1. 의미
모델이 학습 데이터에만 과도하게 최적화되어 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상을 과적합 이라고 한다.
과적합을 막기 위해 사용하는게 Cross Validation(교차검증) 이다.

일반적인 모델 학습 방식은 데이터셋을 train/test 데이터로 분류한뒤에
train 데이터로 모델을 학습시키고 test 데이터로 성능을 측정한다.
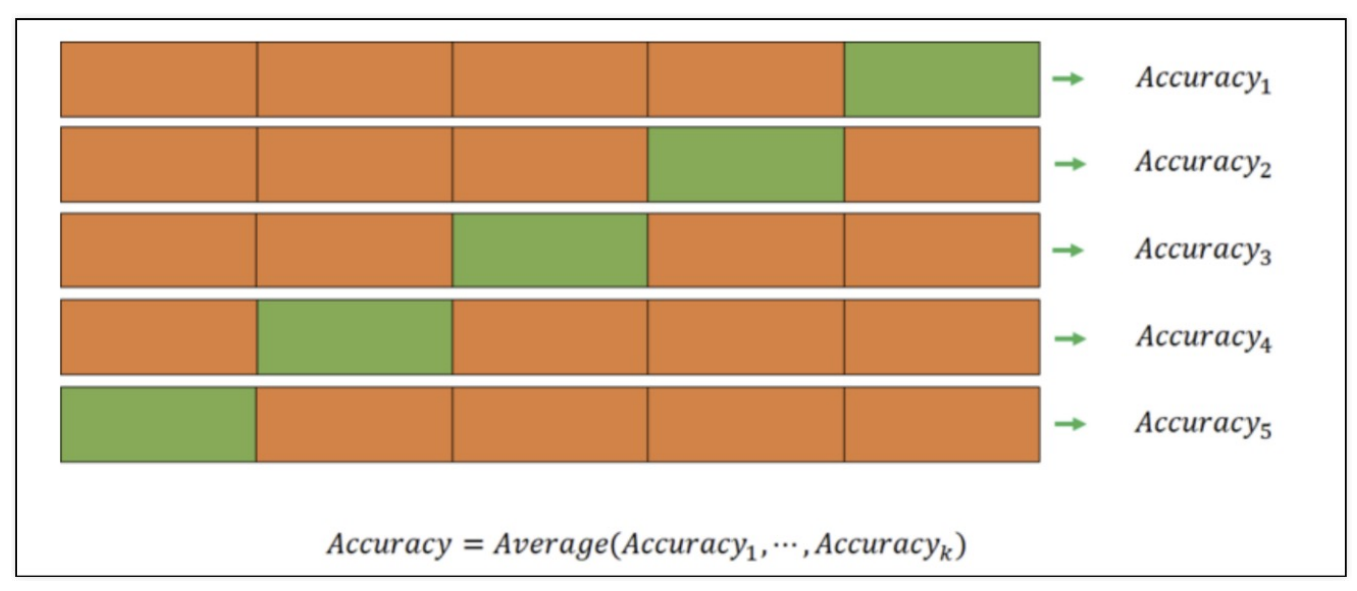
K-fold Cross Validation은 train 데이터을 여러개로 나눈 뒤에
한 블록은 test, 나머지는 train 데이터로 사용하는 방법이다.
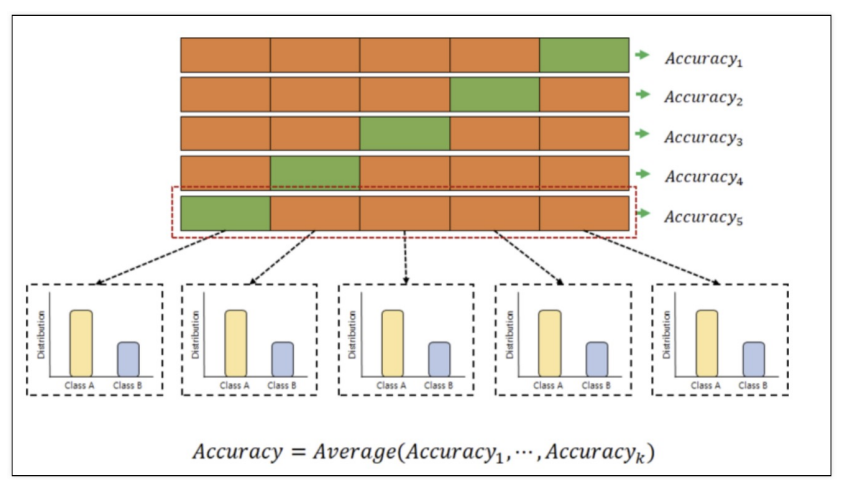
모든 조각이 한번씩 test 데이터가 되어 모델 학습과 성능 측정을 여러번 하는 방법!
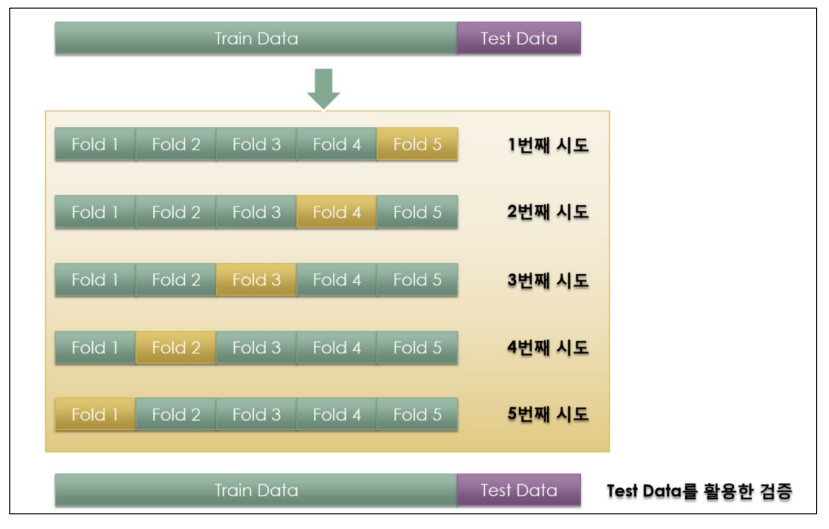
검증 validation이 끝나면 test 데이터로 최종 평가를 한다.
2. 예시
import numpy as np from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 2, 3, 4])

numpy를 사용해 임의로 X, y 데이터를 생성했다.
kf = KFold(n_splits=2) print(kf.get_n_splits(X)) print(kf)

n_splits=2 : 데이터를 2등분한다.
.get_n_splits(X) : n_splits 값을 반환
for train_idx, test_idx in kf.split(X): print('***** idx *****') print('train_idx : ', train_idx) print('test_idx : ', test_idx) print('--- train data') print(X[train_idx]) print('--- test data') print(X[test_idx]) print()

kflod는 인덱스를 반환한다!
첫번째 부분을 보면 train데이터를 2등분해서
2,3 인덱스를 갖는 [5 6], [7 8] 을 train 용으로,
0,1 인덱스를 갖는 [1 2], [3 4] 을 test 용으로 사용한다는 의미다.

데이터 분석으로 세상을 읽어보쟈 빠샤