결측데이터 처리하기
isna()
데이터가 NaN인지 아닌지 알려준다.
DataFrame에서 isna()를 수행하면 모든 칼럼의 값이 NaN인지 아닌지를 True나 False로 알려준다.
titanic_df.isna().head(5)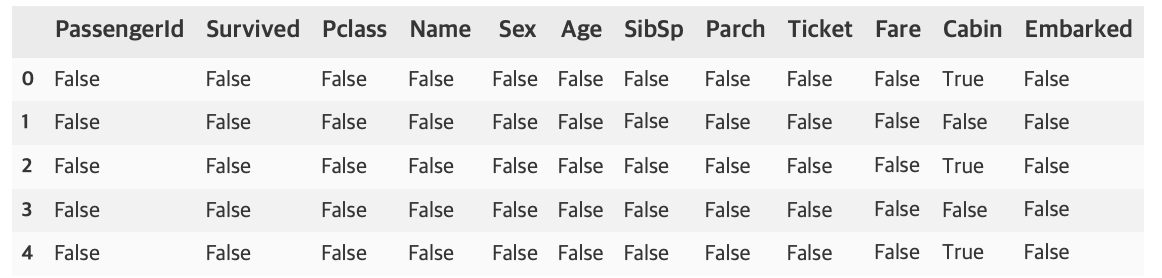
kaggle titanic 대회에서 많이 쓰는걸로 보였던 식은 아래와 같다.
titanic_df.isna().sum()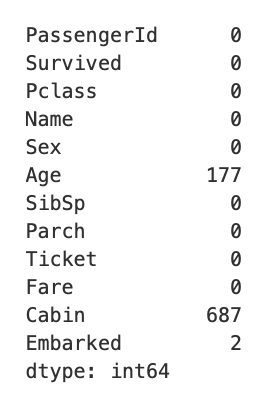
이 글을 작성하는 현재까지 titanic 예제만 봤고 그 데이터엔 결측값들이 존재했다. 즉 위의 식을 이용해서 결측값이 있는 칼럼을 찾아내고 그 결측값들을 어떻게 채울 것인지에 따라 예측 결과에 영향을 줄 수 있다고 생각된다.
fillna()
NaN값 대체하기
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
titanic_df.head(3)
위에서 언급했듯이 결측값을 채울때 사용하는 메서드이다. 앞으로 수많은 분석을 진행하면서 isna로 결측값의 유무를 판단하고 fillna로 채운다고 생각하면 된다.
apply lambda 식으로 데이터 가공하기
def get_square(a):
return a**2
print(f'3의 제곱은: {get_square(3)}')lambda_square = lambda x : x ** 2
print(f'3의 제곱은: {lambda_square(3)}')[Output]
3의 제곱은: 9
여러 개의 값을 입력 인자로 사용하는 경우 map()함수와 같이 사용한다.
a = [1, 2, 3]
squares = map(lambda x : x**2, a)
list(squares)[Output]
[1, 4, 9]
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <= 15 else 'Adult')
titanic_df[['Age', 'Child_Adult']].head(8)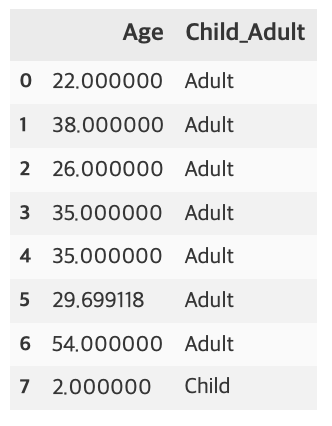
위와 같이 if-else식과 함께 사용할 수 있다. 하지만 lambda에는 else if 가 없기때문에 else절 안에 if~else를 적용해서 사용해야한다. 그러다보니 세분화가 이루어 지는 경우 반복사용하기 부담스럽다. 이런 경우 함수를 만드는게 낫다.
def get_category(age):
cat = ''
if age <= 5: cat = 'Baby'
elif age <= 12: cat = 'Child'
elif age <= 18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Young Adult'
elif age <= 60: cat = 'Adult'
else: cat = 'Elderly'
return cat
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
titanic_df[['Age', 'Age_cat']].head()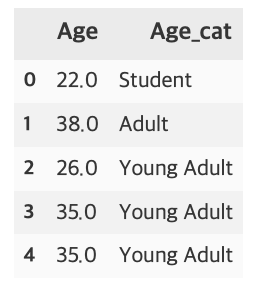
Source: 파이썬 머신러닝 완벽 가이드 / 위키북스

데이터 분석 공부용 벨로그
글 잘 읽었습니다 코드싸개님:)
이 과정을 마칠 땐 그 누구보다 성장해 있을 코드싸개님
동기사랑 나라사랑외치면서 꼭 잘해보아요 코드싸개님