[Computer Vision] Designing a Practical Degradation Model for Deep Blind Image Super-Resolution
Super Resolution

Designing a Practical Degradation Model for Deep Blind Image Super-Resolution
[Abstract]
본 논문은 무작위로 섞은 blur, downsampling, noise degradations로 구성된, 더 복잡하지만 실용적인 degradation 모델을 설계하였다.
- blur
- isotropic와 anisotropic Gaussian kerenels를 사용한 두 개의 convolutions에 의해 생성된다. - downsampling
- nearest, bilinear, bicubic interpolations 중 무작위로 선택된다. - noise
- 각기 다른 noise level들을 사용한 Gaussian noise를 더함으로써 통합된다.
이 새로운 degradation 모델의 효과를 확인하기 위해 저자들은 deep blind ESRGAN super-resolver를 학습시켰고, 다양한 degradation들로 종합 및 실제 이미지 모두 super-resolve에 적용해 보았다.
[A Practical Degradation Model]
새롭고 실용적인 SISR degradation에 대해 이야기하기 전에 bicubic과 전통적인 degradation 모델에 대해 다음과 같은 사실을 언급하면 도움이 될 것이다.
- 기존의 degradation 모델에 따르면, blur, downsampling, noise 이렇게 3가지 요소가 있는데 실제 이미지의 degradation에 영향을 미친다.
- 저화질 이미지와 고화질 이미지 둘 다 noisy와 blurry가 될 수 있기 때문에 저화질 이미지를 만들기 위한 기존의 degradation 모델로 blur, downsampling, noise를 추가한 pipeline을 사용하는 것은 불필요하다.
- 기존의 degradation 모델의 blur kernel 공간은 규모에 따라 달라야 하므로 실제로는 매우 큰 scale factor를 파악하기가 까다롭다.
- bicubic degradation이 실제 저화질 이미지에는 적절하지 않지만, data augmentation에 사용될 수 있으며, 깨끗하고 선명한 이미지 super resolution에는 좋은 선택이다.
1. Blur
Blur는 이미지 degradation에 흔히 사용된다. 저자들은 고화질 공간과 저화질 공간으로부터 blur를 모델링하는 것을 제안했다.
한편으로는 기존 SISR degradation 모델의 경우, 고화질 이미지는 먼저 blur kernel을 사용한 convolution에 의해 blur 처리가 되었다. 사실 이 고화질 blur의 목적은 aliasing 되는 것을 방지하는 것과 그 다음에 있는 downsampling 후 더 많은 공간적 정보들을 보존하는 것이다. 또 다른 한편으로, 실제 저화질 이미지는 흐릿하게 될 수 있어서 저화질 공간에서 이러한 흐림을 모델링하는 것은 실현 가능한 방법이다.
저자들은 Gaussian kerenls이 SISR 작업을 수행하기에 충분하다는 것을 고려하여, isotropic Gaussian kerenls(Biso)와 anisotropic Gaussian kernel(Baniso) 이 2개의 Gaussian blur를 수행하였는데, 이를 통해 blur의 degradation 공간이 매우 확장될 수 있었다.
- Blur kernel setting
- size = [7x7, 9x9, ... , 21x21] 중에서 균등하게 추출됨
- isotropic Gaussian kerenl
- kernel width
- scale이 2일 경우, [0.1, 2.4] 중에서 추출됨
- scale이 4일 경우, [0.1, 2.8] 중에서 추출됨
- kernel width
- anisotropic
- rotation angle
- [0, π] 중에서 추출됨
- scale이 2일 경우, 각 축(axis)의 길이는 [0.5, 6] 중에서 추출됨
- scale이 4일 경우, 각 축(axis)의 길이는 [0.5, 8] 중에서 추출됨
- rotation angle
2. Downsampling
고화질을 저화질로 downsample하기 위한 직접적인 방법은 nearest neighbor interpolation이다. 하지만 이렇게 만들어진 저화질의 경우 왼쪽 위의 모서리쪽에 0.5x(s-1) 픽셀의 조정불량(misalignment) 문제가 생길 것이다. 이것에 대한 해결책으로써 저자들은 2D linear grid interpolation 방법을 통해 21x21 isotropic Gaussian kerenl 중심을 0.5x(s-1) 픽셀만큼 이동시켰고, 이것을 nearest neighbour downsampling 전 convolution에 적용하였다. Gaussian kernel의 넓이는 Baniso kernel의 넓이로 설정하였다.
- nearest downsampling => 'D S nearest'
- bicubic downsampling => 'D S bicubic'
- bilinear downsampling => 'D S bilinear'
- down-up smapling => 'D S down-up'
저자들은 고화질을 downscale하기 위해 네 가지 downsampling 중에서 균등하게 추출하였다.
3. Noise
- Gaussian noise
- (Σ = σ^2I) => widely-used channel independent AWGN model
- (Σ = σ^21) => widely-used gray-scale AWGN model
- 3D zero-mean Gaussian noise modelI = identity matrix
1 = 3x3 matrix with all elements equal to one
새로운 degradation 모델에서 저자들은 데이터 통합을 위해 Gaussian noise를 추가하였고, 그 중 3D zero-mean Gaussian noise model은 0.2, channel independent AWGN model과 gray-scale AWGN model은 각각 0.4씩 확률을 적용하였다.
-
JPEG compression noise
JPEG은 대역폭과 저장량 감소를 위해 가장 널리 쓰이는 이미지 압축 기준이다.- JPEG 품질 요소 = [30, 95]
JPEG 품질 요소는 0~100의 값으로, 0에 가까울수록 high compression & low quality이며, 100에 가까울수록 low compression & high quality이다.
-
Processed camera sensor noise
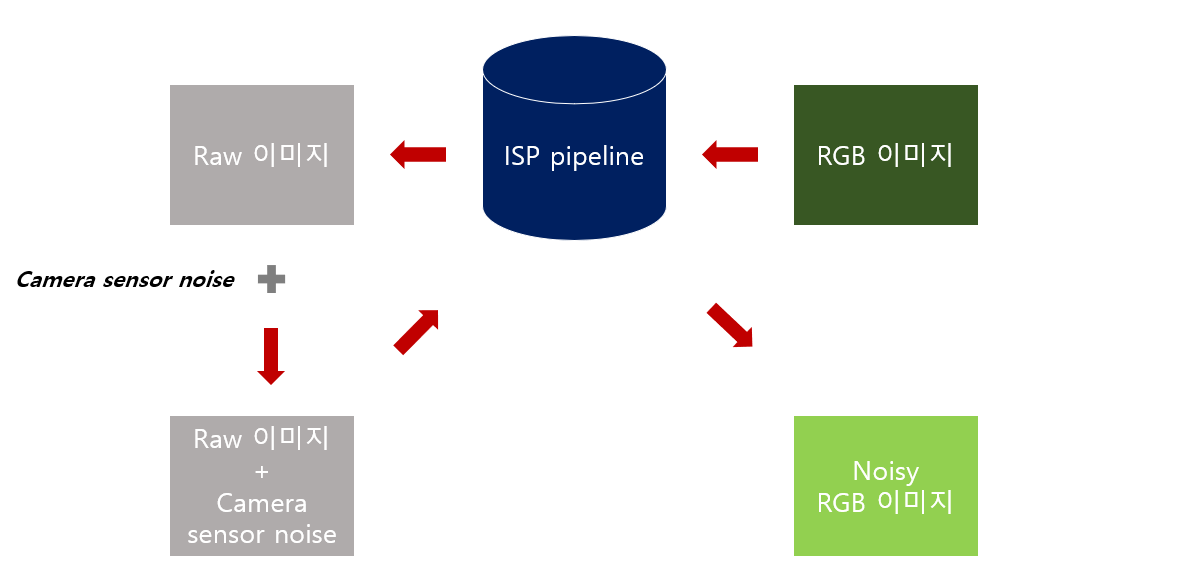
먼저 reverse ISP pipeline을 통해 RGB 이미지로부터 raw 이미지를 얻은 후, camera sensor noise를 만들어진 raw 이미지에 추가한 후 ISP pipleine을 통해 noisy RGB 이미지를 복원한다.ISP pipeline은 5가지 종류로 구성되어 있다.
1. demosaicing
- matlab의 demosaic fuction과 같은 방법으로 사용되었다.
2. exposure compensation
- global scaling은 [2^-0.2, 2^0.3] 중에서 선택되었다.
3. white balance
- red gain과 blur gain은 [1.2, 2.4] 중에서 선택되었다.
4. camera to XYZ(D50) color space conversion
- 3x3 color correction matrix는 raw 이미지 파일의 metadata에서 ForwardMatrix1과 ForwardMatrix2의 무작위 가중치 조합이다.
5. tone mapping and gamma correction
- 쌍으로 구성된 raw 이미지 파일과 RGB output을 기반으로 각 카메라에 대해 논문 What is the Space of Camera Response Functions?에서 가장 적합한 tone curve를 수동으로 선택했다.
4. Random Shuffle
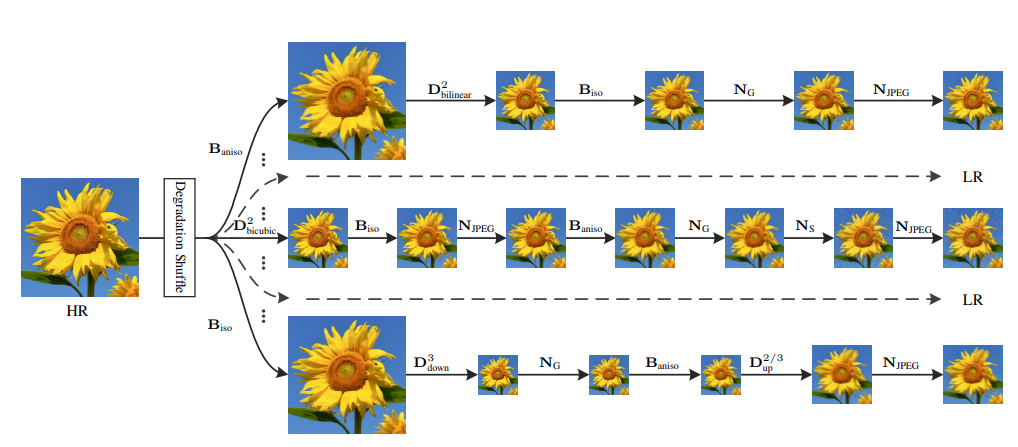
위의 도식에 있는 제안된 degradation 모델은 scale factor 2에 대한 것이다. 고화질 이미지에서 무작위로 섞은 degration sequence(Biso, Baniso, D2, Ng, Njpeg, Ns)가 먼저 진행된다. 그 다음, 저화질 이미지를 JPEG 형식으로 저장하기 위해 JPEG 압축 degration(Njpeg)가 적용된다. scale factor 2를 사용한 downscaling operation(D2)는 [D2 nearest, D2 bilinear, D2 bicubic, D2 down-up] 중에서 선택된다.
[Some Discussions]
제안한 새로운 degradation 모델을 더욱 잘 이해하기 위해 일부 논의를 추가할 필요가 있다.
첫 번째, 해당 degradation 모델은 주로 저하된(degraded) 저화질 이미지들을 종합하도록 설계되었다. 이것의 가장 직접적인 용도는 저화질 및 고화질 이미지를 포함하는 deep blind super-resolver를 학습하는 것이다. 특히, 본 degradation 모델은 제한된 데이터나 정렬되지 않은 방대한 고화질 이미지 데이터셋을 기반으로 완벽하기 정렬된 학습 데이터를 무한히 생성할 수 있다.
두 번째, 너무 많은 degradation 매개변수와 무작위로 섞는 전략을 포함하고 있기 때문에 제안된 degradation 모델은 저하된 저화질 이미지에 적용되지 않습니다.
세 번째, degradation 모델이 특정 실제 장면(scene)의 극단적인 degradation을 유발할 수 있지만, 이는 여전히 deep blind 이미지의 일반화 성능을 개선하는 데 기여한다.
네 번째, DNCNN과 같이 다양한 degradation을 처리할 수 있는 단일 모델을 갖춘 대용량 DNN은 다양한 확대, JPEG 압축 정도, 다양한 noise level을 처리할 수 있으며 VDSR에서 상당한 성능을 발휘한다.
다섯 번째, degradatio 매개변수들을 조정함으로써 특정 애플리케이션에 대한 실용성을 향상시키기 위해 더 합리적인 degradation 유형들을 추가할 수 있다.
[Deep Blind SISR Model Training]
이 논문의 색다른 점은 새로운 degradation 모델과 ESRGAN과 같은 기존 네트워크 구조를 차용하여 deep blind 모델을 학습시키는 것에 있다. 제안된 degradation 모델의 장점을 보기 위해, 저자들은 널리 사용되는 ESRGAN 네트워크를 채택하고, 새로운 degradation 모델에서 생성된 합쳐진 두 저화질 및 고화질 이미지를 사용하여 학습시켰다.
저자들은 먼저 PSNR 지향적인 BSRNet 모델을 학습시키고, 지각 품질 지향적인 BSRGAN 모델을 학습시켰다. PSNR 지향적인 BSRNet 모델은 pixel-wise 평균 문제로 인해 과도하게 매끄러운(oversmooth) 결과를 만드는 경향이 있기 때문에 실제 적용에서는 지각 품질 지향적인 모델인 BSRGAN이 선호된다. 따라서 저자들은 BSRGAN 모델에 집중하였다.
ESRGAN과 비교하여 BSRGAN은 몇 가지 방법으로 수정되었다.
1. 이미지 prior를 캡쳐하기 위해 먼저 약간 다른 고화질 이미지 데이터셋을 사용했다.
(DIV2K, Flick2K, WED, FFHQ의 2,000개 얼굴 이미지)
그 이유는 BSRGAN의 목표는 다용도의 blind 이미지 super resolution 문제를 해결하는 것이며, degradation prior 외에도 한 이미지 prior는 super-resolver의 성공에 기여할 수 있기 때문이다.
2. BSRGAN은 72x72의 큰 저화질 patch size를 사용한다.
그 이유는 본 degradation 모델이 bicubic degradation을 통해서 만들어진 저화질 이미지 보다 더 심하게 저하된 저화질 이미지를 생성할 수 있기 때문이다. 그리고 큰 patch는 더 나은 복원을 위해 더 많은 정보를 캡쳐할 수 있다.
3. L1 loss, VGG percepture loss, PatchGan loss의 가중치 조합을 최소화하여 BSRGAN을 학습시켰다.
(L1 loss weight = 1, VGG percepture loss weight = 1, PatchGAN loss weight = 0.1)
특히 VGG percepture loss는 super-resolved 이미지의 색상 변화 문제를 방지하는 것이 더 안정적이기 때문에 미리 학습된 19-layer VGG 모델의 네 번째 maxpooling layer 전, 네 번째 convolusion에서 실행된다.
저자들은 learning rate를 0.00001로 고정시켰고, batch size는 48로 하여 Adam optimizer와 함께 BSRGAN을 학습시켰다.
optimizer = Adam
learning rate = 0.00001
batch size = 48
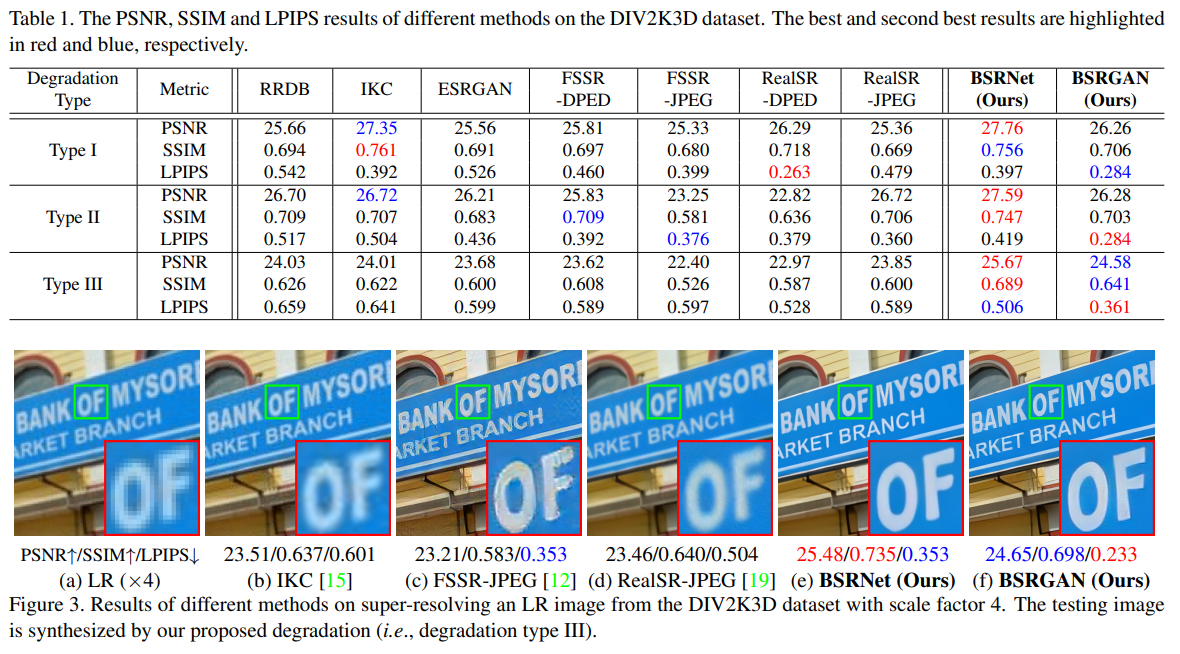
[Experimental Result]