
요즘에는 YOLO 시리즈가 워낙 잘 되어있지만, gpu 사용이 불가하고 cpu만 사용해야 하는 상황에서는 mobilenet+SSD 를 이용한 object detector도 하나의 선택사항이 될 수 있다.
워낙 만들어진 지 오래돼서인지 ultralytics 처럼 학습할때 최적화가 잘 되어있지 않아 학습 할 때 꽤나 불편했다.
처음에는 caffe build하고 학습하려고 했는데, tensorflow 기반 학습이 좀 더 수월한 것 같아서 그걸로 진행했고, 혹시 같은 고민이라면 아래와 같은 방법으로 한 번 해봐도 좋을 것 같다!
학습 환경 및 설정
python 3.7
tensorflow==1.15
protobuf
tensor 1.x 버전을 필요로 하다보니, 가상환경을 따로 파서 진행하는 것을 권장한다.
다른 라이브러리들은 진행하다 보면 자연스레 설치되기도 하고, 필요하면 추가 설치하면 좋을 것 같다.
protobuf 설치
먼저 tensorflow의 object-detection library에 필요한 protobuf와 필요한 패키지를 다운로드 및 설치해 준다.
# 필요한 패키지 설치
sudo apt-get update
sudo apt-get install -y autoconf automake libtool curl make g++ unzip
# GitHub에서 Protobuf 3.4.0 소스코드 다운로드
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.4.0/protobuf-cpp-3.4.0.zip
# 압축 해제
unzip protobuf-cpp-3.4.0.zip
cd protobuf-3.4.0/
# 구성 파일 생성 (위에서 압축 해제한 protobuf 파일 위치에서 실행)
./autogen.sh
./configure
# 소스 코드 빌드
make
# 빌드된 바이너리 설치
sudo make install
# 설치된 라이브러리 업데이트
sudo ldconfig잘 됐는지 확인하려면 아래와 같이, protoc --version 을 실행해 보자.

설치가 잘 됐으면 해당 설치 버전이 뜨게 될 것이다.
object-detection 설치
원본 object-detection library는 tensorflow github의 해당 링크에 위치해 있다.
그런데 저거 받겠다고 상위 폴더를 다 clone 하는건 너무 번거롭잖아요?
그래서 해당 프로젝트를 위해 필요한 부분만 있는 git repository가 있으니 아래 거를 clone 하면 된다.
[링크] tensorflow-models-object-detection
clone 하고 난 다음, 하위 폴더에 object_detection으로 접근한 다음 아래 명령어를 차례로 실행한다.
protoc object_detection/protos/*.proto --python_out=.
# setup.py
python3 setup.py install추가로, models/research/slim의 slim 또한 미리 install 해 주어야 한다.
# slim install , deployment module 제공
cd models/research/slim
python setup.py install여기까지 설치가 완료되었으면, 학습 환경 설정은 끝났다고 보면 될 것 같다.
학습 데이터 세팅
우선 준비한 학습 데이터와 테스트 데이터의 이미지와 파일을 같은 폴더에 넣는다. (.jpg, .xml 형식)


나는 train_data, test_data 폴더에 각각 넣었다.
이제 이 파일들을 csv 형식으로 변환해주면 되는데, 변환 방법은 기존에 있는 xml_to_csv.py 파일을 실행해주면 된다. (pandas library 필요)
python3 xml_to_csv.pycsv 형태는 아래와 같이 [filename, width, height, class, xmin, ymin, xmax, ymax] 형태로 제공되어야 한다.
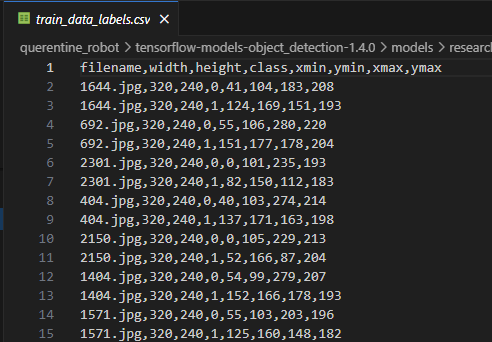
csv 파일이 잘 생성되었으면, 이 csv 파일을 tfrecord 형식으로 변환해 준다.
python3 generate_tfrecord.py --csv_input=data/train_data_labels.csv --output_path=data/train.record
python3 generate_tfrecord.py --csv_input=data/test_data_labels.csv --output_path=data/test.record여기서 protobuf 버전 때문에 특정 에러가 날 수 있는데, 그러면 버전 다운그레이드 해주면 해결 된다.
# protobuf 버전 다운그레이드 하고 tfrecord 다시 실행
pip install protobuf==3.20.*모델 학습 및 저장
base model인 ssd_mobilenet_v1_coco의 특정 버전을 다운로드 받고, 현재 디렉토리에 넣는다.
학습 관련 configuration은 training 폴더의 ssd_mobilenet_v1_custom.config 에서 수정하면 된다. 이 때 멀티클래스를 학습하려면 ssd의 num_class를 꼭 클래스 수 만큼 바꿔주자. (처음에 생각없이 그냥 돌렸다가 단일 클래스로 학습됨 ㅜㅜ.)
config 파일 맨 아랫줄을 보면 label_map_path가 training/object-detection.pbtxt로 되어있을텐데, 데이터셋에 맞게 이 파일을 수정해주자.
이제 진짜 학습 시간!
# 학습 수행
python3 train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_custom.config학습이 잘 진행되면 아래와 같이 loss 정보가 뜨게 될 것이다.
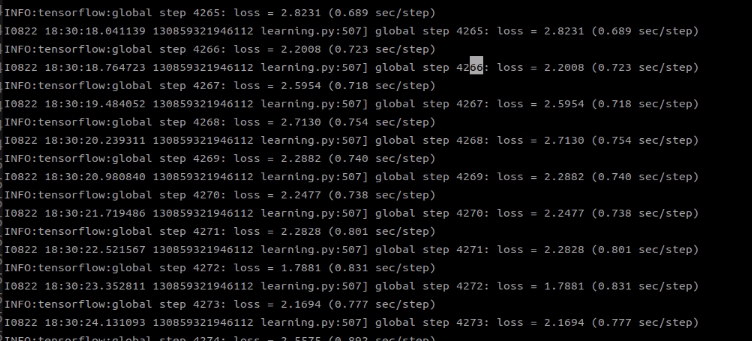
학습이 종료되고 나면, 이제 inference를 위해 export_inference_graph.py 를 실행하자.
python3 export_inference_graph.py --input_type image_tensor --pipeline_config_path training/ssd_mobilenet_v1_custom.config --trained_checkpoint_prefix training/model.ckpt-6074 --output_directory station_inference_graph
# output dir은 새로 저장을 원하는 path로 설정모델이 .pb 형태로 저장된다.

저장한 모델을 테스트해보고 싶으면, test-video-example.py를 실행하면 된다.
해당 파일 내부에 비디오 파일경로, 모델 파일경로 변경 후 사용하자.
python3 test-video-example.py학습이 잘 되어 좋은 결과가 있기를 ^__^* !
덧붙여, 프로젝트 경로에서 아래 명령어를 실행하면, 학습 경과를 모니터링 해 볼 수 있다.
tensorboard --logdir=.