AP-BSN: Self-Supervised Denoising for Real-World Images via Asymmetric PD and Blind-Spot Network
GIST 동계 인턴

안녕하세요❗️
이번에 리뷰할 논문은 바로 AP-BSN: Self-Supervised Denoising for Real-World Images
via Asymmetric PD and Blind-Spot Network 입니다. 해당 논문은 앞서 리뷰한 N2N, N2V와 같이 SSL을 활용하지만 SSL을 활용하는데 있어서 약간의 차이점이 존재합니다. 특히 Pixel-shuffle Downsampling을 수행합니다. 해당 논문 이전의 나온 선행 연구들에서는 SSL을 단순히 Blind-spot 기반 SSL이었지만 본 논문은 Downsampling Invariance SSL 분야의 기반인 연구입니다. 가장 지금 Denoising 분야에서 활용하는 기법의 시작점이라고 보시면 되겠습니다.
그럼 리뷰 시작해보도록 하겠습니다.
Abstract
Blind-spot Network와 그 변형들은 Self-supervised Denoising 분야에서 상단한 발전을 이루었습니다. 하지만 이러한 선행 연구들의 문제점은 바로 픽셀 단위로 독립인 노이즈 즉, Pixel-wise independent noise라는 가정으로 인해서 현실과는 달라 다양한 Real-world noise 및 Synthetic noise를 처리하는 데 어려움을 겪었습니다. 최근, Real-world noised의 Spatial Correlation을 제거하기 위해 Pixel shuffle Downsampling(PD)이 제안되었습니다. 그러나 이를 BSN과 함께 사용하는 것은 Real world image에 대해서 fully Self-supervised Denoising을 방해합니다.
PD(Pixel-shuffle Downsampling) 의 경우, real-world noise의 spatial correlation을 줄이기 위한 장치입니다. 이 때, BSN은 noise를 조건부 독립으로 가정하고 있습니다. 하지만 현실 카메라 이미지에서는 노이즈가 픽셀 단위로 독립이 아닌 이웃한 픽셀의 노이즈가 서로 이웃한 픽셀끼리 노이즈가 섞여 있습니다. 여기서 이러한 상관 관계를 끊어내기 위해 PD를 수행하고 이는 Stride로 조정이 가능하며 너무 약하게 적용하는 경우, 노이즈의 상관 관계를 효과적으로 지우지 못해 J-invariant가 깨져 중앙의 픽셀 정보가 주변 픽셀에 잔재하며 PD를 너무 강하게 적용한 경우, low-pass 없이 수행하기 때문에, 이로 인해 고주파 성분이 Aliasing artifacts로 나타나게 되는데 이를 BSN이 노이즈로 오인하여 성능 저하의 문제가 발생하게 됩니다.
이러한 문제를 해결하기 위해 본 논문에서는 Asymmetric PD(AP) 를 제안합니다. 이는 훈련과 추론 시의 사용하는 Stride의 계수를 달리 설정하고 Stride의 크기에 따라 발생하는 문제들을 절충안을 제시하여 BSN을 Real-world에 적용 가능하게 하였습니다.
즉, 해당 논문의 주장은 바로 "실제 sRGB 이미지에 대한 state-of-the-art Self-supervised Denoising method인 AP-BSN을 개발합니다." 이때, 추가적인 파라미터 없이 AP-BSN의 성능을 크게 향상 시키는 Random-Replacing Refinement를 제안합니다. 이는 앞서 선행된 연구들의 method보다 훨씬 뛰어난 성능임을 입증합니다.

Introduction
Image Denoising은 Computer Vision에서 필수적인 주제 중 하나로, 노이즈 신호로부터 깨끗한 이미지를 복원하는 것을 목표로 합니다. 해당 분야에도 CNN을 활용하는 기법과 다양한 학습 기반 노이즈 제거 알고리즘들이 제안되었습니다. 기존의 방법들은 일반적으로 Supervised learning을 위해 (clean image, noisy image) 쌍을 합성하여 대규모 학습 데이터를 확보하기 위해서 Additive white Gaussian noise(AWGN) 을 채택합니다.
AWGN
Additive: 원 신호에 더해지는 형태 (관측 = clean + noise)
White: 주파수적으로 “평평”(이상적으로는 모든 주파수 성분에 동일한 파워), 공간적으로는 픽셀 간 상관이 없다는 모델링과 연결됨
Gaussian: 노이즈 값 분포가 정규분포(대개 평균 0)
즉 “독립 + 0평균”을 가장 깔끔하게 만족시키는 이상적인 노이즈 분포
오히려, 이로 인해서 실제 노이즈의 특성과 많이 다르기에 실제 환경에서 잘 일반화되지 않습니다. 이러한 한계를 극복하기 위해서 SIDD, NIND와 같은 실제 데이터셋 쌍을 구축하려는 여러 시도가 있었습니다. 실제 학습 쌍을 사용하여 노이즈가 있는 실제 입력으로부터 깨끗한 이미지를 복원하도록 하는 Supervised Denoising Method 연구가 이어졌습니다. 하지만 실제 데이터셋을 구축하는 것은 막대한 비용과 엄격하게 통제된 환경 및 복잡한 후처리를 요구하며 캡처 장비마다 노이즈 특성이 크게 다르기 때문에 일반화하기 어렵습니다.
최근, 쌍으로 된 훈련 데이터에 의존하지 않는 여러 Self-supervised Denoising 연구가 이루어지고 있습니다. 이러한 방법들은 (clean image, noise image) 쌍 대신 독립적인 두 noisy image 혹은 한장의 noisy image를 학습에 필요로 합니다. 그중에서도 BSN은 Noise2Noise에서 영감을 받은 대표적인 방법 중 하나입니다. BSN은 노이즈 신호가 Pixel-wise independent하고 기대값이 0이라고 가정하에, 중앙의 픽셀을 masking 한 다음 주변의 노이즈 픽셀로부터 예측으 수행하며 이 과정을 통해서 깨끗한 신호를 재구성하는 기법입니다. 이후, BSN을 가지고 다양한 후속 연구들이 이루어졌으며 더 엄격한 blindness를 보장하면서 합성 노이즈에 대해 더 나은 성능을 기록하기도 했습니다. 하지만 Real-world noise는 Spatial Independent를 가지고 있기에 BSN의 기본 가정을 충족하지 못합니다.
선행 연구 중 Real-world의 Spatial Correlation을 끊기 위해서 PD를 활용했습니다. PD는 고정된 stride를 활용하여 노이즈가 포함된 이미지를 서브 샘플링하여 모자이크를 생성하며, 이를 통해 노이즈 신호 간의 실제 거리를 증가시킵니다. 그럼에도 불구하고, 실제 노이즈를 처리할 때, PD를 BSN에 통합하는 것은 간단하지 않습니다. 이러한 한계점의 주된 이유는 픽셀별 독립성 가정과 재구성 품질 간의 Trade-off가 있음을 확인했습니다.(N2V paper에 잘 나와있습니다!) 특히, PD에서 큰 Stride(s > 3)을 사용하는 경우, 엄격한 픽셀별 독립 노이즈 가정을 보장하고 훈련 중 BSN에 이점을 제공합니다. 하지만 이는 노이즈가 포함된 이미지의 상세한 구조와 텍스처를 파괴합니다.(Aliasing artifacts) 반대로, 작은 Stride(s < 3)를 활용하는 경우, 이미지 구조를 보존하지만 BSN을 훈련할 때, 픽셀별 독립성 가정을 만족시키지 못하는 문제가 발생합니다.
이러한 관찰에서 영감을 받아, 훈련 및 추론에 대해 서로 다른 Stride 요인을 사용하는 Asymmetric PD(AP)를 제안합니다. 실제 노이즈에 대해서, 훈련 및 추론에서의 서로 다른 stride의 조합이 서로의 단점을 보완할 수 있음을 체계적으로 검증합니다. 그런 다음, 우리는 AP를 BSN에 통합한 AP-BSN을 제안하며, 이는 실제 환경에서 fully Self-supervised Denoising을 동작할 수 있게 합니다. 더 나아가, 우리는 추가적인 훈련 없이 AP-BSN의 성능을 향상시키는 새로운 후처리 방법인 Random-Replacing-Refinement(R³)를 제안합니다. 본 논문은 실제 sRGB 노이즈 이미지에 대해서 Self-supervised BSN을 도입한 최초의 시도입니다. 이러한 제안은 이전에 이루어진 다양한 선행 연구들보다 더 큰 차이로 우수함을 보여줍니다.
본 논문의 기여는 다음과 같이 요약됩니다.
-
Spatial correlation of Real-world noise를 처리하기 위한 Self-supervised BSN을 제안합니다. 해당 프레임워크는 훈련과 추론을 위한 Astmmetric PD Stride를 활용합니다.
-
추가적인 파라미터 없이 Ap-BSN의 성능을 더욱 향상시키는 새로운 후처리 방법인 R³을 제안합니다.
-
다양한 선행 연구보다 우수한 sRGB 노이즈 입력을 처리하는 최초의 Self-supervised BSN 입니다.
Related Works
Deep image denoising for synthetic noise
Classical non-learning(non-local, mean-median filters)을 넘어, DnCNN은 주어진 이미지에서 AWGN을 제거하기 위해 CNN 기반 아키텍처를 도입했습니다. DnCNN에 이어, FFDNet, RED30, MemNet과 같이 고급 네트워크 아키텓처를 갖춘 여러 학습 기반 접급법이 연구되었습니다. 그럼에도 불구하고, AWGN으로 훈련된 방법들은 실제 및 합성 노이즈 간의 불일치로 인해 실제 Denoising의 일반화에 어려움을 겪습니다. 특히, CBDNet 연구에 AWGN의 기저(노이즈가 서로 독립적이고 평균이 0이라는 가정)가 종속적이거나 상관된 노이즈 신호에 대해 잘 작동하지 않음을 입증했습니다.
Real-world image denoising.
Synthetic 및 Real-world Denoising 간의 격차를 줄이기 위해, CBDNet은 카메라의 ISP를 gamma correction and demosaicking 프로세스와 함께 시뮬레이션합니다. 그런 다음, 가우시안 노이즈는 실제 노이즈 신호로 변환될 수 있으며 이는 지도 학습을 위한 훈련 쌍을 생성하는 데 사용될 수 있습니다. AWGN을 가정한 Denoisier 연구 중 공간적으로 상관된 실제 노이즈를 커버하기 위해 Pixel shuffle Downsampling(PD)를 제안했습니다. 반대로, Real-world로부터 (noisy image, clean image) 쌍을 생성하려는 시도는 거의 없었습니다. 실제 데이터셋을 활용하게 되는 경우, 해당 데이터셋에 훈련을 하는 것은 쉬우나 실제 데이터셋을 구축하는 데 많은 노력이 필요하게 됩니다.
Unpaired image denoising
Unpaired image를 사용하는 경우, 여러 선행 연구에서는 Generative 접근법을 활용하여 clean sample로부터 실제 노이즈를 합성합니다. 그 중 GCBD는 안정적인 학습을 위해 노이즈가 포함된 이미지의 plain 영역을 선택적으로 사용합니다. 최근 C2N은 실제 노이즈를 더 정확하게 시뮬레이션하기 위해 다양한 노이즈 특성을 명시적으로 고려합니다. 생성된 (noisy image, clean image)를 사용하여 Supervised model을 훈련할 수 있도록 합니다. 한편, (Synthetic noise, clean image)쌍을 채택하면서 Self-supervised Denoising 모델을 활용하기도 합니다. 그럼에도 불구하고 Input과 Target 즉, noisy image와 clean image의 Distribution을 일치시키는 것이 중요하며, 이는 실제로 어려울 수 있습니다.
Self-supervised denoising
실제 노이즈 제거의 주요 병목 현상은 적절한 훈련데이터의 부재입니다. 따라서, 노이즈가 포함된 이미지만을 사용하여 모델을 훈련하기 위한 여러 접근 방식이 제안되었습니다. N2N, N2V, N2S와 같이 입력 이미지의 noise pixel 일부를 마스킹함으로써 새로운 Self-superised denoisig 프레임워크를 도입했습니다. 특히, BSN의 개념은 four halved RF(4개의 절반 수용 필드) 또는 확장 및 마스킹된 컨볼루션의 형태로 더 효율적인 아키텍처로 확장되었습니다. Noise2same은 BSN을 사용하지 않지만, Denoising Network에서 J-invariant을 만족시키기 위해 새로운 loss를 사용합니다. 반면에 Neighbor2Neighbor은, 주어진 입력을 서브샘플링하여 self-supervised를 위한 (noisy image, noisy image) 쌍을 얻습니다. 그럼에도 불구하고, 앞서 언급한 Self-supervised method들은 pixel-wise independent noise라는 가정에 크게 의존합니다. 하지만 real-world noise의 경우 spatial correlation으로 인해 실제 sRGB image에 적용될 때 종종 Identity mapping을 학습하게 됩니다.
최근 Noiser2Nose, NAC, R2R은 보조 훈련 쌍을 만들기 위해 주어진 입력에 다른 Synthetic nooise 신호를 추가합니다. Noiser2Nose는 내재된 노이즈 분포에 대한 사전 지식이 필요하며, Noisy-As-Clean은 약한 노이즈 가정에 의존합니다. R2R은 또한 노이즈 레벨 및 ISP 함수와 같은 여러 사전 정보를 필요로 하는데, 이는 실제 시나리오에서는 사용 가능하지 않을 수 있습니다.
BSN and PD
Blind-spot Network(BSN)
BSN은 RF 내의 중심 픽셀을 보지 않고 해당 출력 픽셀을 예측하는 기존의 CNN의 변형입니다. 여러 연구에서 BSN이 Self-supervised 방식으로 노이즈가 포함된 이미지를 Denoising할 수 있음을 보여주었습니다. 이미지의 해상도 H x W이며, 수식의 단순화를 위해 channel 표기를 생략합니다. BSN을 훈련하기 위해서는 다음 두 가지 가정이 충족되어야 합니다. 노이즈는 공간적으로 즉, 픽셀 단위로 독립적이고 평균이 0이어야 합니다. 이러한 가정 하에 BSN에 대한 self-supervised loss를 최소화하는 것은 다음과 같이 기존의 지도학습과 동등하다는 것이 알려져 있습니다.
Self-supervised loss가 Supervised loss와 동등하다는 얘기에 대해서 자세히 보도록 하겠습니다. 먼저, 두 기법 모두 동일한 가정을 수행하게 됩니다.
- Signal s는 Statistics Independent 하지 않다.
- Noise는 signal s가 주어졌을 때, Conditional Independent 하다.
- Noise의 기대값 즉, 평균은 0이다.
=> 이러한 가정으로 인해서 x(noisy image) = s + n에서 s와 n을 서로 분리하는 작업이 Denoising입니다. 이때, 양변의 기대값을 취하게 되면 결론적으로 E[x] = s가 남게됩니다. 더불어 loss function 측면에서도 예를 들어 l2 loss의 경우, minimum을 위해 미분을 수행한다면 최저점이 바로 기대값을 추정하게 됩니다. 그렇기 때문에 위의 가정을 만족한다면 noisy image를 Denoising model에 입력했을 때, clean image를 추정하는 것을 기대값을 통해 확인할 수 있습니다. 즉, Self-spuervised loss가 Supervised loss와 동등하다고 이야기 하는 것입니다.
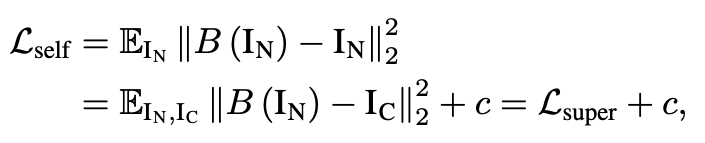
먼저, 자기 지도 및 지도 학습의 loss를 전개하면 교차항이 서로 사라지게 됩니다.(BSN의 기대값은 Clean image이고 noise의 기대값은 0입니다.) 그렇게 되면 지도학습에 상수항 c가 남게 되는데 이는 E[n^2]으로 noise의 분산을 의미하게 됩니다. 그렇다면 상수항이 존재하기 때문에 다른 것 아니냐? 라고 생각하실 수 있는데 이때, 노이즈는 저희가 학습 시 타겟이 되는 파라미터가 아닙니다. 즉, 학습 중 업데이트에 고려할 대상이 아니란 이야기입니다. 그렇기 때문에 동등하다고 볼 수 있습니다.
따라서, BSN의 여러 유형은 픽셀 단위 독립 노이즈 가정 하에 구성됩니다. 그러나. 실제 노이즈는 ISP로 인해서 공간적으로 상관되어 있습니다. 특히, Bayer필터에서의 Demosaicking은 노이즈가 있는 서브픽셀 간의 보간을 포함합니다.(국소 평균으로 수행되기에 주변 이웃한 픽셀의 정보가 섞임)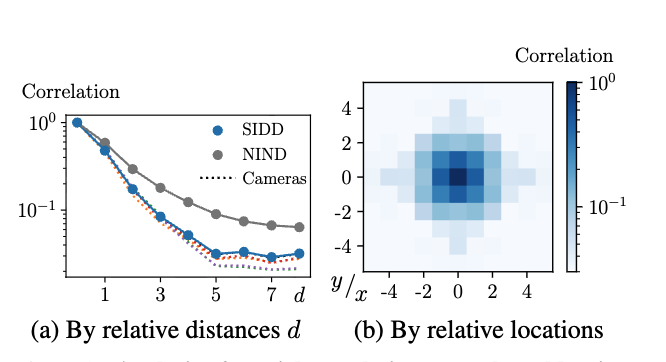
위의 그림에서 실제 환경에서 이웃한 픽셀 간의 상대적 거리에 따라 노이즈의 상관 관계를 보인다는 것을 보여줍니다. 이웃한 노이즈 신호가 보이지 않는 중심 픽셀을 추론할 때, 주변의 픽셀이 중심 픽셀의 정보를 가지고 있기 때문에 BSN이 sRGB에서 거의 Identity mapping이 되는 것을 확인했습니다.
Pixel-shuffle downsampling
실제 노이즈의 공간적 상관관계를 끊기 위해 PD라는 새로운 개념을 도입했습니다. 구체적으로, PD는 stride(s)를 갖는 pixel shuffling의 역연산으로 간주될 수 있습니다. 실제 노이즈 신호는 몇몇 이웃한 픽셀과 상관되어 있으므로, PD 과정에서 서브 샘플링은 이들 간의 Dependency를 끊을 수 있습니다. 그런 다음 PD-Inverse는 s가 전체 크기 출력을 재구성하기 위해 뒤따르는 다운샘플링 된 이미지에 기존 Denoising 알고리즘을 적용할 수 있습니다. 이미지 텍스처와 디테일을 보존하기 위해, PD의 stride 계수를 2로 설정하였습니다.(PD2)
Method
본 논문에서 제안하는 최종적인 목표는 Self-supervised Denoising으로 실제 sRGB 이미지에 BSN을 일반화하는 것입니다. 이를 위해, PD를 활용하고자 하며 BSN을 훈련하기 위해서 다음과 같은 BSN loss를 최소화하고자 합니다.
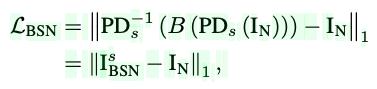
이때, 위 수식에서 I_BSN이 의미하는 바는 PD 및 BSN 파이프라인 즉, PD-BSN의 출력입니다. 널리 사용되는 L2 손실 대신에 더 나은 일반화를 위해 L1 loss를 활용하고자 합니다. 간단히 파이프라인에 대해서 보면 먼저, 주어진 noisy image를 s^2개의 서브 이미지로 분해합니다. 이 과정이 PD를 의미합니다. 이후, 서브 이미지에 BSN을 적용하고 PD-Inverse를 거쳐 이미지를 재구성합니다.
그러나 실제 sRGB이미지에 PD-BSN을 직접 적용하는 것은 간단하지 않습니다. 기존 선행 연구에서는 PD와 BSN을 통합하려고 시도했지만, 추가적인 (sythetic noisy image, clean image) 쌍과 함께 지식 knowledge distillation을 사용했습니다. 또한, Self-supervised loss로 학습될 때, PD-BSN이 real-world image에 적용되지 않음을 관찰했습니다.

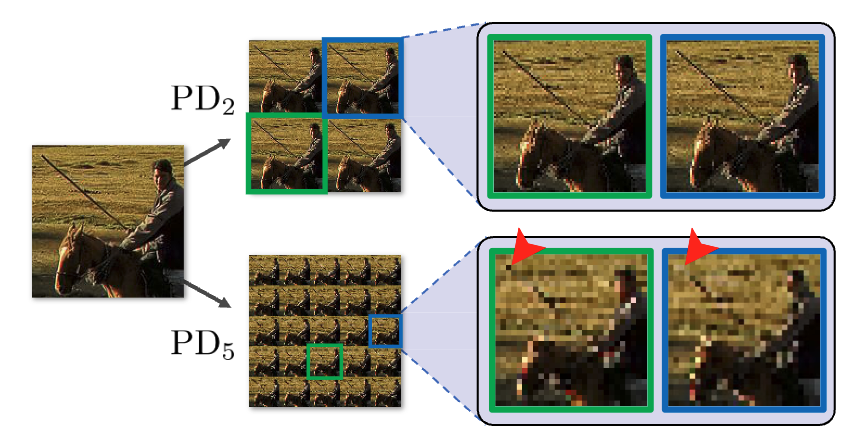
위의 그림을 보면 보폭 계수 s에 관계 없이 PD-BSN이 주어진 노이즈 입력으로부터 깨끗하고 선명한 이미지를 복원할 수 없음을 보여주고 있습니다. 즉, PD와 BSN의 결합은 BSN의 가정으로 인해서 실제 RGB image에서는 동작하는 데 있어서 한계점을 보여주고 있습니다.
Trade-offs of PD-BSN
실제 이미지에 AWGN 기반 Denoiser를 적용할 때, 기존의 PD를 제안한 연구에서는 stride를 2로 설정했습니다. 그러나 PD에서의 stride의 계수가 변함에 따라 다른 결과를 보이는 것을 관찰했습니다.
Breaking spatial correlation
PD는 실제 이미지에서 이웃한 노이즈 신호 간의 Spatial correlation을 줄이기 위해 제안되었습니다. 해당 연구에서는 stride를 2로 사용했지만 아래 그림 a를 보시게 되시면 픽셀 간 거리가 distance가 5정도는 되어야 노이즈 신호의 Dependancy를 최소화할 수 있음을 볼 수 있습니다.
즉, stride의 크기를 2로 수행한 서브 샘플링 된 이미지의 노이즈 신호들은 여전히 Spatial correlation으로 상관되어 있으며, 이는 BSN에서의 pixel-wise Independent 가정이 성립하지 않습니다.
Aliasing artifacts
PD에서 stride가 커질수록, low-pass filtering 없이 수행되는 pixel-shuffle downsampling은 원본 이미지의 고주파 성분을 단순히 저주파로 folding하여 공간적으로 비연속적인 패턴을 생성합니다. 이러한 패턴은 신호 처리 관점에서 aliasing이라고 표현하며, 특히 stride가 커질수록 서로 멀리 떨어진 픽셀들이 해상도를 압축하는 과정에서 국소적으로 인접하게 되어 aliasing artifact가 더욱 강해집니다.
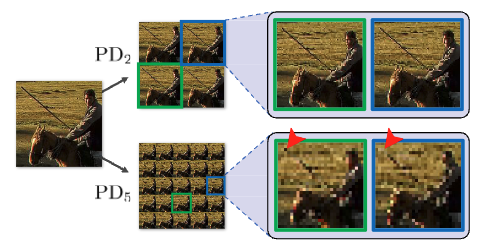
위 그림에서 보여지듯이 stride를 5와 같이 큰 stride를 적용할 때, Aliasing 현상이 noise의 한 형태로 발생함을 확인했습니다.
Effective training stride factor for PD-BSN
학습하고자 하는 입력 이미지의 noise 신호 간의 상관관계는 최소화되어야 합니다. 그러나 섹션 4.1에서 논의한 바와 같이, PD2는 실제 노이즈의 공간 상관관계를 해결하기엔 충분하지 않습니다. 즉, BSN의 기본 가정이 만족되지 않기 때문에, 모델을 PD2로 학습할 수 없습니다. 그렇기에 학습 샘플의 노이즈 신호 간 공간 상관관계를 억제하기 위해 s = 5로 설정함으로써, 더 작은 서브 이미지로 BSN을 학습할 수 있습니다.
BSN은 이렇게 크게 설정된 stride의 Aliasing artifacts를 제거하는 것을 학습하게 됩니다. 이때, Aliasing은 고주파의 성분이므로 노이즈 이미지에서 이웃한 픽셀의 상대적 거리에서 빠르게 변화하기에 Spatial correlation을 무시할 수 있습니다. 또한 이러한 Aliasing artifacts는 zero-mean 조건을 만족합니다. 즉, 이러한 Artifacts는 통계적으로 noise와 거의 유사하므로 BSN의 두 가지 가정을 만족하기에 이러한 Artifacts를 제거하는 것을 학습하게 됩니다.
Asymmetric PD for BSN
여러 선행 연구에서 학습 샘플과 테스트 샘플 간의 데이터 분포를 일치시키는 것이 Denoising에서 중요한 역할을 한다는 것을 확인할 수 있습니다. 따라서, PD-BSN을 적용할 때, 학습 및 추론에 동일한 보폭 계수를 사용하여 두 샘플간의 데이터 분포를 일치시키는 것이 자연스럽습니다. 하지만, 학습된 BSN은 PD5로부터 Aliasing artifacts를 노이즈로 오인하여 제거의 대상으로 동작하는 것을 발견했습니다. 이러한 artifacts는 image reconstruct 시 고주파의 detail한 부분이기 때문에 추론 중에 이미지 구조를 파괴합니다.
이를 해결하기 위해서 PD-BSN의 추론 중에 Asymmetric stride factor을 제안하며 이를 Asymmetric PD(AP)라고 합니다. 구체적으로는 훈련 중에는 s = 5, 추론 시에는 s = 2로 설정하여 추론 중에는 최소한의 aliasing artifacts를 포함하도록 하며, 이웃한 노이즈 신호 간의 상관관계는 감소될 수 있습니다. 이후에 Spatial correlation 과 Aliasing artifacts가 AP-BSN의 denoising 성능에 어떤 영향을 미치는지 보여줍니다. 제안된 AP-BSN은 실제 노이즈에서 self-supervised method로 학습될 수 있으며, 이미지 구조를 보존할 수 있습니다. 또한, AP-BSN은 학습을 위해 어떠한 clean sample도 필요로 하지 않으며, Real-world에서 sRGB noisy images에 직접 적용 가능하단 점을 주목해야 합니다.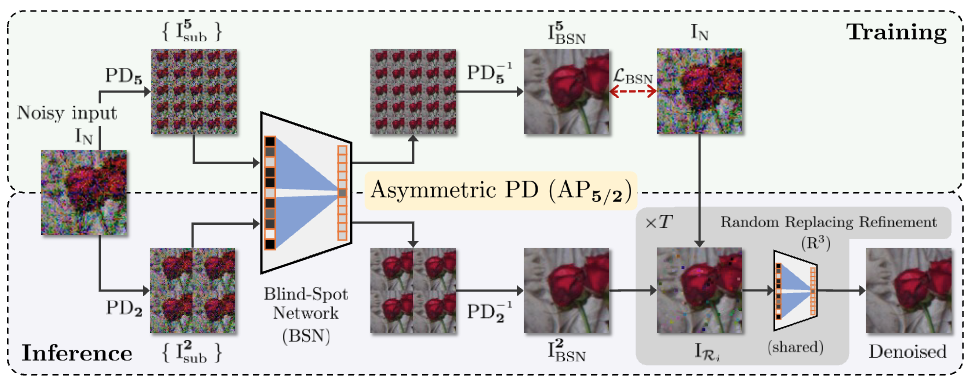
Random-replacing refinemen(R³)
추론 시 가장 작은 stride factor를 사용하더라도, low-pass filtering 없이 수행되는 pixel-shuffle downsampling은 aliasing 성분을 유발하여 시각적인 artifacts가 관측될 수 있습니다. 이를 완화하기 위해 PD를 처음 제안한 연구에서는 PD 과정에서 발생하는 artifacts를 억제하고 denoising 결과의 디테일을 향상시키기 위해 PD-refinement를 제안합니다. PD-refinement에서 i번째 replaced image는 다음과 같은 수식으로 볼 수 있습니다.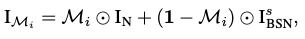
이 때, M_i는 0 또는 1의 값으로 이진 마스크에 해당하며 노이즈 이미지와 마스크는 element-wise 곱으로 이루어집니다. 이때, 마스크는 고정된 stride 2를 활용하고 i만큼 생성된 이미지는 다시 denoised 되고 평균내어 최종 Denoising된 이미지를 구성하게 됩니다.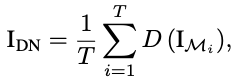
그러나 PD-refinement의 경우, 대체된 노이즈 신호 간에 무시할 수 없는 상관관계를 남깁니다. 즉, 아래 사진의 윗부분을 보시게 되면 일정한 간격으로 mask 되기에 이로 인해 상관관계가 생기게 됩니다. 이러한 상관관계는 공간적으로 상관이 없는 노이즈 가정에 부합하기 때문에 오히려 Denoiser의 성능에 부정적인 영향을 미칩니다. 따라서 PD-refinement의 한계를 완화하기 위해 R³ 전략을 제안합니다.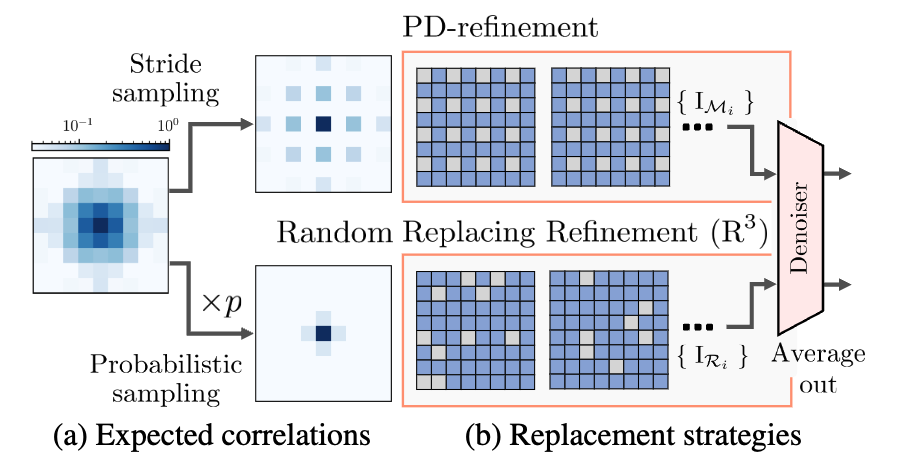
R³에서는 T개의 randomized bianry mask를 사용하게 되며, 다음과 같이 정의할 수 있습니다.
이전에 본 PD-refinement 수식의 경우, 최종 출력을 얻기 위해 고정된 마스크를 활용하는 반면에 해당 R³에서는 Randomized binary mask를 활용합니다. 즉, 노이즈 픽셀이 랜덤하게 배치되므로, 두 노이즈 신호 간의 correlation의 기대값이 p로 곱해져 이전 PD-refinement에 비해 상관관계를 크게 줄일 수 있습니다. R³를 AP-BSN과 결합할 때, PD를 수행하지 않고 입력의 노이즈 공간 상관관계가 거의 무시할 수 있기 때문에 대체 이미지 IRi를 BSN에 직접 공급합니다.

Experiments
Experimental configurations
dataset
AP-BSN을 훈련하고 평가하기 위해 많이 사용되는 Denoising dataset인 SIDD 및 DND를 활용합니다. SIDD-Medium은 훈련을 위한 320개의 (Real-world noise image, clean image) 쌍을 사용합니다. 검증 및 성능 평가를 위해서 각각 SIDD validation 및 benchmark dataset을 채택합니다. 둘 다 256x256 크기의 1280개 노이즈 패치를 포함하며, SIDD validation의 경우, clean image도 함께 제공됩니다.
DND dataset은 train dataset을 포함하지 않으며 test를 위한 50개의 real-world noise inputs만 포함합니다. 이 경우, fully self-supervised learning의 이점을 활용하여 DND의 50개 노이즈 이미지를 훈련과 평가 모두에 사용했습니다.
Metric
Ap-BSN을 평가하고 다른 Denoising method와 비교하기 위해 자주 사용되는 PSNR 및 SSIM 지표를 도입합니다. SIDD 및 DND benchmark의 경우, evaluation site에 업로드하여 수행했습니다. SIDD validation dataset에서는 skimage.metric을 RGB color space를 비교하기 위해 사용합니다.
Implementation and optimization
| 구분 | 항목 | 설정 / 내용 |
|---|---|---|
| 프레임워크 | 딥러닝 라이브러리 | PyTorch 1.9.0 |
| R³ 설정 | AP stride(s) | AP5/2 |
| 치환 확률 (p) | 0.16 | |
| 반복 횟수 (T) | 8 | |
| BSN 구조 | 기본 구조 | Wu et al.기반 |
| 구조 수정 | MDC 모듈 제거 | |
| 최적화 | Optimizer | Adam |
| 학습률 | Initial LR | 0.0001 |
| 기타 | 세부 구현 | Supplementary Material 참고 |
Analyzing Asymmetric PD
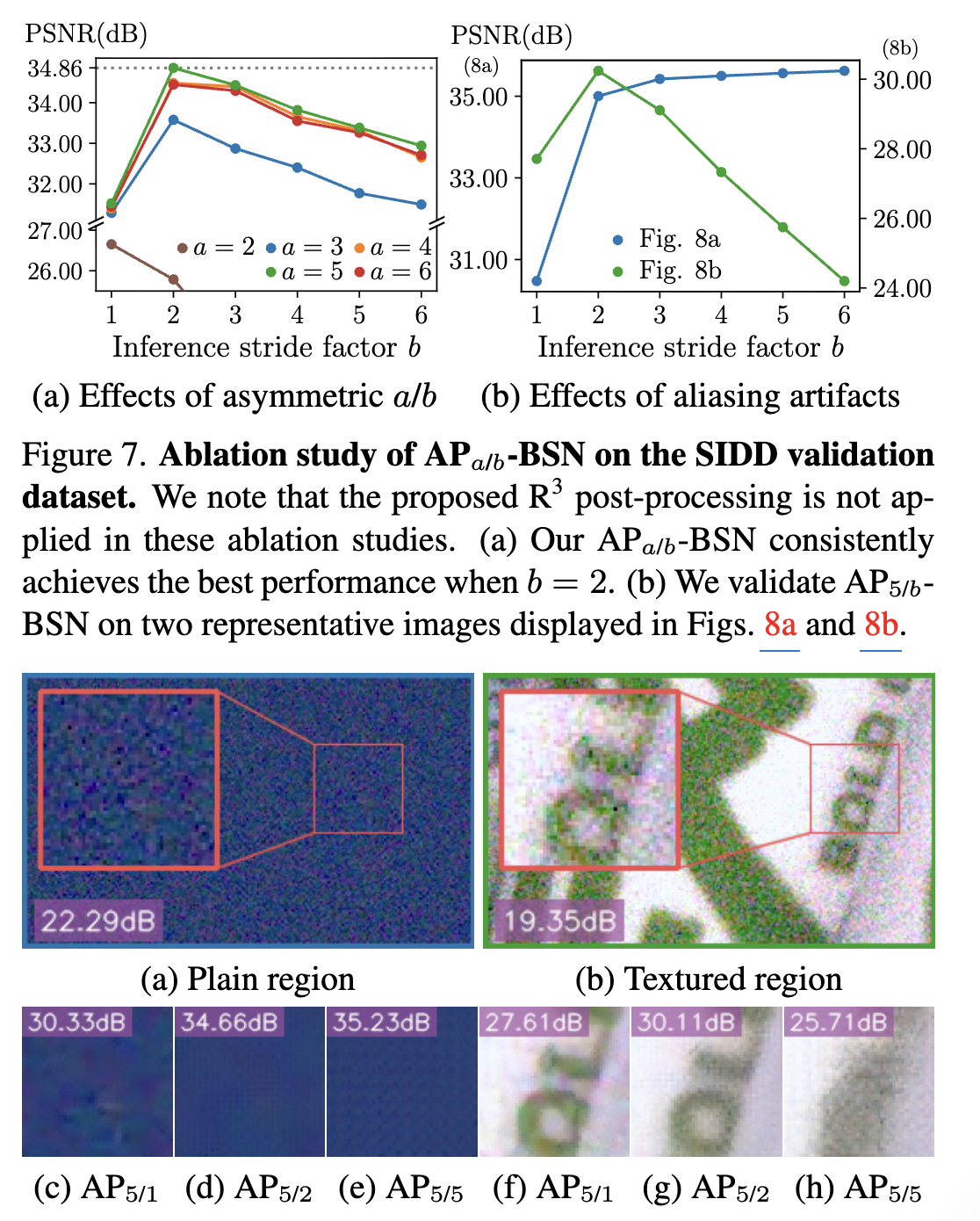
먼저, Real-world의 Denoising에 대한 AP의 효과를 검증합니다. Fig.7a에서 다양한 stride 계수 조합에 대해서 연구를 수행합니다. 실제 노이즈의 spatial correration으로 인해 a = 2일 때, BSN 훈련을 할 수 없다는 점을 확인할 수 있습니다. 더 큰 stride를 사용하면 input noise가 pixel-wise independent 가정을 더 엄격하게 따릅니다. 따라서 모델은 Denoising의 훈련 시, stride를 5로 설정할 때 성능이 최대치에 달성합니다. 이 때, 훈련 시 스트라이드 계수를 6으로 설정하면 SIDD 데이터셋에서는 성능이 약간 떨어지는 것을 확인할 수 있습니다.그러나 NIDD 데이터셋에서는 6으로 설정했을 때, 보다 더 좋은 성능을 기록했습니다. 추론 중에는 BSN이 PD 없이 Denoising을 수행할 수 없습니다.(즉, 추론 시의 stride를 1로 설정) 이는 pixel-wise independent noise를 학습했기 때문입니다. 그러나 스트라이드를 키우게 되면 low-pass filter 없이 수행한 downsampling으로 Aliasing artifacts 현상이 생기기 때문에 이러한 절충안인 stride를 2로 설정할 때, 성능이 최대화 되는 것을 확인할 수 있었습니다. 만약, 스트라이드 계수를 2보다 크게 설정한 경우, 많은 이미지에서 detail을 제거하여 성능이 저하됨을 볼 수 있습니다.
Fig.7b에서 Aliasing artifacts가 Denoising 성능에 중요한 요소임을 확인할 수 있습니다. 먼저, 주파수가 plain한 영역에 적용했을 때, 추론 시의 스트라이드를 크게 키울수록 성능이 향상됨을 볼 수 있습니다. 해당 영역에서는 주파수가 plain하기 때문에 Aliasing artifacts 가 발생하지 않습니다. 이는 스트라이드가 커질 수록 노이즈 신호의 공간 상관관계가 작아짐을 시사할 수 있습니다. 그러나 일반적인 이미지 fig.8b를 보면 고주파 영역의 신호가 존재하기 때문에 스트라이드가 커질 수록 아티팩트로 인해 성능 저하가 생김을 확인할 수 있습니다.
Analyzing Random-Replacing Refinement
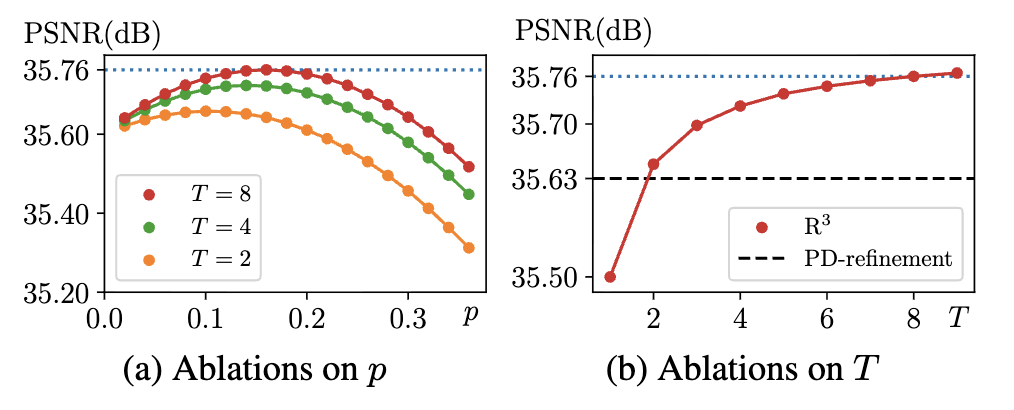
Fig.9는 제안된 R³에 대한 연구입니다. 먼저, 최적의 replacement probability를 찾기 위해서 다양한 크기의 T를 설정합니다. 즉, 몇 장의 이미지를 생성해낼지에 대한 설정입니다. fig.9a에서 볼 수 있듯이, R³의 P는 0.16일 때 최대 성능을 달성하는 결과를 볼 수 있습니다. 더 큰 p를 사용하는 경우, 노이즈 신호의 예상 공간 상관관계를 증가시켜 성능을 저하시킨다는 점을 확인할 수 있습니다.
AP-BSN for real-world denoising
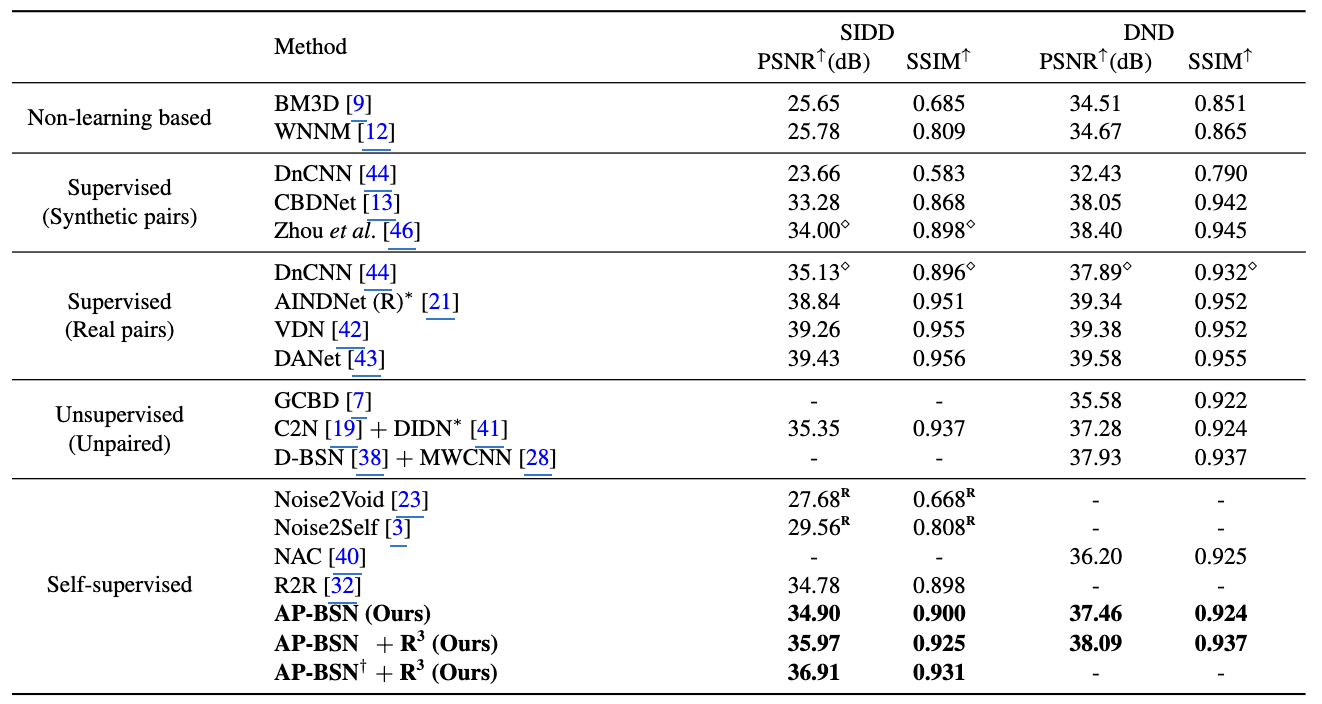
AP-BSN은 self-supervised Denoising method로 실제 sRGB 이미지의 노이즈를 제거하는 것을 목표로 합니다. Table.1은 SIDD, DND benchmaark 데이터셋에서 다양한 모델들과 비교하고자 합니다. 본 논문에서 제안하는 AP-BSN + R³은 기존의 선행된 연구 중 최고의 성능을 달성합니다. 특히, 기존의 Self-supervised 방식인 NAC, R2R의 경우, 실제 노이즈와는 다른 가정으로 수행되었습니다. 반면에, 본 논문에서 제안하는 method는 실제 노이즈의 특성에 대해서 반영하기 때문에 여러 실제 데이터셋에서 더 좋은 일반화 성능을 보여줍니다. 추가적으로, 제안된 R³는 추가적인 파라미터 없이 SIDD benchmark에서 1dB 이상 향상 시킴을 볼 수 있었습니다.
특히, AP-BSN은 깨끗한 이미지를 사용하지 않고도 노이즈가 있는 샘플에서 직업 훈련될 수 있습니다. 기존의 선행된 unsupervised, self-supervised learning 연구들은 보조 이미지 혹은 생성된 노이즈를 사용하기 때문에 훈련 및 테스트 분포 간의 불일치로 인해서 최적화에 어려움을 겪습니다. 대조적으로, 본 논문에서 제안하는 기법은 훈련 단계에서 target sRGB noisy image를 직접 사용할 수 있습니다. 이를 검증하고자 SIDD 벤치마크에서 AP-BSN을 훈련하고 동일한 데이터셋에서 평가합니다. 해당 데이터셋에서 AP-BSN은 성능 향상을 기록했으며 이는 노이즈 테스트 샘플만 존재하는 실용적인 경우에도 잘 일반화될 수 있음을 강조합니다.
Conclusion
본 논문에서는 먼저 BSN의 관점에서 다양한 PD Stride의 요인에 대해서 여러 실험적 결과를 수행했습니다. PD와 BSN을 직접 통합하는 대신, 픽셀 단위 독립성 가정을 만족시키면서 이미지 디테일을 보존하기 위해 훈련과 추론 간의 Asymmetric PD를 활용하는 실제 이미지 노이즈 제거를 위한 Self-supervised AP-BSN을 제안합니다. 또한, 추가적인 파라미터 없이 Ap-BSN의 시각적 아티팩트를 제거하는 Random-Replacing-Refinement(R³)를 제안합니다. 본 논문에서 제안하는 기법이 최근에 수행된 선행 연구들보다 우수한 성능을 기록함을 보여줍니다.
Optimization
| 항목 | 내용 |
|---|---|
| 입력 패치 크기 | 120 × 120 noisy patches |
| 데이터셋 | SIDD-Medium / DND / SIDD Benchmark |
| Epoch 당 패치 수 (SIDD-Medium) | 24,542 |
| Epoch 당 패치 수 (DND) | 24,784 |
| Epoch 당 패치 수 (SIDD Benchmark) | 24,320 |
| 데이터 증강 (Augmentation) | Random 90° rotation + Horizontal / Vertical flip |
| Mini-batch size | 8 (augmented samples) |
| 총 학습 Epoch | 20 |
| Learning rate schedule | Every 8 epochs → LR × 0.1 |
Network architecture
| 항목 | 설명 |
|---|---|
| 기본 구조 | BSN (Wu et al 기반, D-BSN) |
| 구조 변경 | MDC 모듈 제거 |
| 대체 모듈 | Single-branch Dilated Convolution (DC) sequence |
| Dilated Conv 구조 | 다중 branch ❌ → 단일 branch ✅ |
| 설계 목적 | 구조 단순화 + 파라미터 감소 |
| 전체 파라미터 수 | 3.7M |
| 시각화 | Fig. S1 (보충자료) |
| 방법 | 학습 방식 | 파라미터 수 |
|---|---|---|
| Original BSN (Wu et al. [38]) | Self-Supervised | 6.6M |
| AP-BSN (Ours) | Self-Supervised (Noisy-only) | 3.7M |
| DIDN [41] | Unsupervised / Unpaired | ~16.2M |
| C2N [19] | Unsupervised / Unpaired | ~16.2M |
| MWCNN [28] | Unsupervised / Unpaired | ~16.2M |
| 항목 | AP-BSN의 특징 |
|---|---|
| 학습 데이터 | Noisy image only (clean GT ❌) |
| 네트워크 규모 | 기존 BSN 대비 약 44% 감소 |
| 구조 복잡도 | MDC → 단순 DC sequence |
| 성능 | AP-BSN w/o R³도 경쟁력 있는 성능 |
| 장점 | 작은 모델 + Self-Supervised + Real-world noise 대응 |
Effects of aliasing artifacts

훈련 및 추론 중 Aliasing artifacts에 대해서 알아보기 위해서 깨끗한 SIDD 이미지만을 사용하고자 합니다. 이 때, 깨끗한 이미지는 노이즈의 강도가 0이며 노이즈가 공간적으로 상관이 없고 평균이 0인 이미지들을 의미합니다. 따라서, PD-BSN은 깨끗한 이미지를 입력 받기 떄문에 이를 그대로 출력하는 identity mapping을 학습해야 합니다. 그러나 fig.S2b, fig.S2C에서 볼 수 있듯이, 스트라이드가 2인 경우 BSN이 identity mapping을 학습하는 반면, 스트라이드가 5인 경우, Identity mapping이 아님을 확인할 수 있습니다. 반면, 본 논문에서 제안하고 있는 AP-BSN을 활용하면 BSN은 고주파 성분을 제거하지 않고 이미지 구조를 잘 보존하는 것을 볼 수 있습니다. 즉, 스트라이드를 5로 설정한 PD-BSN의 경우, Aliasing artifacts가 Denoising model의 방해 요소 인식하는 것을 확인할 수 있습니다. 이는 추론 중에 해당 아티팩트를 제거하는 것이 이미지의 디테일을 지우는 것과 같기 때문에 성능을 상당히 저하하기 때문입니다.
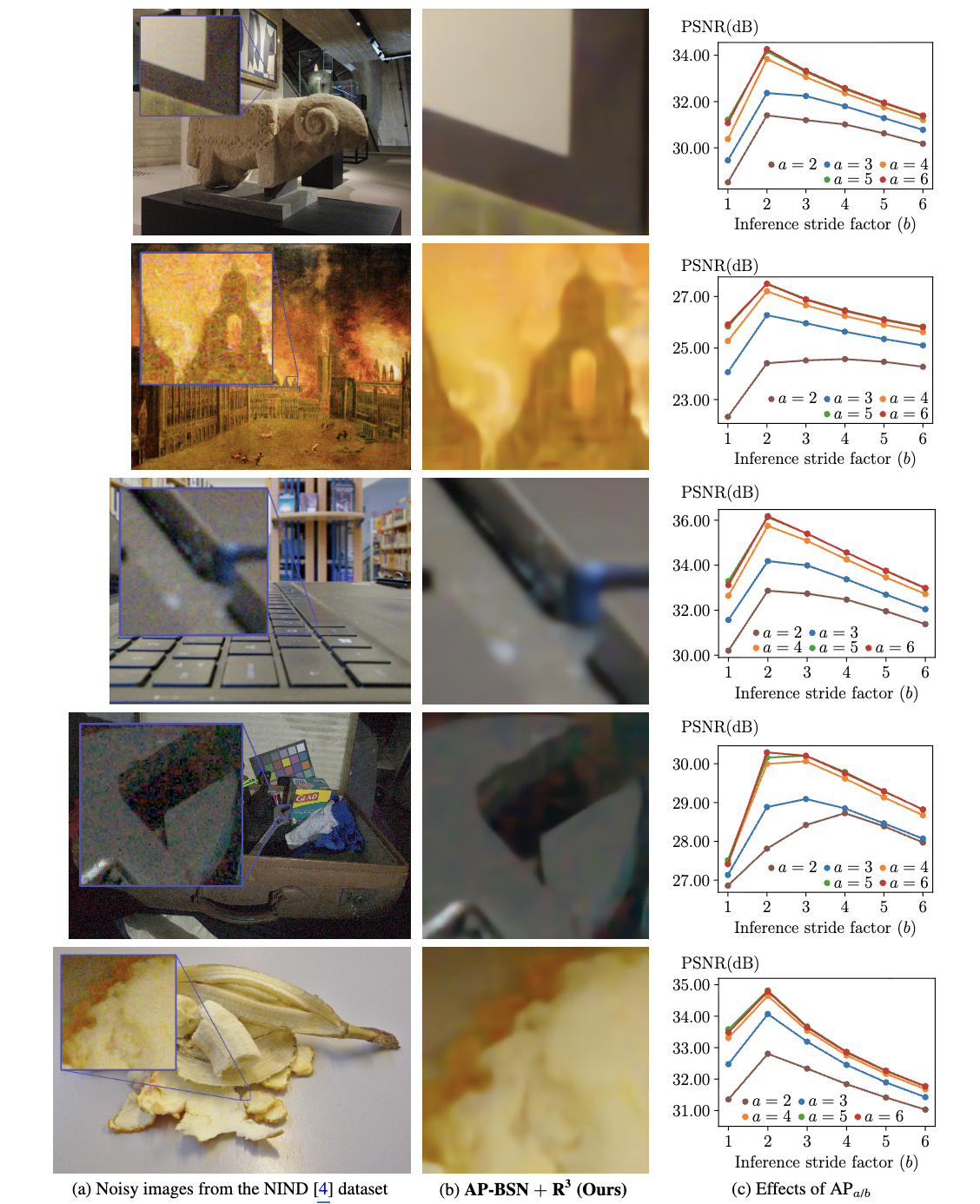
위 실험은 NIND 데이터셋에서 수행한 AP-BSN + R³의 Denoising 결과를 보여줍니다. NIND 데이터셋의 경우, SIDD 데이터셋과 노이즈 특성이 다르기 때문에, 스트라이드 계수를 훈련 시 6으로 높이는 경우, 일부 샘플에서 더 좋은 성능을 보임을 확인할 수 있지만 평균적으로는 본 논문에서 제안하는 스트라이드 계수를 5로 훈련하는 것이 더 좋은 일반화 성능을 보여줌을 확인할 수 있습니다.
Additional qualitative results

DND 벤치마크와 SIDD validation datasets에 대한 다양한 Denoising method 간의 추가적인 비교를 수행한 결과입니다. R2R과 같이 몇몇의 모델에서는 실험에 대한 결과를 확인할 수 있는 경우도 존재하였기 떄문에, 최대한 정량적으로 비교 가능한 기법들과 함께 비교하고자 합니다.
Results on real-world inputs

AP-BSN은 실제 sRGB 이미지를 처리하도록 설계되었으며 clean-noisy iamge pair가 존재하지 않아도 fully self-supervised learning이기 때문에 단일 노이즈 이미지에 모델을 직접 적용할 수 있습니다. 이를 위해서 삼성 갤럭시 스마트폰을 사용하여 높은 ISO 조건에서 실제 노이즈 이미지를 캡처했습니다. 일반적으로 최신 스마트폰 카메라에는 소프트웨어 기반 Denoising algorithm을 활용합니다. 따라서, 먼저 Raw 획득하고 시뮬레이션 된 ISP 를 활용하여 sRGB 이미지를 얻은 뒤 AP-BSN에 적용하고자 합니다. 카메라 내부에 있는 ISP 과정과 DnCNN과 비교했을 때, 노이즈의 신호를 효과적으로 억제하면서 훨씬 더 선명하게 복원하는 것을 볼 수 있습니다.
Qualitative improvement by R³

제안된 AP-BSN의 추가적인 파라미터 없이 성능을 향상 시킨 R³의 유무에 대한 비교를 수행하고자 합니다. R³가 없는 경우, blocky artifacts를 생성하는 것을 볼 수 있습니다. 제안된 R³를 활용하는 경우 추가적인 파라미터 없이도 부드럽고 자연스러운 이미지 구조를 복원할 수 있음을 확인할 수 있습니다.
AP-BSN의 대한 논문 리뷰를 마무리해보도록 하겠습니다.
본 논문은 단순히 훈련과 추론 시 동일한 메커니즘을 활용해야 한다는 고정관념을 깨주는 좋은 자료인 것 같습니다. 특히, 이 비대칭성을 단순히 말로만 풀어서 설명하는 것이 아닌 왜 이러한지에 대한 다양한 실험적인 연구가 존재하여 보다 더 해당 주장에 대해서 신빙성을 높일 수 있는 것 같습니다. 최근 읽어본 논문 가운데 가장 많은 실험적 연구를 수행하였고 이를 통해 주장을 뒷받침하기 때문에 추후에 논문 작업 시, 좋은 참고자료가 될 것 같습니다.
해당 논문에 대한 실험은 AP-BSN 구현 github
해당 페이지를 참고해주시면 감사하겠습니다!
감사합니다.
