
출처 https://monovm.com/blog/what-are-web-crawlers/
웹 크롤링(Web crawling)
웹 크롤링이란 컴퓨터 소프트웨어 기술로 web site에서 원하는 정보를 추출하는 것을 의미한다.
이때, 한 페이지만 머무는 것이 아니라 그 페이지에 링크되어 있는 또 다른 페이지를 차례대로 방문하고 링크를 따라 웹을 돌아다니는 모습이 마치 거미와 비슷하다고 해서 스파이더 라고 부르기도 한다.
웹 스크래핑(Web scraping)
크롤링은 여러 웹 페이지를 기계적으로 탐색하는 방법,
스크래핑은 특정한 하나의 웹 페이지를 탐색하여 원하는 정보만 콕 집어내는 방법, 일반적으로는 구분없이 사용하기도 한다.
웹 크롤링 방식
정적 크롤링
- 어느 상황에서나 같은 주소에서 변하지 않는 데이터를 기대할 수 있는 경우
- 수집 대상에 한계가 있으나 속도가 빠름
- 사용 모듈 - requests
동적 크롤링
- 입력, 클릭 등 실제 브라우저에서 행하는 행동 들을 해야만 데이터를 수집할 수 있는 경우
- 수집 대상에 한계가 없으나 속도가 느림
- 사용 모듈 - Selenium
보통 두 가지 경우를 혼용해서 쓰기도 함
웹 크롤링에 필요한 라이브러리
- 윈도우 명령 프롬프트 창을 실행하기
- pip install requests # 정적 크롤링을 위한 request 설치
- pip install beautifulsoup4 # HTML과 XML 문서를 파싱하기 위한 파이썬 패키지
- pip install selenium # 동적 크롤링을 위한 셀레니움 설치
- selenium webdriver 다운로드(for chrome)
1) http://chromedriver.chromium.org/ 접속
2) 최신 chrome webdriver 다운로드 -> chromedriver.exe 다운로드 됨
3) 아래 위치에 WebDriver 폴더를 만들고 위에서 다운로드한 exe 파일을 이동 시킨다.
정적 크롤링(스크래핑)
[실습] 네이버 뉴스 검색 데이터 수집하기
단, 네이버에서는 한번에 90개까지만 수집 가능한 상태임
- 1.데이터 가져올 웹페이지: 네이버 뉴스검색(검색어:우영우) https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%9A%B0%EC%98%81%EC%9A%B0
- 2.가져올 정보: 기사제목, URL
- 3.DataFrame으로 만들기
- 4.DataFrame --> csv파일로 만들기
import requests
from bs4 import BeautifulSoup
import pandas as pd
print('-'*50)
print("#네이버 뉴스 데이터 크롤링하기...")
print('-'*50)
# 검색 URL 지정하기
# query=검색어, start=페이지 (10건씩 추출)
news_url = 'https://search.naver.com/search.naver?where=news&query={}&start='
# 검색어 직접 입력 받기
keyword = input('검색 키워드를 입력하세요 : ')
query = keyword.replace(' ', '+') # 검색에서 공백문자를 +로 대체해 사용하도록 적용
def get_naverNewTitle(total=100, start_cnt=1):
# 1.웹 데이터 수집하기
titles, urls= [],[] # 제목=[], url=[] 데이터담기
while True:
# 웹 페이지 요청하기
req = requests.get(news_url.format(query) + str(start_cnt))
# 2.응답 결과 파싱하기(제목, url 추출하기)
soup = BeautifulSoup(req.text, 'html.parser')
# page_tags = soup.select('ul.list_news > li > div > div > a')
page_tags = soup.select('div.news_area > a')
page_titles = list(map(lambda tag: tag.get('title'), page_tags))
page_urls = list(map(lambda tag: tag.get('href'), page_tags))
# 목적 개수만큼 추출하기
if len(page_titles) <= 0:
break
elif start_cnt >= total:
break
else:
titles += page_titles
urls += page_urls
start_cnt += len(page_titles)
# 데이터 수집 진행률 표시
print(f"{int( start_cnt-1/total*100 ) }% ", end="")
print()
print(f"검색어[{keyword}] 로 검색된 뉴스 [{len(titles)}]건 가져오기 완료!")
print('-'*50)
# 3.titles, urls 2차원 리스트로 만들어 DataFrame으로 만든다.
datas = [[t, u] for t, u in zip(titles, urls)]
df = pd.DataFrame(datas, columns=['title','url'])
return df
df = get_naverNewTitle(100, 1)
df
# 4.파일로 저장하기
file = f"data/naver_news_{keyword}_title.csv"
news_df = df['title']
news_df.to_csv(file, index=False, encoding="utf-8-sig")
df[실습] (수집된 데이터)기사 제목의 단어(토큰) 빈도수 분석하기
- CountVectorizer 클래스 사용 : 단어 빈도수 추출
- 단, 한글에서 불용어 처리 및 가중치 처리 등 자연어 텍스트 전처리에 필요한 여러 가지 방법은 여기서 다루지 않는다.
pip install scikit-learn
import sklearn
sklearn.__version__
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
def get_wordTokenCount(corpus):
from sklearn.feature_extraction.text import CountVectorizer
# 기사제목을 토큰화
vect = CountVectorizer().fit(corpus)
count = vect.transform(corpus).toarray().sum(axis=0)
# 토큰 빈도수로 정렬하고 토큰명 추출
idx = np.argsort(-count) # 내림 정렬하여 인덱스 반환: 토큰의 인덱스
count = count[idx] # 토큰의 빈도수
feature_name = np.array(vect.get_feature_names_out())[idx] # 토큰값
# 빈도수 많은 순서대로 토큰명 10개만 출력
print(list(zip(feature_name, count))[:10])
return feature_name, count
def draw_wordTokenCountGraph(data, freq):
plt.bar(data, freq)
plt.grid()
# 그래프 그림 저장히기
plt.savefig(f'image/{keyword}_bar_graph.png')
plt.show()
# 기사제목을 말뭉치로 사용
corpus = df['title'].to_list()
print(corpus)
# 기사제목을 토큰화하여 빈도수 가져오기
feature_name, count = get_wordTokenCount(corpus)
# 단어(토큰) 빈도 수_Bar그래프 그리기 : 상위 10개
draw_wordTokenCountGraph(feature_name[:10], count[:10])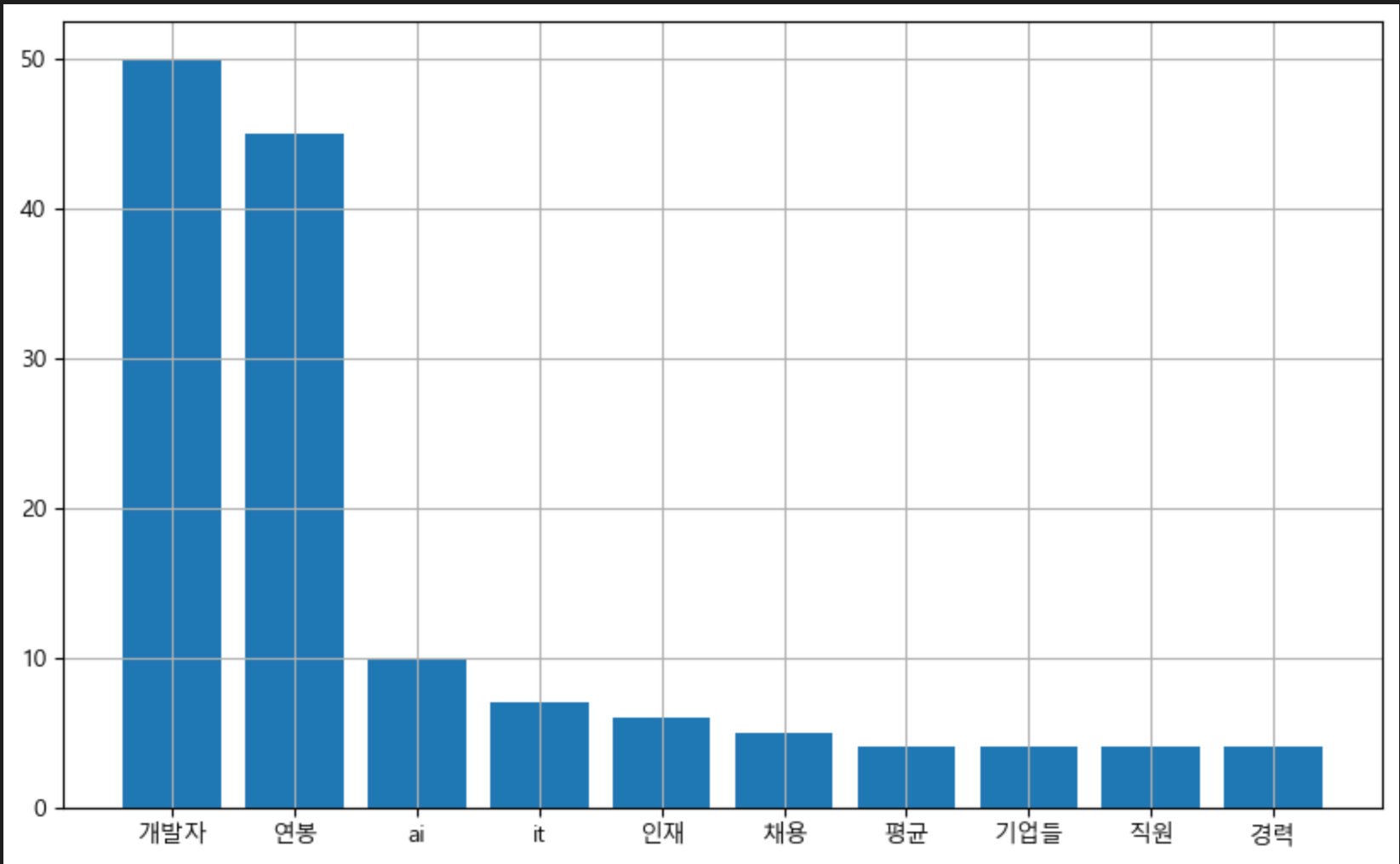
[실습] (수집된 데이터)기사 제목의 토큰 빈도수 워드클라우드로 시각화
- 워드클라우드 입력데이터 : 딕셔너리 타입
from wordcloud import WordCloud
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10,6)
# 자신의 컴퓨터 환경에 맞는 한글 폰트 경로를 설정(window에서)
# font_path = 'malgun' # C:/Windows/Fonts/
font_path = 'HMKMMAG' # C:/Windows/Fonts/HMKMMAG.TTF
# (토큰명, 빈도수) 딕셔너리 타입으로 변환
data = dict(zip(feature_name, count))
# 워드클라우드로 그래프로 시각화
wc = WordCloud(width = 1000, height = 600, background_color="white", font_path=font_path)
plt.imshow(wc.generate_from_frequencies(data)) #딕셔너리
plt.axis("off")
plt.show()
# 파일로 저장하기
wc.to_file(f'image/{keyword}_워드클라우드.png')
03.동적 크롤링(PC에서 실행)
- https://chromedriver.chromium.org/
- 최신 chrome webdriver 다운로드
- 해당 위치에 WebDriver폴더 만들고 exe파일 옮겨놓는다.
- (C:/python/projectmanager/WebDriver/chromedriver.exe)
- 자신의 크롬 웹 브라우저의 버전을 확인하고 버전에 맞는 것을 다운로드해야한다.
# webdriver 동작 테스트하기
- 자신의 크롬 웹 브라우저의 버전을 확인하고 버전에 맞는 것을 다운로드해야한다. 그렇지 않으면 오류가 발생한다.
- 아래 코드를 실행시키면 크롬 브라우져가 잠깐 실행되었다 닫힌다.
from selenium import webdriver
# chromedriver.exe 파일이 있는 경로
driver = './WebDriver/chromedriver.exe'
wd = webdriver.Chrome()
wd.get('https://www.naver.com/')
# webdriver.Chrome(driver).get('https://www.naver.com/') 위에 두줄과 동일
wd.close() # 브라우저가 실행되었다가 자동으로 닫힌다.[실습] 커피빈매장 정보 크롤링하여 파일로 저장하기
- 아래 사이트를 이용해 호출해야할 자바스크립트 함수를 확인하다.
- https://www.coffeebeankorea.com
- https://www.coffeebeankorea.com/store/store.asp
- (매장 번호로) 자세히보기: javascript:storePop2('374');
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime
from selenium import webdriver
import time
MAX = 10 # 추출 데이터 건수
#[매장 추출 함수]
def getStoreInfo():
CoffeeBean_URL = "https://www.coffeebeankorea.com/store/store.asp"
wd = webdriver.Chrome()
result = [] # 매장 목록 데이터 저장 변수
total, cnt = 370, 0
for i in range(1, total+1): #매장 수 만큼(370) 반복
wd.get(CoffeeBean_URL)
time.sleep(1) #웹페이지 연결할 동안 1초 대기
try:
wd.execute_script("storePop2(%d)" %i) #javascript 실행해주는 함수
time.sleep(1) #스크립트 실행 할 동안 1초 대기
html = wd.page_source
soupCB = BeautifulSoup(html, 'html.parser')
store_name_h2 = soupCB.select("div.store_txt > h2")
store_name = store_name_h2[0].string #매장 이름
store_info = soupCB.select("div.store_txt > table.store_table > tbody > tr > td")
store_address_list = list(store_info[2])
store_address = store_address_list[0] #매장 주소
store_phone = store_info[3].string #매장 전화번호
result.append([store_name]+[store_address]+[store_phone])
cnt += 1
# 매장정보 가져온 데이터 출력하기
print("[%3d] %3d - %s" % (cnt, i, store_name))
# MAX값에 해당하는 건수 만큼만 실행하기
if cnt >= MAX:
break
except:
continue
return result
#---------------
# main
#---------------
print('CoffeeBean store crawling >>>>>>>>>>>>>>>>>>>>>>>>>>')
result = getStoreInfo() #[매장 추출 함수]호출하기
df_cb = pd.DataFrame(result, columns=('store', 'address','phone'))
df_cb.head()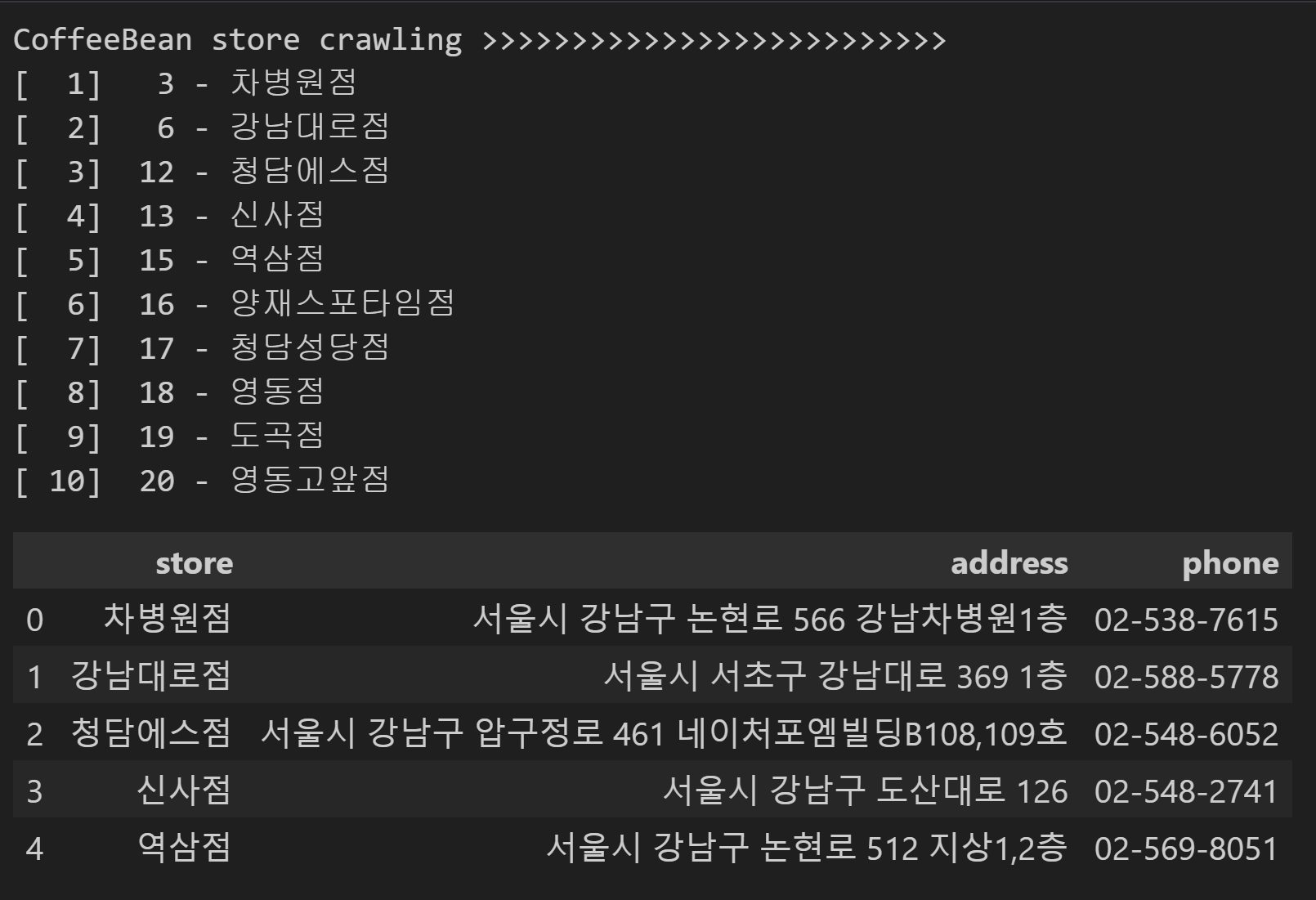

Slowly but surely