Today I Learned
오늘은 주제에 맞는 초기 베이스라인 모델을 찾기위해 정리 겸 공부를 다시 해보았다.
Collaborative Filtering
CF모델에 대한 정리 기존 내용은 TIL #528과, 심화내용은 TIL #540 참고
-
cold start 문제가 있으며, sparsity가 높으면 추천 성능이 좋지 않다.
 이미지 출처 : just-data
이미지 출처 : just-data
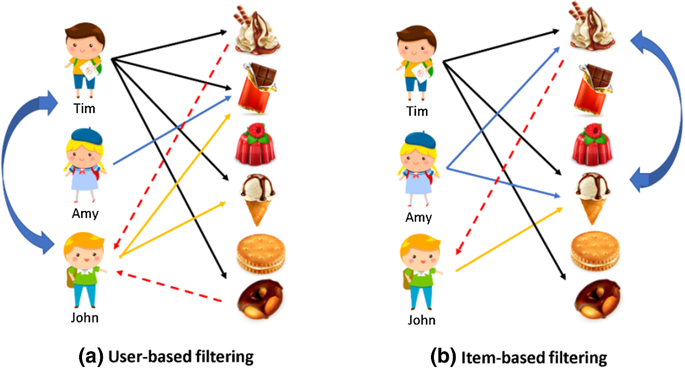
User-Based CF
특정 사용자와 구매 패턴 및 평가가 유사한 사용자들을 먼저 찾아내고, 그들이 선호하는 아이템을 추천하는 방식
-
구현이 상대적으로 간단하다.
-
이웃 사용자들의 평가 변화에 따라 민감하게 반응한다.
-
사용자들의 다양한 취향을 반영해 예상치 못한 추천과 폭넓은 추천이 가능하다.
-
사용자가 늘어날수록 계산량이 기하급수적으로 증가하고, 실시간 추천에서 모든 사용자간 유사도를 계산하는건 비효율적이다.
Item-Based CF
사용자들의 평점이나 구매 이력과 같은 행동 데이터를 기반으로 아이템 간 유사도를 계산하는 방식
-
대부분 시스템에서 유저 수보다 아이템 수가 적어 유저 기반에 비해 빠르다.
아이템 간 유사도는 미리 계산해두고 필요할 때 불러올 수 있어 실시간 처리가 더 효율적이다. -
아이템의 특성은 시간이 지나도 크게 변하지 않기 때문에 새로운 평가가 추가되어도 전체적인 추천 결과가 크게 변하지 않는다. 그래서 다양성이 부족할 수 있다.
사용자의 취향은 시간에 따라 변하지만, 아이템의 특성은 비교적 변화에 안정적이다. -
새로운 사용자가 단 하나의 아이템만 평가해도 즉시 추천이 가능해 cold user에 대해 나름 강건하다.
-
일반적으로 실시간처리와 확장성측면에서 더 효율적이고, 추천결과에 대한 설명이 더 직관적이기 대문에 아이템 기반이 더 널리 쓰인다.
Content-Based Filtering
아이템의 장르, 특성, 설명과 같은 아이템 자체의 속성 정보를 활용하는 방식
- 아이템 기반 CF는 여러 사용자들의 평점 패턴을 통해 아이템 간 유사도를 계산하지만,
컨텐츠 기반은 아이템의 실제 특성(예: 영화의 장르, 배우 등)을 비교하여 유사도를 계산한다.
하이브리드 추천 방식
-
혼합형 하이브리드: 유저기반과 아이템 기반 CF의 결과를 결합해 최종 추천 리스트 생성
기본적으로 각각 독립적으로 실행해 각 방식의 결과에 가중치를 곱해 계산. -
스위칭 하이브리드: 특정 조건이나 컨텍스트에 따라 적합한 방식을 선택
MF
-
유저-아이템 평점 행렬을 저차원의 잠재 요인(latent factor) 행렬로 분해해 관측된 평점 데이터만을 사용하여 모델을 학습하고, 유저와 아이템의 잠재 벡터를 학습하여 평점을 예측
-
희소한(sparse) 데이터에서도 좋은 성능을 보이고, 계산 효율성이 높고 확장성이 좋다.
FM
-
TIL #532 참고
-
다양한 특성(feature)들 간의 상호작용을 모델링
-
SVD+MF로 각 특성을 잠재 벡터로 매핑하여 특성 간 상호작용을 계산한다.
-
매우 희소한 데이터에서도 파라미터 추정이 가능하고 선형 복잡도를 가져 최적화가 용이하다.
NCF
-
TIL #530 참고
-
MF가 가진 선형결합의 한계를 극복하고자 MLP를 도입
-
Cold Start에 대한 대비가 되어있지 않다. 임베딩 레이어가 ID 기반으로 동작하기 때문에 새로운 ID에 대해서는 처리가 불가능
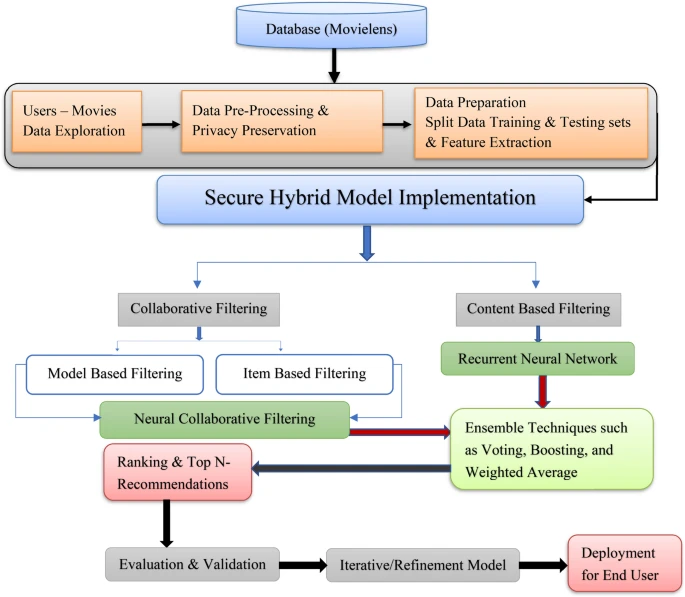
HRS-IU-DL
 이미지 출처 : 논문
이미지 출처 : 논문
-
A deep learning based hybrid recommendation model for internet users (2024)
-
CF+NCF+RNN+CBF 모델
-
데이터셋으로 movielens 100k 사용.
-
TF-IDF로 아이템 속성을 분석해 CBF를 구현하고, 유저의 순차적인 행동패턴을 파악하기 위해 RNN을 사용.
-
CF와 NCF로 전반적인 선호도를 파악
