
안녕하세요.
이번에 리뷰할 논문은 바로 "Noise2Void - Learning Denoising from Single Noisy Images" 입니다. 본 논문은 Noise2Noise 이후의 후속 연구로 단일 noisy image로만 입력으로 활용하여 다양한 분야에서 적용이 가능한 장점이 존재하는 연구입니다. 특히, 논문의 흐름이 제안하고자 하는 기법에 대한 구체적인 설명과 구체적인 구현, 다양한 모델들과의 비교, 제안하는 기법의 한계점에 대한 실험 등 상당히 완성도가 높은 논문인 것 같습니다. 그럼 바로 논문을 리뷰해보도록 하겠습니다.
Abstract
Image denoising 분야는 (noisy input data, clean target data) 쌍으로 학습되는 Discriminative Deep Learning method에 의해 지배되고 있습니다. 최근, N2N과 같이 Clean target data가 없어도 학습할 수 있는 method도 나오고 있습니다. N2N에서 한 단계 더 나아간 N2V 기법을 제안하고 있습니다. 해당 method는 noisy input data, clean target 데이터 모두 학습에 요구하지 않습니다. 결과적으로 N2V는 노이즈 제거 대상 데이터 자체로 직접 학습할 수 있게 해주므로, 기존의 방법으로는 적용할 수 없는 다양한 task에 적용이 가능합니다. 특히, noisy input data, clean target data를 수집하기 어려운 biomedical 분야에서도 활용할 수 있습니다. N2V를 clean target data, noisy input data를 활용하는 기존 연구들과 비교하고자 하며 직관적으로 N2V는 학습 중에 더 많은 정보를 가진 방법보다 성능이 우수할 것이라 기대할 수는 없습니다. 그럼에도 불구하고, N2V의 노이즈 제거 성능은 적당히 저하되며 훈련 없는 노이즈 제거 방법과 비교했을 때 유리하다는 것을 볼 수 있습니다.
Introduction
영상 노이즈 제거는 노이즈가 있는 영상 x = s + n에서 s와 n을 분리하는 작업입니다. 노이즈 제거 방법은 일반적으로 s의 픽셀 값들이 통계적으로 독립적이지 않다 즉, 서로 상관 관계가 존재한다는 가정을 수행하게 됩니다. 다시 말해, 주변 픽셀을 관찰하여 예측하고자 하는 픽셀을 예측할 수 있음을 의미합니다.
많은 연구에서 마르코프 랜덤 필드(MRF)를 통해 이러한 상호 의존성을 명시적으로 모델링했습니다. 최근 몇 년 동안, CNN은 해당 픽셀의 Receptive field 내 주변 patch로부터 픽셀 값을 예측하도록 다양한 방식으로 학습되었습니다.
일반적으로 위와 같은 시스템은 노이즈가 있는 입력 영상과 해당하는 깨끗한 영상인 (noisy input data, clean target image)를 학습에 요구합니다. 그런 다음 네트워크 파라미터들은 네트워크의 예측과 ground truth 간의 적절하게 공식화된 loss를 최소화하도록 조정됩니다.
Ground truth가 없는 경우, 이러한 방법은 학습 기법들은 활용할 수가 없는 문제점이 존재합니다. 이를 해결하기 위해서 ground truth image를 noisy input data로 매핑하도록 훈련하는 대신, N2N은 동일한 신호 s에서 조건부 독립인 노이즈 신호 n을 독립적으로 추출하여 (s + n, s + n') 간의 mapping을 학습하려고 시도합니다. 당연히 신경망은 하나의 노이즈가 있는 이미지에서 다른 노이즈가 있는 이미지를 완벽하게 예측하도록 학습할 수 없지만 해당 기법을 활용하며 Clean target image를 활용하는 Traditional method와 비슷한 결과를 생성해낼 수 있습니다. 즉, Clean target image를 얻기 힘든 경우, N2N 기법을 활용하면 훈련이 가능하지만 동일한 신호인 s에서 서로 독립적인 노이즈(n, n')을 캡처해야만 합니다.
N2N 훈련의 이러한 장점에도 불구하고 이 접근 방식에는 적어도 두 가지 단점이 존재합니다.
- 먼저, N2N 훈련은 (nosy input data, noisy input data) 쌍을 요구합니다.
- 두 번째로는 이러한 동일한 s에서 서로 독립적인 noise 이미지를 얻기 위해서는 정적인 장면에 대해서만 가능합니다.
이 두 가지 제한 사항을 모두 극복하는 새로운 훈련 방식인 NOISE2VOID(N2V)를 제시합니다. N2N과 마찬가지로 N2V도 깨끗한 원본 데이터 없이도 고품질 디노이징 모델을 훈련할 수 있다는 관찰을 활용합니다. 그러나 N2N 또는 전통적인 훈련과 달리 N2V는 noisy input data pairs 또는 clean target images pairs 모두 없는 데이터에도 적용할 수 있습니다. 즉, N2V는 Self-supervised training method입니다. 이 연구에서는 두 가지의 간단한 통계적 가정을 합니다.
- 신호 s는 픽셀 단위로 독립적이지 않다.
- 노이즈 n은 신호 s가 주어졌을 때 조건부로 픽셀 단위로 독립적이다.
우리는 BSD68 데이터셋과 시뮬레이션된 현미경 데이터셋에서 N2V의 성능을 평가합니다. 그런 다음 우리는 전통적으로 훈련된 네트워크, N2N, BM3D, non-local means, mean-and-median filters에 대해서도 비교합니다. 추가적인 정보를 훈련 중에 활용할 수 있는 방법보다 제안하는 기법이 더 나을 것으로 기대할 수는 없지만, 약간의 Denoising 성능은 약간만 저하되며 여전히 BM3D보다 우수함을 관찰할 수 있습니다.
또한, cryo-TEM 이미지와 Cell Tracking Challenge의 두 데이터셋 총 3가지 생물의학 데이터셋에서 N2V를 적용합니다. 해당 task의 경우, 전통적인 방식의 경우, 원본 데이터 부족으로 인해서 적용할 수 없으며 N2N의 경우, cryo-TEM 데이터셋에서만 적용이 가능합니다. 그 결과 제안하고 있는 기법은 엄청난 실용적 유용성을 보여줍니다.
요약하자면 주요 기여는 다음과 같습니다.
- 단일 노이즈 이미지만 필요한 Denoising CNN 훈련을 위한 새로운 접근 방식인 NOISE2VOID의 소개
- 기존 CNN 훈련 방식 및 비 훈련 방식으로 얻은 결과와 N2V의 결과 비교
- N2V의 접근 방식에 대한 타당성 및 효율적인 구현에 대한 자세한 설명
Related Work
아래에서는 위에서 언급한 Denoising 작업이 아닌 더 일반적인 이미지 복원 작업을 다루는 다른 벙법들을 논의합니다. 이에는 JPEG 아티팩트나 블러와 같은 다양한 왜곡을 제거하는 작업이 포함됩니다. N2V에서는 보다 더 좁은 분야인 디노이징 작업에 머무르는데 이는 N2V가 여러 번의 노이즈 관측이 평균적으로 실제 신호를 복원할 수 있다는 사실에 의존하기 때문입니다. 하지만, 블러와 같은 일반적인 왜곡에서는 이러한 사실이 성립하지 않습니다.
우리는 N2V를 여러 방법론적 범주가 교차하는 지점에 위치하여 각 범주에서 가장 관련 있는 연구들에 대해서 간략하게 논의할 것입니다. 단, N2N의 경우 이미 충분히 논의했기 때문에 여기서는 생략합니다.
동시에 진행된 연구인 N2S는 입력의 일부를 제거하는 아이디어에 기반한 자기 지도 학습 방법을 제안합니다. 해당 방식은 픽셀을 제거하는 것뿐만 아니라 일반적으로 변수들의 그룹을 제거하는 경우에도 적용 가능함을 보여줍니다. 즉, N2V보다 더 일반적인 self-supervised masking 프레임워크입니다.
Discriminative Deep Learning Methods
판별적 딥러닝 방법은 테스트 데이터에 적용되기 전에 이미 annotation된 학습 데이터셋으로 모델 파라미터를 오프라인으로 훈련합니다.
디노이징 작업을 위해 처음으로 CNN을 적용합니다. 오늘날 성공적인 방법들이 여전히 수행하는 해당 연구의 기본적인 설정을 소개합니다.
- 디노이징은 회귀 작업으로 간주되며 CNN은 예측과 깨끗한 원본 데이터 간에 계산된 손실을 최소화하도록 학습합니다.
디노이징을 위한 매우 깊은 CNN 아키텍처를 도입하여 최첨단 결과를 달성합니다. 이 접근 방식은 잔차 학습의 아이디어를 기반으로 합니다. 해당 기법에서 CNN은 깨끗한 신호가 아닌, 각 픽셀의 노이즈를 예측하려고 시도하며, 후속 단계에서 신호를 계산할 수 있게 합니다. 해당 구조는 다양한 수준의 노이즈로 손상된 이미지의 디노이징을 위해 단일 CNN을 훈련할 수 있게 합니다. 그들의 아키텍처는 풀링 레이어를 완전히 사용하지 않습니다.
거의 같은 시기에 디노이징 작업을 위해 상호 보완적인 매우 깊은 인코더-디코더 아키텍처를 도입했습니다. 해당 기법 역시 잔차 학습을 활용하지만, 해당 인코딩 및 디코딩 모듈 간의 대칭 스킵 연결을 도입함으로써 이를 수행합니다. 마찬가지로 해당 기법 또한 다양한 수준의 노이즈에 대해 단일 네트워크를 사용할 수 있습니다.
순환 지속 메모리 유닛을 아키텍처의 일부로 사용하며 이전 방법들을 더욱 개선했습니다.
최근에는 형광 현미경 데이터의 맥락에서 이미지 복원을 위한 CARE 소프트웨어 프레임워크를 발표했습니다. 해당 기법은 저노출 및 고노출 이미지 쌍을 기록하여 훈련 데이터를 얻습니다. 생물학적 샘플이 노출 간에 움직이지 않아야 하므로 이는 어려운 절차가 될 수 있습니다. 본 논문은 해당 연구를 실험의 시작점으로 사용하며, 특정 U-Net 아키텍처를 포함합니다.
N2V는 원칙적으로 언급된 어떤 아키텍처와도 적용될 수 있다는 점에 유의해야 합니다. 그러나 이와 관련하여 흥미로운 특징을 제시하는데, 그들의 잔차 아키텍처는 각 픽셀에서 노이즈가 있는 입력에 대한 지식을 요구하기 때문입니다. 이를 위해서 N2V에서는 이 입력이 기울기 계산 시 마스킹 됩니다.
Internal Statistics Methods
Internal Statistics Methods는 사전에 정답 데이터로 훈련될 필요가 없습니다. 대신, 테스트 이미지에 직접 적용되어 필요한 모든 정보를 추출할 수 있습니다. N2V는 테스트 이미지에서 직접 훈련을 가능하게 하므로 Internal Statistics Methods라고도 볼 수 있습니다.
Buades et al에서 고전적인 잡음 제거 접근 방식인 비지역 평균(non-local means)을 도입했습니다. N2V와 마찬가지로, 이 방법은 노이즈가 있는 주변 픽셀을 기반으로 픽셀 값을 예측합니다.
BM3D는 Classic한 Internal Statistics Methods입니다. 이는 자연 이미지가 일반적으로 반복되는 패턴을 포함한다는 아이디어에서 기반합니다. BM3D는 유사한 패턴을 함께 그룹화하고 공동으로 필터링하여 이미지의 잡음 제거를 수행합니다. 해당 기법의 단점은 테스트 시간 동안의 계산 비용입니다. 대조적으로, N2V는 훈련 중에만 광범위한 계산을 요구합니다. 특정 종류의 데이터에 대해서 CNN이 훈련이 되면, 추가적인 이미지에는 효율적으로 적용될 수 있습니다.
Ulyanov et al.에서 CNN의 구조가 본질적으로 자연 이미지의 분포와 공명하며 추가 훈련 데이터 없이 이미지 복원에 활용될 수 있음을 보여줍니다. 그들은 임의의 상수 입력을 CNN에 공급하고 이를 단일 노이즈 이미지를 출력하도록 근사하도록 훈련합니다. Ulyanov et al.은 수렴 전에 적절한 순간에 훈련 과정을 중단하면 네트워크가 정규화된 잡음 제거 이미지를 출력한다는 것을 발견했습니다.
Generative Models
GAN을 기반으로 하는 이미지 복원 접근 방식을 제시합니다. 저자들은 노이즈가 있는 이미지와 깨끗한 이미지로 구성된 쌍이 아닌 훈련 샘플을 사용합니다. 이때, GAN을 통해서 노이즈를 생성하고 해당하는 깨끗한 이미지와 노이즈가 있는 이미지 쌍을 생성하여 전통적인 지도학습 설정에서 훈련 데이터로 사용됩니다. N2V와 달리, 해당 접근 방식은 훈련 중에 깨끗한 이미지를 요구합니다.
마지막으로, Van Den Oord et al의 작업을 언급하고 싶습니다. 해당 연구는 잡음 제거에 사용되지는 않지만, 정신적으로 N2V와 유사한 생성 모델을 제시합니다. N2V와 마찬가지로, Van Den Oord et al.은 신경망을 훈련하여 주변 픽셀을 기반으로 보이지 않는 픽셀 값을 예측합니다. 그런 다음 이 네트워크는 합성 이미지를 생성하는 데 사용됩니다. 그러나 N2V는 회귀 작업을 위해 네트워크를 훈련하는 반면, 해당 기법은 각 픽셀에 대한 확률 분포를 예측합니다. 또 다른 차이점은 수용 필드의 구조에 있습니다. Van Den Oord et al.은 이미지 위로 이동하는 비대칭 구조를 사용하는 반면, 우리는 항상 정사각형 수용 필드에서 중앙 픽셀을 마스킹합니다.
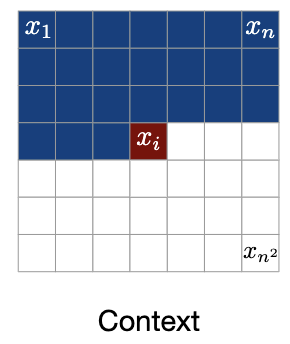
Methods
먼저, 이미지 형성 모델에 대해서 논의하겠습니다. 그런 다음, 전통적인 CNN 훈련과 N2N 방법에 대한 간략한 요약을 제공하겠습니다. 마지막으로, N2V와 그 구현에 대해서 소개하도록 하겠습니다.
Image Formation
noisy image를 x로 두었을 때, x = s + n으로 볼 수 있습니다. 이때, 이들의 joint distribution은 다음과 같습니다.
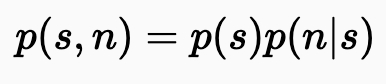
다음은, N2V에서 수행한 첫 번째 가정인, 신호는 서로 독립적이지 않음을 나타내는 수식입니다.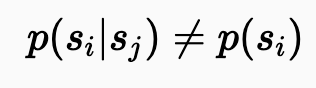
주변 픽셀이 주어졌을 때, 중앙 픽셀의 조건부 확률 분포는 아무 정보 없이 중앙 픽셀을 추정할 때의 사전 확률 분포와 다름을 의미하고 있으며 이는 위에서 언급한 첫 번째 가정인 s는 서로 관련성이 있음을 보여줍니다.
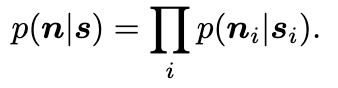
이 해당 수식은 signal s가 주어졌을 때 전체 노이즈 n의 분포는 각 픽셀의 노이즈 n_i가 서로 독립인 조건부 확률의 곱으로 분해됩니다. 즉, 이는 위에서 언급한 두 번째 가정인 노이즈는 signal에 의존하고 픽셀 간에는 서로 독립적임을 의미합니다.
이때, 노이즈의 평균을 0이라고 가정하고 이는 아래와 같은 수식을 유도할 수 있습니다.
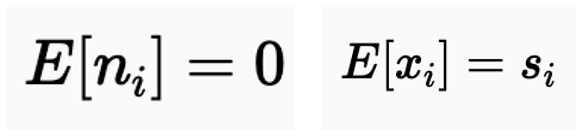
위의 수식을 다른 말로 하면, 동일한 신호로 여러 이미지를 얻었지만 서로 다른 노이즈를 가지고 평균을 낸다면, 결과는 실제 신호에 접근할 것입니다. 이는 고정된 삼각대에 장착된 카메라를 사용하여 정적인 장면의 여러 사진을 기록하여 평균을 내면 원래 실제 신호에 접근할 것이라고 표현할 수도 있습니다.
Traditional Supervised Training
Traditional Supervised Training에서는 CNN을 훈련하여 x에서 s로의 매핑을 구현하는 데 관심이 있습니다. 우리는 하나의 이미지를 입력으로 받아 다른 하나를 출력으로 예측하는 FCN을 가정하고자 합니다.
여기서는 이러한 네트워크에 대해 약간 다르지만 동등한 관점을 취하고자 합니다. CNN 출력의 각 픽셀 예측은 특정 수용필드를 가지며, 이는 픽셀 예측에 영향을 미치는 입력 픽셀들의 집합입니다. 픽셀의 수용 필드는 일반적으로 해당 픽셀 주변의 정사각형 패치입니다.
이러한 고려 사항을 바탕으로, 우리는 CNN을 입력으로 패치를 취하고 패치 중심에 위치한 단일 픽셀에 대한 예측을 출력하는 함수로도 볼 수 있습니다. 해당 관점을 따르면, 전체 이미지의 노이즈 제거는 겹치는 패치를 추출하여 네트워크에 하나씩 공급함으로써 달성될 수 있습니다. 결과적으로는 CNN을 다음과 같은 함수로 정의할 수 있습니다.
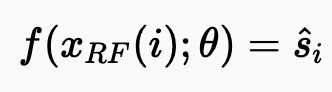
여기서 세타는 우리가 훈련하고자 하는 CNN 매개변수 벡터를 나타냅니다.
전통적인 지도학습 훈련에서는 노이즈가 있는 입력 이미지와 함께 깨끗한 실제 신호인 (x, s)의 집합으로 주어집니다. CNN의 패치 기반 관점을 다시 적용함으로써, 우리는 훈련 데이터를 쌍을 (x^RF(i)_j, s)로 볼 수 있습니다. 이제 우리는 픽셀 단위 손실을 최소화하기 위해 이 쌍들을 사용하여 매개변수 θ를 조정하며 손실 함수로 MSE Loss를 고려합니다.
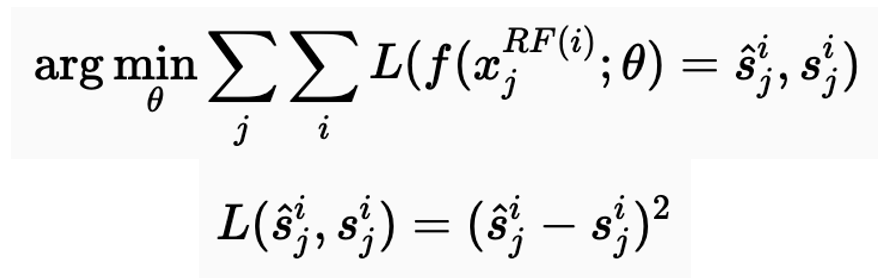
Noise2Noise Training
N2N은 Clean target image 없이도 처리할 수 있게 해줍니다. 대신, 노이즈가 있는 이미지 쌍(x_i, x'_j)으로 시작하며 동일한 signal 분포인 s로부터 두 독립적인 노이즈 샘플입니다.
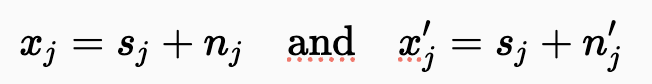
노이즈가 있는 입력에서 노이즈가 있는 타겟으로의 매핑을 학습하려고 시도함에도 불구하고, 훈련은 올바른 해로 수렴할 것입니다. 이 현상의 핵심은 노이즈가 있는 입력의 기댓값이 깨끗한 신호와 같다는 사실에 있습니다.
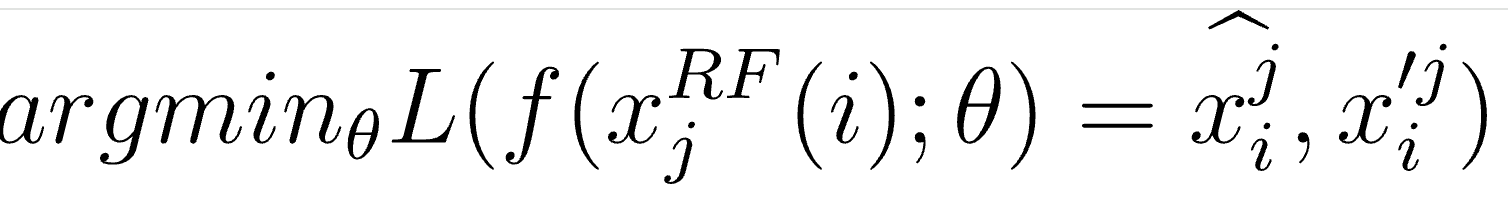
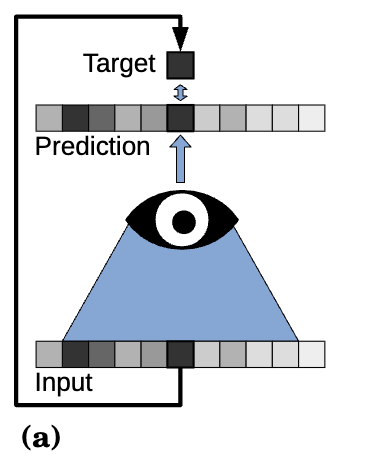
Noise2Void Training
여기서 본 논문은 한 걸음 더 나아갑니다. 본 논문은 훈련 샘플의 쌍인 입력과 타겟을 단일 노이즈가 있는 훈련 이미지에서 파생시킬 것을 제안합니다. 만약 단순히 입력으로 패치를 추출하고 그 중심 픽셀을 타겟으로 사용한다면, 우리의 네트워크는 입력 패치의 중심 값을 출력으로 직접 매핑함으로써 항등함수를 학습하게 될 것입니다.
그럼에도 불구하고 단일 노이즈 이미지로부터 훈련이 어떻게 가능한지 이해하기 위해, 우리는 특별한 Receptive field를 가진 네트워크 아키텍처를 사용한다고 가정해 봅시다. 우리는 이 네트워크의 Receptive field가 중심에 블라인드 스팟을 가지고 있다고 가정합니다. 픽셀에 대한 CNN 예측은 해당 위치의 입력 픽셀을 제외한 정사각형 이웃의 모든 입력 픽셀에 의해 영향을 받습니다. 이러한 유형의 네트워크를 blind-spot network라고 부릅니다.
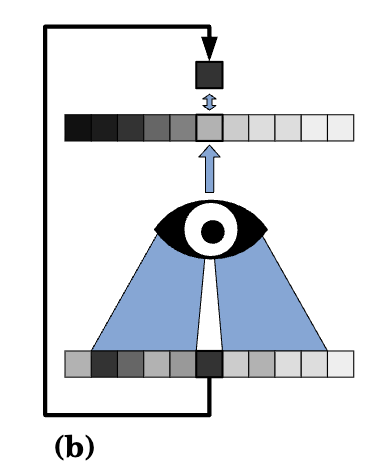
Blind-spot network는 위에서 설명한 어떤 훈련 방식과도 함께 훈련될 수 있습니다. 일반적인 네트워크와 마찬가지로, 우리는 각각 깨끗한 타겟 또는 노이즈가 있는 타겟을 사용하여 전통적인 훈련 또는 N2N을 적용할 수 있습니다. blind-spot network는 예측에 사용할 수 있는 정보가 약간 적기 때문에 일반적인 네트워크에 비해 정확도가 약간 저하될 것으로 예상할 수 있습니다. 그러나 전체 수용 필드에서 단 하나의 픽셀만 제거된다는 점을 고려할 때, 여전히 합리적으로 잘 수행될 것으로 가정할 수 있습니다.
블라인드 스팟 아키텍처의 본질적인 장점은 항등 함수(identity)를 학습할 수 없다는 것입니다. 이것이 왜 그런지 고려해 봅시다. 노이즈는 신호가 주어졌을 때 픽셀별로 독립적이라고 가정하므로, 이웃 픽셀 값에 대한 정보를 전달하지 않습니다. 따라서 네트워크가 사전 기대값보다 더 나은 추정치를 생성하는 것은 불가능합니다.
그러나 신호는 통계적 종속성을 포함한다고 가정합니다. 결과적으로 네트워크는 주변을 살펴봄으로써 픽셀의 신호를 여전히 추정할 수 있습니다.
결론적으로, 블라인드 스팟 네트워크를 사용하면 동일한 노이즈가 있는 훈련 이미지에서 입력 패치와 타겟 값을 추출할 수 있습니다. 우리는 경험적 위험을 최소화하여 이를 훈련할 수 있습니다.
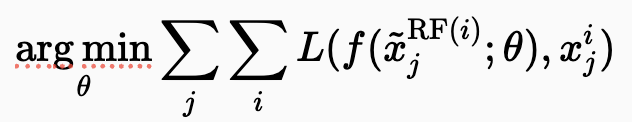
즉, N2V에서 사용하는 noisy 타깃은 N2N에서 사용하는 두 번째 noisy 이미지의 타깃과 통계적으로 동등하며, 두 경우 모두 동일한 clean signal을 포함하고 노이즈 성분만이 동일 분포에서 독립적으로 샘플링된다는 점에서 기대값 기준으로 동일한 학습 목표를 갖고 있습니다.
우리는 블라인드 스팟 네트워크가 원칙적으로 개별 노이즈 훈련 이미지만 사용하여 훈련될 수 있음을 보았습니다. 그러나 이러한 네트워크를 효율적으로 작동하도록 구현하는 것은 간단하지 않습니다. 이 문제를 피하고 표준 CNN으로 동일한 속성을 달성하기 위해 마스킹 전략을 제안합니다. 입력 패치의 중앙 값을 주변 영역에서 무작위로 선택된 값으로 대체합니다. 이는 픽셀의 정보를 효과적으로 지우고 네트워크가 항등 함수를 학습하는 것을 방지합니다.
Implementation Details
앞서 설명한 N2V의 학습 방식을 그대로 구현하면, 하나의 출력 픽셀에 대한 그래디언트를 계산하기 위해서도 전체 패치를 네트워크에 통과시켜야 하므로 계산 효율이 매우 떨어지게 됩니다. 이를 완화하기 위해 저자들은 근사 기법을 도입하는데, 노이즈가 있는 학습 이미지로부터 네트워크의 수용 필드보다 충분히 큰 64×64 크기의 패치를 무작위로 추출하고, 각 패치 내에서 픽셀들이 한곳에 몰리지 않도록 계층적 샘플링을 통해 N개의 픽셀을 선택한다. 이후 선택된 픽셀들은 입력에서 마스킹되며, 해당 위치의 원래 노이즈 픽셀 값을 타깃으로 사용하여 학습을 진행한다. 이때 예측된 이미지 전체에 대해 손실을 계산하는 것이 아니라, 선택된 픽셀 위치에서만 손실이 계산되도록 하고 나머지 픽셀에 대해서는 손실을 0으로 설정함으로써, 한 번의 forward–backward 과정에서 여러 픽셀에 대한 그래디언트를 동시에 계산할 수 있도록 한다. 이러한 방식은 계산 효율을 크게 향상시키면서도 N2V의 블라인드-스팟 학습 원리를 유지하며, 구현은 CSBDeep 프레임워크(현미경·자연 이미지 복원을 위한 딥러닝 실험을 빠르고 안정적으로 구현하기 위한 표준화된 프레임워크)를 기반으로 U-Net 아키텍처를 사용하고 각 활성화 함수 이전에 배치 정규화를 추가하는 표준 설정을 따른다.
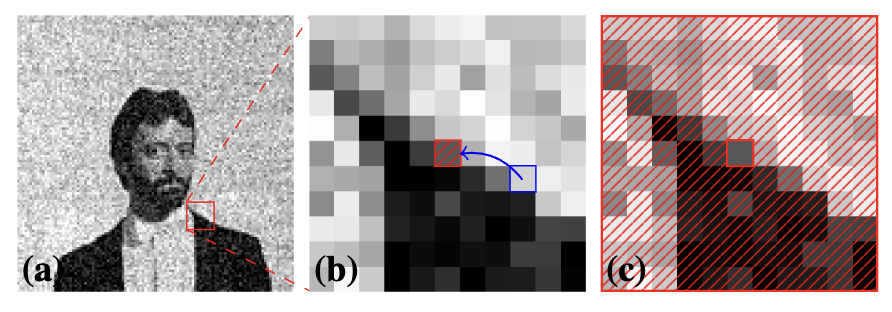
- (a) 노이즈 이미지: 훈련을 시작할 단일 잡음 이미지 (x)입니다.
- (b) 입력 패치 마스킹: 입력 이미지 x에서 64x64 픽셀 크기의 패치(patch)를 무작위로 추출합니다. 이 패치 안에서 N개의 픽셀(여기서는 N=64)을 무작위로 선택합니다(파란색 사각형). 그리고 이 선택된 픽셀들의 원래 강도 값을 주변 영역에서 무작위로 선택된 다른 픽셀의 값으로 대체합니다(빨간색 줄무늬 사각형). 이렇게 하면 원래 선택된 픽셀의 정보가 지워져 네트워크가 해당 픽셀의 값을 직접적으로 볼 수 없게 됩니다. 이 수정된 패치가 네트워크의 입력이 됩니다.
- (c) 목표 패치: 목표(target)는 원본 잡음 이미지 x에서 마스킹 된 픽셀의 원래 값입니다. 네트워크는 마스킹 된 입력 패치를 보고, 마스킹 된 픽셀의 원본 잡음 값을 예측하도록 훈련됩니다.
Experiments
BSD68(가우시안 노이즈)
🔹 데이터 Information
| 항목 | 내용 |
|---|---|
| 학습 데이터 | 400장, 180×180 그레이스케일 이미지 |
| 테스트 데이터 | BSD68 그레이스케일 |
| 노이즈 모델 | Gaussian Noise (μ=0, σ=25) |
| 데이터 증강 | 90° 회전 ×3 + 좌우 반전 |
| 학습 패치 | 64×64 랜덤 패치 |
🔹 CNN 기반 방법 (Traditional / N2N / N2V)
| 항목 | 설정 |
|---|---|
| 네트워크 | U-Net |
| Depth | 2 |
| Kernel Size | 3 |
| Initial Feature Maps | 96 (깊어질수록 ×2) |
| Normalization | BatchNorm (activation 이전) |
| Output Activation | Linear |
| 프레임워크 | CSBDeep |
🔹 학습 전략
| 방법 | Batch Size | 학습 방식 |
|---|---|---|
| Traditional | 128 | Clean GT 사용 |
| Noise2Noise (N2N) | 16 | 노이즈 이미지 쌍 |
| Noise2Void (N2V) | 128 | 패치당 N=64 픽셀 마스킹 |
| 항목 | 설정 |
|---|---|
| Initial Learning Rate | 0.0004 |
| LR Schedule | Validation loss plateau 시 LR ×0.5 |
🔹 Training-free 방법
| 방법 | 설정 |
|---|---|
| BM3D | 기본 설정 |
🔹 BSD68(가우시안 노이즈) Result
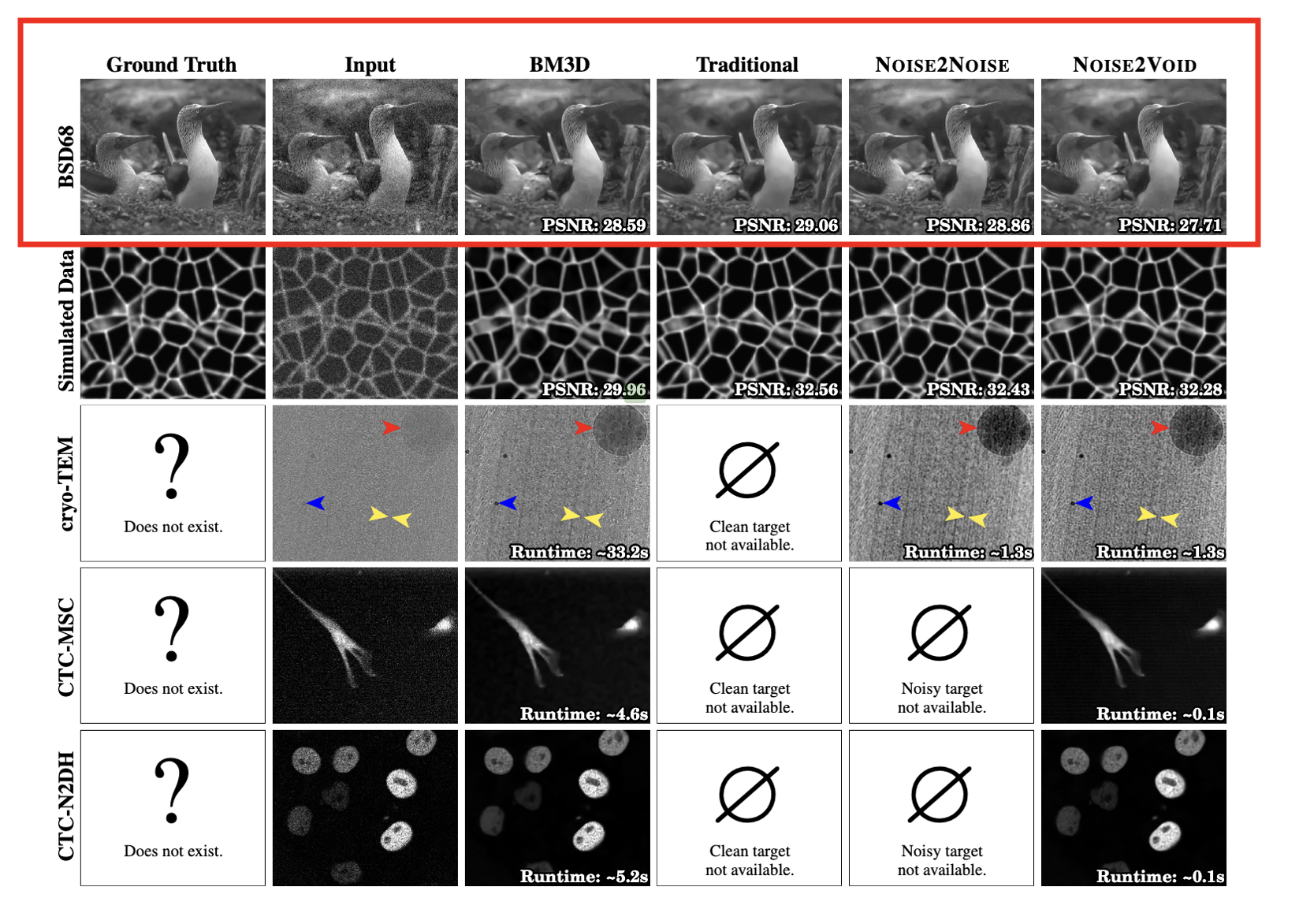
앞서 언급했듯이, N2V는 예측에 더 적은 정보를 활용할 수 있기 때문에 다른 훈련 방법보다 성능이 뛰어나기를 기대하지는 않습니다. 그럼에도 불구하고, 여기서는 N2V의 노이즈 제거 성능이 BM3D의 성능보다 적당히 낮아지는 것을 관찰합니다.(이는 다른 데이터에서는 해당되지 않습니다)
Simulated data(현미경 데이터, Poisson + Gaussian)
현미경 데이터의 경우, 거의 실제와 같은 품질의 현미경 데이터 획득은 불가능하거나 매우 어렵고 비용이 많이 듭니다. 원하는 PSNR 값을 계산하기 위해 실제 데이터가 필요하므로, 두 번째 실험 세트에 시뮬레이션된 데이터셋을 사용하기로 결정했습니다. 이를 위해 막으로 표지된 세포 상피를 시뮬레이션하고, 먼저 포아송 노이즈를 적용한 다음 평균이 0인 가우시안 노이즈를 추가하여 형광 현미경의 일반적인 이미지 모방했습니다.
🔹 데이터 설정
| 항목 | 내용 |
|---|---|
| 데이터 생성 | 막으로 표지된 세포 상피 시뮬레이션 |
| 노이즈 모델 | Poisson → Gaussian (μ=0) |
| GT 존재 여부 | High-SNR GT + 2 Low-SNR 이미지 |
| 데이터 증강 | BSD68과 동일 |
| 학습 패치 | 64×64 |
🔹 CNN 기반 방법 (Traditional / N2N / N2V)
| 항목 | 설정 |
|---|---|
| 네트워크 | U-Net |
| Depth | 2 |
| Kernel Size | 5 |
| Initial Feature Maps | 32 |
| Normalization | BatchNorm |
| Output Activation | Linear |
🔹 학습 전략
| 방법 | Batch Size | 특징 |
|---|---|---|
| Traditional | 16 | GT 사용 |
| Noise2Noise (N2N) | 16 | 노이즈 쌍 사용 |
| Noise2Void (N2V) | 128 | 패치당 N=64 픽셀 마스킹 |
| 항목 | 설정 |
|---|---|
| Initial Learning Rate | 0.0004 |
| LR Schedule | CSBDeep 기본 스케줄 |
🔹 Simulated data Result
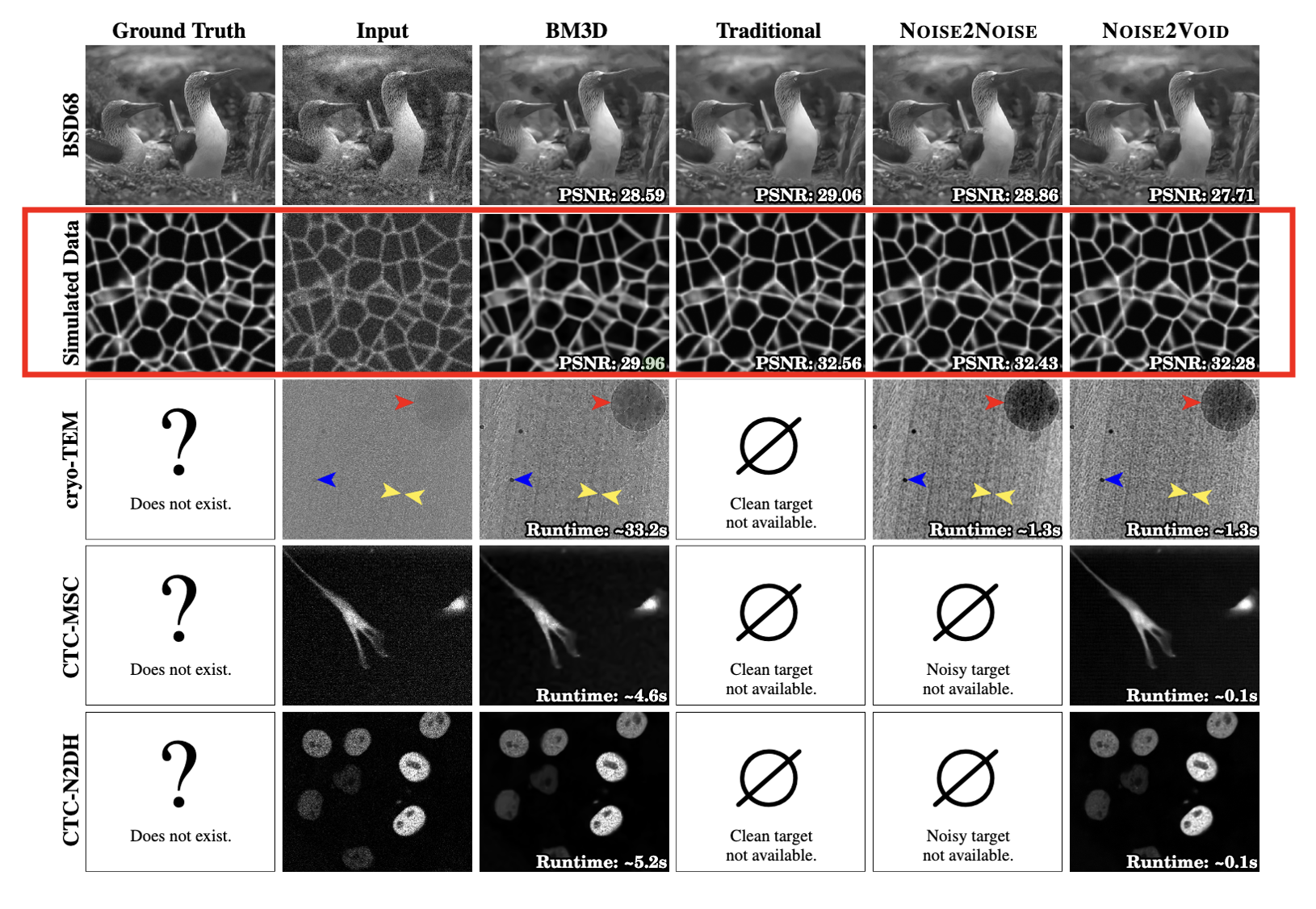
NOISE2VOID 학습의 노이즈 제거 품질을 확인할 수 있으며, 이는 전통적인 학습 및 NOISE2NOISE 학습과 거의 동일한 품질에 도달합니다. 모든 학습된 네트워크는 BM3D로 얻은 결과보다 명확하게 우수합니다.
실제 획득 현미경 data(Cryo-TEM, CTC-MSC, CTC-N2DH)
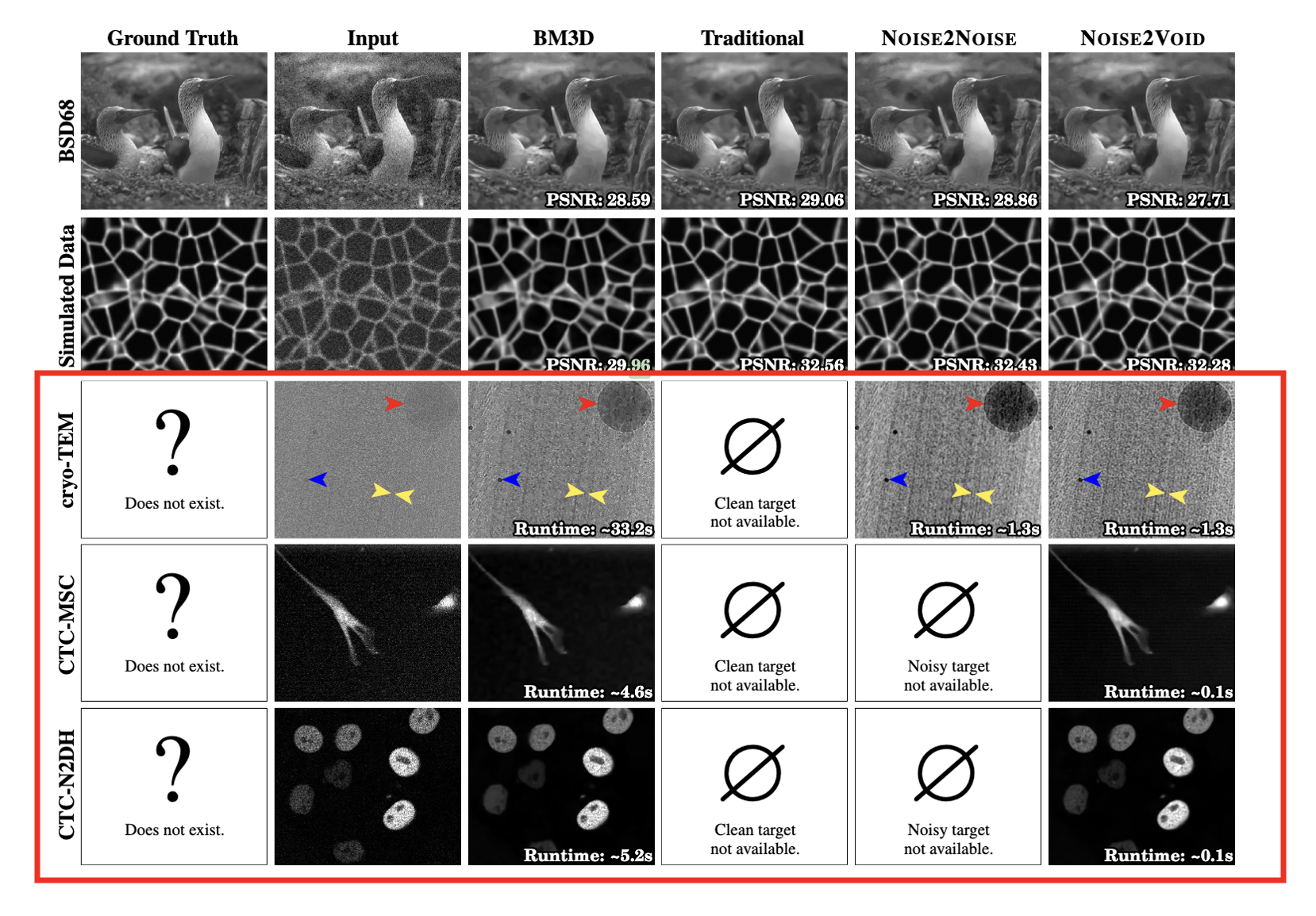
이전 섹션에서 언급했듯이, 고품질의 Ground truth 현미경 데이터는 일반적으로 사용 가능하지 않습니다. 따라서 우리는 더 이상 PSNR 값을 계산할 수 없습니다. 그렇기 때문에 해당 데이터셋에서는 시각적으로 각 모델의 성능의 차이를 보고 실행하는데 소요된 시간을 비교하고자 합니다.
🔹 데이터셋 구성
| 데이터 | 특징 | 적용 가능 방법 |
|---|---|---|
| Cryo-TEM | 노이즈 이미지 쌍 존재 | N2N, N2V, BM3D |
| CTC-MSC | GT/노이즈 쌍 없음 | N2V, BM3D |
| CTC-N2DH | GT/노이즈 쌍 없음 | N2V, BM3D |
🔹 CNN 기반 방법 (N2V / N2N)
| 항목 | 설정 |
|---|---|
| 네트워크 | U-Net |
| Depth | 2 |
| Kernel Size | 3 |
| Initial Feature Maps | 32 |
| Normalization | BatchNorm |
| Output Activation | Linear |
🔹 학습 전략 (N2V 기준)
| 항목 | 설정 |
|---|---|
| Batch Size | 128 |
| Masked Pixels per Patch | N = 64 |
| Initial Learning Rate | 0.0004 |
| Patch Size | 64×64 |
| Data Augmentation | 회전 + 미러링 |
🔹 Training-free 방법
| 방법 | 비고 |
|---|---|
| BM3D | GT 없는 데이터에서 비교 |
🔹 실제 획득 현미경 data Result
Errors and Limitations

위쪽 행 (a, b, c): 가장 큰 개별 픽셀 오류가 발생한 테스트 이미지의 확대된 일부를 보여줍니다.
- (a) Ground Truth: 노이즈가 없는 원본 이미지이며, 빨간 화살표는 특히 밝고 고립된 픽셀을 가리킵니다.
- (b) Traditionally trained network: 전통적인 방식으로 훈련된 네트워크의 결과입니다.
- (c) N2V trained network: Noise2Void 방식으로 훈련된 네트워크의 결과입니다.
N2V의 주요 가정 중 하나는 신호(s)가 픽셀 단위로 독립적이지 않다는 것입니다. 즉, 주변 픽셀의 정보를 통해 특정 픽셀의 값을 합리적으로 예측할 수 있다는 가정을 기반하는 예시입니다. 빨간 화살표로 표시된 픽셀처럼 매우 불규칙하거나 고립된 밝은 픽셀의 경우, 주변의 픽셀 정보만으로 해당 픽셀을 정확히 예측하기 어렵습니다. 그렇기 때문에 (c)의 결과를 보면 N2V는 이 고립된 밝은 픽셀을 효과적으로 복원하지 못하고 주변에 스며들거나 부드럽게 처리하는 경향을 보입니다.
아래쪽 행 (d, e, f): 전체 오류 합계가 가장 큰 테스트 이미지의 일부를 보여줍니다.
- (d) Ground Truth: 노이즈가 없는 원본 이미지입니다.
- (e) Traditionally trained network: 전통적인 방식으로 훈련된 네트워크의 결과입니다.
- (f) N2V trained network: Noise2Void 방식으로 훈련된 네트워크의 결과입니다.
그림 (d)와 같이 표면이 거칠거나 규칙적인 것이 아닌 불규칙적인 사진임을 확인할 수 있습니다. 즉, 이는 시그널이 서로 통계적으로 독립적이지 않다는 가정을 위배하는 예시입니다. 이때, 그림 (f)에서 (d)나 (e)에 비해 이미지가 다소 부드럽고 세부 묘사가 떨어진다는 것을 통해 확인할 수 있습니다. 이는 N2V는 노이즈 제거 과정에서 신호의 예측 불가능한 부분을 제거하는데, 이는 때때로 불규칙적인 신호 자체를 노이즈로 오인하여 제거할 수 있기 때문입니다.

N2V의 또 다른 주요 가정 중 하나는 노이즈는 픽셀 단위로 조건부 독릭적이라는 것입니다. N2V는 노이즈가 픽셀 단위로 독립적이라는 가정을 바탕으로 작동하는데, 구조화된 노이즈는 이 가정을 위반하기 때문에 N2V가 이를 제거하지 못하거나 오히려 드러낼 수 있음을 보여줍니다.
위쪽 행 (a, b, c):
- (a): 이 이미지는 구조화된 노이즈가 인위적으로 추가된 사진입니다. 노이즈가 전반적으로 존재하지만, 자세히 보면 미세한 체스판(checkerboard) 패턴과 같은 구조화된 노이즈가 신호와 함께 섞여 있습니다.
- (b) Traditionally trained network: 전통적인(traditional) 방식으로 학습된 CNN으로 노이즈를 제거한 결과로 전통적인 학습 방식은 깨끗한(clean) 원본 이미지(ground truth)를 가지고 노이즈가 있는 이미지와 비교하여 학습하기 때문에, 노이즈의 종류에 관계없이 대부분의 노이즈를 효과적으로 제거하여 깨끗한 이미지를 복원할 수 있습니다. 여기서는 체스판 패턴이 성공적으로 제거되었음을 알 수 있습니다.
- (c) N2V trained network: N2V로 학습된 CNN으로 노이즈를 제거한 결과입니다. N2V는 픽셀 단위로 독립적인 노이즈를 제거하도록 설계되었으므로, 불규칙한 노이즈는 제거하지만 구조화된 노이즈(체스판 패턴)는 신호의 일부로 간주하여 제거하지 못하고 오히려 선명하게 드러내는 모습을 보입니다.
아래쪽 행 (d, e):
- (d): 이 이미지는 실제 현미경 데이터(Fluo-C2DL-MSC 데이터셋)에서 관찰되는 구조화된 노이즈의 예시입니다.
- (e) N2V trained network: (c)와 마찬가지로 N2V는 무작위 노이즈는 제거하지만, 구조화된 노이즈인 줄무늬 패턴(structured noise)을 신호의 일부로 인식하여 제거하지 못하고 더 명확하게 드러내는 것을 볼 수 있습니다. 이는 N2V가 실제 데이터에서도 구조화된 노이즈를 신호로 오인하여 처리할 수 있음을 보여줍니다.
즉, 처음에 가정한 두 조건에 대해서 위배되는 경우, 오히려 성능이 좋지 않음을 한계점으로 이야기하고 있습니다.
Performance over Various Noise Levels
| 방법 | 학습 유형 | 사용 데이터 | 감독 정보 | 학습 필요 | 핵심 아이디어 / 원리 | 파라미터 튜닝 |
|---|---|---|---|---|---|---|
| DnCNN* | Supervised | BSD400 (학습) + BSD68 (테스트) | Clean GT | ✔ | Residual learning으로 노이즈 직접 예측 | 논문 값 사용 |
| Traditional* | Supervised | BSD400 + BSD68 | (Noisy, Clean) 쌍 | ✔ | Noisy → Clean 직접 회귀 | 학습 기반 |
| Noise2Noise (N2N)† | Weakly supervised | BSD400 + BSD68 | 독립 noisy pair | ✔ | 노이즈 평균 0 가정 | 학습 기반 |
| Noise2Void (N2V)‡ | Self-supervised | BSD400 + BSD68 | Single noisy image | ✔ | Blind-spot + masked MSE | 학습 기반 |
| BM3D | Training-free | BSD68 | 없음 | ❌ | Patch grouping + 3D filtering | 자동 |
| Non-local Means | Training-free | BSD68 | 없음 | ❌ | 유사 패치 가중 평균 | *h grid search |
| Mean Filter | Training-free | BSD68 | 없음 | ❌ | 국소 평균 | 커널(3/5/7) 선택 |
| Median Filter | Training-free | BSD68 | 없음 | ❌ | 국소 중앙값 | 커널(3/5/7) 선택 |
🔹 Performance over Various Noise Levels Result
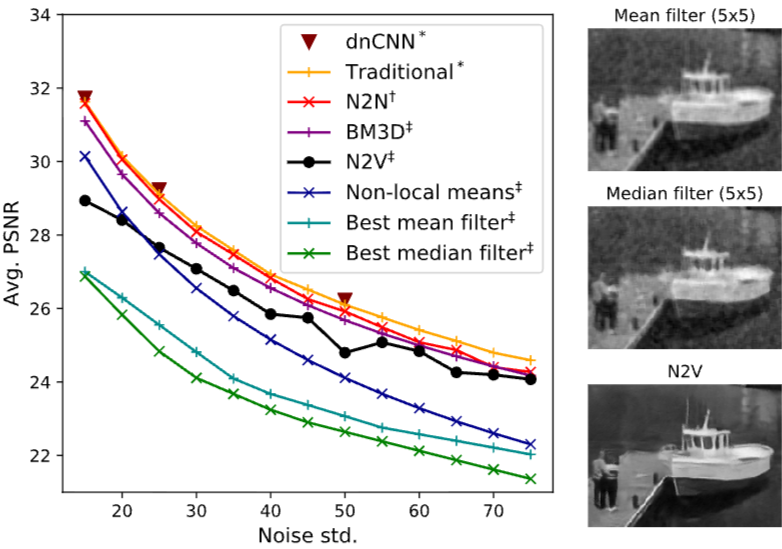
비록 Traditional이나 N2N처럼 더 많은 정보가 주어지는 방법들보다 PSNR이 약간 낮지만, N2V는 실제 응용 분야, 특히 깨끗한 데이터나 노이즈 쌍을 얻기 어려운 생물의학 이미징 데이터에 매우 유용합니다. BM3D와 같은 기존의 강력한 비학습 기반 방법과 비교해도 경쟁력 있는 성능을 보입니다. 즉, 깨끗한 이미지나 노이즈 이미지 쌍이 없는 경우에도 효과적인 노이즈 제거 성능을 제공하는 강력한 자기 지도 학습(self-supervised learning) 방법임을 보여줍니다.
Conclusion
단일 노이즈 획득만으로 노이즈 제거 CNN을 학습하는 데 필요한 새로운 학습 방식인 NOISE2VOID를 소개했습니다. 우리는 N2V의 적용 가능성을 사진, 형광 현미경, 저온 투과 전자 현미경과 같은 다양한 이미지 모달리티에 대해서 입증했습니다. 예측 가능한 신호와 픽셀별 독립적인 노이즈라는 초기 가정이 충족되는 한, N2V로 학습된 네트워크는 전통적인 학습 및 N2N으로 학습된 네트워크와 경쟁할 수 있습니다. 추가적으로, 우리는 이러한 가정이 위반될 때 N2V 학습의 동작 또한 분석했습니다.
우리가 제안하는 NOISE2VOID 학습 방식은 강력한 노이즈 제거 네트워크를 학습할 수 있게 해줄 것이라고 믿습니다. 우리는 처리될 데이터 자체를 사용하여 노이즈 제거 네트워크를 학습할 수 있는 여러 예시를 보여주었습니다. 따라서 N2V 학습은 생의학 이미지 데이터와 같은 수많은 응용 분야의 문을 열 것입니다.
이렇게 논문 리뷰를 마치도록 하겠습니다. 해당 논문은 크게 다음과 같이 핵심 기법으로 볼 수 있을 것 같습니다.
- Signal은 pixel-wise dependent 하다.
- Noise는 Signal이 주어졌을 때, 조건부 독립이다.
- Blind-spot과 Masking scheme
- Loss 계산 시, 주변 픽셀에 대해서는 0을 넘겨준다.
해당 논문에 대한 구현은 github를 참고해주시면 감사하겠습니다!
다음 논문 리뷰로 찾아 뵙겠습니다❗️
