1. 탐색적 데이터 분석
사용한 데이터셋: Best Book to Read in 2021
1. Load dataset & Import libraries
- 시각화 도구로는
plotly라이브러리를 사용했다. - 참고할만한 사이트
- https://plotly.com/python/
- https://towardsdatascience.com/the-next-level-of-data-visualization-in-python-dd6e99039d5e
import pandas as pd
import numpy as np
import plotly.figure_factory as ff
import plotly.offline as py
import statistics
import plotly.express as px
import matplotlib.pyplot as plt
data = pd.read_csv('Best_Books_ever.csv', usecols=['title', 'series', 'author', 'rating', 'language', 'genres', 'characters', 'pages', 'publishDate', 'awards', 'numRatings', 'likedPercent', 'price'])
data.head()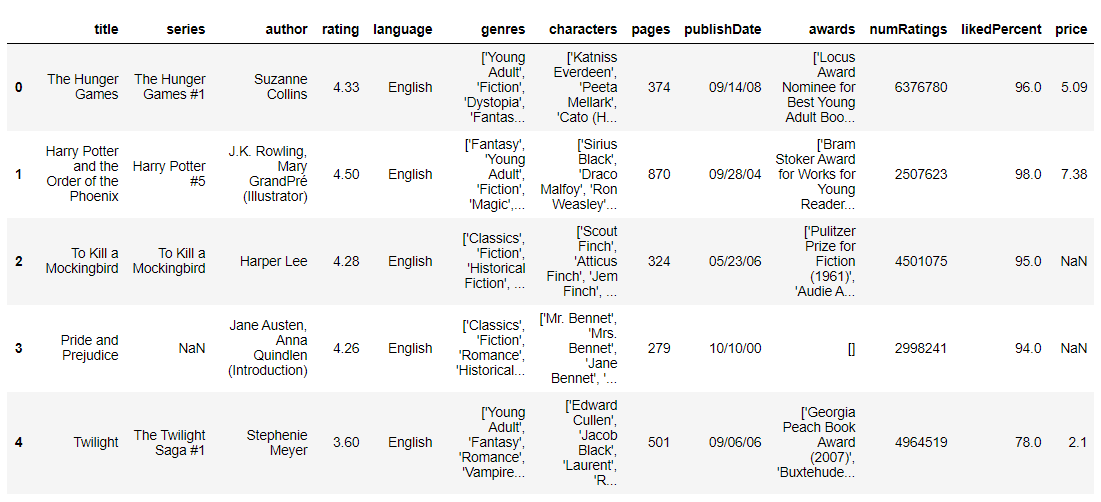
2. Data cleaning
The 4 C's of Data Cleaning: Correcting, Completing, Creating, and Converting
- 데이터프레임 열의 datatype을 바꾸고 싶을 때는
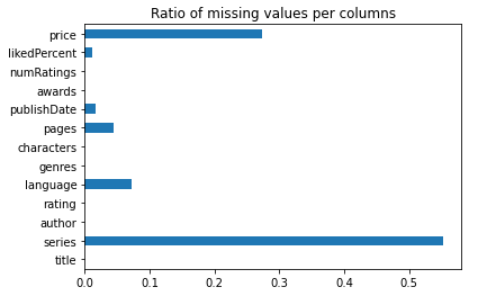
pd.to_numeric()을 이용하자.errors='coerce'로 설정하면 에러가 발생하는 경우에 NaN으로 처리한다. data.isnull().mean(axis=0).plot.barh()그래프를 그려 column별로 결측치의 비율을 한눈에 파악하자.
# 수치형으로 다뤄야 할 데이터인 pages, price의 datatype을 바꿔준다
# convert datatypes
# https://stackoverflow.com/questions/15891038/change-column-type-in-pandas
data['price'] = pd.to_numeric(data['price'], errors='coerce')
data['pages'] = pd.to_numeric(data['pages'], errors='coerce')
# 결측치 확인하기
'''Missing Value Chart'''
data.isnull().mean(axis=0).plot.barh()
plt.title("Ratio of missing values per columns")
# 데이터 개수가 충분하다고 생각되어 price, pages가 없는 행은 제거하였다
data.drop(data[data['price'].isnull()].index, inplace=True)
data.drop(data[data['pages'].isnull()].index, inplace=True)
data.reset_index(drop=True, inplace=True) # reindex- 효과적인 EDA를 위해 새로운 column을 도출하자.
- kaggle의 타이타닉 데이터셋을 분석한 여기를 참조하였다.
# 시리즈물인지 여부 'is_series'
data['is_series'] = 1
data['is_series'].loc[data['series'].isnull()] = 0
# 캐릭터 수 'num_characters'
data['num_characters'] = 0
for i in range(len(data)):
if data['characters'][i] == '[]':
continue
else:
data['num_characters'][i] = len(data['characters'][i].split(','))
# 받은 상의 개수 'num_awards'
data['num_awards'] = 0
for i in range(len(data)):
if data['awards'][i] == '[]':
continue
else:
data['num_awards'][i] = len(data['awards'][i].split(','))- 장르가 1:M으로 분류되어 있으므로, main_genre를 선정하자.
- 장르별 데이터 수를 카운팅하고 가장 빈도가 높은 상위 15개 장르를 main_genre 카테고리로 선정했다. 나머지는 etc로 분류했다.
# 장르별 빈도 카운팅
genre_dict = {}
for i in range(len(data)):
if data['genres'][i] == '[]':
continue
lst = data['genres'][i][2:-2].split("', '")
for s in lst:
genre_dict[s] = genre_dict.get(s, 0) + 1
# 상위 15개 장르만 선정, 나머지는 etc로 분류
import operator
genre_lst = sorted(genre_dict.items(), key=operator.itemgetter(1), reverse=True)[:15]
# 선정된 genre category
genre_lst
- 분석에 사용할 최종 데이터셋을 만들자.
# 주요 장르로 재배치, 해당되는 장르가 없으면 etc
data['main_genre'] = 'etc'
for i in range(len(data)):
for g, num in genre_lst:
if g in data['genres'][i]:
data['main_genre'][i] = g
break
# 최종 데이터셋 확인
del data['series']
del data['genres']
del data['characters']
del data['awards']
data.head(5)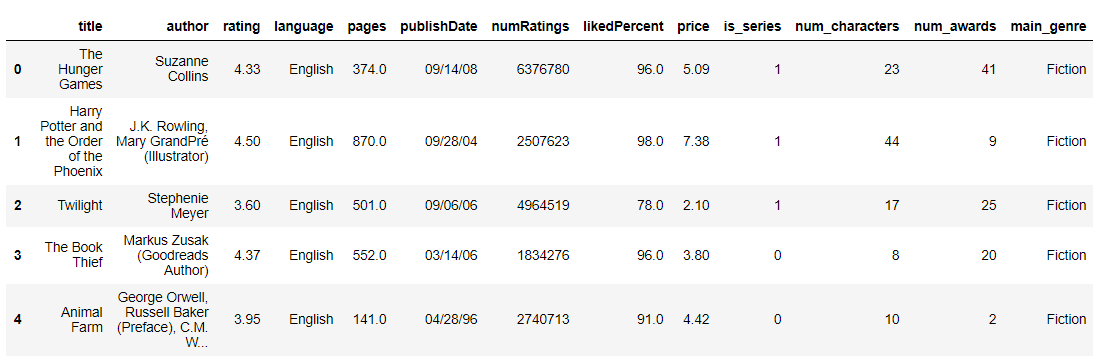
3. Exploratory Data Analysis
# 수치형 변수 기초통계분석
data.describe()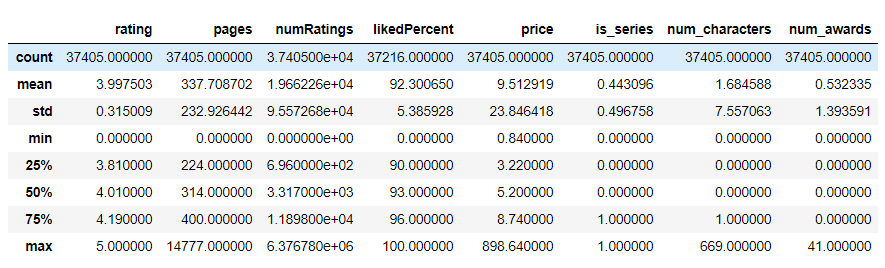
- 수치형 변수 간 상관관계를 파악하기 위해 히트맵을 그려보았다.
- plotly.express를 이용해
px.imshow(data.corr())로 히트맵을 쉽게 그릴 수 있다.
fig = px.imshow(data.corr(), template='plotly_dark', title='Heatmap')
fig.show()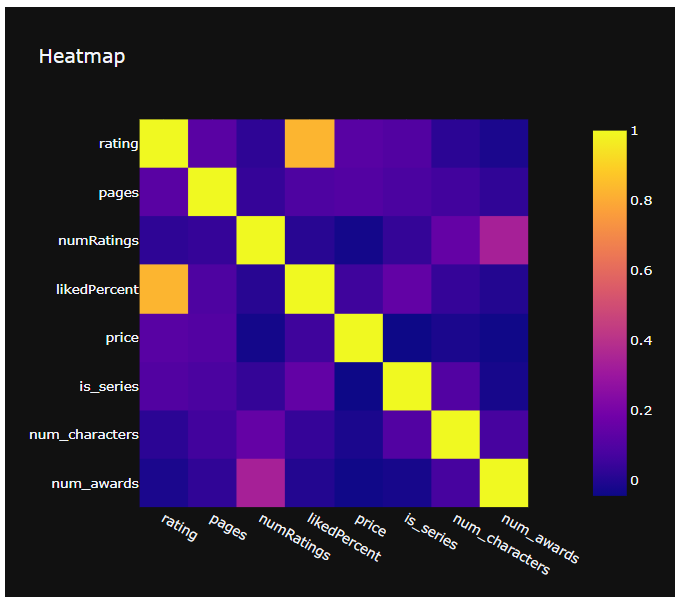
- 시리즈물인 책과 그렇지 않은 책의 평점 분포가 다른지 알고 싶어서 두 그룹의 평점 분포를 그려보았다.
- plotly.figure_factory를 이용해 distplot을 그렸다.
ff.create_distplot(hist_data, group_labels, bin_size=.2, colors=colors)
# 시리즈물과 단편의 평점 분포
# group data
hist_data = [data[data['is_series'] == 1]['rating'], data[data['is_series'] == 0]['rating']]
group_labels = ['is_series', 'not_series']
colors = ['#2BCDC1', '#F66095']
# create distplot
fig = ff.create_distplot(hist_data, group_labels, bin_size=.2, colors=colors)
fig.update_layout(title_text='Rating Distribution', template='plotly_dark')
fig.show()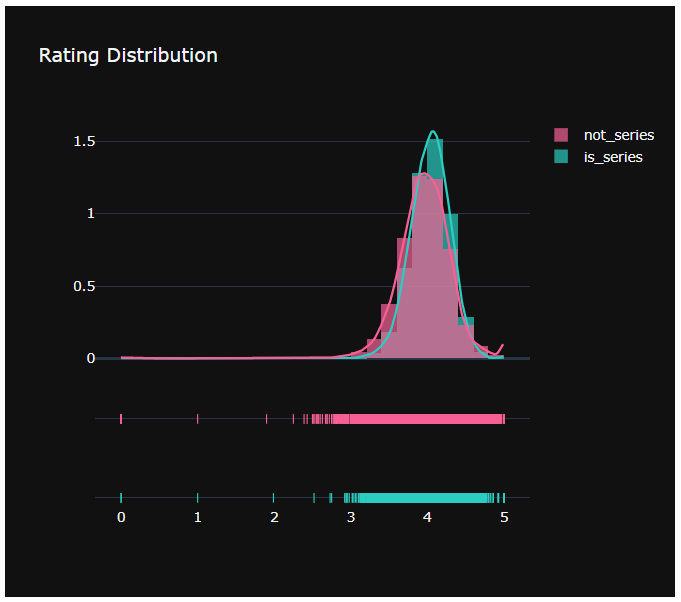
- 장르별 평점 분포를 비교하기 위해 boxplot을 여러개 그려보았다.
px.box(data, x="main_genre", y="rating", color='main_genre')
# 장르별 평점 분포
fig = px.box(data, x="main_genre", y="rating", color='main_genre', template='plotly_dark')
fig['layout'].update(title='Rating Distributions by Genre')
fig.show()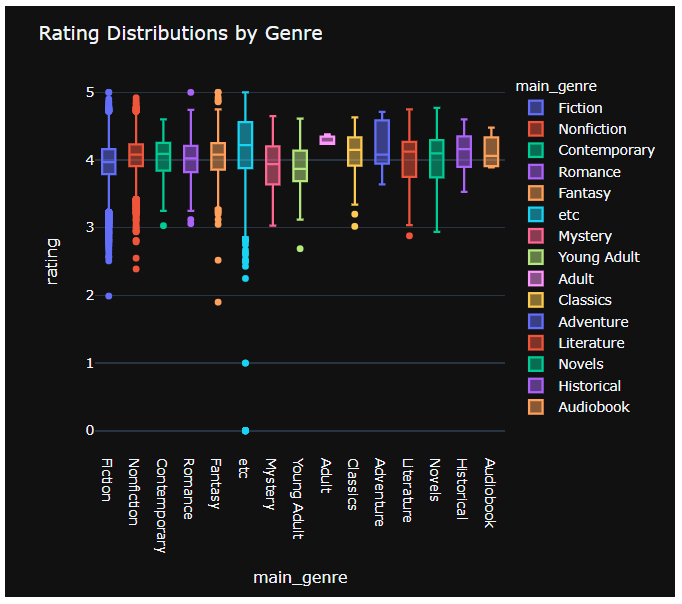
- 책이 너무 두꺼우면 사람들이 많이 읽지 못했을 것 같다는 생각에 likedPercent와 pages의 관련성을 시각화 해보았다.
- density heatmap은 처음 그려보는데 꽤나 직관적인듯 하다.
- x와 y의 범위를 적절히 조절해 그렸고, 히트맵 바깥에 히스토그램도 추가할 수 있다.
px.density_heatmap(data, x="pages", y="likedPercent", marginal_x="histogram", marginal_y="histogram", range_x=[0, 500], range_y=[80, 100])
# likedPercent vs Pages 밀도 히트맵
fig = px.density_heatmap(data, x="pages", y="likedPercent", marginal_x="histogram", marginal_y="histogram", range_x=[0, 500], range_y=[80, 100], template='plotly_dark')
fig['layout'].update(title='Density Heatmap of LikedPercent vs Pages')
fig.show()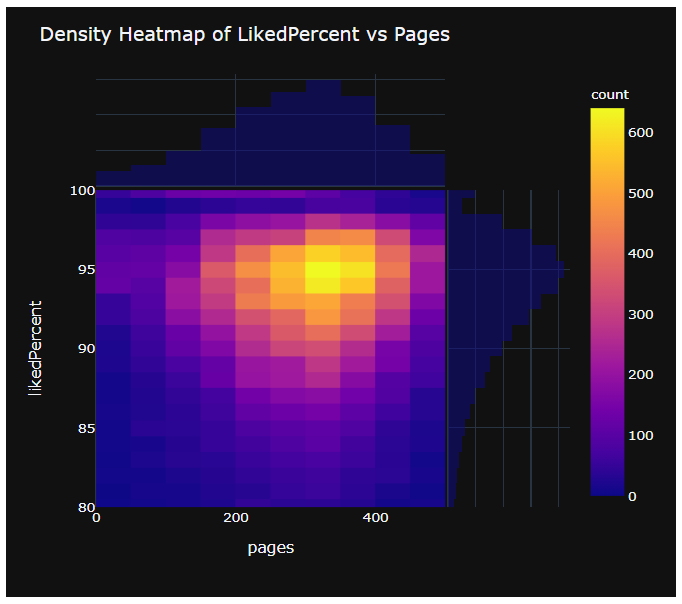
- 마지막으로, best books에 이름을 올린 책들이 어떤 장르들을 가지고 있는지, 비율을 파악하고 싶어서 pie chart를 그려보았다.
px.pie(df2, values=values, names=labels)
# 장르의 비율
# count values by main_genre
df2 = pd.DataFrame(data['main_genre'].value_counts()).reset_index()
df2.columns = ['main_genre', 'counts']
labels = df2['main_genre'].tolist()
values = df2['counts'].tolist()
fig = px.pie(df2, values=values, names=labels, template='plotly_dark')
fig.update_traces(textposition='inside')
fig.update_layout(uniformtext_minsize=12, uniformtext_mode='hide')
fig['layout'].update(title='Genre Ratio', boxmode='group')
fig.show()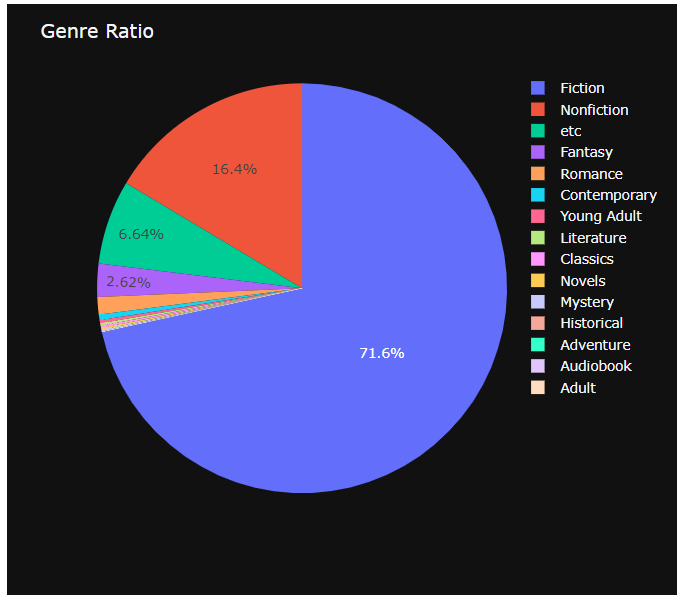
2. Flask 웹 만들기
웹 페이지의 미적 요소를 위해.. 부트스트랩 템플릿을 적용하였다. 템플릿을 다운받아서 사용하기 위해서는 몇가지 수정해줄 부분들이 있다.
1. 템플릿 폴더의 압축을 풀어서 flask project의 알맞은 위치에 파일 이동
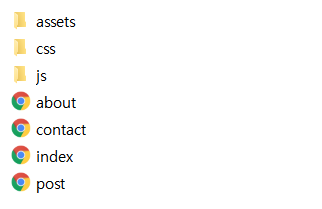
템플릿 폴더를 다운받아 압축을 풀면 위와 같은 모습이다. 여기서 html 파일들은 flask project 디렉토리의 templates로, 나머지 폴더(assets, css, js)는 통째로 static 하위로 옮겨준다!!
2. static 파일을 사용하는 코드들 경로 수정
static 파일들을 .html에서 올바르게 읽어와 사용하기 위해서는 경로를 수정해주어야 한다. 항상 경로 때문에 많이 고생하는 것 같다...😂 아래와 같이 바꿔주기만 하면 되는데, href혹은 src 속성을 찾아 일일이 바꿔주려니 조금 귀찮다.

3. 웹에 plotly chart 올리기
seaborn, matplotlib를 쓰지 않고 굳이 plotly를 선택한 건 당연 그래프가 더 예뻐서였다. 그래서 더더욱 웹에 적용하는걸 포기할 수 없었다! 아주 다행스럽게도 plotly를 적용하는건 그다지 어렵지 않다.
우선 그래프 객체 fig를 .html 파일로 저장한다. fig.write_html('pie.html')로 간단하게 다운로드 할 수 있다.
plotly 그래프가 담긴 .html 파일을 static 폴더 안에 charts 폴더를 만들어 저장해주었다.
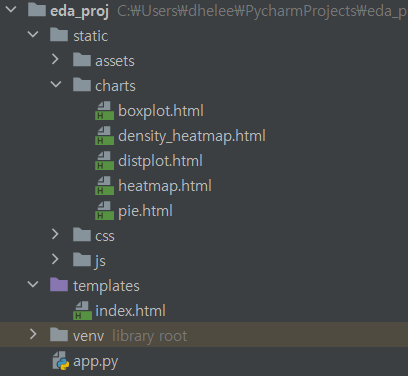
이제 원하는 곳에 아래와 같이 <iframe> 태그를 이용해 넣어주기만 하면 된다!!
<iframe src="../static/charts/heatmap.html" width="700" height="500" frameborder="0" framespacing="0" marginheight="0" marginwidth="0" scrolling="no" vspace="0"></iframe>3. pythonanywhere로 웹 페이지 배포하기
AWS를 사용하는 방법도 있었지만, 처음 설정할 때 너무 헤맸던 기억에 조금 더 안전한 방법(?)을 찾아보던 중 pythonanywhere를 발견했다! 무료로 웹을 배포할 수 있고 무엇보다 비교적 간단하다.
구글링을 열심히 해보니 git clone해서 바로 올리는 방법들이 많이 나왔는데, git repository를 따로 만들고 싶지는 않았기에 웹사이트에 파일을 바로 업로드 하는 방식을 찾았다. 여기를 참조해서 쉽게 웹 배포를 할 수 있었다.
최종적으로 완성한 웹페이지와 관련 소스는 아래에서 확인할 수 있다.
Site: http://dhelee.pythonanywhere.com/
Github: https://github.com/dhelee/AIDevCourse/tree/main/monthly_project1
+) 첫번째 monthly project를 끝마치며
EDA도, Flask도 다뤄봤던 것들이기에 어렵지 않게 할 수 있을 것 같았다. 하지만 역시나 오산이었다. 다 안다고 생각해도, 0에서부터 만드는 일은 어렵다. 어쩌면 그건 다 아는게 아니었을지도 모르겠다. 진짜 아는 것으로 만들기 위해 끊임없이 기록하고 점점 더 나아지는 내가 될 것이다. 어제보다 오늘 조금 더 성장할 수 있기를..!
