
Matplotlib
- 데이터 시각화 : 도표라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것
- Matplotlib website API Reference를 참고하면 좋다
https://matplotlib.org/stable/api/index.html
Colab에서 사용
라이브러리 설치 먼저 해주기
import metaplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 폰트
plt.rcParams['figure.figsize'] = (10, 5) # 그래프 크기(인치)
plt.rcParams['axes.unicode_minus'] = False # 그래프 축 마이너스 표시
1. 선(Line)그래프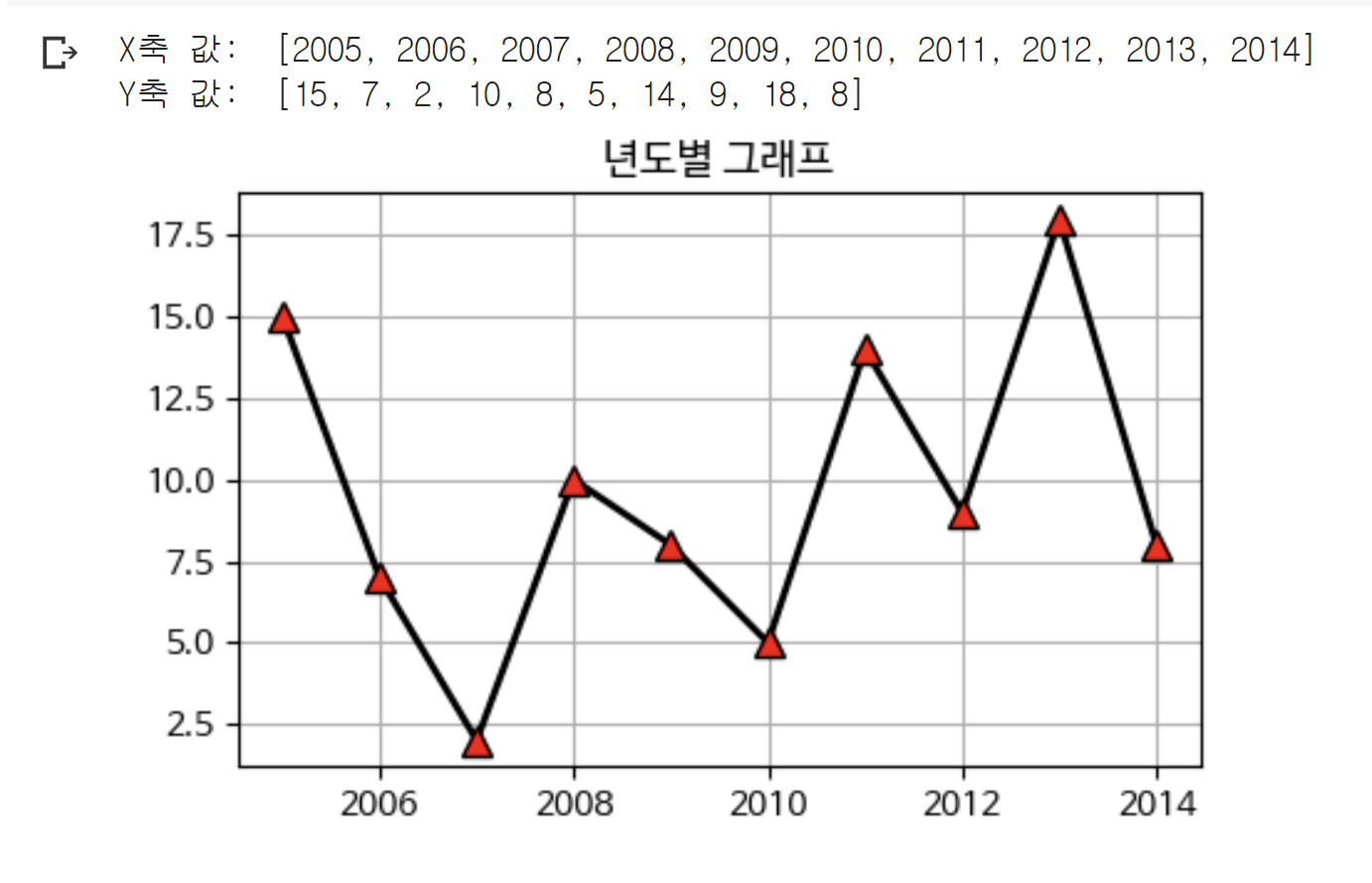
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5, 3) # 그래프 크기(인치)
plt.rcParams['axes.unicode_minus'] = False # 그래프 축 마이너스 표시
X = list(range(2005, 2015, 1)) # X좌표
Y = [15,7,2,10,8,5,14,9,18,8] # Y좌표
print('X축 값: ', X)
print('Y축 값: ', Y)
# plt.plot(X, Y) # 기본 선 그래프
# plt.plot(X, Y, linestyle='dashdot', color='r') # 빨간색 점선 그래프
plt.plot(X, Y, color='k', marker='^', linestyle='solid',
linewidth=2, markersize=8, markerfacecolor='red')
plt.grid(True)
plt.title('년도별 그래프')
plt.show()사실 꾸며주는 것보다는...
어떤 데이터를 어디다 mapping 하느냐가 핵심!!
2차 방정식의 그래프 : f(x) = a*x^2 + b, 포물선 방정식
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(-4.5,5,0.5)
y = 2*x**2
print('X축 값: ', x)
print('Y축 값: ', y)
plt.plot(x, y, label='L1')
plt.plot(x, 4*x, label='L2')
plt.plot(x,-3*x, label='L3')
plt.legend()
plt.show()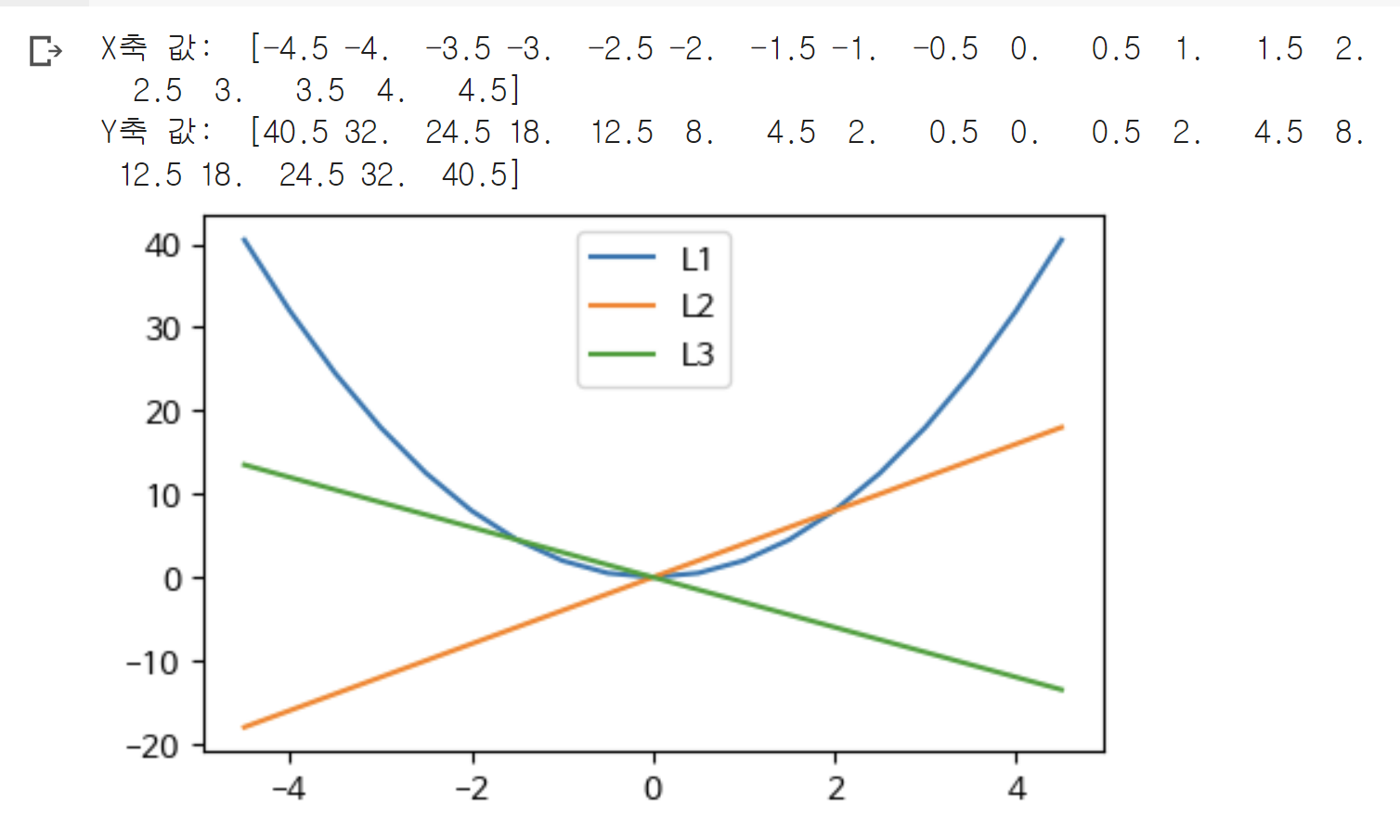
파일 데이터 읽어서 선 그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('./sample_data/weather_total.csv', encoding='cp949')
# df.head(2)
#컬럼명 변경하기
df.columns = ['일시','기온','습도','구름','일조시간','강수시간','구분']
# 1.년도 추출: 일시에서 년도만 자르기
df['년도'] = df['일시'].str[0:4]
df['년도'] = pd.to_datetime(df['일시']).dt.year
# 2. query문에서 특정 년도(2010)가 들어간 부분 검색하기
df2 = df.query(" 일시.str.contains('01-01') ")
X = df2['일시']
Y1 = df2['일조시간']
Y2 = df2['강수시간']
df2
# plt.plot(X, Y1, marker='o', label='일조시간')
plt.plot(X, Y1, '*-', color='red', label='일조시간')
plt.bar(X, Y2, label='강수시간')
plt.title('년도별 일조시간&강수시간', fontsize=15)
plt.xlabel('년도')
plt.ylabel('시간')
plt.xticks(rotation=45) # 데이터가 너무 많아서 표시하기 힘들면 좀 기울여서 표시해
plt.legend() # 범례
plt.show()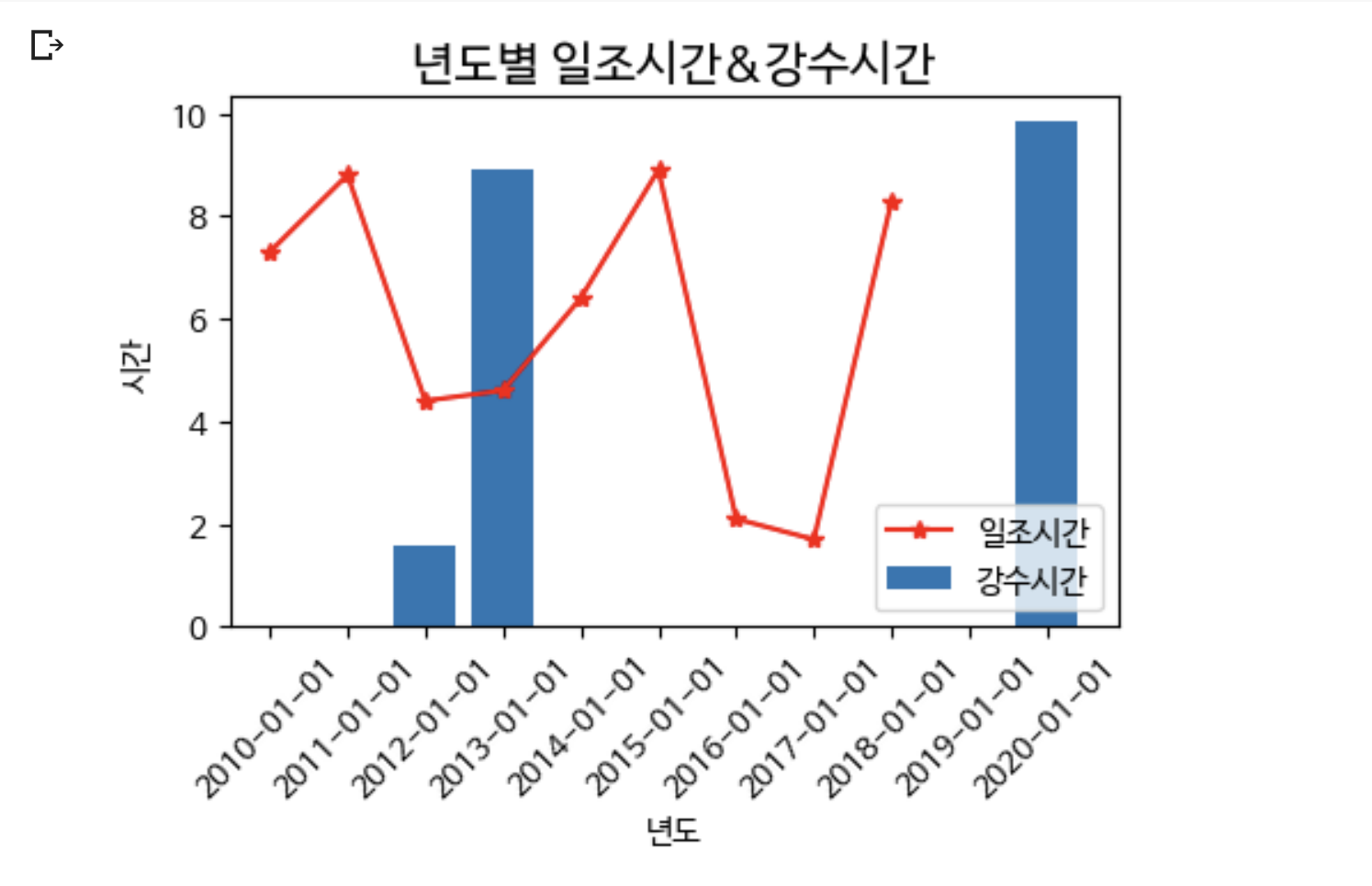
2.점(scatter) 그래프
- https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.scatter.html
- matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)[source]
import numpy as np
import matplotlib.pyplot as plt
# Fixing random state for reproducibility
np.random.seed(12345678)
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = (30 * np.random.rand(N))**2 # 0 to 15 point radii
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.show()
import numpy as np
import matplotlib.pyplot as plt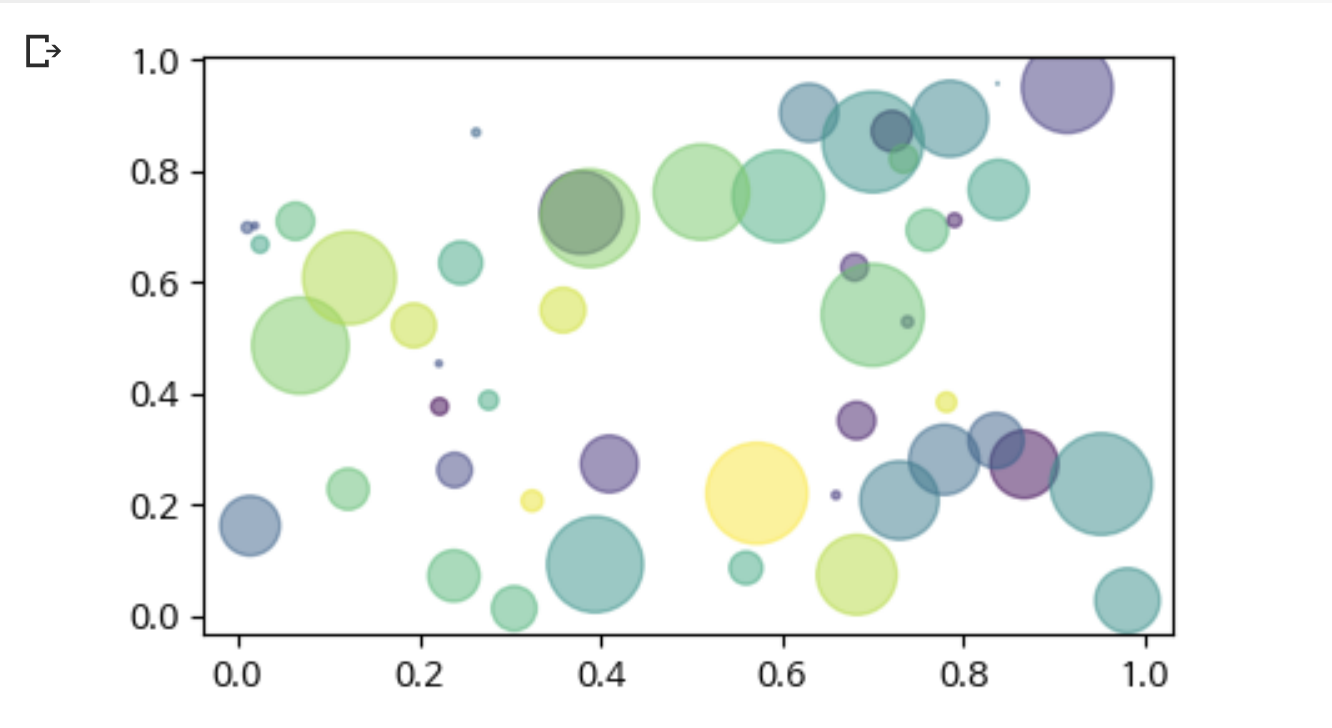
Q. 시각화는 누구를 위해서?
나와 내가 설득시켜야 하는 그들을 위해서!!
공공 데이터 이해
공공데이터란?
데이터베이스, 전자화된 파일 등을 공공기관이 법령 등에서 정하는 목적을 위하여 생성 또는 취득하여 관리하고 있는 광 또는 전자적 방식으로 처리된 자료 또는 정보를 말함
공공데이터를 이것, 저것 다 가져와서 돈이 될 수 있게끔...
EDA 분석 예제
최씨를 찾아라!
워드 클라우드를 사용한 시각화 연습
# df_choi = df[df['성씨'].str.contains('최')]
df_choi = df.query("성씨.str.contains('최') & (지역 != '전국')")
df_choi
# 자신의 한글 성씨 데이터를 지역별 합계 데이터를 '인구' 크기순으로 정렬하기
# 1.'최'씨 데이터를 [지역]별 합계 구하기
# df_choi_group = df_choi.groupby('지역').sum()
df_choi_group = df_choi.groupby('지역').sum(numeric_only=False)
df_choi_group
# 2.지역별 합계 데이터를 '인구' 크기순으로 정렬하기
df_choi_group = df_choi_group.sort_values(by = '인구', ascending = False) # 오름차순 = False -> 내림차순
df_choi_group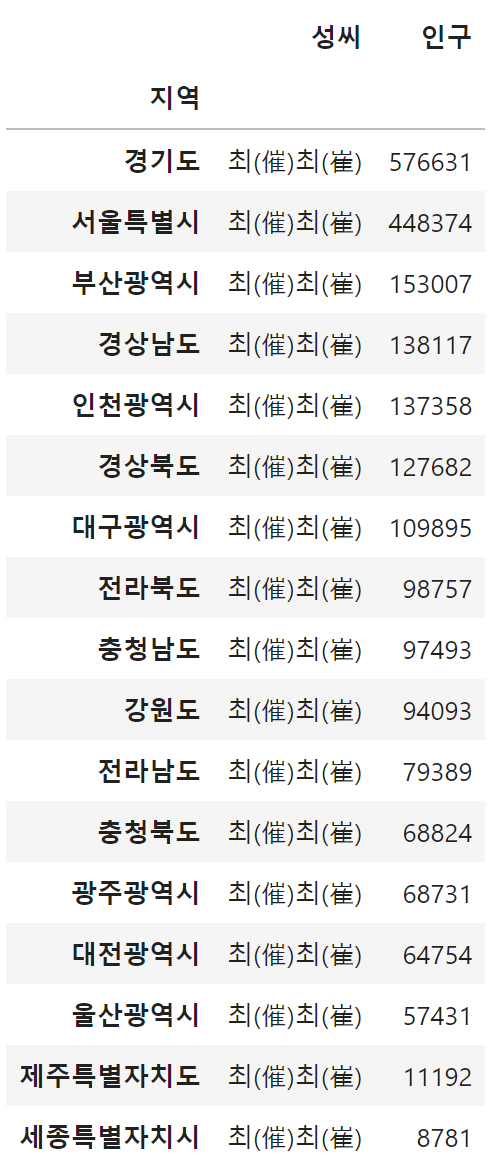
자신의 성씨 데이터 지역별로 그룹핑해서 그래프 그리고 데이터 파일을 저장하기 나타내기
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 1. (win)폰트 지정: 자신의 컴퓨터 환경에 맞는 한글 폰트 경로
# font_path = 'malgun' # C:/Windows/Fonts/
# font_path = 'HMKMMAG' # C:/Windows/Fonts/HMKMMAG.TTF
# 1. (코랩)폰트 지정: 자신의 컴퓨터 환경에 맞는 한글 폰트 경로
font_path = '/usr/share/fonts/truetype/nanum/NanumGothicBold.ttf'
# 2.전처리된 데이터 지정하기
names = df_choi_group.index # 지역
counts = df_choi_group['인구'] # 인구수
data = dict(zip(names, counts)) # 워드클라우드는 딕셔너리 형태로 만들기
# print(data)
# 3.워드클라우드 그래프로 시각화하기
wc = WordCloud(width = 1000, height = 600,
background_color="pink", font_path=font_path)
plt.imshow(wc.generate_from_frequencies(data))
plt.axis("off")
plt.show()
# 4.파일로 저장하기
wc.to_file('./sample_data/최씨_워드클라우드.png')

Slowly but surely