Object Detection 시리즈
0️⃣ 딥러닝 Object Detection(1) - 개념과 용어 정리
1️⃣ 딥러닝 Object Detection(2) - Localization 개념 정리
2️⃣ 딥러닝 Object Detection(3) - Sliding Window, Convolution
3️⃣ 딥러닝 Object Detection(4) - Anchor Boxes, NMS(Non-Max Suppression)
4️⃣ 딥러닝 Object Detection(5) - Architecture - 1 or 2 stage detector
Localization을 위한 모델은 입력값으로 들어온 이미지에서 특정 object가 있는지 확인하고, object가 있다면 그 위치를 찾아냈습니다.
이제 Multi object detection을 통해 이미지에 있는 여러 object를 한꺼번에 찾아야합니다.
Sliding Window

[출처: https://www.researchgate.net/figure/Object-detection-by-sliding-window-approach_fig1_266215670]
큰 이미지에서 여러가지 object를 찾기 위해, 전체 이미지를 적당한 크기의 영역으로 나눈 후에, 각각의 영역에 대해 이전 스텝에서 만든 Localization network를 반복 적용해 보는 방식이 있습니다!
이런 방식을 슬라이딩 윈도우(Sliding window)라고 합니다. Localization network의 입력으로 만들기 위해 원본 이미지에서 잘라내는 크기를 window 크기로 하여 동일한 window 사이즈의 영역을 이동시키며(sliding) 수행하는 방식입니다.
마치 Convolution의 kernel이 sliding하는 것처럼 이해할 수 있습니다.
그러나 기존 CV 분야에서 신경망이 성공적으로 사용되기 전에는 간단한 선형 분류를 사용했고, 사용자가 직접 feature를 정해주어 classifier가 선형 함수를 사용했기 때문에 계산 비용이 저렴했습니다.
sliding window를 CNN에 적용했을 때 여러 번 network 연산을 해야 하므로 계산 속도가 느려지게 되고 반대로 stride를 넓히면 결과가 정확하지 않습니다.
- 참고 영상: 앤드류 응의 Object Detection

제일 왼쪽 이미지의 경우, 입력 영역에 대해 Conv Neural Network는 1의 출력값을 가집니다. 자동차가 있다고 인식하기 때문입니다.
Sliding window란 사각형 상자 모양의 window를 이용해 전체 이미지에 대해 sliding 시키고 모든 사각형 영역에 대해 자동차가 포함되는지 분류하는 것을 의미합니다.
Quiz
Sliding window 방식으로도 물체를 찾아내는데는 문제가 없습니다. 하지만 이렇게 접근하지 않는 이유는 뭘까요?
- Sliding window방식은 매우 많은 갯수의 window 영역에 대해 이미지의 localization을 돌아가면서 하나씩 진행해야하므로 처리해야 할 window 갯수만큼 시간이 더 걸립니다. 또한, 물체의 크기가 다양해지면 단일 크기의 window로 이를 커버할 수 없으므로 더욱 처리속도 문제가 심각해집니다.
Convolution
[출처: https://medium.com/datadriveninvestor/evolution-of-object-recognition-algorithms-i-5803c7be0691]
Sliding Window의 단점인 연산량과 속도를 개선하기 위한 방법 중 하나는 Convolution을 사용하는 것입니다.
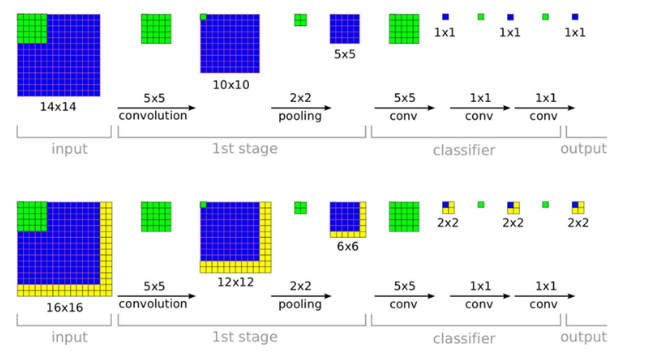
위 그림은 14x14 크기의 입력에 비해 convolution을 수행했을 때, 최종적으로 얻어지는 1x1 사이즈의 출력을 sliding window 영역의 localization 결과라고 해석한다면,
거꾸로 14x14 크기의 receptive field가 바로 sliding window 영역이 되는 효과가 있습니다.
sliding window로 localization을 수행하는 방식처럼 순차적으로 연산이 실행되는 게 아니라 병렬적으로 동시에 진행되므로 convolution은 속도 면에서 훨씬 효율적입니다.
결과적으로 Sliding window를 한 번에 Convolution으로 연산을 할 수 있습니다. 이전 스텝에서 localization을 위한 output이 flat vector 형태로 생성되었다면, convolution의 결과로 얻어지는 1x1 형태의 output도 동일하게 localization 결과로 대체될 수 있습니다.
이 영상에서는 Sliding window의 Conv neural network 구현을 위해서, 먼저 FC layer를 어떻게 convolution layers로 바꾸는지 설명합니다.
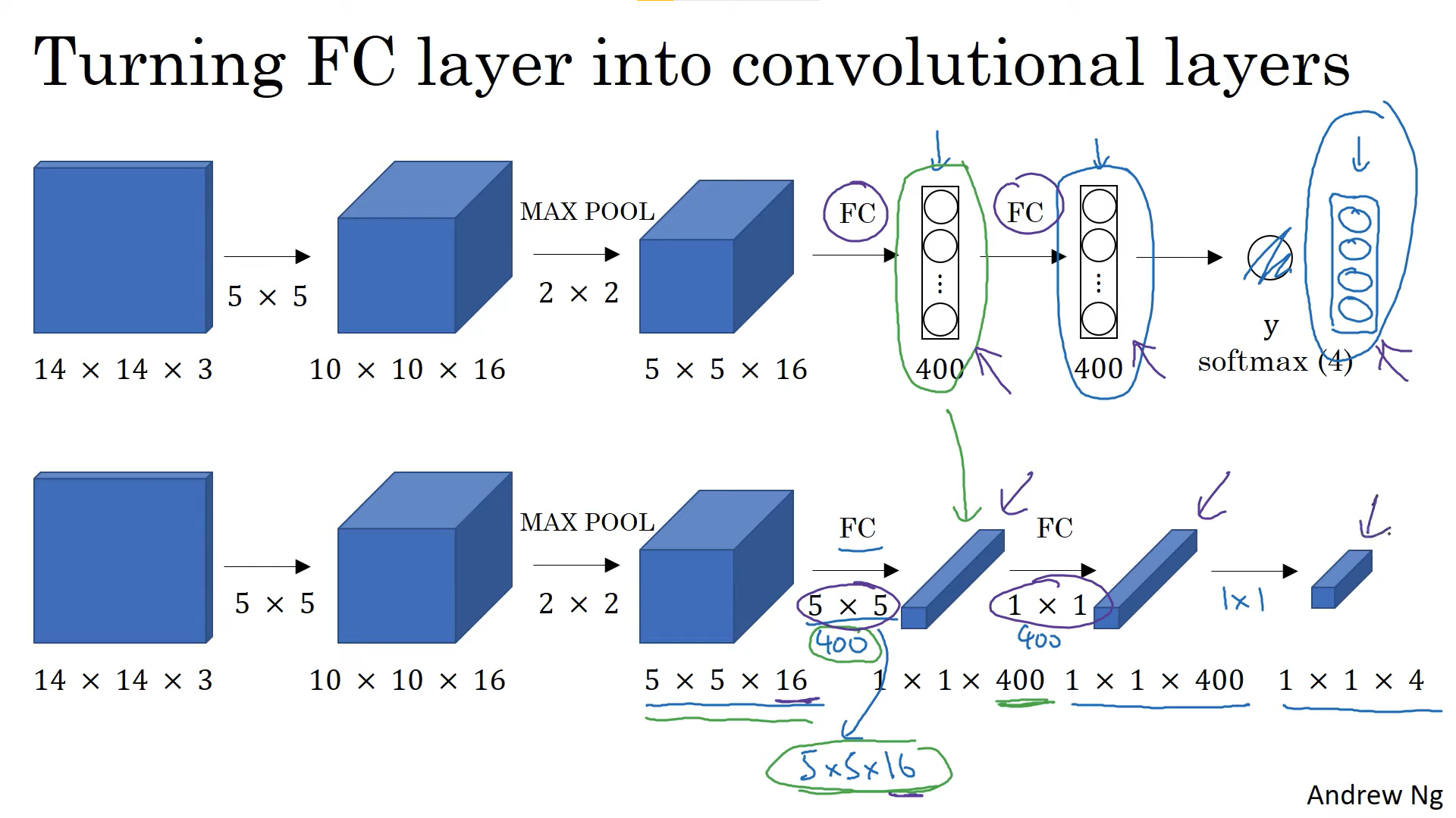
설명은 동영상을 참고 부탁드립니다.😁
Quiz
16x16의 input image를 생각할 때 output에서는 4개의 Bounding box를 얻게 됩니다. 이때 각각의 Bounding box의 좌표는 모두 같은 원점을 기준으로한 것일까요?
- 서로 다른 원점을 기준으로 좌표가 학습됩니다.Window가 sliding함에 따라서 window 내에서 물체의 위치는 바뀌게 됩니다.
- 이때 물체를 표기 하기 위한 bounding box의 원점은 window의 좌측 상단이 원점이 됩니다.

안녕하세요, 답변 해주시면 감사하겠습니다.
쓰신 글 중,
위 그림은 14x14 크기의 입력에 비해 convolution을 수행했을 때, 최종적으로 얻어지는 1x1 사이즈의 출력을 sliding window 영역의 localization 결과라고 해석한다면,
거꾸로 14x14 크기의 receptive field가 바로 sliding window 영역이 되는 효과가 있습니다.
sliding window로 localization을 수행하는 방식처럼 순차적으로 연산이 실행되는 게 아니라 병렬적으로 동시에 진행되므로 convolution은 속도 면에서 훨씬 효율적입니다.
이 부분이 무슨 말인지 이해가 안되어서 질문드립니다.
최종 출력되는 11에 입력 1414의 모든 정보가 들어있다는 말인가요?
그것으로 어떻게 어디에 자동차가 있는지 알수가 있는건가요??