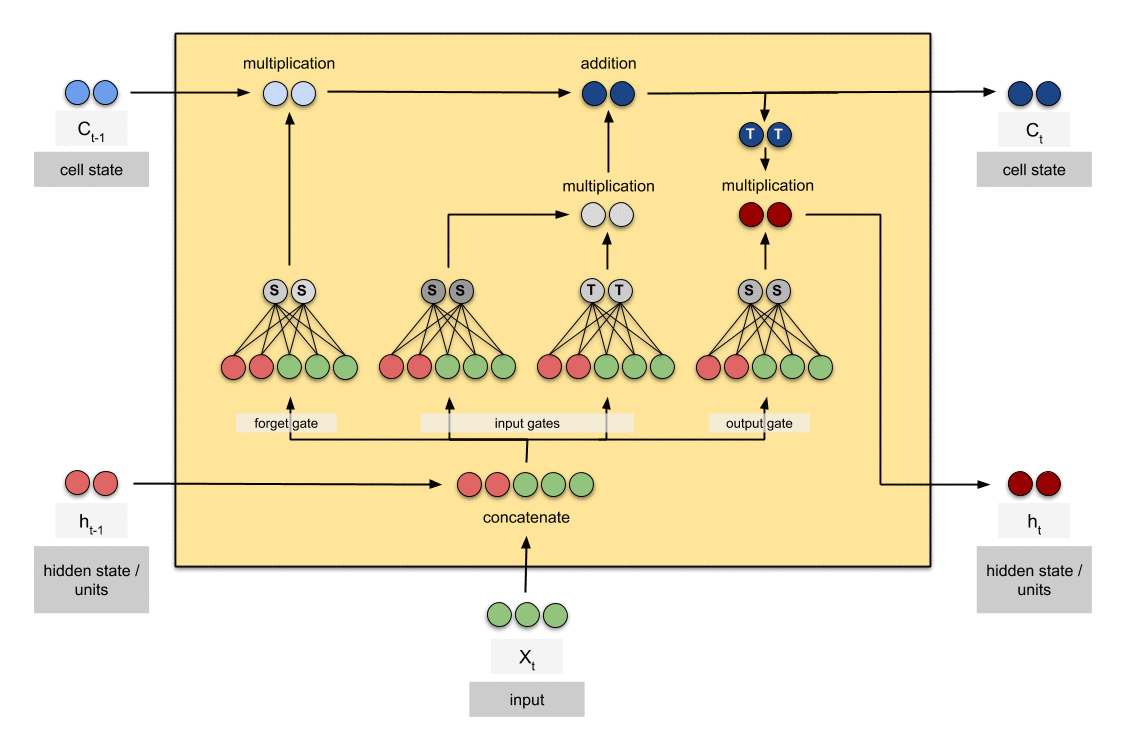
Forget gate
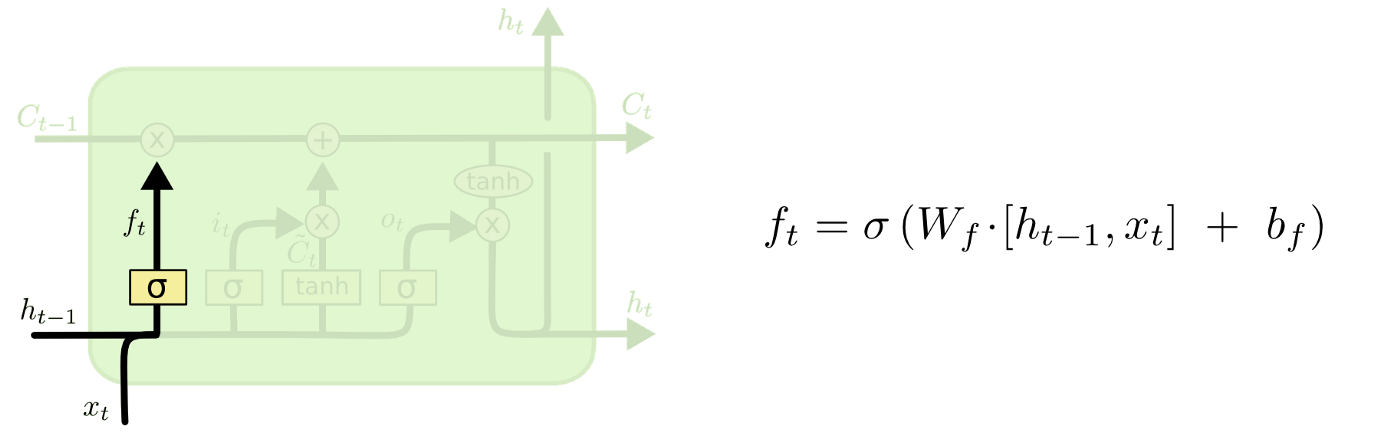
현재 입력과 이전 출력을 고려해서 cell state의 어떤 값을 버릴지를 결정합니다.
forget gate의 경우 time stamp의 cell에서 생략할 정보를 결정합니다.
이전 hidden state()와 input()를 살펴보고 cell state() 0과 1 사이의 숫자를 출력합니다.
- 0에 가까울수록 생략 (omit)
- 1에 가까울수록 유지 (keep)
예를 들어 '수연이와 경은이는 야구를 잘한다.' 라고 문장을 넣어보겠습니다. 이는 에 속합니다.
로 '경은이는 수학을 정말 잘한다' 라는 문장을 입력하겠습니다.
- forget gate는 첫 번째 문장의 마침표를 만난 후 context에 변화가 있을 수 있음을 인지합니다.
- 와 를 비교합니다.
- 다음 문장이 '경은이'에 대해 이야기 하고 있다는 점이 중요합니다.
- 따라서 '수연이'는 생략합니다.
input gate
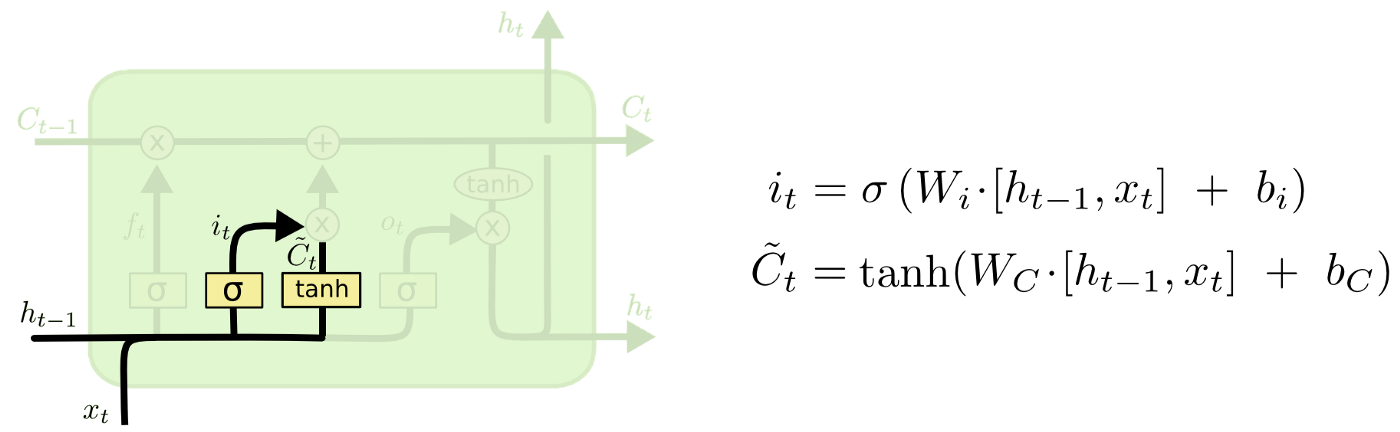
현재의 unit과 이전 출력으로 얻어진 값을 current state에 얼마나 반영할지 정하는 역할입니다.
sigmoid function은 [0,1] 로 값을 출력합니다. tanh는 sigmoid가 전달한 값에 weight를 부여하여 [-1, 1] 사이의 값으로 중요도 수준을 결정합니다.
이번에도 문장으로 예를 들어보겠습니다.
'수학을 잘하는 경은이는 어제 수학 시험에서 1등을 했다고 말했습니다.'
- input gate에서 중요한 정보를 분석합니다
- '경은이'는 '수학을 잘하고', '수학 시험 1등'이란 정보가 중요합니다.
- 여기서 중요하지 않은 정보는 '어제'나 '말했습니다' 입니다.
output gate
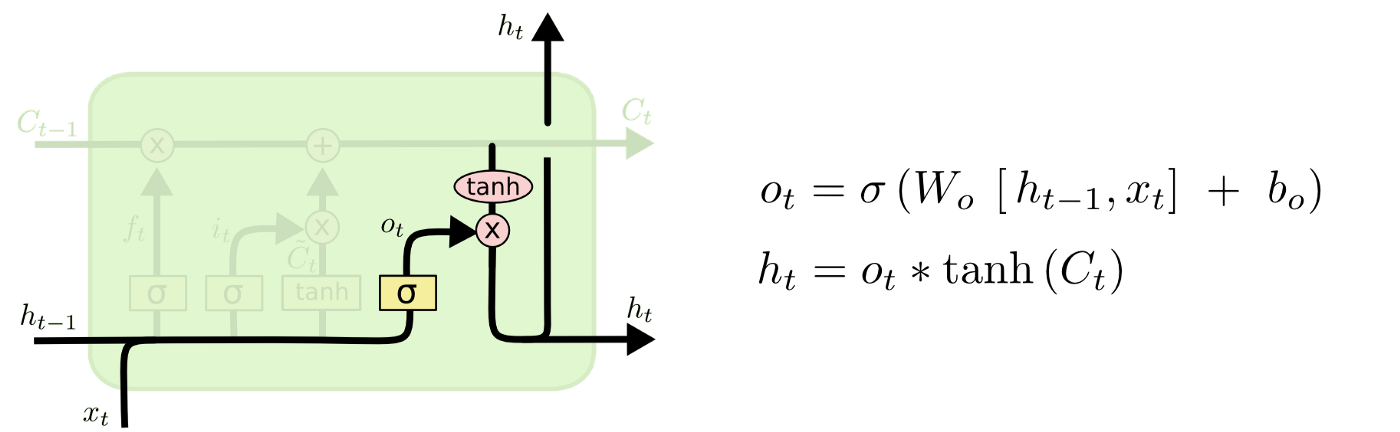
current cell의 어느 부분을 output으로 만들지 결정합니다.
sigmoid function은 [0,1] 로 값을 출력합니다. tanh는 sigmoid가 전달한 값에 weight를 부여하여 [-1, 1] 사이의 값을 출력합니다.
예시 문장을 들겠습니다.
'경은이는 수학을 잘하며 수학 시험 1등이므로 우수 학생 ___(가)이 올림피아드 금메달을 수상했습니다.'
- 빈 칸에 대한 많은 선택지가 있을 수 있지만, 최종 gate는 '경은이'로 대체됩니다.
여기까지 LSTM의 gate를 살펴보았습니다. LSTM은 gate가 추가된 RNN이라고 부르기도 합니다.
RNN은 vanishing or exploding gradient 문제를 갖고 있는 반면, gate가 추가된 LSTM이 해당 문제를 해결하는데 효과가 있다고 합니다.
LSTM의 핵심 개념은 cell state와 various gates입니다.
cell state는 sequence chain 아래로 정보를 전달하는 고속도로 역할을 합니다. 네트워크의 'memory'라고 볼 수 있습니다.
이론적으로는 cell state는 sequence 처리 전반에 걸쳐 관련 정보를 전달할 수 있습니다.
따라서 이전 time step의 정보여도 이후 time step에 이동하여 short-term memory의 영향을 줄입니다.
cell state가 진행됨에 따라 정보는 gate를 통해 cell state에 추가되거나 제거됩니다.
gate는 cell state에 대해 허용되는 정보를 결정하는 다양한 neural network입니다. training 중 유지하거나 잊어야 할 정보가 무엇인지를 학습합니다.
각 gate마다 사용하는 전용 가중치가 있고, 전달해야하는 정보를 결정하기 위해 tanh와 sigmoid의 출력값을 곱해 다음 layer로 전달하는 방식이었습니다.
따라서 LSTM이 layer에 사용되는 gate는 data와 gradient의 흐름을 적절히 조절하는 mechanism이 됩니다!
RNN과 LSTM은 굉장히 어려운 개념 같습니다. 해당 게시글을 번역하며 정리해서 조금 어색한 부분이 있을 수 있습니다.
잘못된 정보는 지적 부탁드립니다! 🙈
