
앞서 사용했던 wine 데이터를 사용해서 Cross Validation을 사용한 와인 분류 모델을 만들어보려 한다..!
1. 데이터 불러오기
import pandas as pd
red_wine = pd.read_csv(red_url, sep=';') white_wine = pd.read_csv(white_url, sep=';') red_wine['color'] = 1 white_wine['color'] = 0 wine = pd.concat([red_wine, white_wine])
이번에도 color 컬럼에 레드와인은 1, 화이트와인은 0 값을 주고, 두 데이터를 합쳤다.
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
그리고 taste 값이 5보다 크면 1, 5이하면 0 값을 갖는 quality 컬럼도 만들었다.
2. KFold
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.model_selection import KFold
X = wine.drop(['taste', 'quality'], axis=1) y = wine['taste'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
X는 feature, y는 분류 대상을 의미한다.
분류대상인 taste 는 quality 로 만든 것이므로, X는 두 컬럼을 제외한 다른 컬럼이 된다.
kfold = KFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
kfold 에서 데이터를 5등분 하는것으로 설정했다.
Decision Tree 는 max_depth를 2로 설정했다.
cv_acc = [] for tr_idx, te_idx in kfold.split(X): X_train, X_test = X.iloc[tr_idx], X.iloc[te_idx] y_train, y_test = y.iloc[tr_idx], y.iloc[te_idx] wine_tree_cv.fit(X_train, y_train) pred = wine_tree_cv.predict(X_test) cv_acc.append(accuracy_score(y_test, pred)) np.mean(cv_acc)
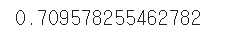
이제 반복문을 사용해 모든 fold를 학습하고, 성능을 알아보자.
kfold는 인덱스를 반환하니까 iloc[] 로 train데이터를 다시 train과 test로나눈 후
train으로 Decision Tree 모델을 학습하고, test로 성능을 확인한다.
각 정확도의 분산이 크지 않은경우, 평균을 대표값으로 사용한다.
5번의 교차검증을 한 결과, 약 70%의 정확도를 얻었다.
3. Stratified KFold
위에서 사용했던 kfold는 분류 대상의 비율이 일정하게 분리되지 않는 문제를 가지고 있다.
다시말해 train데이터를 5등분 했을 때, 한곳에는 0만 잔뜩 있고, 다른곳에는 1만 잔뜩 있는
문제점이 생길수 있다.
그런 문제를 막기 위해 사용하는 것이 StratifiedKFold 다.
StratifiedKFold 는 분류대상이 동일하게 분리되도록 해주는 기능을 갖고 있다!!
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13) cv_acc_s = [] for tr_idx, te_idx in skfold.split(X, y): X_train, X_test = X.iloc[tr_idx], X.iloc[te_idx] y_train, y_test = y.iloc[tr_idx], y.iloc[te_idx] wine_tree_cv.fit(X_train, y_train) pred = wine_tree_cv.predict(X_test) cv_acc_s.append(accuracy_score(y_test, pred)) np.mean(cv_acc_s)
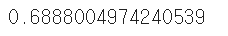
위와 동일하게 train 데이터를 5조각으로 나눠 교차검증을 해봤다.
근데... 정확도가 68%로, 더 낮은 값이 나왔다....
4. 간단한 방법으로 교차검증 하기
데이터를 나누고, 반복문을 사용해 acc값을 리스트에 저장하고, 다시 평균값을 구하고...
교차검증이 너무 복잡하다..!!
라고 생각된다면, 간소화 할 수 있는 방법이 있다!
바로 cross_val_score() 를 사용하는 것!
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13) cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)
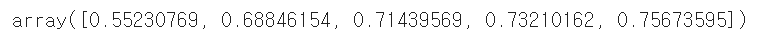
cross_val_score(모델, 분류대상, feature, cv)를 입력하면
복잡한 반복문을 한번에 해결할수 있다!
cross_val_score() 를 사용해서 max_depth를 5로 바꿔 교차검증을 해보자.
skfold = StratifiedKFold(n_splits=5) wine_tree_cv = DecisionTreeClassifier(max_depth=5, random_state=13) cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)
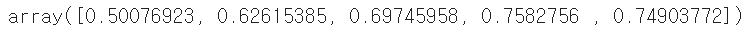
위와 비교했을때 모두 acc값이 떨어졌다.
이제 max_depth가 크다고 해서 성능이 좋다고 단언할수 없다...
5. train score와 함께 보기
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)

return_train_score=True 옵션을 사용하면 train 데이터의 acc 값도 반환한다.
train 데이터의 acc값이 test 데이터의 acc 보다 높은걸 보니, 과적합 문제도 좀 있어보인다..
물론, 이것만 보고 모델이 좋다 나쁘다를 단정할수 없다!!!
