Faster R-CNN Paper Review - An End-to-End Solution for Efficient Object Detection
Computer Vision

Summary
Faster R-CNN combines a Region Proposal Network with Fast R-CNN, enabling a fully end-to-end, CNN-based approach to generating high-quality region proposals and performing object classification and bounding-box regression. This design significantly improves both accuracy and speed compared to traditional proposal methods like Selective Search.
Introduction
Conventional two-stage detection approaches often rely on external region proposal algorithms (e.g., Selective Search, Edge Boxes) for candidate regions before classification. Although effective, these approaches are computationally expensive and relatively slow. Faster R-CNN addresses these shortcomings by learning region proposals directly via a CNN, offering an end-to-end and more efficient pipeline.
Object Detection with Faster R-CNN
Model Overview:
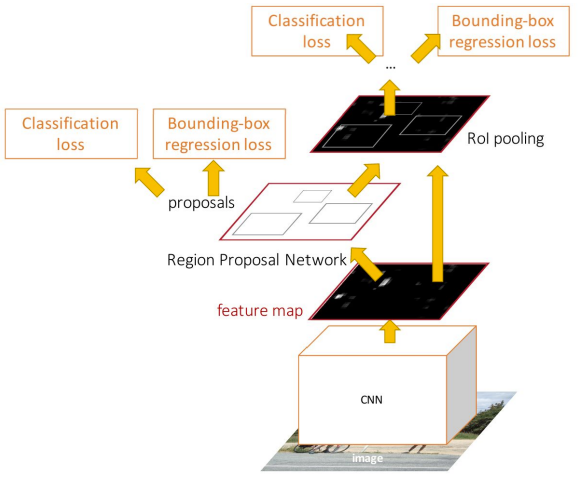
- 1. Input Image → Shared Convolutional Layers
- Pass the input image through a CNN backbone (e.g., ZF or VGG16) to extract a shared convolutional feature map.
- 2. Region Proposal Network (RPN)
- Slides over the feature map to generate candidate object proposals (anchors) and corresponding objectness scores.
- 3. RoI Pooling
- Map each proposed region back onto the shared feature map, then apply RoI Pooling to obtain fixed-sized feature maps for each region.
- 4. Fast R-CNN Head
- Feed these pooled features into Fully Connected Layers (FCLs) for final classification and bounding-box regression.
Faster R-CNN Workflow
- Step 1: Input image → CNN Backbone → Convolutional feature map
- Step 2: RPN → Generate region proposals (anchor boxes + objectness scores)
- Step 3: RoI Pooling → Project proposals onto the shared feature map, then pool into a fixed size
- Step 4: Classification & Bounding-Box Regression → Output final labels and refined boxes
Detailed Architecture of Faster R-CNN
1. Region Proposal Network (RPN)
The RPN is the cornerstone of Faster R-CNN by replacing traditional region proposal methods like Selective Search. Sharing convolutional layers with Fast R-CNN significantly reduces computational overhead.
RPN Workflow
1. Sliding Window: A small n×n (e.g., 3×3) sliding window is applied to the shared feature map to extract local features.
2. Anchor Boxes: For each sliding window position, k anchor boxes (e.g., 9 anchors) with different scales and aspect ratios are generated.
3. Binary Classification: Each anchor (2k outputs) is classified as an “object” or “background.”
4. Bounding-Box Regression: Each anchor (4k outputs) is refined by predicting offsets (x, y, w, h) to best fit the object.
Why RPN Matters
- Replaces slow region proposal algorithms (e.g., Selective Search).
- Shares convolutional layers with Fast R-CNN, minimizing extra computation.
- Handles various object sizes/aspect ratios using multiple anchors.
Non-Maximum Suppression (NMS) After RPN
Once the RPN outputs objectness scores and refined boxes, an NMS step is applied to remove highly overlapped proposals that likely refer to the same object. This reduces redundancy and yields a more compact set of candidate regions.
2. Fast R-CNN Head
Once the RPN generates high-quality proposals, the Fast R-CNN head processes these proposals via RoI Pooling to produce fixed-sized feature maps.
It then performs:
-
Multi-Class Classification: Determines the object category (plus background).
-
Bounding-Box Regression: Further refine each proposal to match ground truth coordinates.
By combining the RPN for region proposals and Fast R-CNN for detection, Faster R-CNN forms a unified, fully CNN-based framework for end-to-end object detection.
3. Anchor Box
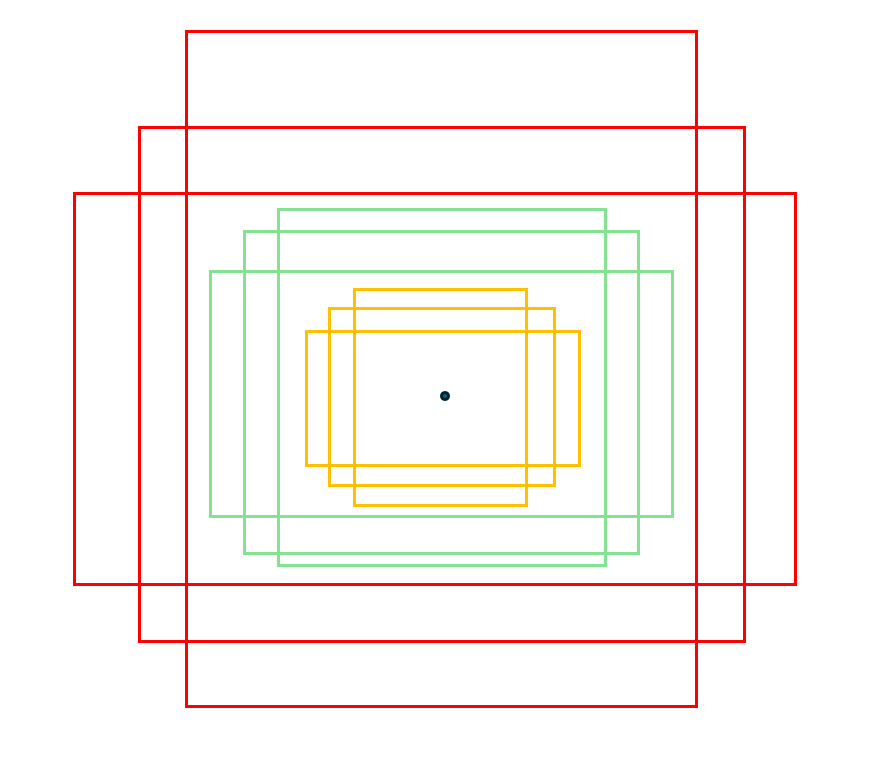
What are Anchor Boxes?
-
Anchor boxes are predefined bounding-boxes of various shapes and sizes placed at each position of the feature map.
-
In practice, 3 scales x 3 aspect ratios = 9 anchors per position.
-
Single-scale features, multi-scale predictions— each anchor has its own prediction function.
Positive and Negative Anchors
- Positive anchors: those whose IoU with a ground truth box is above a certain threshold (e.g., 0.7).
- Negative anchors: those whose IoU with every ground truth box is below a lower threshold (e.g., 0.3).
Outputs of RPN:
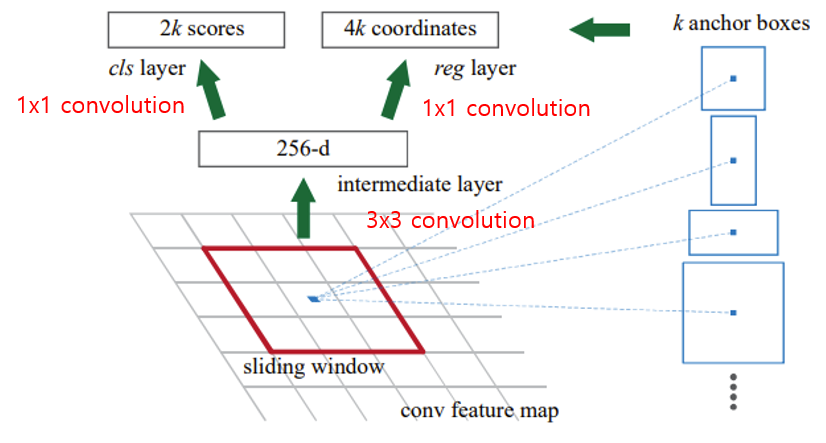
- Objectness Scores
- For each anchor, the RPN outputs the probability of containing an object vs. not containing an object (18 outputs for 9 anchors).
- Bounding-Box Refinements
- For each anchor, the RPN predicts 4 offsets (x, y, w, h) to fine-tune the anchor location and size (36 outputs for 9 anchors).
4. RPN Loss Function
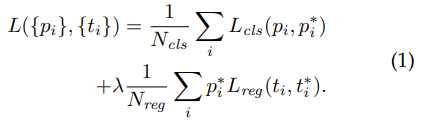
The RPN loss function typically consists of two parts:
1. Classification Loss
- A binary classification between object(positive anchor) and background(negative anchor).
2. Regression Loss
-
A smooth L1 loss on the predicted offsets (x,y,w,h) to align each positive anchor with its corresponding ground truth box.
-
Only positive anchors contribute to the regression loss, while all anchors (positive + negative) are used for classification.
Training and Optimization
Faster R-CNN employs a two-step training process:
-
1) Alternating Training
RPN and Fast R-CNN are trained alternately to allow the RPN to generate better proposals. This iterative process improves both RPN and Fast R-CNN in tandem.- Step 1. Train RPN alone to generate high-quality proposals.
- Step 2. Use the RPN proposals to train Fast R-CNN.
- Step 3. Fine-tune RPN again with updated Fast R-CNN weights.
- Step 4. Retrain Fast R-CNN.
-
2) End-to-End Training
After the alternating steps, Faster R-CNN can be fine-tuned jointly, optimizing the shared layers, RPN, and detection head end-to-end for better performance and efficiency.
Conclusion
Faster R-CNN incorporates the RPN and Fast R-CNN into a unified, fully CNN-based pipeline, delivering significant improvements in both speed and accuracy for object detection. By sharing convolutional features for both proposal generation and classification, it eliminates the need for slow external proposals and achieves near real-time performance. This framework has laid the groundwork for many subsequent two-stage detectors. I believe this architectural design offers ample room for further studies and may serve as a guiding blueprint for future research.
Performance
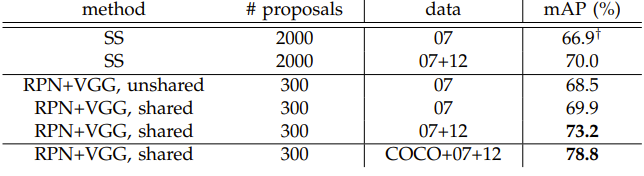
- As illustrated in the first image, Faster R-CNN drastically reduces the number of region proposals compared to Selective Search-based methods (SS). It minimizes computational overhead while improving detection quality.

- By replacing slow proposal methods with the RPN, the system's frame rate increases from around 0.5 to about 5 fps on VGG16 and even higher with more efficient models.
References
Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149.
https://doi.org/10.1109/tpami.2016.2577031
Li, F.-F., Jonhson, J., & Yeung, S. (2017). Lecture 11: Detection and segmentation. https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
