모델링 성능평가는 머신러닝 모델이 얼마나 잘 작동하는지를 수치적으로 평가하는 과정이다.
여러 알고리즘을 테스트할 때 어떤 모델이 더 나은지 비교가 가능하고, 모델이 과적합 또는 과소적합되었는지 판단할 수 있는 근거가 된다.
모델의 문제 유형은 보통 회귀, 분류로 구분된다.
회귀 (Regression)
예측값이 연속적인 숫자일 때 (주가, 온도, 집값)
독립변수(X)를 통해 답(Y)과 가장 유사하도록 예측하는 것이다.
-
MAE(Mean Ansolute Error)
예측값과 실제값의 차이의 절댓값의 평균
장점 : 직관적이고 이상치에 덜 민감하다
단점 : 오차의 방향(음수,양수)를 고려하지 않았다. -
MSE(Mean Squared Error)
오차의 제곱값의 평균
장점 : 큰 오차를 강조한다(제곱을 진행). -> 금융과 같이 작은 오차에도 민감한 분야일 때 사용
단점 : 단위가 실제값보다 제곱되어 해석이 어려울 수 있다. -
RMSE(Root Mean Squared Error)
MSE의 제곱근
장점 : 제곱근을 취하여 해석이 용이하고 큰 오차에 민감하다
단점 : 이상치에 취약하다 -
MAPE(Mean Absolute Percentage Error)
실제값 대비 오차의 비율 평균
장점 : 직관적인 %의 표현으로 이해당사자들이 좋아한다
단점 : 실제값이 0에 가까우면 무한대로 발산
유의 : zero-division(분모에 0이 들어경우)
- R^2(R-Squared)
결정계수로 전체 변동성 중 모델이 설명하는 비율이다
장점 : 예측 성능 전체 평가 가능(1에 가까울수록 모델이 잘 설명함)
단점 : 과적합 모델도 성능이 좋게 평가될 수 있다.
분류 (Classification)
예측값이 카테고리인 경우 (스팸 메일/비스팸 메일, 질병 있음/없음)
독립변수(X)로 답(Y)을 구분하기 위한 경계를 찾는 것이다.
- Confusion Matrix
예측 결과를 TP,FP,TN,FN 4가지로 나눈 행렬이다.
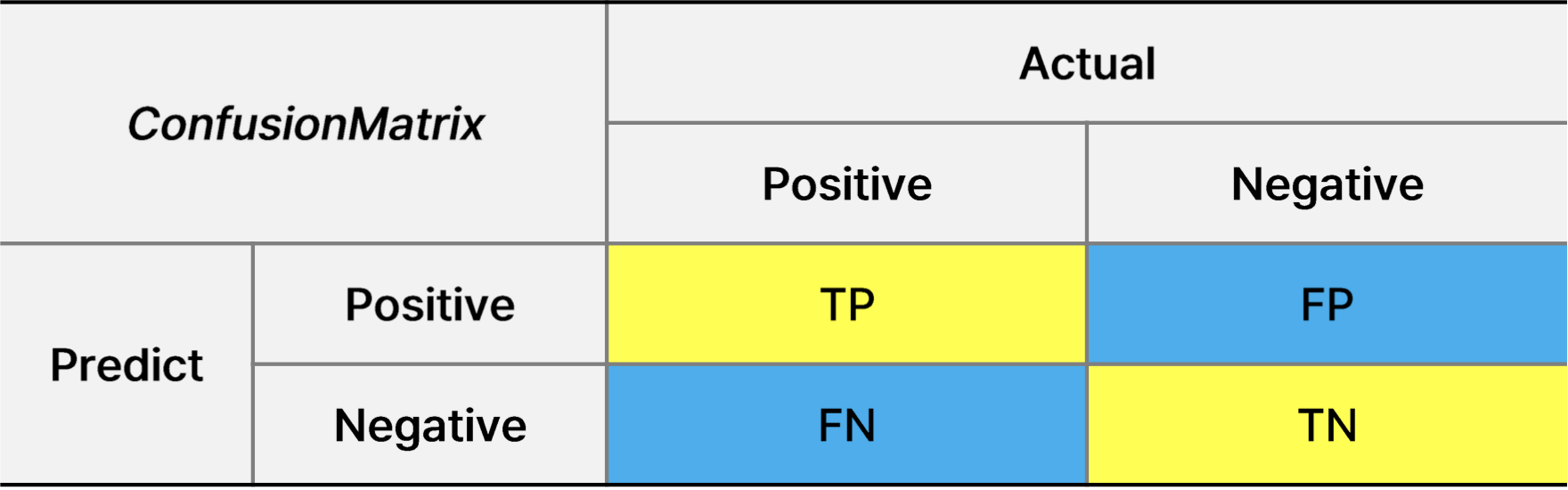
모델에서 뱉는 신호가 있다(Positive, Negative)
예측과 결과가 맞으면 T를 뱉고, 예측과 결과가 다르면 F를 뱉는다.
TP : 실제도 Positive - 예측도 Positive
TN : 실제도 Negaitive - 예측도 Negative
이런 방식이다.
해당 행렬을 통해 아래의 정확도나 정밀도를 계산한다.
- Accuracy(정확도)
TP + TN / (TP+TN+FP+FN)
전체 예측 중 맞춘 비율이다.
장점 : 이해하기 쉽다.
단점 : 클래스의 불균형에 취약하다 (99%가 Negative라면?)
-
Precision (정밀도)
TP / TP+FP
모델이 출력한 양성(Positive) 신호의 정확도를 말한다.
장점 : False Positive를 줄이는데 집중한다(스팸을 필터) -
Recall(재현율) = Sensitivtiy(민감도)
TP / TP+FN
실제 Positive중 예측에 잡힌 확률
ex) 질병예측 → 암을 에측해야 하는데 암 환자 중 진짜를 맞춘 확률 -
Specificity(특이도)
TN / TN+FP
실제 정상인 사람들(암이 아닌) 중에 정상을 맞춘 배율
Actual Negative 중 Negative로 분류한 비율 -
Fallout(위양성률) = 1-Specificity = FPR
FP / TN+FP
실제 정상인 애들 중에서 암이라고 잘못 판정한 비율
Actual Negative 중 양성(Positive)로 잘못 분류한 비율 -
F1 Score
Precision과 Recall의 조화평균
불균형한 데이터에서 잘 동작한다는 장점이 있다.
조화평균(harmonic mean)
Precision, Recall 둘중 하나가 극도로 낮을 때에도 지표에 잘 반영되도록 할때
혹은 두 지표 모두를 균형 있게 반영하기 위해 사용한다.
Precision 1 , Recall 0.01 일때
산술평균은 0.505 → 그럼 반이나 맞추는 모형일까?
조화평균은 이를 0.019로 맞춰주는 과정
-
ROC Curve (Receiver Operating Characteristic)
다양한 임계값 설정에서 분류 모델의 성능을 평가하기 위해 사용한다.
ROC커브가 좌 상단에 붙을 수록 더 좋은 분류기를 의미한다.
임계치(Threshold)를 높은 수준에서 낮은 수준으로 이동하면서 각 임계치마다 점(x:FPR,y:TPR)을 그려주고 이어준다. -
AUROC (Area Under ROC Curve)
ROC 곡선 아래 면적이다.
해석: 1에 가까울수록 분류 성능이 좋음
샘플의 분포에 변화가 생기더라도 급격한 변화를 보이지 않는다. -
Log Loss(로그 손실)
모델의 확률 예측값과 실제값 간의 차이를 로그로 측정한다.
ex) 55%의 확률로 맞춘 모델과 99%의 확률로 맞춘 모델이 같은 모델로 취급해야할까?
운이 좋아서 맞춘경우와 99%의 확률로 맞춘 경우는 다르게 취급해야한다.
얼마나 예측값에 확신하는지에 대한 평가가 필요했고, 예측의 확신을 반영하여 평가하자가 Log Loss이다.
