1. 합성곱 신경망 (Convolutional Neural Network; CNN)
- 딥러닝 프레임워크 중 모델링에 사용하는 한 종류
- 이미지 처리와 컴퓨터 비전 문제에 탁월한 성능을 발휘함 (데이터의 공간적 구조와 패턴을 학습하는데 적합)
- 이미지의 이동, 회전에 강건한 특성을 가지며 데이터로부터 자동 특징 추출이 진행되므로 연구자의 개입이 적은 편
- 활용 분야: CT/MRI 이미지 분석, 자율주행, 얼굴 인식, 문장 내 패턴 학습 등
1-1. 주요 레이어
-
합성곱 레이어 (Convolutional Layer)
- 필터(커널)을 사용하여 스트라이드만큼 이동시켜가며 입력 이미지에서 특징(feature)을 추출하는 기능을 가짐
- 합성곱 연산을 통해 작은 영역에서 패턴 학습 가능
-
풀링 레이어 (Pooling Layer)
- 특징 맵(feature map)의 크기를 줄여 계산량과 모델 복잡도를 감소시키고 데이터를 요약시킬 수 있음
- 영역의 최댓값을 선택하는 Max Pooling, 평균값을 취하는 Average Pooling 등의 기법을 활용함.
-
완전 연결 레이어 (Fully Connected Layer; FC Layer)
- 추출된 특징을 기반으로 최종 출력(클래스 분류 등)을 도출
- 일반적인 신경망처럼 작동하며, 최종 출력은 클래스 확률(softmax) 또는 회귀값으로 나타낼 수 있음
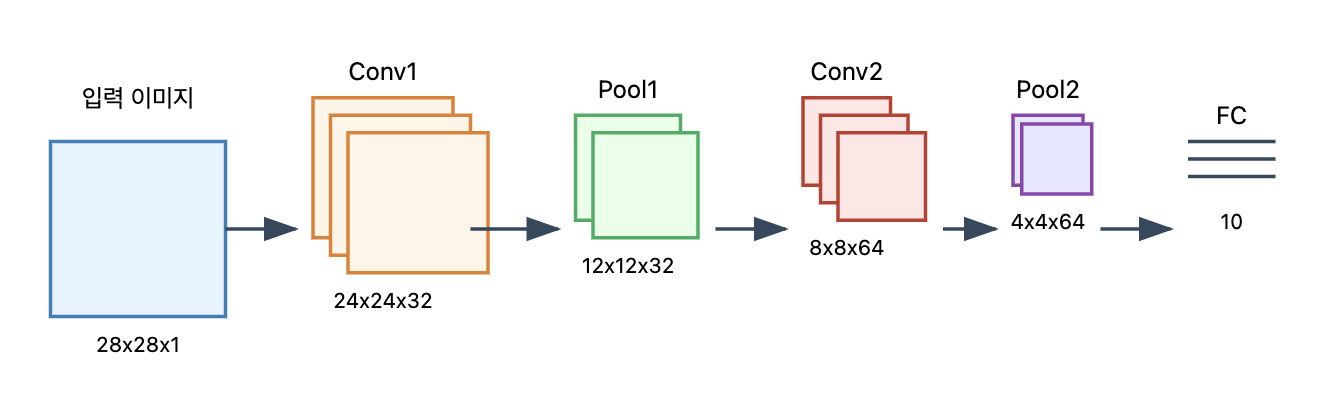
1-2. 학습 과정
-
예를 들어, 사이즈의 흑백 이미지가 주어졌을 때,
-
합성곱 레이어: 필터를 사용해 스트라이드만큼 이동하며 여러 개의 특징 맵을 추출
-
풀링 레이어: 특징 맵의 크기를 줄이고 중요한 정보만 보존
-
추가로 더 쌓은 합성곱 레이어 + 풀링 레이어를 통해 고수준 특징을 학습
-
FC 레이어: 학습된 데이터를 Flatten하여 벡터로 변환한 뒤 분류 수행
2. CNN 구현
2-1. Data Acquisition & Preprocessing
- 데이터 전처리 (클래스 활용)
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
class MNISTDataLoader():
def __init__(self):
(self.X_train, self.y_train), (self.X_test, self.y_test) = mnist.load_data()
def validate_pixel(self, val):
return 255 >= val.max() and 0 <= val.min()
def scale_pixel(self, val):
return (val / 255.0).astype("float32")
def preprocess_data(self, X, y):
# 데이터 검사 (X, y)
X_valid = np.array([val for val in X if self.validate_pixel(val)])
# 데이터 스케일링 (X)
X_scaled = np.array([self.scale_pixel(val) for val in X_valid])
# 데이터 차원 확장 (X)
# CNN은 4차원 구조를 입력으로 취함 (Batch Size, Height, Width, Channels)
X_exp = X_scaled[:,:,:,np.newaxis]
# 데이터 One-hot Encoding (y)
y_ohe = to_categorical(y, num_classes=10).astype("float32")
return X_exp, y_ohe
def get_train_data(self):
return self.preprocess_data(self.X_train, self.y_train)
def get_test_data(self):
return self.preprocess_data(self.X_test, self.y_test)
# 객체 생성 및 함수 호출
X_train, y_train = MNISTDataLoader().get_train_data()
X_test, y_train = MNISTDataLoader().get_test_data()
# 결과 확인
print(X_train.shape, y_train.shape) # (60000, 28, 28, 1) (60000, 10)
print(X_test.shape, y_test.shape) # (10000, 28, 28, 1) (10000, 10)2-2. Modeling
- CNN 모델링
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Activation, MaxPool2D, Flatten
model = Sequential([
Conv2D(32, kernel_size=(3,3), padding="same", activation="relu", input_shape=(28, 28, 1)),
Conv2D(32, kernel_size=(3,3), padding="same", activation="relu"),
MaxPool2D(pool_size=(2,2)),
Conv2D(64, kernel_size=(3,3), padding="same", activation="relu"),
Conv2D(64, kernel_size=(3,3), padding="same", activation="relu"),
MaxPool2D(pool_size=(2,2)),
Flatten(),
Dense(128, activation="relu"),
Dense(54, activation="relu"),
Dense(10, activation="softmax"), # 0~9 예측
])
model.summary()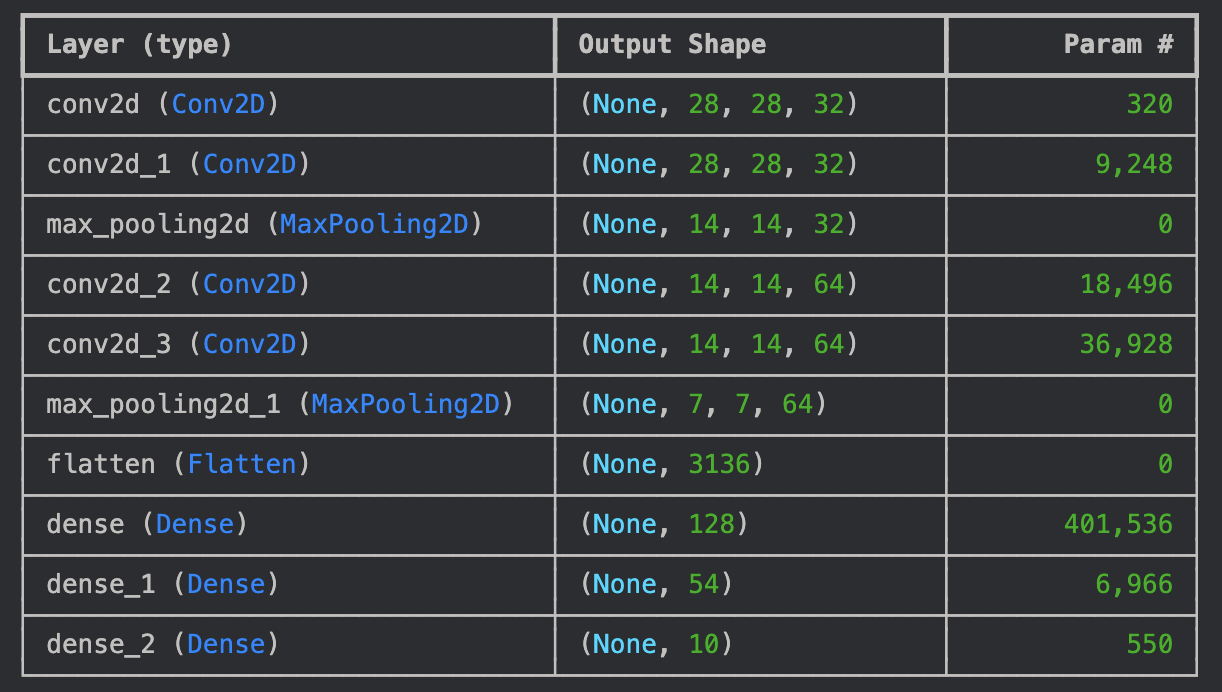
- 모델 컴파일 및 학습
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import categorical_crossentropy
opt = Adam(learning_rate=0.03) # 최적화함수
loss = categorical_crossentropy # 손실함수
model.compile(loss=loss, optimizer=opt, metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=10, batch_size=512, validation_data=(X_test, y_test))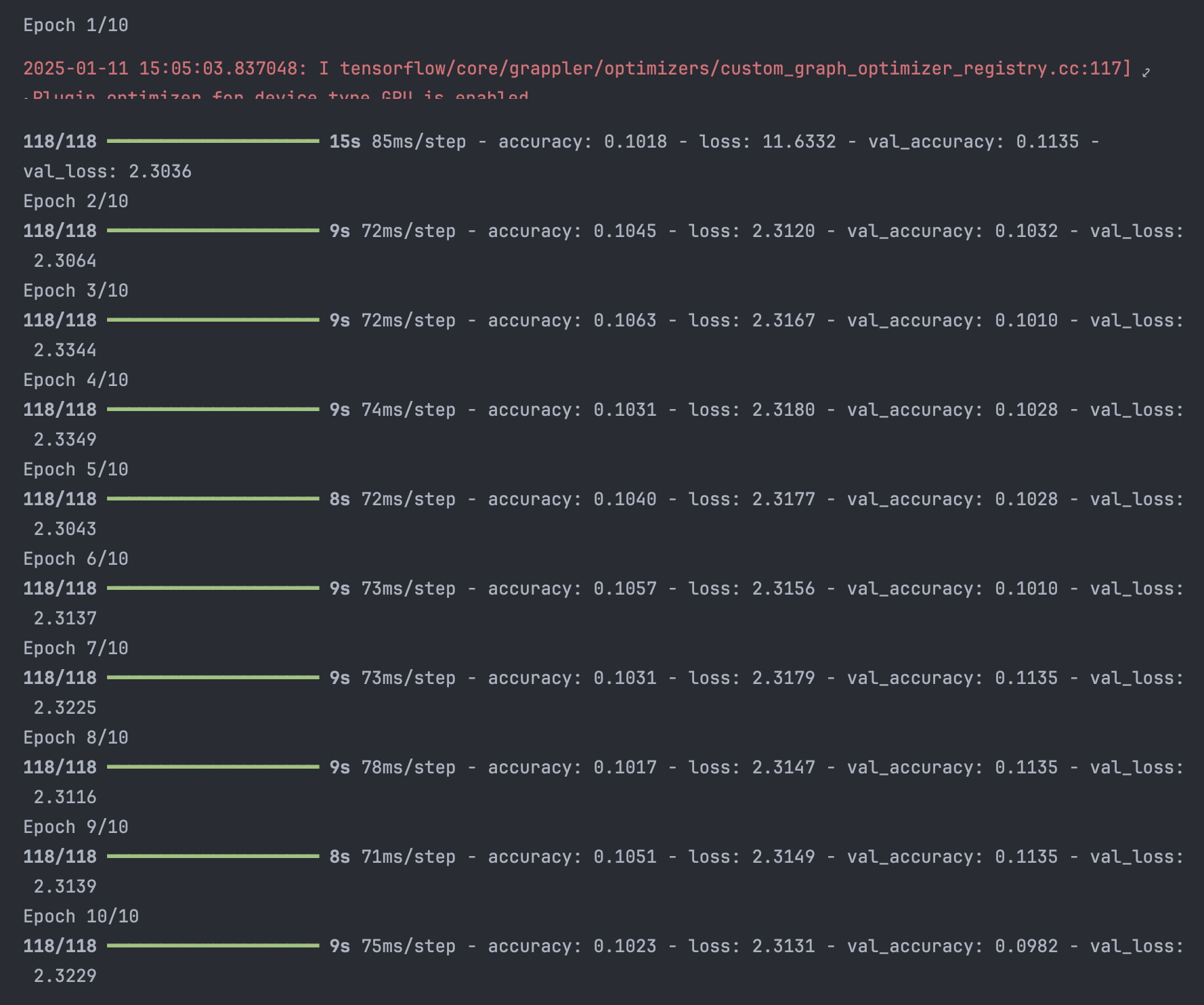
2-3. Evaluation
- 학습과정 확인
fig, ax1 = plt.subplots(figsize=(5, 3))
ax2 = ax1.twinx()
ax1.plot(np.arange(1, 11, 1), hist.history['loss'], label="Loss", c="grey")
ax1.set_xlabel("Epoch")
ax1.set_ylabel("Loss")
ax2.plot(np.arange(1, 11, 1), hist.history['accuracy'], label="Acc.", c="red")
ax2.set_ylim([0, 1])
ax2.set_ylabel("Acc.")
fig.suptitle("Loss and Accuracy")
fig.legend(bbox_to_anchor=(0.88, 0.7))
plt.show()
# 학습이 현저히 부족한 상태로, epoch을 훨씬 많이 진행해야 할 것으로 예상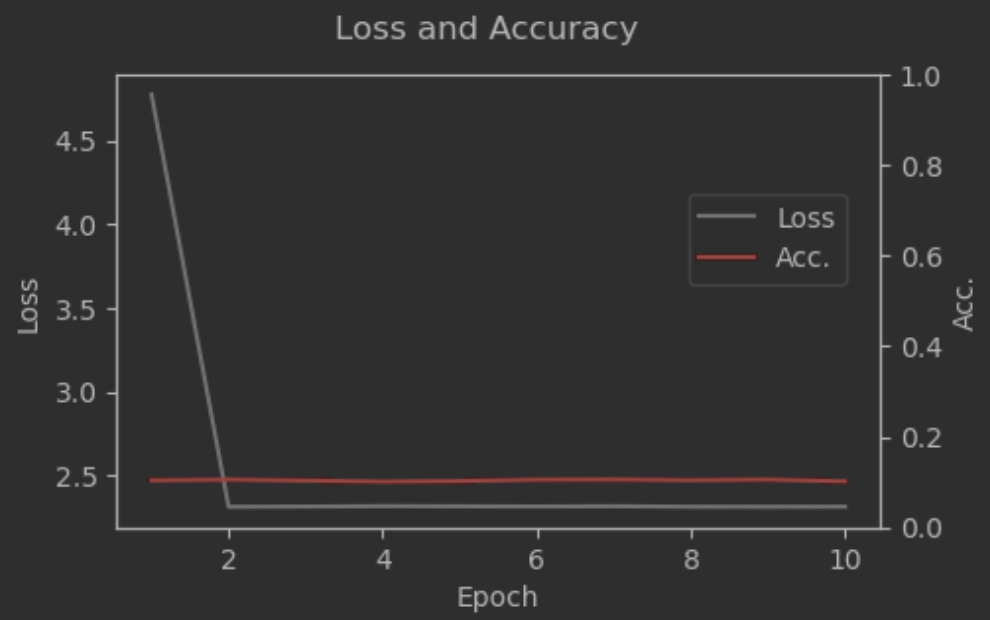
- 모델 예측
y_pred = model.predict(X_test)
print(y_pred[0].argmax()) # 4
print(y_test[0].argmax()) # 7
# 정확도가 낮았던 만큼 1번 샘플에 대한 예측이 틀렸고, 추가 학습이 더 필요함*이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다.

데이터 분석, 데이터 사이언스 학습 저장소