1. 데이터 분석 및 라이브러리 사용
데이터 베이스
데이터를 일시적으로 사용하지 않고 오랫동안 사용할 수 있도록
1) 이해 및 통계 기초
범위가 굉장히 넓어서 범위를 줄였다
2) 데이터 분석을 위한 라이브러리
기술통계 위주의 function들 배울 예정
3) 공공데이터를 이용한 EDA 분석(주로 Pandas)
데이터를 보면서 다듬어야되고 데이터는 결국 시각화가 중요!
2. 웹 데이터 수집 및 시각화
1) 웹 크롤링으로 데이터 수집
2) Open API를 이용한 데이터 수집
어떤 회사가 제공해주는 것
3) 지도를 이용한 데이터 시각화
좌표
위도, 경도 이용
빅데이터(21세기의 석유)
객관적으로 미래 결과를 예측 할 수 있도록 도와준다
<빅데이터의 특징 3V>
- Volumn(데이터의 양)
- Variety(형태의 다양성)
- Velocity(생성 속도)
Machine Generated Data
(IoT - Internet of Things)
탐색적 데이터 분석(EDA: Exploratory Data Analysis)
수학자 '존 듀키'가 개발한 개념으로, 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 '탐색과 이해'를 기본으로 가져야 한다
DEA 과정 5단계
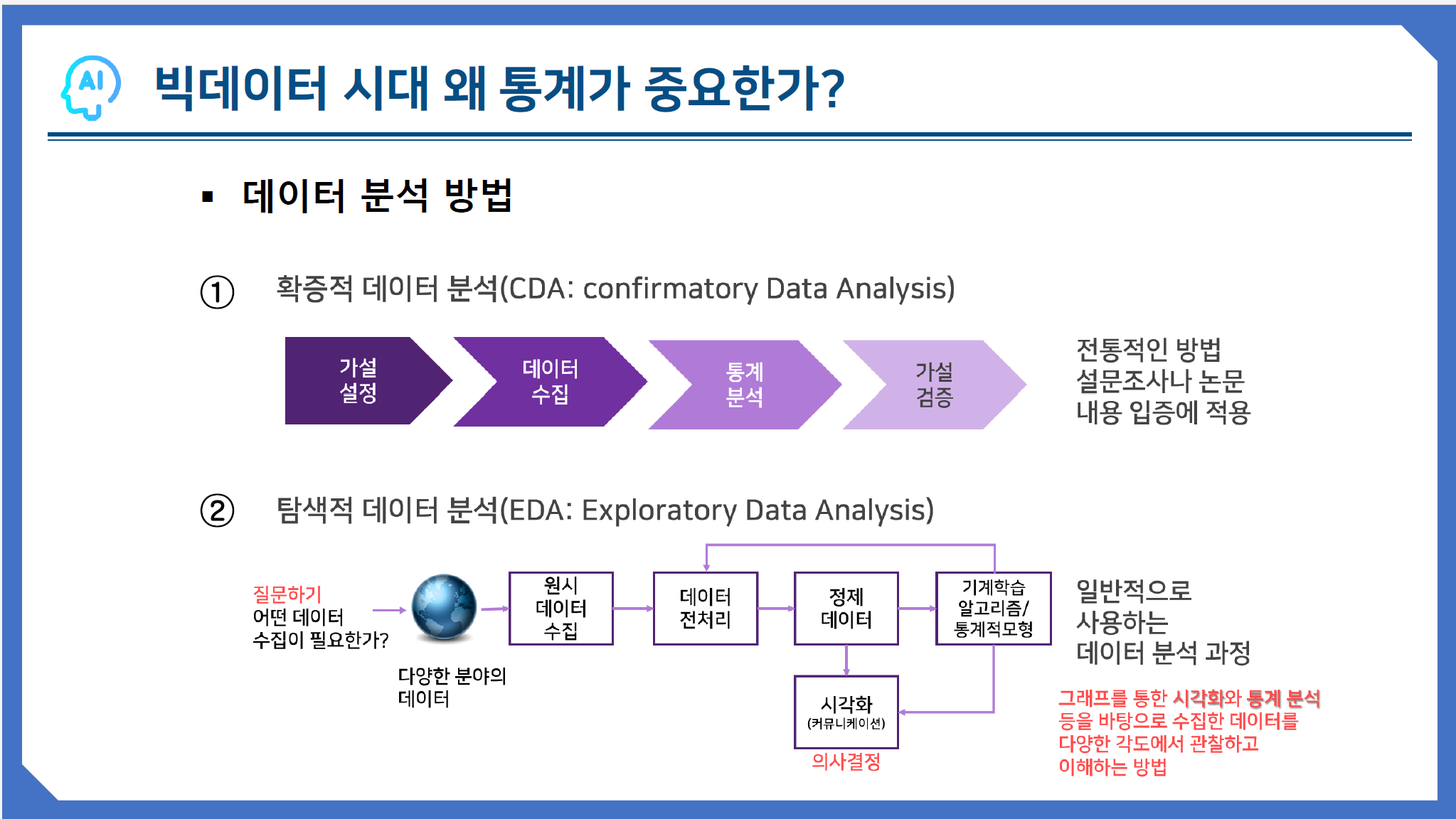
출처<조윤실 교수님>
모델링은 원하는 결과(예측, 분류)를 얻기 위해 다양한 관점에서 데이터를 설계하고 테이블 간의 관계를 설정하는 과정
생성형 AI
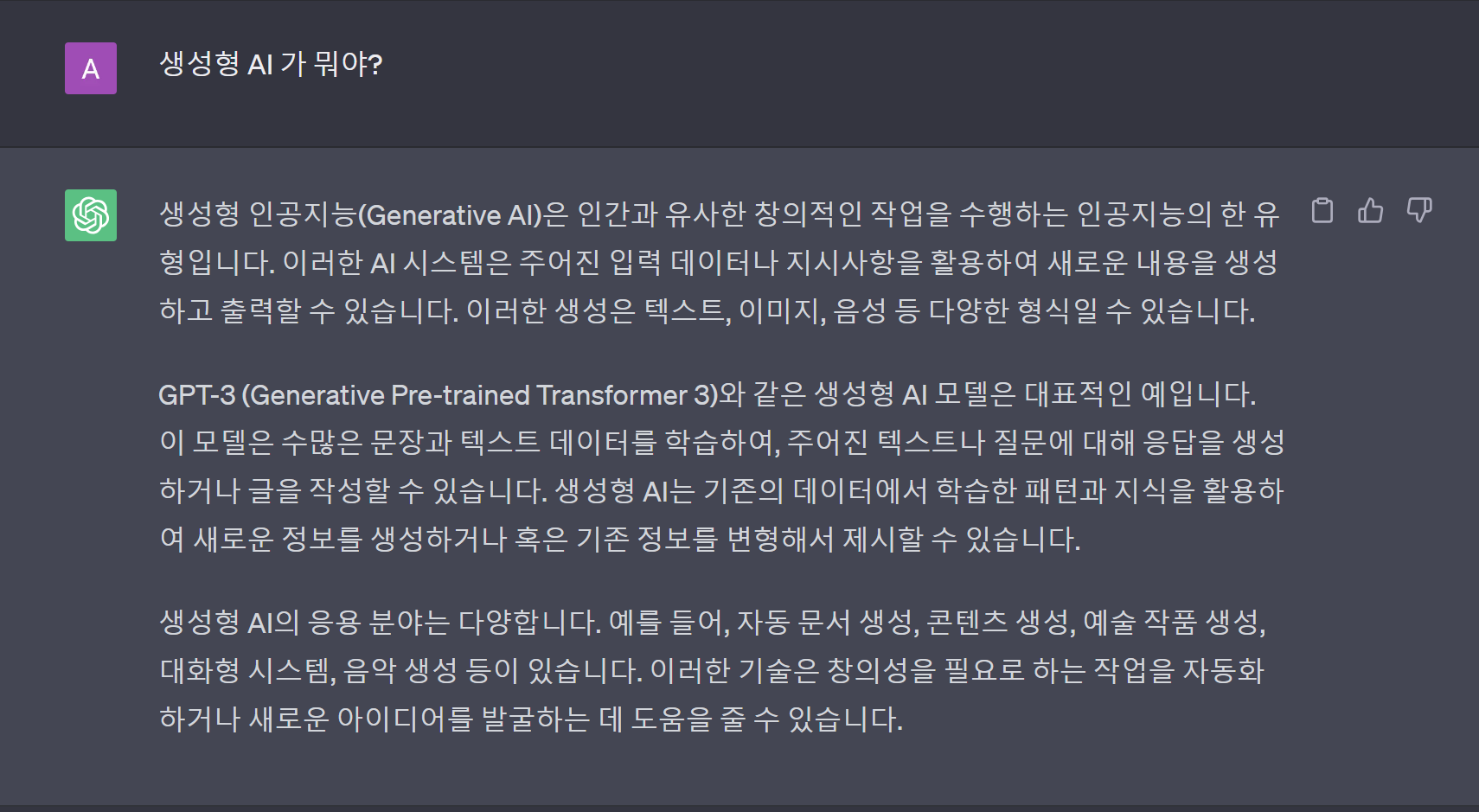
ChatGPT 가 알려줌ㅋㅋ
세상은 이제 linear 아닌 exponential 하게 움직입니다.
급속도로 생산되는 데이터 처리는 Rule-based System 보다는
ML(Machine Learning)-based System 처리가 필요합니다.
그래서 인공지능이 필요한 것임
데이터 분석의 예로
19세기 위생 혁명(콜레라 정복) 사례
-존 스노 잉글랜드 의사
-1854년 영국 런던 소호의 콜레라 창궐의 원인을 추적
-종래에는 미아즈마 학설이 원인으로 인식했으나
알고보니 식수원의 오염이 콜레라의 발병 원임임을 주장
-전세계적으로 공중보건학을 크게 향상, 콜레라 예방법 연구
Q. 장미 그래프로 데이터를 시각화한 대표적인 인물은?
-나이팅 게일
크림 전쟁 당시 영국군의 전사자와 부상자에 관한 방대한 데이터를 분석함
데이터 분석의 핵심??
데이터 분석 목표
=> 의사결정 & 행동 (insight를 얻는게 가장 중요함)
코딩 같은건 하나의 툴일 뿐이고 ChatGPT도 상용화 되었으니 이젠
해당 domain에 대한 business 지식이 가장 중요하다!
그래야 예측을 넘어 처방까지 내릴 수가 있음
머신 러닝 분야의 발전 방향
수학 -> 통계학 -> 컴퓨터 과학 -> 머신 러닝
데이터 전처리(Data Processing) 작업
전체 시간의 70% 이상을 할애 해야할 정도로 중요한 작업
이산화: 카운팅 할 수 있도록 만드는것
제일 중요한건 내가 뭘 하고 싶은지, 뭘 잘하는지, 뭘 해야하는지를 찾아야한다~!
AI 시대 경제 구조 전망
MEGA 기업 - 혁신 소기업들의 형태
대,중,경 기업 점점 사라지는 상향
AI 시대 트랜드
효율성 -> 감수성
개인 취향 맞춤 브랜드
문/이과 문합형 사고
통계
기술통계 기초
인공지는 서비스 개발에서 약 80%는 학습 데이터를 구축하는데 쓰인다
똑똑한 인공지능을 만들기 위해서는,
품질 좋은 대량의 학습 데이터가 필수적이다.
통계의 역할
-개별 데이터로 알 수 없는 현상을 개별 데이터를 요약하여 하나의 현상을 알 수 있게 함
-현재 상황을 판단하고 또 앞으로 일어날 상황을 예측
자료의 종류
질적자료
양적자료 - 이산 자료(대학별 취업자 수, 대형마트별 가격)
, 연속자료(키, 몸무게, 강수량)
상자그림(box plot)
ex) 주식 그래프
데이터
지금 가지고 있는 데이터 - 기술 통계학
가지고 있지 않은 데이터 - 추론 통계학
추론통계학의 목표:
한정된 표본으로부터 모집단의 평균이나 분산이라는 지표를 추정하는것
모수적 기법
'모집단이 이와 같은 성질이므로 이러한 형태를 지닌 확률분포일 것이다' 라고 가정을 하고, 그 뒤에 확률분포의 기대값이나 분산을 결정하는 소수의 파라미터를 추측하는 방법
-> 정규분포를 갖는다는 모수적 특성 이용
-> 어느 정도의 형태(추정이 간단하고 분석이 쉬운 모형)만 결정짓는 모형
확률적 데이터
분포(distribution)
대부분의 확률적 데이터값을 살펴보면 어떤 값은 자주 등장하고 어떤 값은 드물게 나오거나 나오지 않는 경우가 많다. 확률적 데이터에서 어떤 값이 자주 나오고 어떠한 값이 드물게 나오는 가를 나타내는 정보를 분포라고 한다.
분포 그래프
- 실수형 데이터 - 히스토그램으로 표현
- 범주형 데이터 - 카운트 플롯
이항분포
정규분포(가우스 분포)

출처 https://careerly.co.kr/comments/74047
가설검정의 의미
범죄 사건이 발생되었다고 가정할 때
-용의자는 무죄이다 -> 귀무가설(null hypothesis)
-용의자는 범죄자이다 -> 대립가설(alternative hypothesis)
로널드 피셔 경(1966) 통계학, 유전학, 진화생물학자
추론통계학 창시자
오류
오류를 줄이는 방법: 표본 수(n)를 늘려라!
Confusion Matrix
상관 분석
상관 분석(correlation analysis)
상관계수를 이용하여 변수와 변수 사이의 직선 관계를 분석하는 것
피어슨 상관계수(표본 상관계수)
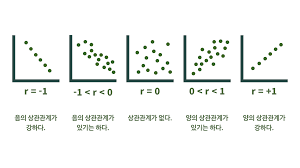
출처 https://ablearn.kr/newsletter/?idx=13552419&bmode=view
회귀분석(regression analysis)
두 변수 간의 관계를 파악하여 한 변수의 값으로부터 그에 대응하는 다른 변수의 값을 예측하고자 할 때 사용하는 통계적 방법
이때 두 변수 중
- 다른 변수에 영향을 주는 변수 - 독립변수(independent variable)
- 영향을 받는 변수 - 종속변수(dependent variable)
단순 회귀분석 모형
단순 선형 회귀분석 모형(simple linear regression model)
회귀분석은 모든 Ei에 대한 오차제곱합(SSE: Sum of Squares of Error)을 최소로 만드는 회귀계수 a와 b를 찾는 것으로서 이를 최소제곱법(method of least square)이라 한다
선형 회귀 함수식
일차함수 y = ax(기울기) + b(절편)
y : 종속변수(결과, 효과), x : 독립변수(입력, 원인)선형회귀분석
- 알고리즘의 개념이 복잡하지 않고 다양한 문제에 폭 넓게 적용할 수 있음
- 회귀 모델은 연속적인 값을 예측
Q. 머신러닝이 해야할 일은?
주어진 데이터에서 x,y 관계를 W,b를 이용해 식을 세우는 것
hypothesis = Wx + b
y x
비용 함수(Cost Function)
모델의 정확도를 측정할 때 활용되는 것으로
예측 값과 실제 값 차이의 평균을 의미한다.
머신러닝 학습 모델의 목표
비용 최소화!!!
W -> minimize cost(W)
최적화(Optimizer)
비용을 최소화 하기 위하여 weight 값을 어떻게 바꿔야 할까?
경사 하강법(Gradient Descent)
포물선의 꼭지점에 가까이 가는 Hypothesis 값을 찾는 것
미분계수가 0에 가까워지는 cost를 찾는 것
