BoostCamp
1.부스트캠프 week1 day1

우리는 부스트캠퍼!첫 주차는 기본적으로 precourse에서 진행한 내용을 다시 반복하는 교육 과정이었다.기본적인 Python Programming을 위한 환경 설정부터 Pythonic Code작성법까지 무난하게 다룬다. 첫 주차에서 배우는 내용 중 Python pro
2.부스트캠프 week1 day2
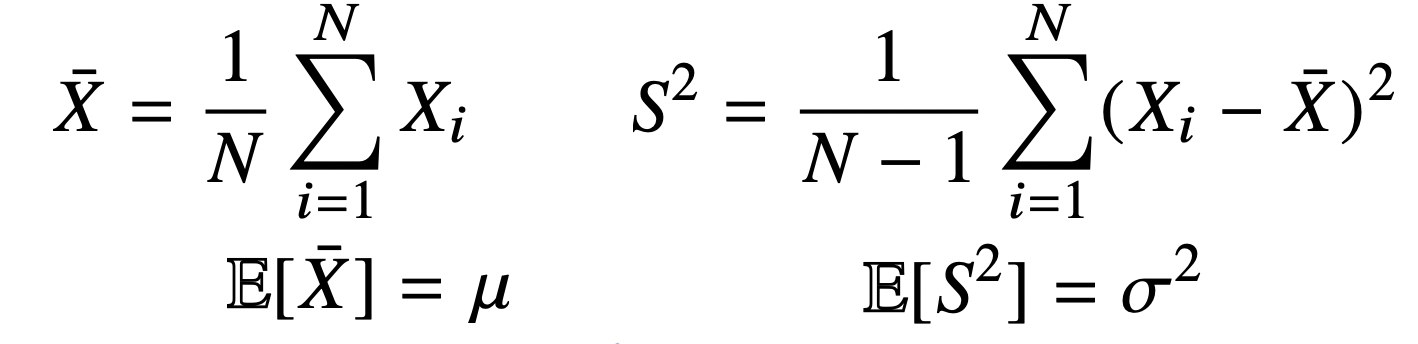
딥러닝 : 확률론 기반의 기계학습 이론에 바탕손실함수(Loss Function)은 데이터 공간을 통계적으로 해석해서 유도회귀 분석에서 손실함수로 사용되는 L2 norm은 예측 오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도분류 문제의 Cross Entropy는
3.부스트캠프 week1 day3
어떤 식으로 모수를 추정하는지에 필요한 베이즈 정리를 알아보자.오늘날 기계 학습을 이용한 예측 모형에 많이 사용되는 방법론 중 하나이다.조건부 확률이란?베이즈 통계학을 이해하기 위한 기본 개념$P(A\\cap B) = P(B)P(A|B)$베이즈정리, 조건부확률을 이용하
4.부스트캠프 week1 day4
Convolution 연산은 MLP와 다르게 커널을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조이다.입력 벡터를 모두 활용하는 것이 아니라 커널 사이즈만큼 움직여가면서 계산하는 것이며, MLP의 가중치 행렬은 i에 따라 변하는 반면 Convoluti
5.부스트캠프 week1 day5
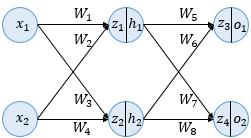
인공 신경망은 입력층, 은니층, 출력층 이렇게 3개의 층을 가진다.위 예제에서는 두 개의 입력, 두 개의 은닉층 뉴런, 두 개의 출력층 뉴런을 사용한다. 모든 뉴런은 활성화 하수로 시그모이드 함수를 사용한다.은닉층과 출력층의 뉴런에서 변수 z가 존재하는데ㅡ 여기서 변수
6.부스트캠프 week1 추가학습
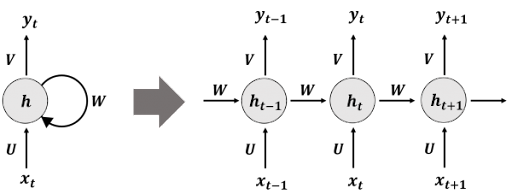
RNN에 대한 이해를 돕기 위하여 다양한 분야의 참고자료들을 정리해보았다.해당 링크들에서 RNN기본 개념부터 BPTT, 그 이상의 개념까지 이해할 수 있도록 영어로 작성해놓았다.Wikidocs - RNN한국어로 정리되어 있으니 처음 공부할 때 도움될 수 있을 것이다.D
7.부스트캠프 week1 RNN 추가학습 Wikidocs
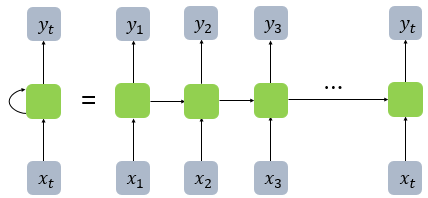
RNN,순환 신경망은 시퀀스 데이터들을 처리하기 위해 고안된 모델들 중 하나다. RNN은 그 중에서 가장 기본적인 딥러닝 시퀀스 모델이다. 나중에 배우게 될 LSTM이나 GRU또한 근본적으로 RNN에 속한다.MLP은 전부 은닉층에서 활성화 함수를 지난 값이 오직 출력층
8.부스트캠프 week1 추가학습 Gradient Vanishing, Exploding

이 내용에 대한 지식이 제대로 머리속에 정리되지 않아 한 번 정리하는 시간을 가지려 한다. 기울기 소실은 역전파 과정에서 입력층으로 갈수록 Gradient가 점차적으로 작아지는 현상을 말한다. 활성화 함수로 자주 사용되는 Sigmoid와 같은 여러 함수의 특성이, 미분
9.부스트캠프 week1 RNN 추가학습 D2L

Dive into Deep Learning 교재의 BPTT부분을 발췌하여 학습하고자 한다.BPTT는 교재 8단원 7절에 해당한다. 1~6절 앞부분을 미리 읽고 와도 도움이 될 듯하다. 이번 글에서는 RNN에서 시퀀스 모델에 대한 역전파 알고리즘의 디테일에 대해 알아보고
10.부스트캠프 week2 day1 MLP

딥러닝에서 중요한 것은 역시 구현실력이다.필수적인 수학 지식은 확률론이나 선형대수학이 필요하다.현재 어떤 트렌드, 어떤 논문이나 연구들이 발표되었는지 아는 것도 중요하다.사람들마다 다르겠지만, 사람의 지능을 모방하는 것.인공 지능 안에 Machine Learning이
11.부스트캠프 week2 PyTorch
nn.Module을 상속받는다.nn.Linear(in_features, out_features)입력받은 dimension 정보를 바탕으로 선형 변환을 진행하는 클래스init_param 함수(nn.init 활용) pytorch는 nn.Linear에서 자동으로 initi
12.부스트캠프 week2 day2 Optimizer
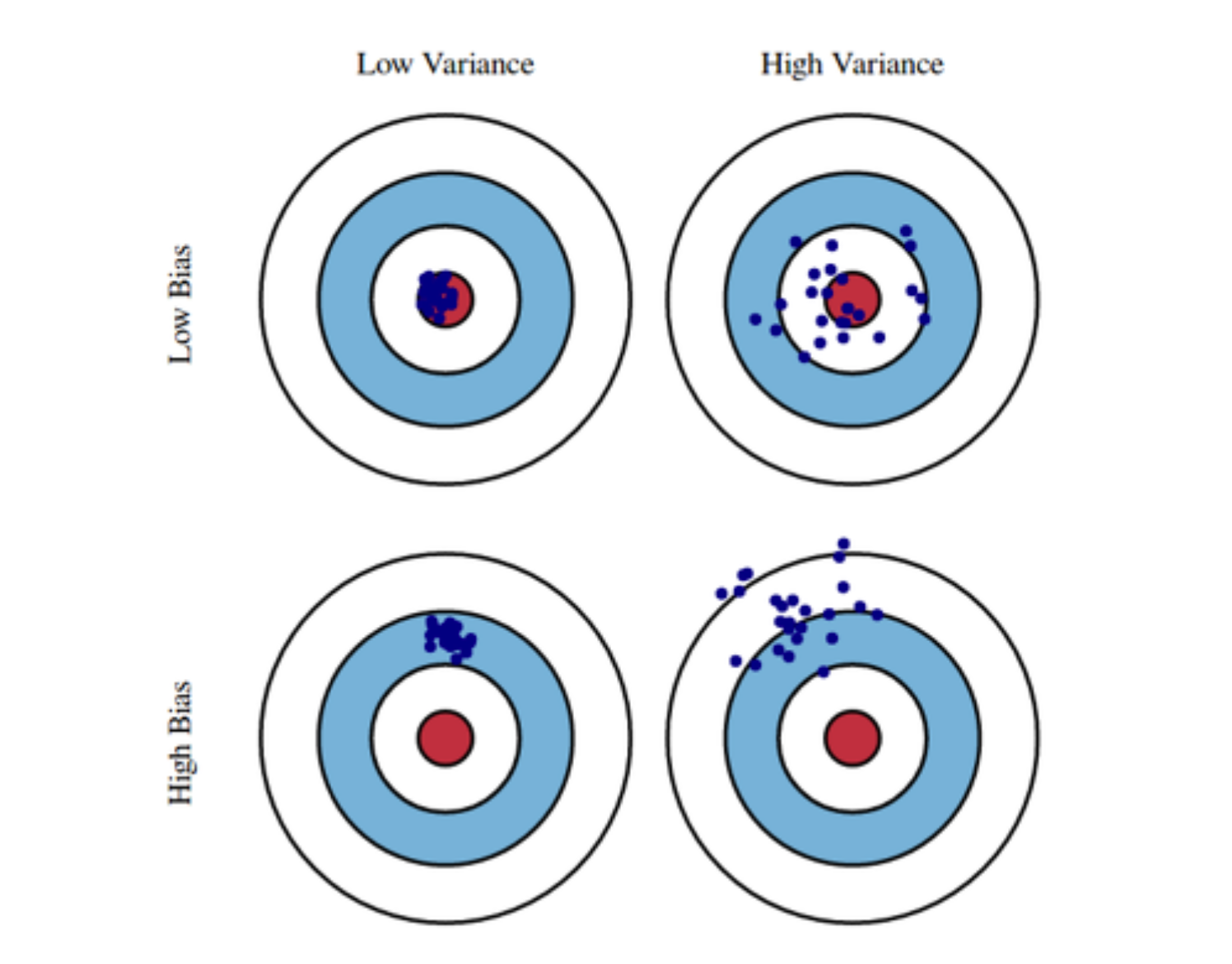
OptimizationGradient DescentFirst-order iterative optimization algorithm for finding a local minimum of a differentiable function일반화 성능을 높이려고 보통 노력한다.
13.부스트캠프 week2 심화 주제
1편2편3편
14.부스트캠프 week2 day3 CNN
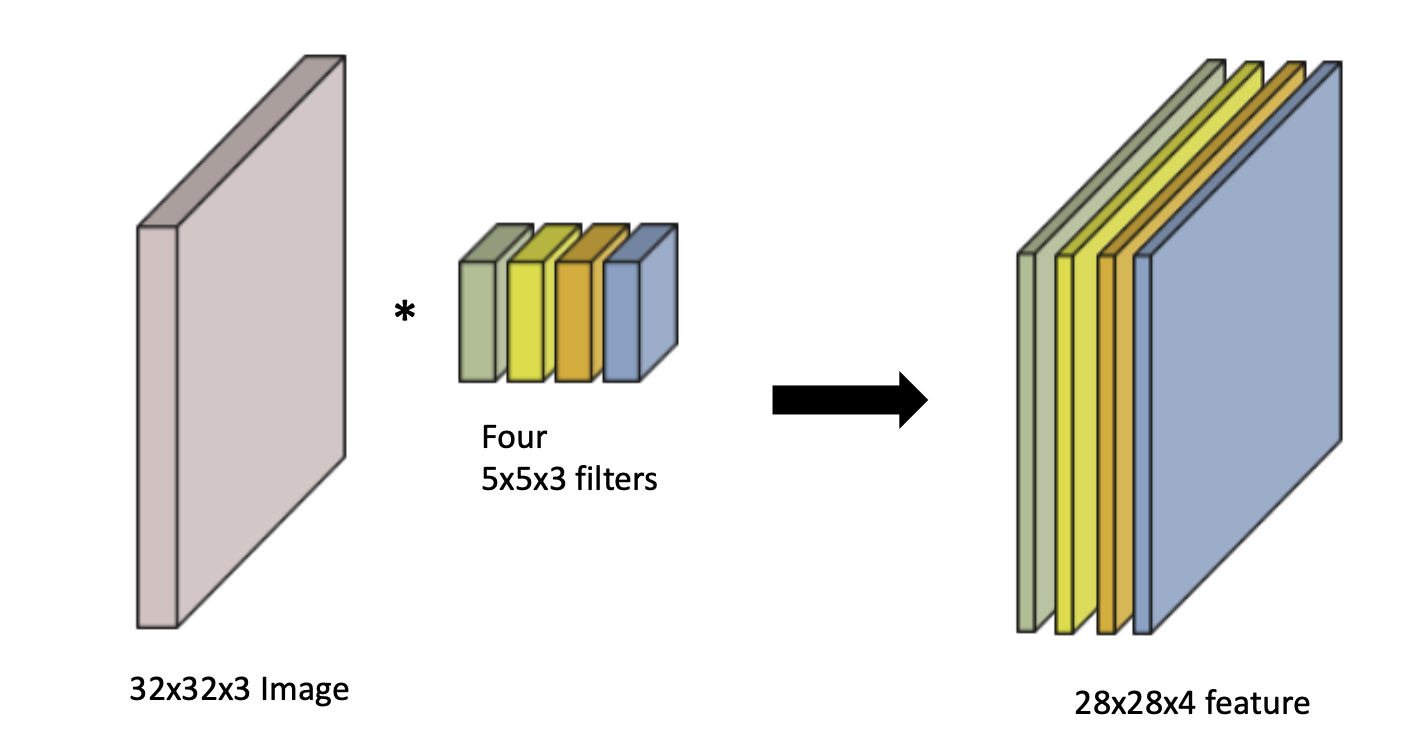
(RGB는 3채널)Input Channel과 output convolution feature map의 channel을 알면 여기에 적용되는 convolution feature의 크기 역시 알 수 있다.파라미터의 숫자를 잘 보자.첫 번째 CONV에서는 4개의 5x5x3
15.부스트캠프 week2 추가학습 추천알고리즘
추천알고리즘
16.부스트캠프 week2 day4 RNNs

현재 일어나는 일은 바로 직전의 일에만 관련이 있다고 가정. (현실적이지는 않음)많은 정보를 버리게 된다. 가장 큰 장점은 Joint Distribution을 설명하는데 편리하다는 장점이 있다.H(hidden state)가 과거의 정보를 담고 있고 현재 시점에서 H의
17.부스트캠프 week2 day5 GAN
그저 단순히 무언가를 생성하는 것만이 아닌 많은 것을 포함하는 개념강아지의 이미지들이 주어졌다고 가정했을 때, 확률 분포 $p(x)$에 대하여 아래와 같은 것을 학습하는 것이 목표이다.Generation$x\_{new}$ ~ $p(x)$로 sampling했을 때, 강아
18.부스트캠프 week2 추가학습 GANs
강의 영상을 참고하여 공부하였습니다.블로그와 Stanford CS231 lecture를 참조하였습니다.실험 결과 자료는 여기를 참조했습니다.
19.부스트캠프 week2 추가학습 LSTM With ResNet, DenseNet
블로그와 Stanford CS231 lecture를 참조하였습니다.실험 결과 자료는 여기를 참조했습니다.
20.부스트캠프 week2 추가학습 Seq2Seq/Attention /Self-Attention
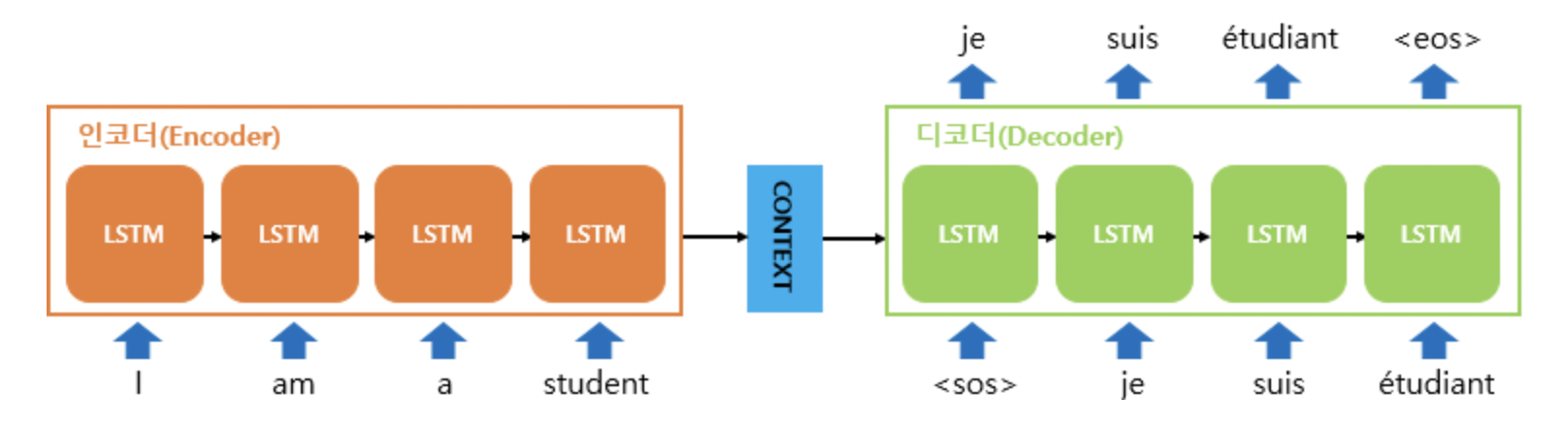
Seq2SeqAttentionTransformer
21.부스트캠프 Week3 Pytorch(1)
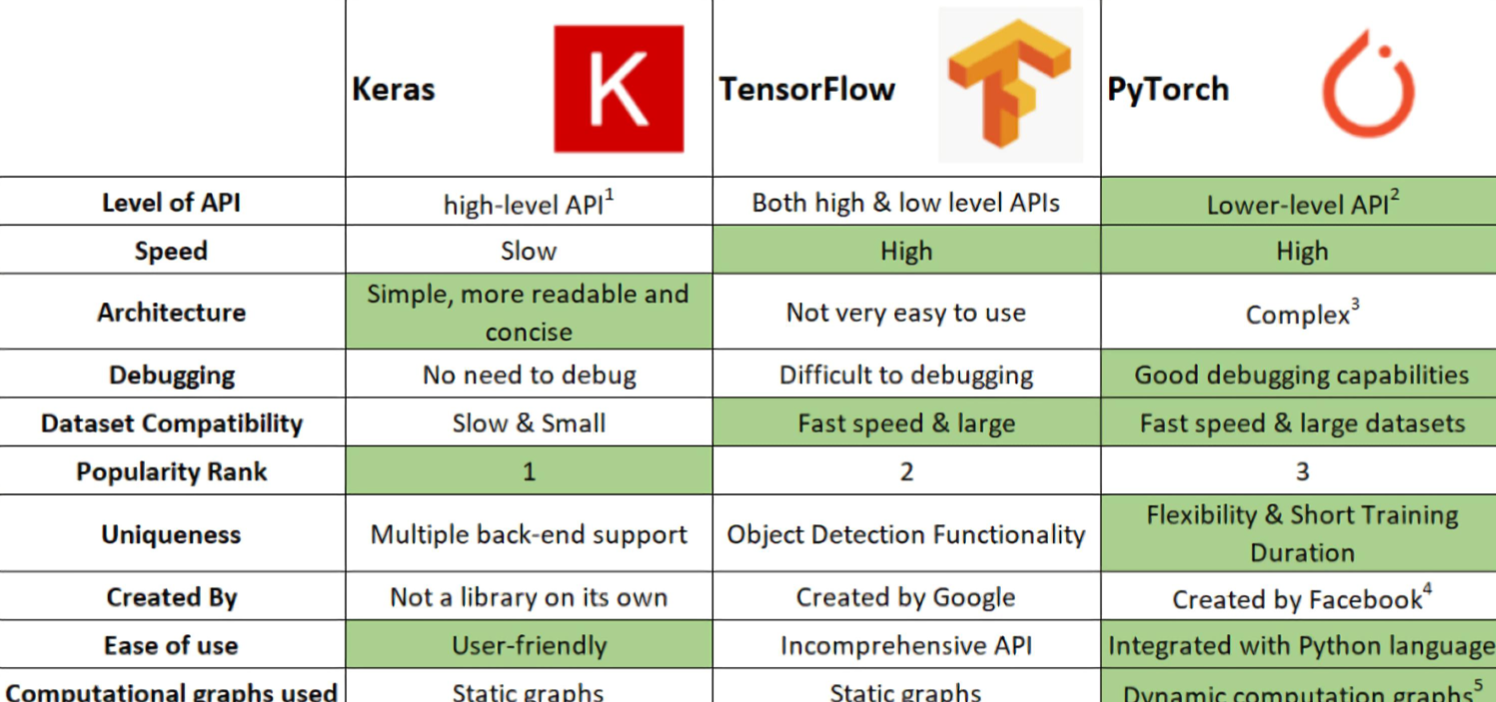
Dataset & Dataloader
22.부스트캠프 Week3 Pytorch(2)
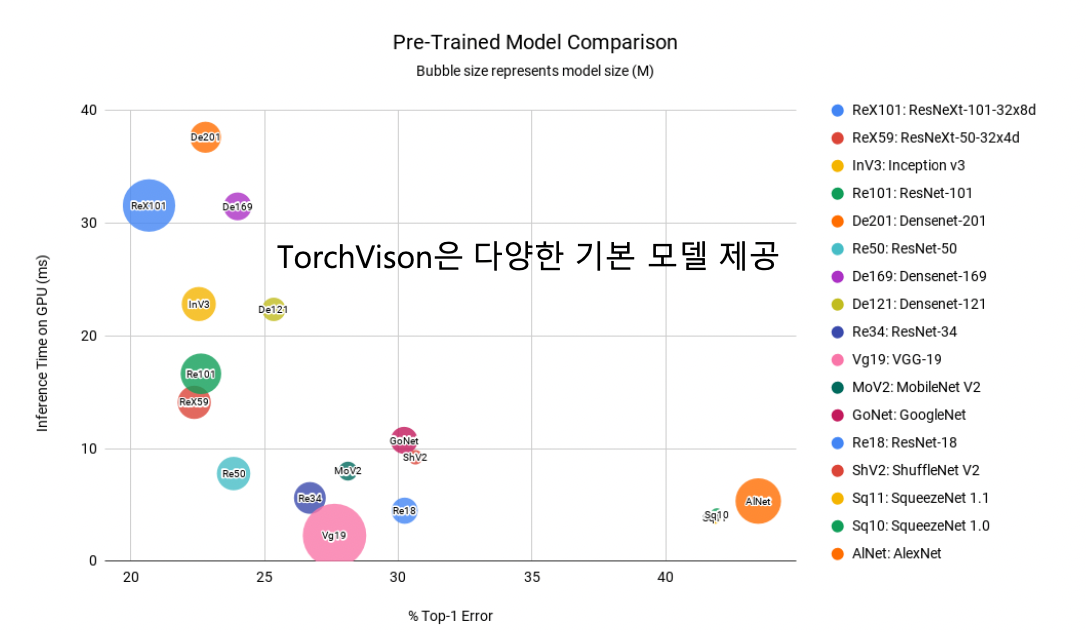
PyTorch Troubleshooting