
CS231N - Lecture 5 | Convolutional Neural Networks
Convolutional Neural Networks (CNN)

Fully Conected Layer
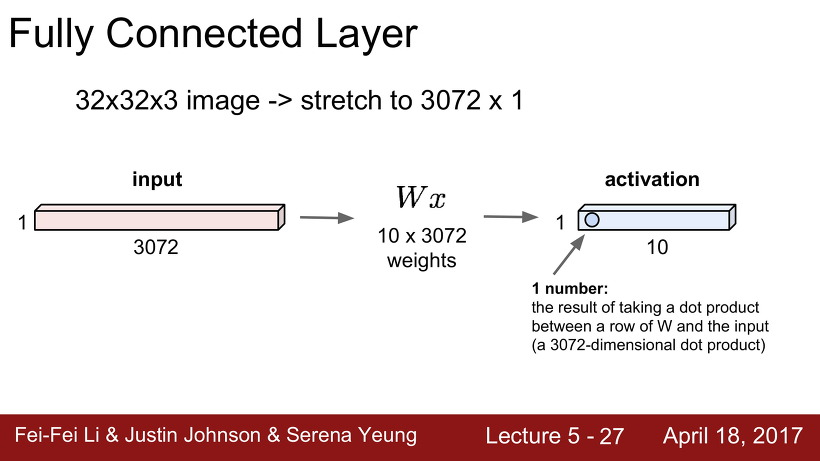
지난 강의에서 배웠던 Fully Connected Layer에 대해 다시 한번 짚고 넘어가자.
32 x 32 x 3의 이미지가 있으면, 그것을 3072 x 1의 크기로 변환시킨 것을 input값으로 하고, 값들은 (클래스 개수인) 10 x 3072로 만들어 둔 뒤에, input과 Weight를 곱하여 10개의 output 값들을 만들어 내는 layer가 Fully connected layer이다.
Convolutional Layer

Convolve란 입력 이미지에 filter를 슬라이딩해서 내적을 구하는 것을 말한다.
Weight는 위의 자그마한 filter가 될 것이다. filter의 경우 가로, 세로의 크기는 input보다 크지만 않으면 되지만 깊이는 무조건 같아야한다.
Fully Connected Layer vs Convolutional Layer
Convolutional Layer에서는 Fully Connected Layer와 달리 input값을 stretch하지 않고 원형을 보존한다.
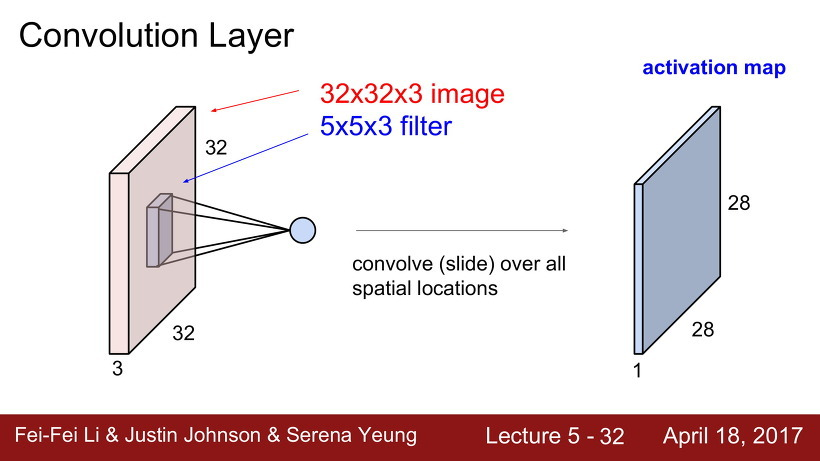
그렇게 하나하나 점곱을 하다보면, 다음과 같은 28 x 28 x 1 크기의 output을 얻게 되는데 이를 activation map 이라고 한다. activation map은 이미지가 가지는 특징을 나타내어주는 역할을 한다.
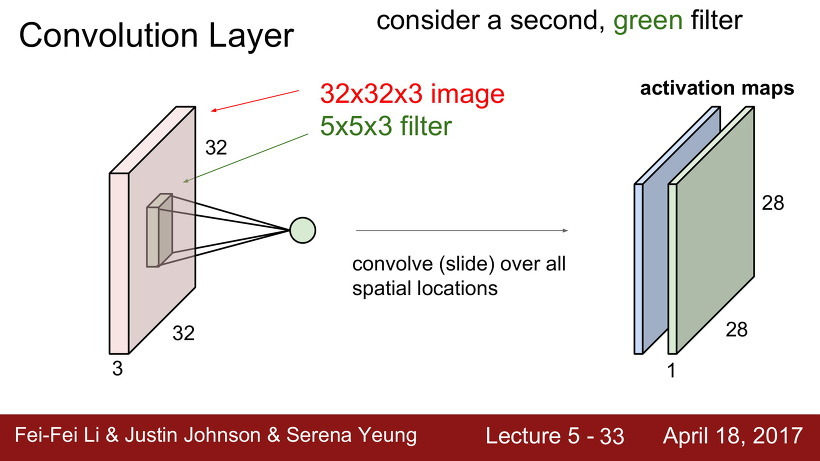
Convolution Neural Network (CNN) 에서는 filter를 하나만 사용하지는 않는다. 다양한 필터를 사용하여 필터마다 다른 특징을 나타내게 만든다.
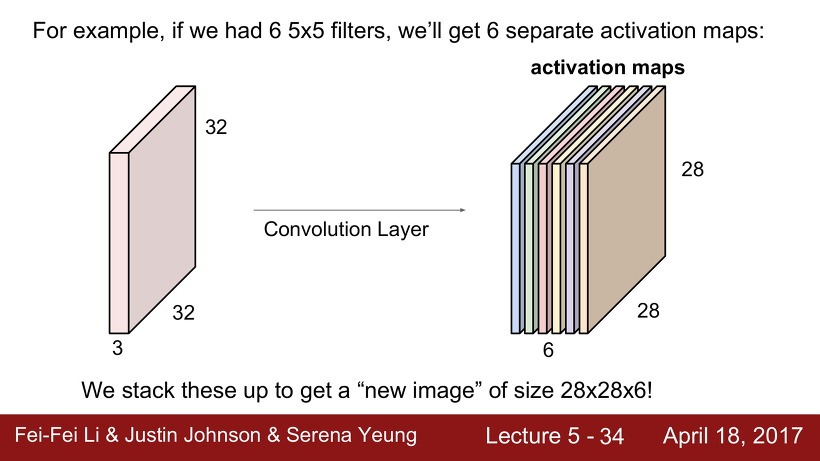
예를들어, 6개의 filter를 사용한다면 6개의 activation map이 나온다. 그렇게 나온 6개의 activation map을 모아 크기 28 x 28 x 6의 새 이미지를 얻을 수 있다.
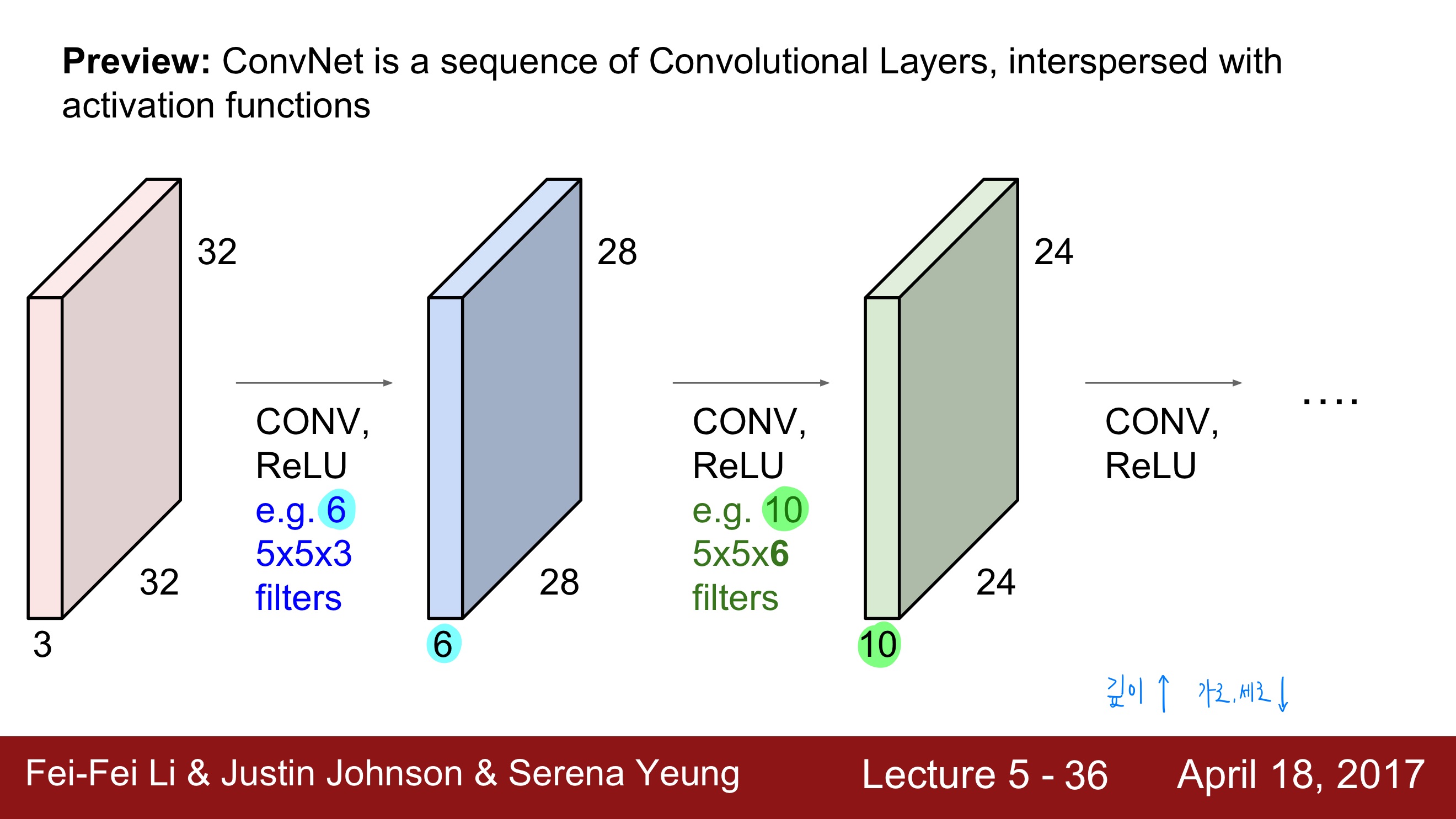
CNN에서는 입력 이미지가 convolution layer와 활성함수 ReLU를 통과하여 activation map을 얻고, 앞에서 얻은 activation map에 다시 convolution layer와 활성함수 ReLU를 통과하여 다시 activation map을 얻는 과정을 반복적으로 하게 된다. (ConvNet은 activation map이 흩어져 있는 Convolution Layers의 배열이다.)
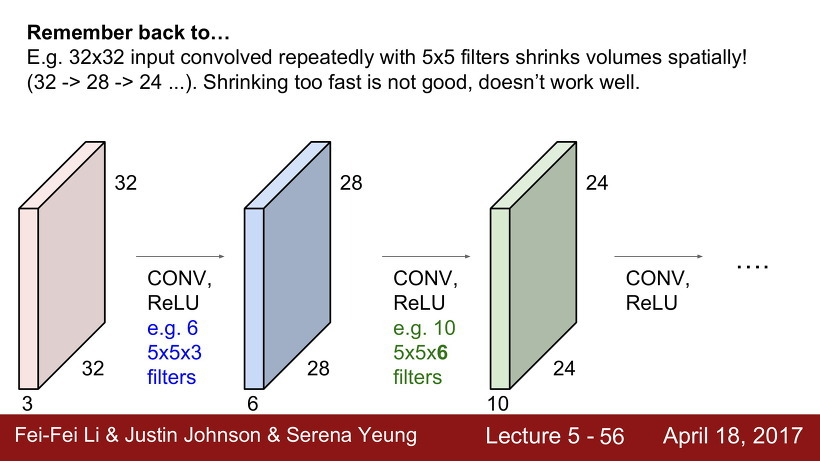
그림을 설명하면 다음과 같다. 32x32x3의 입력 이미지를 6개의 5x5x3(입력 이미지의 depth가 3이므로 필터의 depth도 3)의 필터로 내적하여 28x28x6(필터의 개수가 6개이므로 depth가 6)의 activation map을 얻는다. 28x28x6의 activation map은 입력 이미지가 되어 10개의 5x5x6(입력 이미지의 depth가 6이므로 필터의 depth도 6)의 필터와 내적을 하고 24x24x10(필터의 개수가 10개이므로 depth가 10)의 activation map을 얻는다. 이 과정이 계속 반복된다.
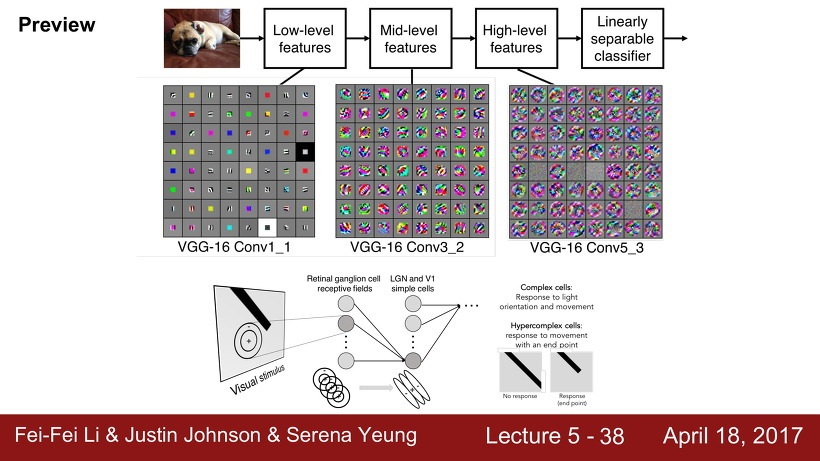
필터가 여러개 쌓일수록 필터는 간단한 특징들(low-level)부터 가면 갈수록 더욱더 복잡하고, 정교한 특징들을 얻어내는 것이다.
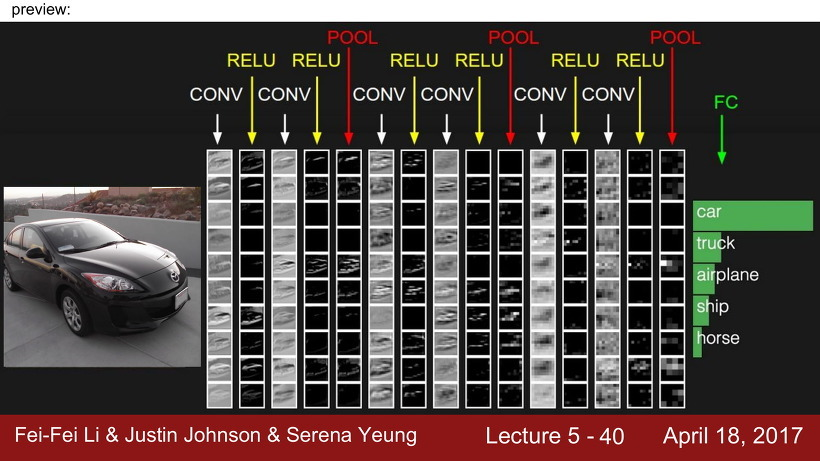
CNN의 기본 구조는 다음과 같이 이루어져 있다. Convolution layer에 활성함수인 ReLU를 쌓고, activation map의 크기를 줄여주는 pooling layer를 쌓는 방식을 여러 번 한 후, 마지막에 Fully connected layer를 쌓아 이미지를 클래스별로 분류한다.
Stride
Stride 는 보폭이라는 의미로 필터를 적용하는 간격을 정한다.
패딩을 크게하면 출력 데이터의 크기가 커지는 반면 스트라이드를 작게하면 출력 데이터의 크기는 작아진다.
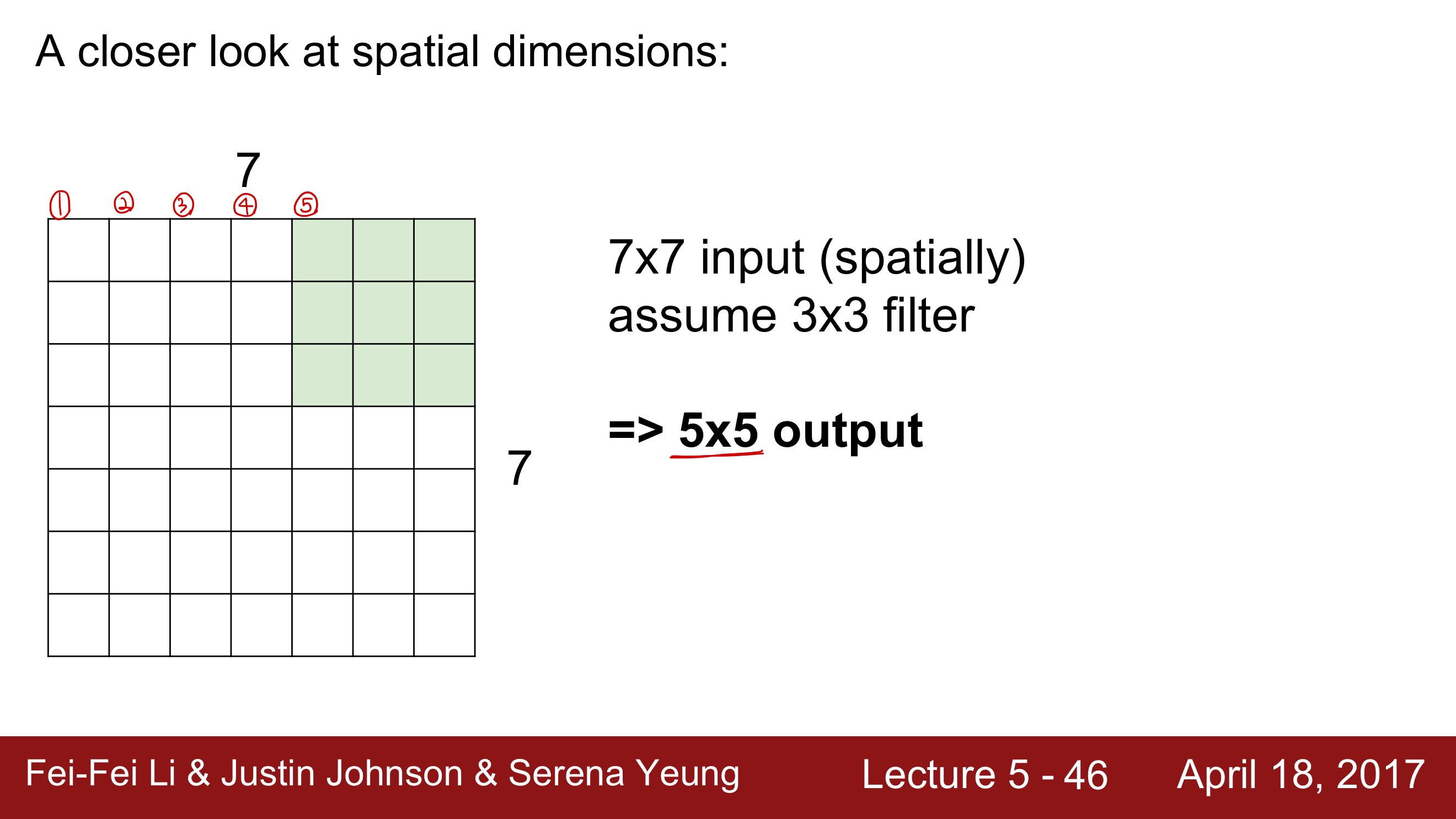
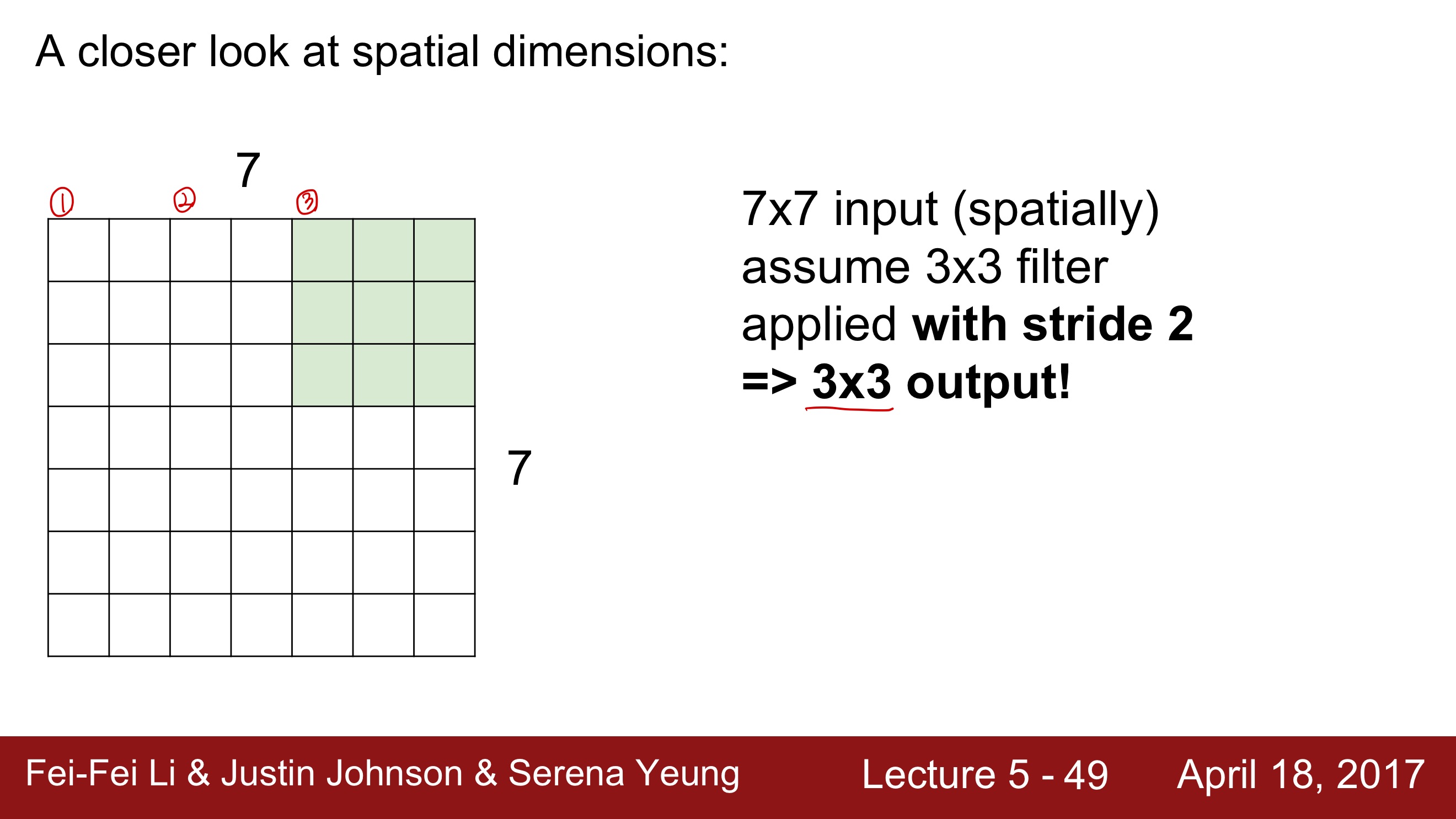
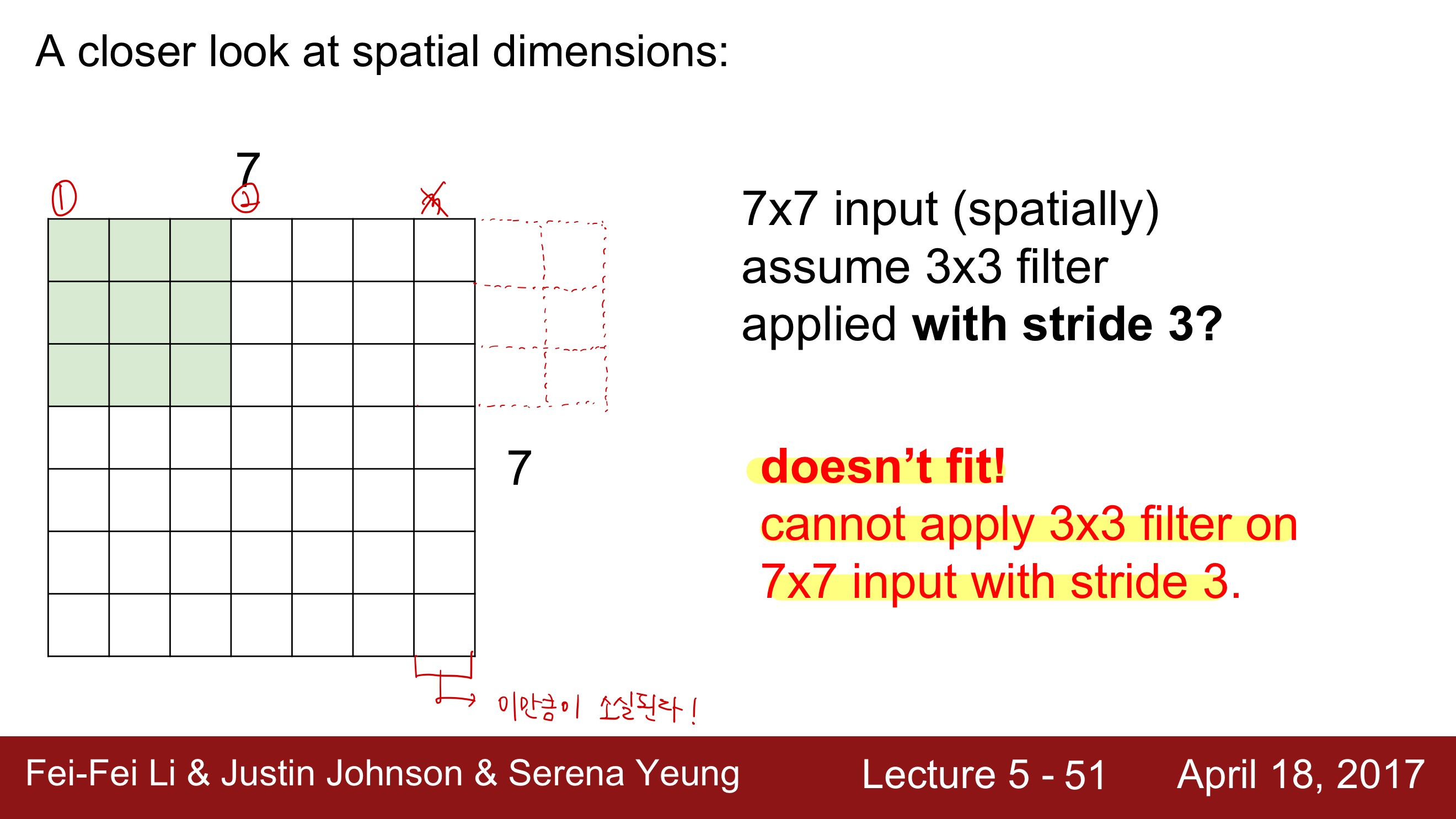
Stride = 1로 설정하고 slide하면서 점곱을 하면 ouput의 크기는 5 X 5가 된다.Stride = 2로 설정하고 slide하면서 점곱을 하면 ouput의 크기는 3 X 3이 된다.Stride = 3으로 설정하고 slide하면 7 X 7을 모두 커버할 수가 없다. 결국 마지막에 한줄이 남게 되는데, 그러면 오른쪽 한줄이 손실되는 결과를 가져오게 된다.

산술적으로 생각해보면, 이기 때문에 다음의 식을 적용하여 계산하면 Stride = 3 인 경우에 Output size가 자연수가 아닌 값이 나오게 된다. 하지만, 크기는 당연히 자연수여야하기 때문에 Stride = 3 인 경우는 성립하지 않는다.
Padding
Padding 이란 이미지의 가장자리 부분에 어떠한 숫자들을 채워 넣는 것을 의미한다.
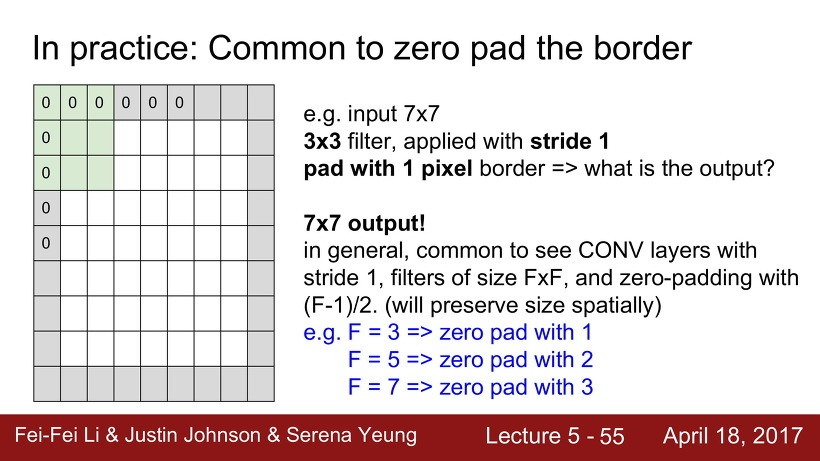
일반적인 경우엔 convolutional layer은 stride는 1로 하고, filter 크기가 F X F라면 padding은 (F-1)/2의 크기만큼 한다고 한다.
왜 Padding을 하는 것일까?
이미지에 filter를 적용하면 깊이 말고 크기가 계속 줄어드는데, 이는 이미지의 부분적인 요소들을 보존하자는 취지를 생각하면 별로 좋지 못하기 때문에 입력데이터가 합성곱의 결과로 크기가 줄어들면서 데이터의 특성이 손실되는 것을 막고자, 입력데이터의 주변에 임의로 추가 픽셀을 둘러주는 것이다.
Summary

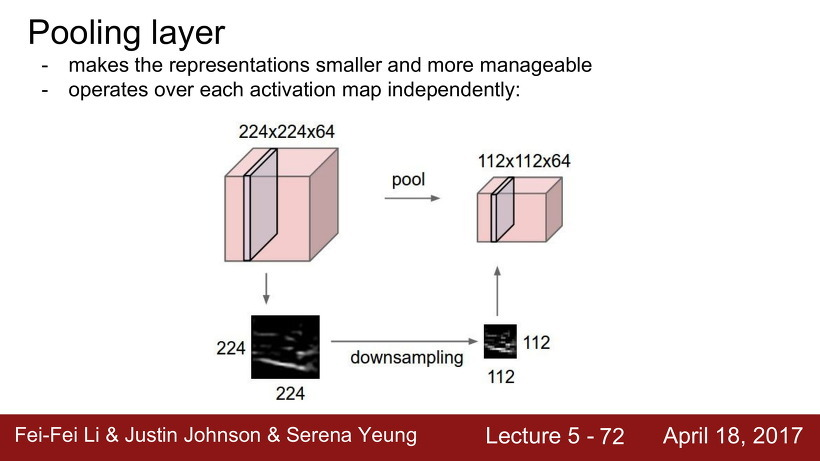
Pooling Layer
Pooling layer는 특성을 잃지 않고 데이터 크기를 조정하는 역할을 한다.
Pooling 은 activation map의 크기를 downsampling 하는 과정을 말한다. 즉, 이미지의 크기를 줄이는 것이다.
여기서 크기를 안줄이려고 padding 했는데 왜 크기를 줄이는거지? 라는 의문점이 생긴다.
Padding 을 한 것은 크기 보존뿐만 아니라, 이미지의 부분적 특징을 살리기 위해서 한 것이다. 계속 convolution을 하면 가장자리 부분의 특징이 잘 살아나지 못하기 때문이다.
Pooling은 이미지의 특정 부분을 잘라내는 것이 아니라, 사진 전체 부분을 유지한 상태로 픽셀만 줄이는 것이다.
Max pooling
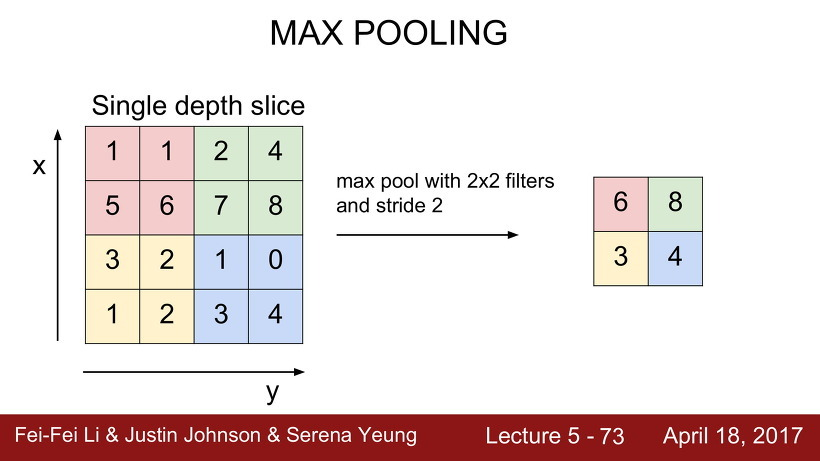
Max Pooling 은 크기별로 필터를 취해, 필터의 영역 안에서 가장 큰 값을 치해 downsampling하는 것이다.
여기서 주의해야 할 점은, 일반적으로 stride는 filter끼리 서로 겹치는 것은 지양해야 한다는 것이다. 가령, 위의 stride가 1이라면, 빨간 부분과 초록 부분 사이에 걸치는 부분이 생기게 되는데, 이러면 조금 곤란해진다.
더불어, Pooling Layer에는 zero-padding을 하는 것이 일반적이지 않다.
Fully Connected Layer (FC Layer)

입력 이미지는 Convolution layer, ReLu, Pooling layer를 통과한 후, 마지막으로 FC layer를 통과한다. CNN의 마지막 층인 FC layer에서는 이전의 데이터를 1차원 벡터로 펴주고 가장 마지막에 Softmax에서 클래스를 구분하게 된다.
SUMMARY
CNN의 구성
- Convolutional Layer : 필터와 입력데이터의 합성곱을 이용해 입력데이터의 특성을 추출
- Filter : depth는 입력데이터와 동일하게 유지. 입력데이터와 dot연산을 진행하여 모두 더한 값의 집합을 activation map으로 출력
- Stride : Filter가 한번 이동하는 칸수
- Padding : Convolution 시행시 데이터 크기를 유지하기 위해 입력데이터의 주변에 두르는 픽셀
- Pooling layer : 데이터의 크기를 줄이는 층
- 주로 Max pooling을 이용하고, Filter 안에서 가장 큰 입력데이터의 픽셀값을 뽑아 출력하게 됨.
- 입력데이터의 위치가 조금 변해도, 출력값이 유지됨
- Fully Connected Layer : 위의 결과를 1차원 벡터로 펴서 Softmax함수에 넣어 클래스를 구분
