MM-BSN: Self-Supervised Image Denoising for Real-World with Multi-Mask based on Blind-Spot Network
GIST 동계 인턴

안녕하세요!
이번에 리뷰할 논문은 BSN의 연구 중 단순히 중앙 픽셀을 마스킹하는 것이 아닌 다양한 형태의 마스킹을 활용하면 어떨지에 대해서 연구한 MM-BSN: Self-Supervised Image Denoising for Real-World with Multi-Mask
based on Blind-Spot Network 논문입니다.
해당 논문은 리뷰를 진행하면서 확인할 수 있지만 다양한 마스킹 형태를 가져가기 시작하고 이들의 조합을 연구합니다. 직관적으로 당연히 다양한 형태로 feature를 뽑으면 더 좋은 성능이 나올 것이라 예상될 수 있지만 다양한 형태의 feature의 연결을 어떤 식으로 수행할지 궁금해서 본 논문을 고르게 되었습니다.
이제 리뷰를 시작해보도록 하겠습니다❗️
Abstract
최근 딥러닝의 발전은 이미지 노이즈 제거 기술을 한 단계 발전시키고 있습니다. Self-supervised image denoising 분야에서 Blind-spot Network(BSN)는 가장 일반적인 방법 중 하나입니다. 하지만 기존 BSN 알고리즘 대부분은 점 기반 central mask를 사용하는데, 이는 large-scale spatially correlated noise가 있는 이미지에 비효율적인 것으로 알려져 있습니다. 본 논문에서는 대규모 노이즈(large-noise)의 정의를 제시하고, 여러 모양으로 마스킹된 다중 컨볼루션 커널을 사용하는 multy-maske strategy을 제안하여 노이즈의 공간 상관을 더욱 효과적으로 분해합니다. 더 나아가, multi-mask 전략과 BSN을 결합한 새로운 Self-supervised image denoising 방법(MM-BSN)을 제안합니다. 서로 다른 마스크가 상당한 성능 차이를 유발할 수 있음을 보이며, 제안하는 MM-BSN은 다중 마스크 처리된 레이어에서 추출된 특징을 효율적으로 융합하는 동시에, 다중 마스킹 및 정보 전송으로 인해 파괴된 질감 구조를 복구합니다. MM-BSN은 다른 BSN 방법으로는 효율적으로 처리하기 어려운 대규모 노이즈 제거 문제에 적용될 수 있습니다. 공개된 실제 데이터셋에 대한 광범위한 실험을 통해, 제안하는 MM-BSN이 레이블링 노력이나 사전 지식 없이 sRGB 이미지 노이즈 제거에 있어 자기 지도 학습 및 unpaired image denoising 방법 중에서도 최첨단 성능을 달성함을 입증합니다.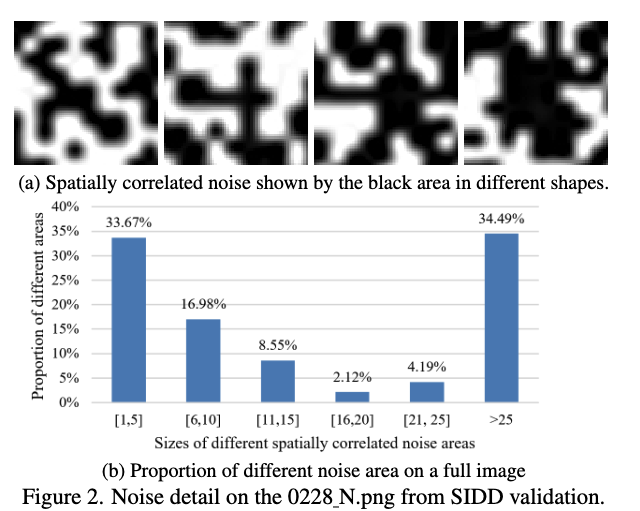
Introduction
Image denoising은 이미지 처리의 핵심 단계이며, Denoising 성능은 후속 이미지 처리 작업에 상당한 영향을 미칩니다. 기존의 Traditional image denoising 방법들은 시간이 오래 걸리고 비용이 많이 들지만, 실제 응용에서는 일반적으로 견고성이 떨어집니다. 딥러닝의 발전과 함께, 학습 기반 Image denoising 알고리즘은 큰 발전을 이루었으며, supervised learning 방법과 self-supervised learning 방법의 두 가지 범주로 나눌 수 있습니다.
supervised learning 방법들은 self-supervised learning 방법보다 상대적으로 더 나은 성능을 보입니다. 그러나 supervised image denoising은 실제 응용에서 수집하기 어려운 다수의 노이즈 이미지-깨끗한 이미지 쌍을 요구하며, 이러한 이미지 쌍을 생성하는 데는 막대한 인간의 노력과 비용이 필요합니다. 가장 일반적인 방법 중 하나는 깨끗한 이미지에 Additive White Gaussian Noise, AWGN와 같은 시뮬레이션된 실제 노이즈를 추가하여 인위적으로 노이즈 이미지를 합성함으로써 (synthetic noisy image, clean image) pair을 얻는 것입니다. 그럼에도 불구하고, 합성 노이즈와 실제 노이즈 사이에는 항상 피할 수 없는 간극이 존재하며, 이는 실제 환경에서의 이미지 노이즈 제거 응용에서 합성 노이즈로 학습된 이러한 지도 학습 모델의 성능에 심각한 영향을 미칩니다. 또한, 일부 경우에는 깨끗한 이미지를 얻는 것조차 어렵습니다.
이러한 상황에서 노이즈-깨끗한 이미지 쌍을 요구하지 않는 많은 Self-supervised image denoising 방법들이 제안되었습니다. Noise2Noise는 (noisy image, noisy image) 쌍을 사용하여 모델을 학습시켰으며, 이는 supervised learning 알고리즘과 비교할 만한 성능을 달성했습니다. 하지만 이는 실제 환경에서 얻기 어려운 완벽하게 정렬된 두 개의 노이즈 이미지를 필요로 합니다. Noisier2Noise와 NAC는 기존 노이즈와 동일한 유형의 노이즈를 원본 노이즈 이미지에 추가하여 더 노이즈가 많은 노이즈 이미지 쌍을 학습 데이터셋으로 형성했습니다. 이는 모델 사용자가 이미지 내 노이즈의 특정 유형을 알아야 한다는 것을 요구하는데, 노이즈의 원인은 다양하고 실제 환경에서는 노이즈 유형이 끊임없이 변할 수 있기 때문에 이는 현실적으로 비현실적입니다. IDR은 반복적인 접근 방식을 채택하여, 노이즈 이미지를 이미 노이즈-노이즈 쌍으로 학습된 기존 노이즈 제거 모델의 입력으로 사용하고, 그 출력을 다음 라운드 최적화 목표로 삼아 노이즈 제거 모델을 더욱 정제합니다. 이러한 방식으로 노이즈 제거 모델은 반복을 통해 최적화되며, 이는 최종적으로 노이즈가 제거된 이미지가 과도하게 평활화되는 결과를 초래하기 쉽습니다. Noise2Void[18]는 이미지 내 픽셀 신호가 공간적으로 상관되어 있고, 노이즈 신호는 평균이 0이고 공간적으로 독립적이라는 가정을 기반으로 하는 블라인드 스팟 네트워크(Blind Spot Network, BSN) 노이즈 제거 방법을 제안했습니다. 최근 몇 년간 여러 후속 연구들에서 BSN이 노이즈 제거를 위한 노이즈 합성에 효과적임이 입증되었습니다. 그러나 실제 환경의 노이즈는 일반적으로 공간적으로 연속적입니다. 대부분의 기존 BSN 노이즈 제거 방법들에서 블라인드 스팟을 생성하는 데 사용되는 마스크는 중앙에 단일 픽셀이 가려져 있어, 노이즈 상관 영역이 클 때 노이즈 제거가 어렵습니다. Zhang 등은 트랜스포머와 CNN을 결합하여 전역적으로 공간 상관된 노이즈를 가진 이미지를 노이즈 제거하는 것과 국부적 디테일을 보존하는 것 사이의 절충점을 달성했습니다. 그러나 트랜스포머는 계산 집약적이어서 모바일 장치와 같은 실제 응용 프로그램에 배포하기 어렵습니다.
컨볼루션 커널의 다양한 모양이 다른 특징을 추출할 수 있다는 사실에 동기 부여를 받아, 우리는 블라인드 스팟을 생성하기 위해 '+' 모양 마스크, ' ' 모양 마스크, '×' 모양 마스크 등 다양한 모양의 마스크를 제안합니다. 서로 다른 블라인드 스팟을 가진 multi-mask는 서로 다른 위치에서 주변 픽셀을 마스킹하는 데 사용되어, 다방향으로 노이즈의 spatial correlation을 파괴합니다. 그리고 우리는 Image denoising을 위해 서로 다른 마스크 또는 서로 다른 마스크 조합을 사용하는 것의 효과를 체계적으로 입증합니다. 또한, 우리는 multi-mask전략과 결합된 향상된 BSN, 즉 MM-BSN을 제안하여 멀티 마스크 경로를 보다 효율적으로 통합하고, 손상된 질감을 복구하며, 모델 크기를 제어합니다. 광범위한 실험은 제안된 방법의 효과와 우수성을 입증합니다.
우리 연구의 주요 기여는 다음과 같습니다:
- 우리가 알기로는, 우리는 서로 다른 convolution kernel과 multi-mask를 결합하여 특징을 추출하고, self-supervised learning에서 large-scale spatially correlated noise에 대한 denoising을 수행한 최초의 연구입니다. 더 나아가, 우리의 multi-mask strategy은 다른 방법들과 통합될 수 있습니다.
- 우리는 Multi-masked convolution kernels에 의해 추출된 특징을 통합하고, 모델 크기를 제어하며, Denoising 시 이미지 디테일을 보존할 수 있는 새로운 Self-sueprvised MM-BSN을 제안합니다.
- 우리의 접근 방식은 발표된 자기 지도 학습 sRGB 이미지 노이즈 제거 방법들 중에서 최첨단 성능을 달성했으며, 이는 실제 응용 분야에 중요합니다.
Related Work
supervised image denoising
Zhang 등에서 깨끗한 이미지에 AWGN을 수동으로 추가하여 노이즈-깨끗한 쌍을 생성하여 모델을 학습시킨 최초의 딥러닝 기반 이미지 노이즈 제거 방법인 DnCNN을 제안했습니다. 이후 많은 연구자들이 깨끗한 sRGB 이미지에 AWGN을 추가함으로써 딥러닝 기반의 Image denoising 방법들을 제안했습니다. 그러나 만들어진 노이즈와 실제 노이즈 간의 큰 간극으로 인해 이러한 모델들의 실제 환경에서의 노이즈 제거 성능은 만족스럽지 못했습니다. 다른 연구 학자들은 먼저 sRGB 이미지를 rawRGB로 변환한 다음, shot-noise에 해당하는 Poison noise와 판독 노이즈에 해당하는 가우시안 노이즈를 rawRGB에 추가할 것을 제안했습니다. rawRGB 공간에서 노이즈 제거를 수행한 후, 최종 노이즈 제거 결과 이미지는 ISP 도구를 사용하여 sRGB 공간으로 다시 변환되었습니다. 이 image denoising 방법의 성공을 위해서는 정확한 노이즈 추정 및 모델링이 필수적이었습니다. 통계적 모델링을 통해 얻은 노이즈가 합성 노이즈와 실제 노이즈 간의 간극을 줄였지만, Synthetic noise는 실제 노이즈가 아니었고 외부 요인이 노이즈 모델링의 정확성에 영향을 미칠 수 있었습니다. 이를 위해, 실제 환경에서 사용 가능한 noisy-clean image 쌍을 직접 사용하는 것이 Image denoising에서 가장 효과적인 방법임이 인식되었습니다. 그러나 이러한 Noisy-clean image 쌍 데이터셋은 실제 환경에서 수집하는 데 막대한 양의 인력과 구축하는 데 막대한 시간이 필요하며, 다양한 응용 시나리오를 고려할 때 더욱 비현실적이었습니다.
Self-supervised image denoising
Noise2Noise는 동일한 장면에서 완벽하게 정렬된 두 개의 노이즈 이미지를 각각 입력과 타겟으로 사용했습니다. 해당 연구에서는 L2 loss를 활용하여 모델이 노이즈 제거 능력을 갖도록 두 노이즈 이미지 간의 차이를 최소화하는 데 사용되었습니다. 이후 Noise2Void, Noise2Self, Probabilistic Noise2Void, Neighbor2Neighbor, IDR, CVF-SID, Blind2Unblind 및 AP-BSN 등이 제안되어 훈련에 Noisy image만을 사용했습니다. 가장 널리 사용되는 self-supervised iamge denoising 방법인 BSN은 Noise2Void에서 처음 제안되었으며, 이는 Receptivw field의 central pixel을 마스킹하고 주변 정보를 사용하여 마스킹된 픽셀의 정보를 재구성하는 특수한 CNN입니다. 이 방법의 노이즈 제거 능력은 노이즈가 공간적으로 독립적이라는 가정에 국한됩니다. Noise2Void는 마스킹된 이미지를 입력으로, 완전히 노이즈가 있는 이미지를 타겟으로 사용하여 모델을 훈련했습니다. 훈련 중에 마스킹된 픽셀은 사용되지 않으므로 세부 정보 손실과 이미지의 over-smoothing 쉽게 발생할 수 있습니다.
이를 정리하자면 N2V는 입력에서 픽셀을 blind하여 동작하지만, input과 output 모두 노이즈 이미지 그대로이기 때문에 모델은 주변 픽셀의 평균값을 예측하게 되고, 이로 인해 고주파와 같은 detail한 정보가 over-smoothing되는 현상을 의미합니다.
Neighbor2Neighbor는 원시 RGB 이미지의 4×4 이웃에서 두 개의 인접한 픽셀을 무작위로 선택하여 두 개의 서브-노이즈 이미지를 합성했습니다. 두 개의 서브-노이즈 이미지는 각각 훈련을 위한 입력과 타겟으로 사용되어 노이즈-노이즈 쌍을 형성했습니다. 그러나 서브-노이즈 이미지에서 직접 훈련하면 필연적으로 일부 이미지 세부 정보가 손실됩니다. 이를 개선하기 위해 Blind2Unblind는 서로 다른 위치에 픽셀을 마스킹한 서브-마스크 이미지를 생성하여 모든 픽셀을 훈련에 사용한 다음, 노이즈 제거 후 서브-마스크 이미지에서 마스킹된 위치의 모든 픽셀을 수집하기 위해 전역 마스크 전략을 사용했습니다. Blind2Unblind는 모든 픽셀 정보를 최대한 활용하지만, dot-based mask로는 large noise를 제거하기 어렵습니다.
High-Quality Self-Supervised Deep Image Denoising라는 해당 연구에서는 네 가지 다른 방향으로 수용 필드의 절반을 가려, 수용 필드 중심이 보이지 않는 효과를 달성했습니다. D-BSN과 David 등은 중심 마스킹 컨볼루션 커널과 특정 스트라이드(step size)를 갖는 확장 컨볼루션 레이어(DCL)를 사용하여 BSN을 구성했습니다. 이 논문들은 BSN이 노이즈 합성을 통한 노이즈 제거에 효과적임을 입증했습니다. 그러나 실제 세계의 노이즈는 일반적으로 공간적으로 연속적이어서 BSN은 이를 처리하는 데 실패할 수 있습니다.
이는 BSN의 기본적인 가정으로 인해 생기는 구조적 한계에 대해서 이야기하고 있습니다. BSN의 가정으로는 신호는 서로 연속적이고 노이즈의 경우 pixel-wise 독립이며 평균은 0이라는 이상적인 가정을 수행하게 됩니다. 이로 인해서 BSN은 실제 노이즈에 대해서 일반화하는데 어려움을 겪는 문제점이 존재합니다.
실제 세계 노이즈의 공간적 상관관계를 끊기 위해 AP-BSN은 훈련 중에는 큰 스트라이드(s = 5)를 활용하며 추론 중에는 작은 스트라이드(s = 2)를 활용한 Pixel-shuffle downsampling을 수행하고 central pixel masking convolution kernel과 dilated convolution layer(DCL)를 활용하여 훈련 중 blind-spot 효과를 달성했습니다. 그러나 AP-BSN은 노이즈의 공간적 상관관계를 끊기 위해 제한된 스트라이드를 갖는 PD에 의존합니다. 이미지에 큰 노이즈가 존재하는 경우, PD 스트라이드를 무분별하게 증가시키면 이미지 세부 정보에 복구 불가능한 손상을 초래할 수 있습니다. 따라서 AP-BSN은 특히 큰 노이즈를 제거할 때 노이즈 제거와 텍스처 정보 보존 사이의 균형을 맞추기 어렵습니다. 본 논문에서는 large noise correltaion을 파괴하기 위해 multi mask convolution kernel을 사용하는 특징 추출 방법을 제안합니다. 또한, 추출된 특징을 최대한 활용하고 원본 이미지의 텍스처 구조를 최대한 보존하기 위해 multi mask convolution kernel과 BSN(MM-BSN)을 결합한 새로운 아키텍처를 제안합니다.
위에서 언급한 연구들의 Contiribution과 flow는 다음과 같습니다.
Supervised Image Denoising
| 연구 | 핵심 문제 인식 | 해결 접근 | 한계점 |
|---|---|---|---|
| DnCNN (Zhang et al.) | 실제 노이즈 데이터 부족 | 깨끗한 이미지에 AWGN을 합성하여 noisy-clean 쌍 생성 | 합성 노이즈 ≠ 실제 노이즈 → 실환경 성능 저하 |
| AWGN 기반 후속 연구들 | 동일 | sRGB 이미지에 AWGN 추가 | 실제 노이즈의 복잡성(비정규성, 상관성) 미반영 |
| RawRGB noise modeling 계열 | sRGB 공간 노이즈 모델의 한계 | RawRGB로 변환 후 Poisson + Gaussian noise 모델링, ISP로 복원 | 정확한 노이즈 추정이 필수, 외부 요인에 민감 |
| Real noisy-clean datasets (SIDD 등) | 합성 노이즈의 근본적 한계 | 실제 noisy-clean 쌍 직접 수집 | 데이터 수집에 막대한 비용·시간, 확장성 부족 |
Self-supervised Image Denoising
| 연구 | 기존 문제 | 제안한 해결책 | 구조적 한계 |
|---|---|---|---|
| Noise2Noise | GT 이미지 필요 | 동일 장면의 노이즈 이미지 2장을 input/target으로 사용 | 완벽한 정렬된 노이즈 쌍 필요 → 현실적으로 어려움 |
| Noise2Void / Noise2Self | GT 부재 | 중앙 픽셀 마스킹, 주변 정보로 예측 | pixel-wise independent noise 가정, 평균 예측 → over-smoothing |
| Probabilistic N2V | N2V의 결정론적 한계 | 픽셀 분포 확률 모델링 | 여전히 공간적 상관 노이즈 취약 |
| Neighbor2Neighbor | 단일 이미지 self-supervision 한계 | 이웃 픽셀로 sub-noise pair 합성 | 서브 이미지 자체가 정보 손실 |
| Blind2Unblind | N2N의 픽셀 활용 부족 | 서로 다른 마스크 + 전역 마스크 수집 | dot-based mask → large noise 제거 한계 |
| High-Quality Self-Supervised Denoising | BSN의 정보 누락 | half-plane receptive field | 실제 노이즈의 공간적 연속성 미처리 |
| D-BSN / David et al. | Blind-spot 구현 한계 | 중앙 마스킹 커널 + DCL | 실제 노이즈는 공간적으로 correlated |
Real-World Noise 대응 계열
| 연구 | 핵심 문제 | 해결 전략 | 남은 문제 |
|---|---|---|---|
| AP-BSN | 실제 노이즈의 공간적 상관성 | Pixel-shuffle Downsampling (PD) + large stride 학습 | PD stride 증가 시 텍스처 손상, large noise에서 trade-off 발생 |
| (본 논문) MM-BSN | AP-BSN의 PD 의존성 | Multi-mask convolution kernel로 상관 노이즈 직접 분해 | (논문 기여) 노이즈 제거와 텍스처 보존의 균형 개선 |
Motivation
위 그림에서 표시된 다양한 모양의 노이즈 공간 상관관계를 확인하고자 합니다. 그림 2a의 서브 이미지들은 모두 높이×너비가 10×10 크기이며, 이는 상관 영역이 크다는 것을 보여줍니다. 또한 그림 2b에서 이미지의 다른 영역에서 공간적으로 상관된 노이즈의 비율을 계산합니다. 25보다 큰 영역을 갖는 공간적으로 상관된 노이즈를 큰 노이즈로 정의합니다. 그림 2b는 이론적으로 5보다 크지 않은 PD 스트라이드로 처리할 수 없는 큰 노이즈가 1/3 이상을 차지함을 보여줍니다.
최근 발표된 BSN 방법들은 입력 마스크 또는 네트워크 마스크 중 점 기반 마스크를 사용한 것은 큰 노이즈의 상관관계를 끊기에 충분하지 않습니다. 이러한 방식으로 주변 정보로부터 복구된 블라인드 픽셀은 여전히 노이즈를 포함하게 됩니다. 다양한 모양의 필터가 '+', 'ㅁ' 등과 같이 다양한 유형의 노이즈를 대상으로 설계될 수 있다는 사전 지식에 동기를 부여받아, 우리는 다양한 모양으로 마스킹된 서로 다른 컨볼루션 커널을 활용하여 노이즈의 공간적 연결을 더욱 파괴하는 새로운 multi-mask 전략을 제안합니다.
기존 self-supervised denoising 방법들은 pixel-wise independent noise 가정에 기반한 blind-spot 구조로 인해 실제 환경의 공간적으로 상관된 노이즈를 효과적으로 처리하지 못하였습니다. AP-BSN은 pixel-shuffle downsampling을 통해 이를 완화하고자 했으나, stride 의존성으로 인해 large noise 환경에서 텍스처 손실 문제가 발생했습니다. 따라서 본 논문은 이러한 한계를 극복하기 위해 multi-mask convolution kernel을 도입한 MM-BSN 구조를 제안한다.
Main Method
Multi-mask strategy
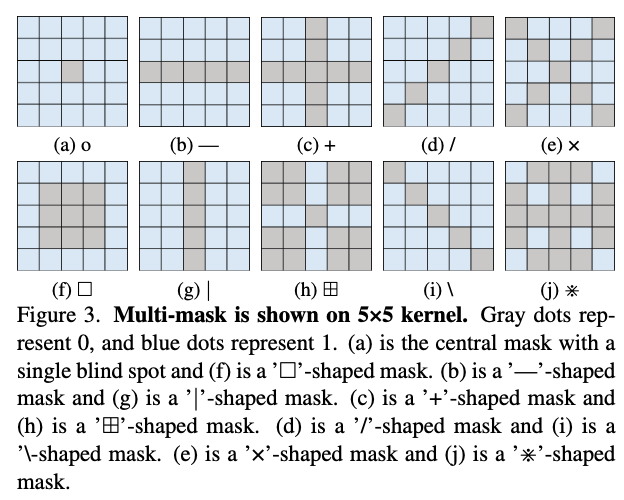
우리는 잡음의 공간적 연결성을 더욱 파괴하면서 이미지의 유용한 텍스처 정보를 보존하기 위해 Multi-mask 전략을 사용할 것을 제안합니다. 그림 3은 컨볼루션 커널 크기가 5×5일 때 '+', ' ', '—', '|', '/', '', '×' 등과 같은 다양한 마스크의 모양을 보여줍니다.
이론적으로 우리는 서로 다른 모양의 여러 마스크를 임의로 조합하여 다양한 디노이징 결과를 얻을 수 있습니다. n개의 종류의 마스크드 컨볼루션 커널 타입을 사용할 때, 각 경로는 최종 concatenation까지 동일한 연산을 수행하며, 여기서 여러 다른 마스크드 컨볼루션 커널에 의해 추출된 모든 특징들이 융합됩니다.
이러한 방식으로, 우리는 여러 마스크에 해당하는 아키텍처를 포함하는 다수의 기본 멀티마스크 BSN 모델을 얻을 수 있습니다. 그러나 이 단순한 스태킹(stacking)이라는 순진한 방법으로 얻어진 모델 크기는 기본 네트워크 크기의 거의 n배입니다. 결과적으로, 하드웨어 장치에 대한 작업량은 n배로 증가합니다. 모델 크기를 제어하고, 블라인드 스팟 주변의 정보를 최대한 활용하며, 정보 중복을 피하기 위해, 우리는 일반적으로 단 두 개의 마스크 조합만을 사용합니다.(뒤에서 사진을 보시겠지만 자세히 말씀드리면 서로 다른 두 커널 사이즈를 가진 mask kernel이 존재하고 각 사이즈의 서로 다른 두 가지의 multi-mask kernel이 존재합니다.) 'o' 모양 마스크에 의해 추출된 특징은 완전한 정보를 포함합니다. 그러나 잡음의 공간적 연결성을 충분히 끊지 못하기 때문에 디노이징에 덜 유익한 정보를 포함할 수 있습니다. 다른 종류의 마스크는 주변 픽셀의 더 많은 픽셀을 마스킹하여 잡음의 공간적 연결성을 더 잘 끊을 수 있지만, 더 많은 이미지 정보를 손실합니다.
따라서 우리는 더 많은 디테일을 제공하기 위해 'o'에 의해 추출된 특징과 잡음의 공간적 상관관계를 끊고 서로 강화하여 더 나은 디노이징 성능을 얻기 위한 다른 모양의 마스크를 결합할 수 있습니다. 물론, 상호 보완적인 마스크 모양을 가진 두 개의 마스크는 잡음의 공간적 연결성을 끊으면서 주변 픽셀로부터 정보를 추출할 수도 있습니다. Multi-mask 조합은 실제 잡음 분포에 따라 유연하게 조정될 수 있습니다.
우리의 멀티마스크 전략은 단순히 다른 마스크 경로를 스태킹함으로써 다른 방법들과 통합될 수 있습니다. 그러나 이 방식으로는, 다른 마스크 타입의 증가하는 수가 모델 크기를 폭발적으로 증가시킬 것입니다. 또한, 최종 concatenate 전에 중간 단계에서 다른 마스크에 의해 추출된 특징들은 처리 경로 간에 상호작용이 없습니다. 이러한 상호작용 없이는, 이러한 처리 경로 간의 정보 전달 및 공동 최적화가 불가능합니다. 따라서, 멀티마스크를 사용하여 잡음의 공간적 연결성을 파괴하면서 더 많은 텍스처 정보를 유지하는 방법 또한 과제입니다. 마지막으로, 마스크 영역이 증가함에 따라 이미지 자체의 텍스처 정보가 점점 더 파괴됩니다. 이러한 과제들을 해결하기 위해 우리는 새로운 MM-BSN을 제안합니다.
MM-BSN Architecture

MM-BSN은 AP-BSN [22]에서 동기를 부여받았습니다. 우리는 또한 masked convolution kernel을 사용하여 얕은 특징을 추출합니다. 하지만 중앙 마스크만 사용하는 대신, 마스크된 특징을 추출하기 위해 다른 모양의 마스크를 추가합니다.
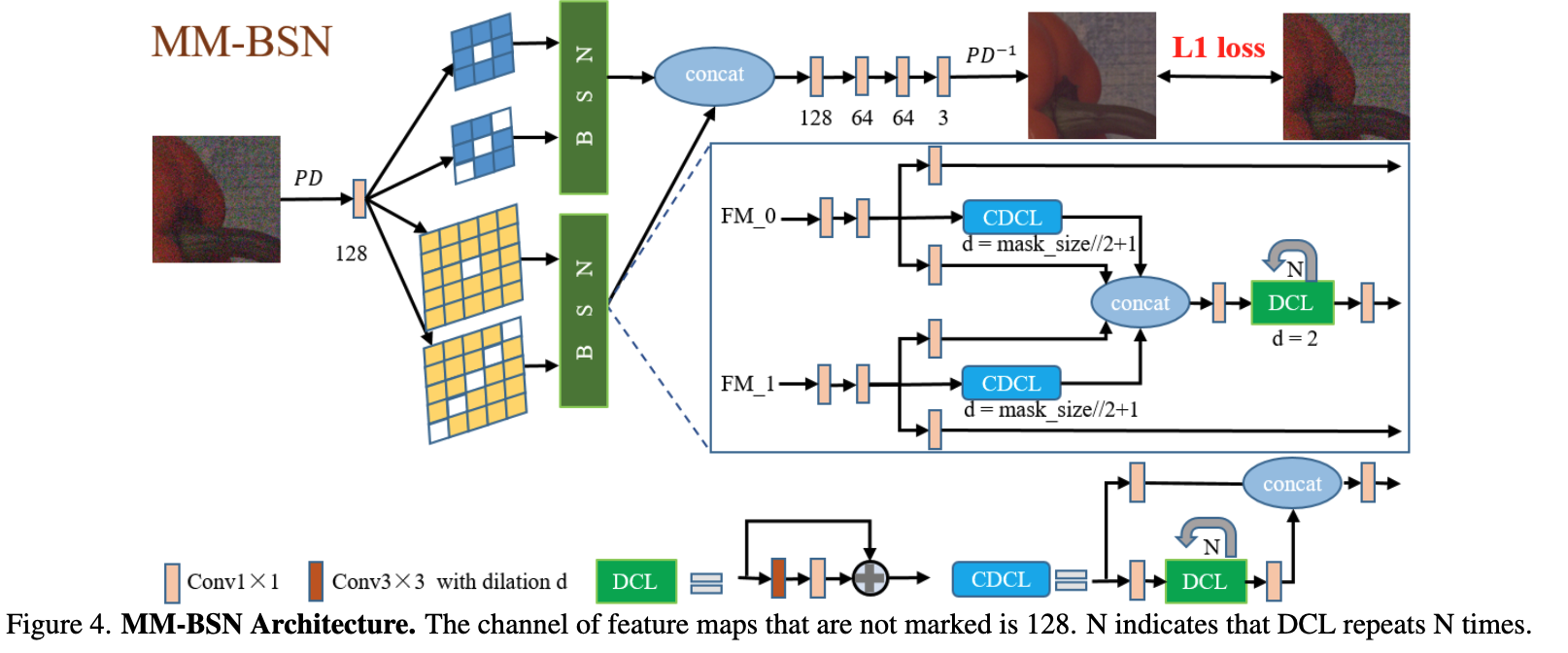
MM-BSN의 아키텍처는 그림 4에 나와 있습니다. 워크플로우는 네 단계로 구성됩니다.
첫째, 1×1 컨볼루션 레이어를 사용하여 잡음 이미지에 선형 변환을 수행하고, 완전한 이미지 정보를 포함하는 출력 특징은 여러 개의 다른 마스크드 컨볼루션 레이어를 병렬로 통과합니다.
둘째, 각 마스크된 특징은 세 개의 레이어를 병렬로 통과하는데[그림에서 파란색으로 표시된 네모난 블록을 의미, BSN 부분], 두 개의 1×1 컨볼루션 레이어와 Concatenation-based Dilated Convolutional Layer (CDCL)입니다. CDCL은 적은 수의 DCL(본 논문에서는 2로 설정)을 포함하며, 그 출력 특징은 마스크 크기에 따라 연결을 사용하여 1×1 컨볼루션 레이어의 선형 변환된 특징 하나와 concatenation 됩니다. 즉, 동일한 크기이지만 다른 마스크드 컨볼루션 커널에 의해 추출된 특징들이 융합됩니다.
셋째, 여러 DCL(본 논문에서는 7로 설정)을 통과한 후[그림에서 파란색으로 표시된 네모난 블록안에 DCL 부분을 의미, BSN 부분], 모든 특징이 함께 연결되며, 다른 크기의 다른 마스크드 컨볼루션 커널에 의해 추출된 특징들이 융합됩니다[BSN 이후의 여러 크기의 커널로 추출한 features를 concat하는 부분을 의미].
마지막으로, 출력은 채널 변환 및 여러 1×1 컨볼루션 레이어를 사용한 특징 융합을 통해 얻어집니다.
서로 다른 특징 경로 간의 상호작용으로 인해, 결과적인 MM-BSN 파라미터 세트(5.3M)는 AP-BSN(3.7M)보다 크지만, 멀티마스크를 가진 AP-BSN의 단순 스태킹(즉, SMM-BSN)의 모델 크기(7.3M)보다는 훨씬 작습니다. 여러 모델에 대한 추가 실험은 섹션 5.3에 자세히 설명되어 있습니다.
Loss function
본 논문에서는 MM-BSN을 훈련하기 위해 L1 loss를 사용합니다.
여기서, M은 MM-BSN의 모델을 의미하고, 은 의 결과이며, 은 Noisy image를 의미합니다. AP-BSN과 유사하게, MM-BSN은 PD를 사용하여 인접한 픽셀 간의 Spatial correltaion noise의 연결성을 미리 끊습니다. 스트라이드 를 가진 후, 우리는 MM-BSN의 입력이 되는 하위 이미지 그룹을 얻습니다. 원본 이미지와 동일한 크기를 갖는 Denoising 결과 모델의 출력에 연산을 수행하여 Decoding 됩니다.
Experiments
Implementaion Details
Dataset
| 구분 | 데이터셋 | 사용 목적 | 구성 / 특징 |
|---|---|---|---|
| 학습 (Supervised) | SIDD Medium (sRGB) | 학습 세트 | 320쌍의 (노이즈, 깨끗한) 이미지 |
| 검증 | SIDD Validation | 검증 세트 | 노이즈-깨끗한 이미지 쌍 |
| 테스트 | SIDD Validation / SIDD Benchmark | 테스트 세트 | 정량 평가용 |
| 테스트 | DND | 테스트 세트 | 50장 노이즈 이미지만 존재 |
| 학습 + 테스트 (Self-supervised) | DND | 학습 & 테스트 | 노이즈 이미지만 필요 → GT 불필요 |
Training Details
| 항목 | 설정 값 |
|---|---|
| 배치 크기 (Batch size) | 8 |
| 학습 에포크 수 | 30 |
| 옵티마이저 | Adam |
| 초기 학습률 | 0.0001 |
| 학습률 스케줄 | 8 에포크마다 ×0.1 감소 |
| 입력 이미지 크기 | 128 × 128 |
| 데이터 증강 | 학습 전 수평/수직 방향으로 최대 90° 무작위 회전 |
| Python 버전 | 3.8.0 |
| PyTorch 버전 | 1.12.0 |
| GPU | Nvidia Tesla T4 |
Fair Comparison Settings
| 항목 | 설정 |
|---|---|
| PD stride (학습) | 5 |
| PD stride (테스트) | 2 |
| 후처리 방식 | AP-BSN과 동일한 post-processing 적용 |
| 하이퍼파라미터 | 모든 모델 동일하게 사용 |
Analyzing Multi-Mask strategy in BSN
제안된 방법과 다른 마스크 조합의 성능을 비교하기 위해, SIDD Medium 데이터셋에서 다양한 마스크를 사용하여 여러 MMBSN 모델을 학습시켰습니다.
학습된 모든 모델은 SIDD validation 및 benchmark에서 정량적으로 평가되었습니다. 기존 Python 툴킷을 사용하여 SIDD validation의 PSNR/SSIM을 계산했습니다. 동시에 SIDD benchmark의 잡음 제거 결과를 공식 웹사이트에 업로드하여 보고된 PSNR/SSIM을 얻었습니다.
Significant effect on breaking the noise structure


Large-noise의 structure를 끊어내는 마스크의 효과를 확인하기 위해, 로 PD를 진행한 다음의 이미지를 입력으로 사용하여 학습했습니다. 그림 5는 서로 다른 stride와 mask를 사용하여 모델의 Denoising 성능을 보여줍니다. Table 1을 보면, 일 때, cental mask,'ㅇ'-> 'ㅁ' mask로 교체하면 SIDD validation, benchmark에서 PSNR, SSIM 성능 지표가 크게 향상됨을 볼 수 있습니다.
Quantitative comparison of MM-BSN models
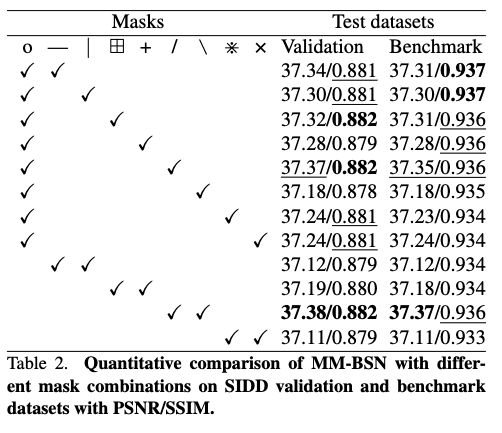
Table 2의 정량적 비교 결과를 통해 MM-BSN에서 사용된 마스크 조합이 노이즈 제거 성능에 미치는 영향을 분석할 수 있습니다. 첫째, 서로 다른 마스크 조합은 서로 다른 노이즈 제거 성능을 보입니다. 이는 각 마스크가 목표로 하는 노이즈의 공간적 상관 구조가 서로 다르기 때문이며, 마스크 형태에 따라 제거되는 노이즈 성분이 달라지므로 최종 복원 이미지의 품질 또한 상이하게 나타납니다. 이러한 결과는 공간적으로 상관된 실제 노이즈의 특성을 고려할 때 자연스러운 현상입니다.
둘째, ‘o’ 형태의 마스크가 포함된 조합은 ‘o’가 포함되지 않은 조합에 비해 전반적으로 더 우수한 성능을 보입니다. 이는 ‘o’ 모양 마스크가 다양한 방향의 주변 정보를 균형 있게 활용함으로써 노이즈 제거 과정에서 이미지 자체의 질감 및 구조적 정보를 보다 완전하게 보존하기 때문입니다. 다시 말해, ‘o’ 마스크는 노이즈 억제뿐만 아니라 텍스처 보존 측면에서도 긍정적인 역할을 수행합니다.
셋째, ‘/’와 ‘\’ 형태의 마스크 조합이 가장 우수한 성능을 보이며, 그 다음으로 ‘o’와 ‘/’ 조합이 높은 성능을 기록합니다. 이는 실험에 사용된 데이터셋에 ‘/’ 및 ‘\’ 방향성을 갖는 공간적으로 상관된 노이즈 패턴이 상대적으로 많이 존재함을 의미합니다. 이러한 결과는 실제 세계 노이즈가 특정 방향성을 갖는 구조적 특성을 포함할 수 있음을 시사합니다.
마지막으로, 데이터셋마다 노이즈의 공간적 구조와 상관 특성이 서로 다르므로, MM-BSN은 고정된 마스크 조합에 의존하지 않고 사용자가 데이터 특성에 따라 마스크 조합을 선택하거나 실제 데이터셋에 적합한 새로운 마스크 형태를 설계할 수 있는 유연성을 제공합니다. 이는 다양한 실제 환경에서 MM-BSN을 효과적으로 적용할 수 있는 중요한 장점입니다.
Comparison of BSN models with increasing mask types.
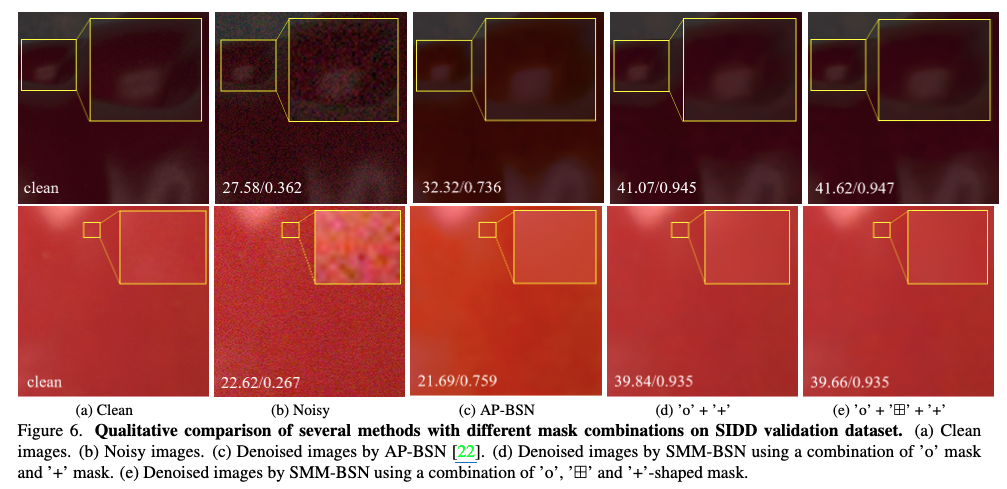
해당 figure.6 을 통해서 알수 있는 점은 크게 3가지가 있습니다.
-
단일 마스크 BSN의 한계: AP-BSN과 같이 중앙 마스크만을 사용하는 기존 BSN 방법은 spatially correlated large noise를 효과적으로 제거하지 못하며, 때로는 이미지 품질을 저하시킬 수도 있습니다.
-
멀티-마스크 전략의 효과: 'o' 마스크와 함께 다른 형태의 마스크(예: '+')를 조합하는 멀티-마스크 전략은 노이즈의 공간적 상관관계를 훨씬 더 효과적으로 파괴하여 노이즈 제거 성능을 크게 향상시킵니다. 이는 특히 large noise가 존재하는 경우에 두드러집니다.
-
마스크 조합의 중요성: 멀티-마스크 전략은 효과적이지만, 무조건 마스크의 개수를 늘린다고 해서 성능이 계속 향상되는 것은 아닙니다. 데이터셋의 노이즈 특성에 따라 적절한 마스크 조합을 선택하는 것이 중요하며, 정보의 중복이나 디테일 손실을 방지하기 위한 효율적인 통합 아키텍처(MM-BSN)의 필요성을 보여줍니다.
Analyzing our network architecture
공정한 비교를 위해 모든 모델은 SIDD Medium 데이터셋에서 학습되고 SIDD 검증 데이터셋으로 평가됩니다. AP-BSN은 중심 마스크만 사용하고, SMM-BSN과 MM-BSN은 훈련 시 '/' 모양 마스크와 '\' 모양 마스크의 조합을 사용하며, 다른 설정은 이전과 동일합니다.

표 3은 AP-BSN과 그에 해당하는 확장 버전인 SMM-BSN을 비교하며, 이는 멀티 마스크 전략을 적용함으로써 노이즈 제거 성능이 크게 향상됨을 나타냅니다. SIDD Validation 데이터셋의 PSNR/SSIM은 MM-BSN(37.38/0.882)이 AP-BSN(35.91/0.870)보다 훨씬 뛰어난 성능을 보임을 나타냅니다.

그림 7b는 AP-BSN을 사용할 경우 이미지의 노란색 상자 안의 알파벳이 흐릿하고 많은 세부 정보가 손실됨을 보여줍니다. 그림 7c는 노란색 상자 안의 알파벳이 전반적으로 보존됨을 보여줍니다. 이 관찰은 MM-BSN의 얕은 특징으로부터 Concatenation based skip connection을 추가함으로써 손실된 세부 정보가 시간에 따라 보충될 수 있음을 시사합니다.
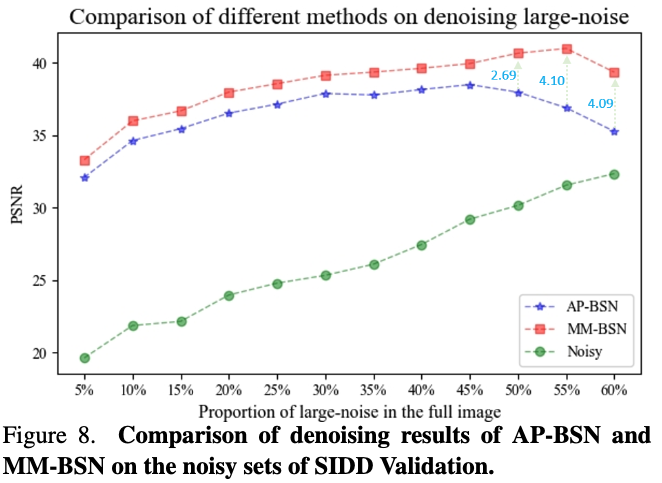
SIDD 검증을 위해 다양한 큰 노이즈 비율을 가진 이미지를 분류하고 각 이미지 세트에서 APBSN과 MM-BSN의 평균 PSNR을 계산했으며, 이는 그림 8에 나타나 있습니다. Multi-mask 전략을 사용하는 저희의 MM-BSN은 'o' 마스크만 사용하는 AP-BSN보다 훨씬 뛰어난 성능을 보이며, 특히 큰 노이즈 환경에서 큰 성능 향상을 보여줍니다.
MM-BSN in real-world sRGB image denosing
제안하는 MM-BSN은 multi-mask를 self-supervised 방식으로 결합하여 sRGB 이미지의 큰 노이즈를 제거하는 것을 목표로 하며, 동시에 질감 디테일을 보존하고 모델 크기를 제어합니다.
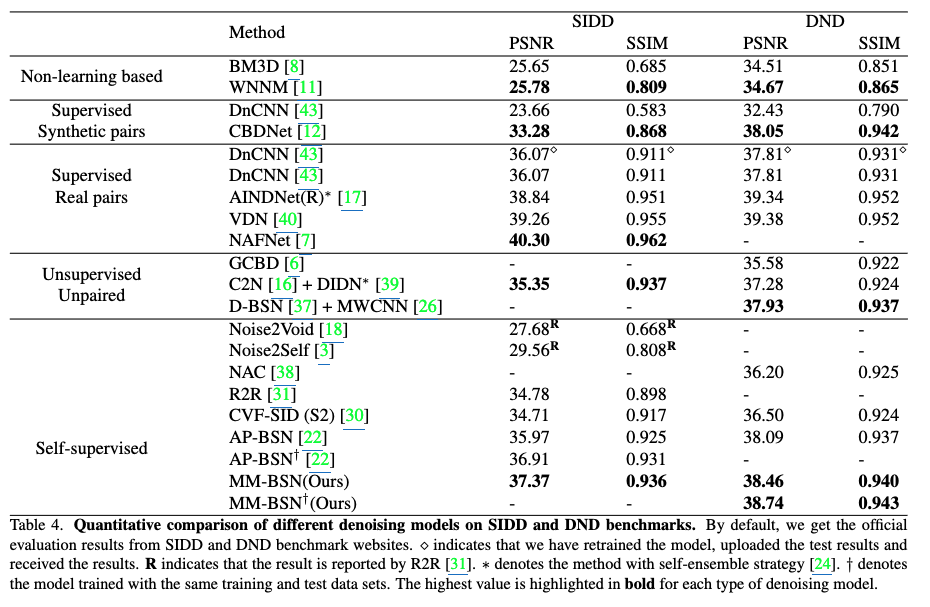
표 4는 SSID 및 DND 벤치마크에서 여러 전통적인 알고리즘, 지도 학습 노이즈 제거 알고리즘, 비지도 및 자기 지도 학습 알고리즘의 노이즈 제거 성능을 정량적으로 비교합니다.
표 4는 **MM-BSN이 자기 지도 학습 방법 중에서 가장 좋은 성능을 보이며, 일부 지도 학습 알고리즘보다도 뛰어남을 보여줍니다.
더욱이, 저희의 MM-BSN은 R2R과 같은 원시 RGB 이미지 및 노이즈 추정이 필요 없으며, 지도 학습 모델과 같은 실제 노이즈-깨끗한 쌍도 필요하지 않습니다.
따라서 실제 응용 프로그램에서 연구자들은 대상 장면의 노이즈가 있는 이미지에서 직접 MM-BSN을 훈련하여 노이즈를 제거할 수 있으며, 시나리오가 변경될 때 모델 성능 저하를 피할 수 있습니다.**
그림 9는 SIDD 및 DND 벤치마크의 무작위 이미지에 대한 최신 모델들의 시각적 노이즈 제거 성능을 정성적으로 비교합니다.
상단 이미지의 노란색 상자와 비교했을 때, 그림 9d 및 그림 9e의 자기 지도 학습 모델로 노이즈 제거된 선 영역은 더 부드럽지만, 그림 9a, 그림 9b 및 그림 9c에 표시된 다른 모델로 노이즈 제거된 선 근처에는 원치 않는 명확한 번짐 효과가 있습니다. MM-BSN은 대부분의 모델보다 더 나은 성능을 보이며, 약간 낮은 PSNR/SSIM으로 지도 학습 방법인 CBDNet과도 경쟁할 수 있습니다. 하단 이미지의 노란색 상자를 비교했을 때, 저희의 MM-BSN은 알파벳의 외부 경계에 더 명확한 윤곽선을 가지며, 알파벳 자체의 노이즈가 더 명확하게 감소했습니다.
Conclusion
본 논문에서는 self-supervised sRGB image denoising를 위해 BSN에 적용되는 multi-mask strategy를 제안합니다. Multi-mask는 이전에 단일 중심 마스크 모델로는 효율적으로 처리할 수 없었던 큰 노이즈 구조를 크게 파괴할 수 있습니다. 또한, Multi-mask Convolution layer에서 추출된 특징을 효과적으로 결합하고 모델 크기가 폭발적으로 증가하지 않도록 제어하는 MM-BSN을 개발했습니다. 특히, Concatenation-based skip-connection의 활용은 마스크로 인한 정보 손실을 보상하는 데 도움이 될 수 있습니다. 광범위한 실험은 저희 방법이 큰 스케일의 공간적으로 상관된 노이즈가 있는 이미지를 효과적으로 제거할 수 있음을 증명합니다.
MM-BSN Contribution 정리
1. 문제 정의: 기존 Self-supervised BSN의 구조적 한계
본 논문이 출발하는 핵심 문제는 기존 self-supervised image denoising 방법, 특히 Blind-Spot Network(BSN) 계열이 실제 환경의 노이즈 특성을 충분히 반영하지 못한다는 점입니다.
기존 BSN 기반 방법들은 공통적으로 다음과 같은 이상적인 가정을 전제로 합니다.
첫째, 이미지의 신호(signal)는 공간적으로 연속적이며,
둘째, 노이즈는 pixel-wise로 독립적이고 평균이 0이라는 가정입니다.
그러나 실제 세계의 노이즈는 이러한 가정을 만족하지 않습니다. 실제 sRGB 이미지에서 노이즈는 종종 공간적으로 연속적이며 방향성을 갖는 large-scale spatially correlated noise 형태로 나타납니다. 이러한 노이즈 환경에서는 중심 픽셀 하나만을 마스킹하는 기존 BSN 구조가 주변 픽셀로부터 노이즈 성분을 충분히 분리하지 못하게 됩니다. 결과적으로 복원된 픽셀에는 여전히 노이즈가 남거나, 이를 제거하기 위해 평균화가 과도하게 작용하여 이미지 디테일이 손실되는 문제가 발생합니다.
즉, 본 논문은 “BSN의 성능 한계는 네트워크 깊이나 학습 전략이 아니라, 블라인드 스팟을 생성하는 마스크 구조 자체에 있다”는 문제의식에서 출발합니다.
2. 기존 해결 시도의 한계: AP-BSN까지의 흐름
이러한 문제를 해결하기 위해 AP-BSN은 Pixel-shuffle Downsampling(PD)을 도입하여 공간적 상관관계를 인위적으로 끊는 방식을 제안하였습니다. 학습 시에는 큰 stride를 사용하고, 추론 시에는 작은 stride를 사용하는 방식으로 노이즈 상관 영역을 축소하려는 접근입니다.
그러나 AP-BSN은 본질적으로 PD stride에 강하게 의존합니다. 노이즈의 상관 영역이 큰 경우 stride를 증가시키면 노이즈 제거 효과는 커지지만, 동시에 이미지의 텍스처 구조가 비가역적으로 손상됩니다. 반대로 stride를 줄이면 텍스처는 보존되지만 노이즈 제거 성능이 급격히 저하됩니다. 이로 인해 AP-BSN은 특히 large noise 환경에서 노이즈 제거와 텍스처 보존 사이의 trade-off를 안정적으로 제어하기 어렵다는 한계를 갖습니다.
즉, 기존 방법들은 “노이즈 상관을 끊기 위해 이미지 자체를 변형한다”는 간접적인 해결책에 머물러 있었습니다.
3. MM-BSN의 핵심 아이디어: Multi-mask 기반 노이즈 상관 분해
본 논문의 가장 중요한 기여는 노이즈의 공간적 상관관계를 데이터 변환(PD)이 아니라, 특징 추출 단계에서 직접 분해하려는 접근입니다.
이를 위해 논문은 다음과 같은 핵심 아이디어를 제안합니다.
- 첫째, 단일 중심 픽셀 마스크는 large-scale spatially correlated noise를 끊기에 구조적으로 불충분하다는 점을 명확히 정의합니다.
- 둘째, 노이즈는 특정 방향성이나 구조를 갖는 경우가 많으며, 이는 서로 다른 형태의 마스크를 통해 선택적으로 분해될 수 있다는 점에 주목합니다.
- 셋째, 이에 따라 ‘+’, ‘o’, ‘/’, ‘\’, ‘×’ 등 서로 다른 공간적 가시성을 갖는 multi-mask convolution kernel을 도입합니다.
이러한 마스크들은 각기 다른 방향과 범위에서 주변 픽셀을 가리므로, 각 마스크는 서로 다른 노이즈 상관 성분을 타겟으로 하는 특징을 추출하게 됩니다. 결과적으로 하나의 blind-spot이 아닌, 여러 개의 상호 보완적인 blind-spot 집합이 형성됩니다.
즉, MM-BSN의 핵심 발상은
“노이즈 상관을 PD로 끊지 말고, 마스크의 기하학적 구조로 분해하자”
라는 점에 있습니다.
4. MM-BSN 아키텍처의 본질적 기여
단순히 여러 마스크를 병렬로 쌓는 것만으로는 문제를 해결할 수 없습니다. 이 경우 모델 크기가 마스크 수에 비례하여 폭발하고, 서로 다른 마스크 경로 간의 정보 교환이 전혀 이루어지지 않습니다.
이를 해결하기 위해 MM-BSN은 다음과 같은 구조적 설계를 제안합니다.
첫째, 서로 다른 마스크로 추출된 특징을 Concatenation-based Dilated Convolution Layer(CDCL)를 통해 중간 단계부터 통합합니다. 이를 통해 각 마스크 경로가 독립적으로 학습되는 것이 아니라, 공동 최적화되는 특징 공간을 형성합니다.
둘째, shallow feature 단계에서부터 skip-connection을 도입하여, 마스킹으로 인해 손실된 텍스처 정보를 점진적으로 보완합니다. 이는 multi-mask로 인해 발생할 수 있는 정보 손실 문제를 구조적으로 완화합니다.
셋째, 단순한 multi-mask stacking(SMM-BSN) 대비 훨씬 작은 파라미터 수로 유사하거나 더 나은 성능을 달성함으로써, 실제 배포 가능성을 고려한 설계를 유지합니다.
결과적으로 MM-BSN은 노이즈 상관 분해 능력, 텍스처 보존 능력, 모델 크기 제어
라는 세 가지 요구 조건을 동시에 만족시키는 구조를 제안합니다.
5. MM-BSN의 실질적 Contribution 요약
본 논문의 핵심 기여는 다음과 같이 정리할 수 있습니다.
- 첫째, self-supervised image denoising에서 large-scale spatially correlated noise를 명확히 정의하고 이를 구조적으로 다루는 문제 설정을 제시한 점입니다.
- 둘째, 단일 blind-spot 가정에서 벗어나, multi-mask를 통해 노이즈 상관 구조를 분해하는 새로운 feature extraction 패러다임을 제안한 점입니다.
- 셋째, multi-mask 전략을 실용적으로 통합할 수 있는 MM-BSN 아키텍처를 설계하고, 실제 sRGB 데이터셋에서 SOTA 수준의 성능을 달성한 점입니다.
6. MM-BSN의 한계점 및 향후 연구 방향
MM-BSN은 분명 기존 BSN 계열의 중요한 한계를 해결하지만, 여전히 몇 가지 한계가 존재합니다.
첫째, 마스크 조합 선택이 데이터셋 의존적입니다. 논문에서도 실험적으로 보여주듯, 최적의 마스크 조합은 데이터셋의 노이즈 방향성과 분포에 따라 달라집니다. 이는 새로운 데이터셋에 적용할 경우, 추가적인 실험이나 휴리스틱한 선택이 필요함을 의미합니다.
둘째, multi-mask 설계 자체는 여전히 사전 정의된 기하학적 형태에 의존합니다. 즉, 마스크가 데이터로부터 자동으로 학습되지는 않으며, 이론적으로는 더 적합한 마스크 구조가 존재할 수 있습니다.
셋째, BSN 계열의 근본적인 가정인 noise의 zero-mean 특성과 signal–noise 분리 가능성은 여전히 유지됩니다. 극단적으로 복잡한 non-stationary noise 환경에서는 MM-BSN 역시 한계를 가질 수 있습니다.
7. 한 문장으로 정리한 MM-BSN의 본질
MM-BSN은 “blind-spot의 개수를 늘린 모델”이 아니라,
“blind-spot의 형태를 구조적으로 확장하여, 실제 노이즈의 공간적 상관 구조를 직접 분해하려는 최초의 시도”라는 점에서 의미가 있습니다.
이상으로 MM-BSN에 대한 논문 리뷰를 마무리하도록 하겠습니다!
감사합니다🥲
