Lecture video link: https://youtu.be/rVfZHWTwXSA
Outline
- Unsupervised learning
- K-means clustering
- Mixture of Gaussian
- EM (Expectation-Maximization) algorithm
- Derivation of GM
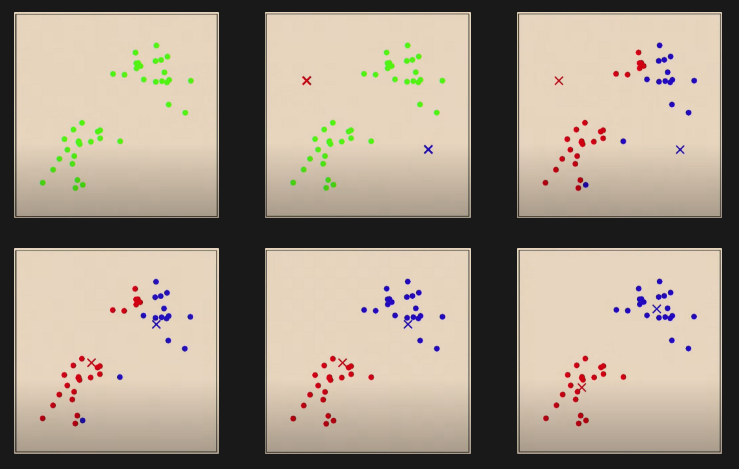
What happens during K-means clustering:
(Source: https://youtu.be/rVfZHWTwXSA?t=2m40s)
K-means Clustering
Data: {x(1),⋯,x(m)}
- Initialize cluster centroids μ1,⋯,μk∈Rd randomly.
- Repeat until convergence:
-
Set c(i):=jargmin∣∣x(i)−μj∣∣
(”color the points”).
-
For j=1,⋯,k,
μj:=i=1∑m1{c(i)=j}i=1∑m1{c(i)=j}x(i)
(”moves the cluster centroids”).
J(↑assignmentsc,μcentroids↓)=i=1∑m∣∣x(i)−μc(i)∣∣2
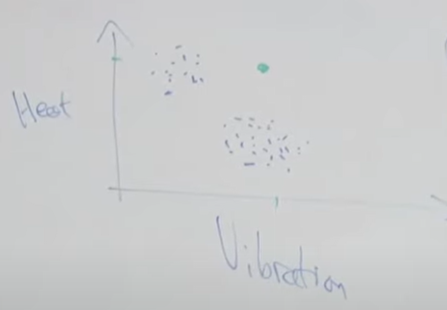
Density estimation
For aircraft engine,
(Source: https://youtu.be/rVfZHWTwXSA?t=17m42s)
Anomaly detection
→ Model p(x)
p(x)<ϵ⇒anomaly.
Mixture of Gaussians model
Problem: When applying an algorithm very similar to GDA to fit a model, the problem with this density estimation problems is that you don’t know which example actually came from which Gaussian.
→ EM algorithm comes in.
Suppose there’s a latent (hidden/unobserved) random variable z, and x(i),z(i) are distributed
p(x(i),z(i))=p(x(i)∣z(i))p(z(i))
where z(i)∼Multinomial(ϕ) and
x(i)∣z(i)=j∼N(μj,Σj).
If we knew the z(i)’s, we can use MLE:
l(ϕ,μ,Σ)ϕjμjΣj=i=1∑mlogp(x(i),z(i);ϕ,μ,Σ)=m1i=1∑m1{z(i)=j}=i=1∑m1{z(i)=j}i=1∑m1{z(i)=j}x(i)=i=1∑m1{z(i)=j}i=1∑m1{z(i)=j}(x(i)−μj)(x(i)−μj)T.
EM (expectation-maximization)
E-step (Guess value of z(i)’s):
Set
wj(i)=p(z(i)=j∣x(i);ϕ,μ,Σ)=l=1∑kp(x(i)∣z(i)=l)p(z(i)=l)p(x(i)∣z(i)=j)p(z(i)=j)
where
p(x(i)∣z(i)=j)=(2π)n/2∣Σj∣1/21exp(−21(x(i)−μj)Σj−1(x(i)−μj)T)p(z(i)=j)=ϕjz∼Multinomial(ϕj)
for every i,j.
M-step:
ϕjμjΣj←m1i=1∑mwj(i)←i=1∑mwj(i)i=1∑mwj(i)x(i)←i=1∑mwj(i)i=1∑mwj(i)(x(i)−μj)(x(i)−μj)T.
wj(i) is how much x(i) is assigned to the μj Gaussian.
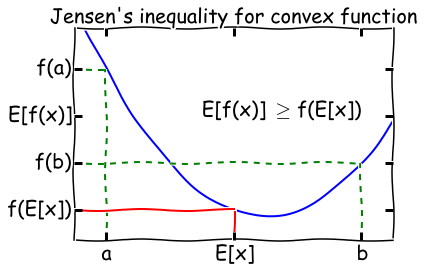
Jensen’s inequality
Let f be a convex function on R (e.g., f’’(x)>0).
Let X e a random variable. Then
f(EX)≤E[f(X)].
(Source: https://people.duke.edu/~ccc14/cspy/14_ExpectationMaximization.html)
Further, if f’’(x)>0 (f is strictly convex), then
E[f(X)]=f(EX)⟺Xis a constant.
Have model for p(x,z;θ).
Only observe x.
l(θ)=i=1∑mlogp(x(i);θ)=i=1∑mz(i)∑logp(x(i),z(i);θ)
Want: θargmaxl(θ).
(Source: https://youtu.be/rVfZHWTwXSA?t=1h3m17s)
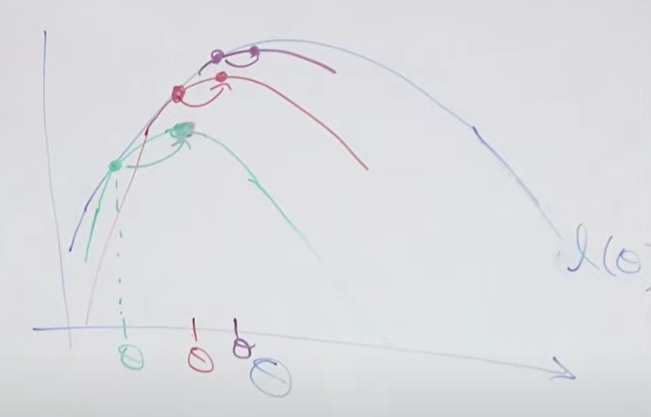
E-step: Construct a lower bound for θ at jth iteration. Draw the green curve in the figure.
M-step: Find the maximum of the green curve and update θ to the maximum.
EM algorithm only does converge to local optimum.
θmaxi∑logp(x(i);θ)=i∑logz(i)∑p(x(i),z(i);θ)=i∑logz(i)∑Qi(z(i))[Qi(z(i))p(x(i),z(i);θ)]=i∑logEz(i)∼Qi[Qi(z(i))p(x(i),z(i);θ)]≥i∑Ez(i)∼Qi[logQi(z(i))p(x(i),z(i);θ)]=i∑z(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ)
where Qi(z(i)) is a probability distribution, i.e., z(i)∑Qi(z(i))=1.
On a given iteration of EM (with parameter θ), we want:
logEz(i)∼Qi[Qi(z(i))p(x(i),z(i);θ)]=Ez(i)∼Qi[logQi(z(i))p(x(i),z(i);θ)].
For the above equation to hold, we need
Qi(z(i))p(x(i),z(i))=constant.
Set Qi(z(i))∝p(x(i),z(i);θ)
z(i)∑Qi(z(i))Qi(z(i))=1=z(i)∑p(x(i),z(i);θ)p(x(i),z(i);θ)=p(z(i)∣x(i);θ).
Summary
E-step:
Set
Qi(z(i)):=p(z(i)∣x(i);θ).
M-step:
θ:=θargmaxi∑z(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ). 
