
오늘 정리할 내용은 CNN입니다. 컴퓨터 비전에 자주 사용되는 모델입니다. CNN이 어째서 컴퓨터 비전에 자주 사용되는지 그 구조와 특성, 작동 원리를 살펴보고 간단히 활용도 해보겠습니다.
1. CNN의 구조
이미지 속 피사체를 구분하려면 어떻게 해야할까요? 피사체의 특성을 포착해야 합니다. 고양이와 개를 구분하려면 귀, 눈, 코, 입, 서있는 자세, 꼬리 모양 등 파악해야할 정보가 많습니다. 이러한 정보를 지역 정보 또는 이미지의 공간적 특성이라고 부릅니다. CNN은 바로 이 지역 정보를 포착하는데 특화된 모델입니다.
1) Convolution
CNN이 어떻게 이미지의 지역 정보를 포착하는지 살펴보겠습니다. CNN에는 이미지의 특성을 추출하는 합성곱층(Convolution layer)가 있습니다. 그리고 이 합성곱층에서는 아래 이미지와 같은 일이 벌어집니다. 순서대로 살펴보겠습니다.
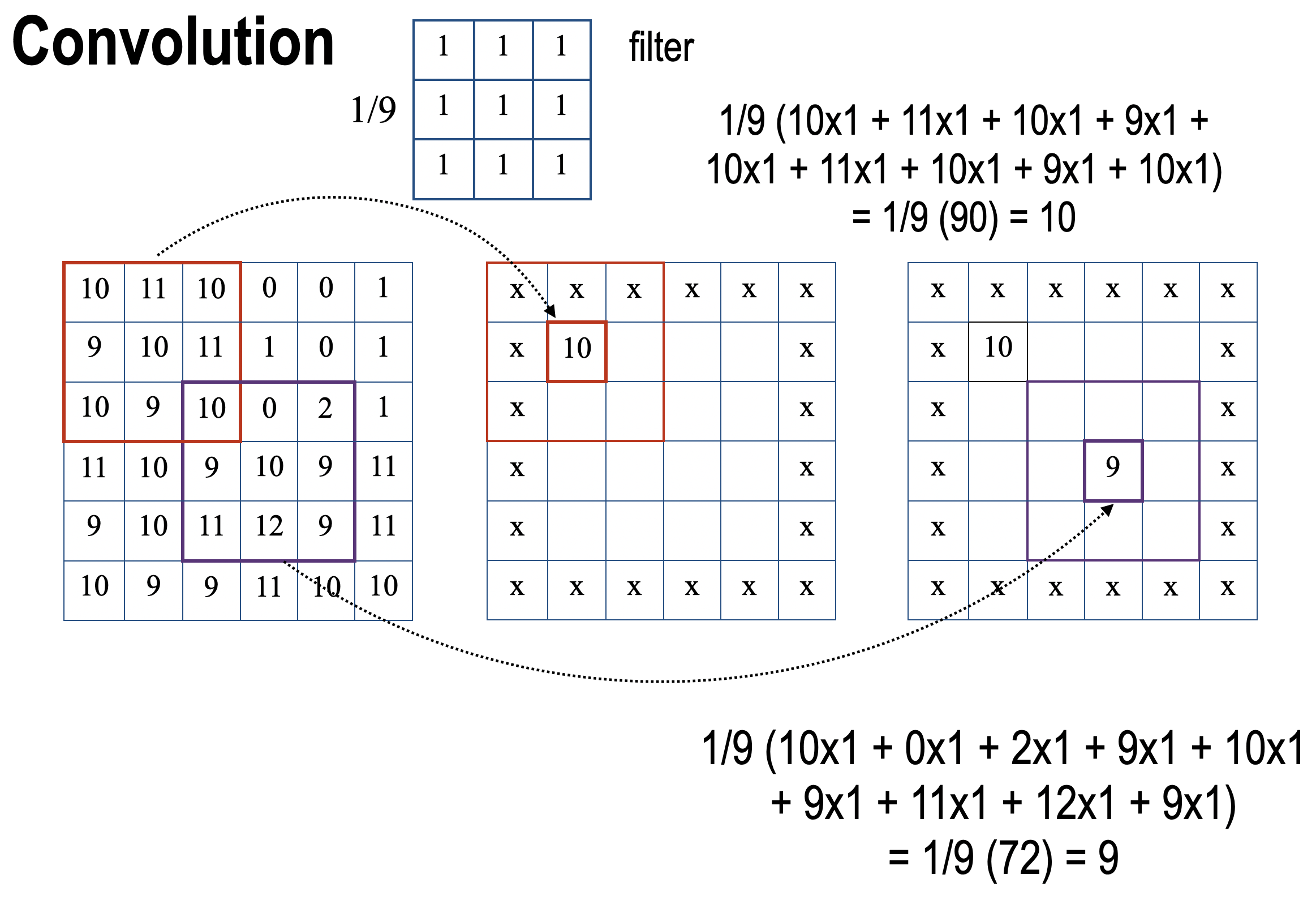
- 먼저 이미지가 합성곱층으로 input됩니다. 위 이미지에서는 6 * 6 크기의 이미지가 인풋됐습니다.
- 합성곱 필터가 이미지 위를 슬라이딩하며 합성곱을 진행합니다. 위 이미지에서는 3 * 3 크기의 필터가 이미지 위를 슬라이딩하고 있습니다.
- 슬라이딩이 모두 끝나면 feature map이라고 부르는 합성곱 결과물이 output 됩니다.
이미지가 이렇게 합성곱층에 input되면 이미지의 특성이 추출된 feature map이 출력됩니다. 여기서 가장 중요한 것은 합성곱 필터가 역전파 과정에서 학습되는 부분이라는 점입니다. 합성곱 필터의 내부 값은 이미지의 특징을 더 잘 분류하는 방향으로 조정됩니다.
2) Padding & Stride
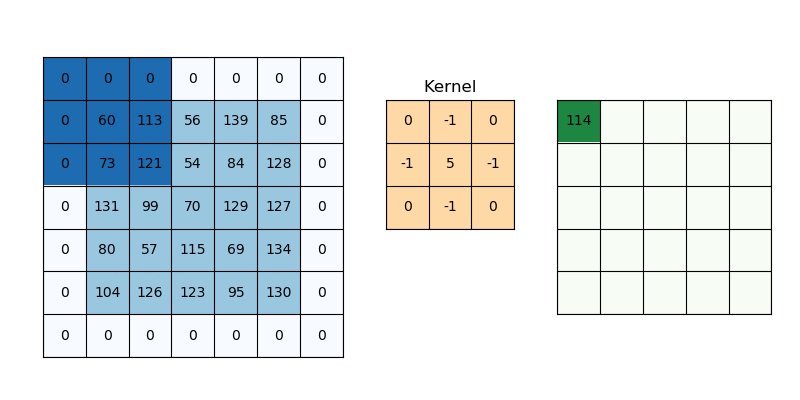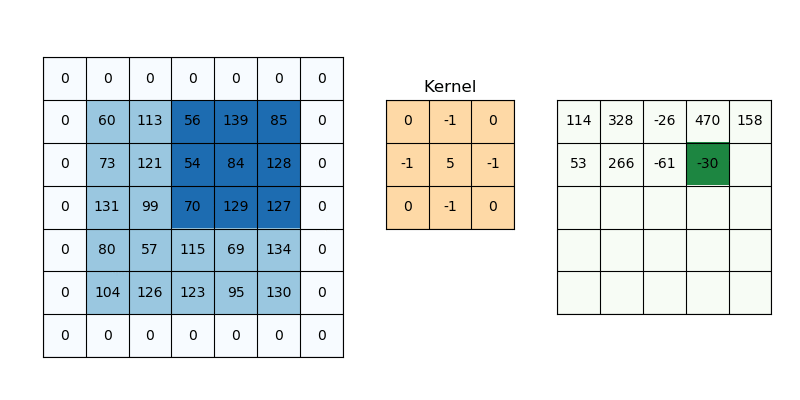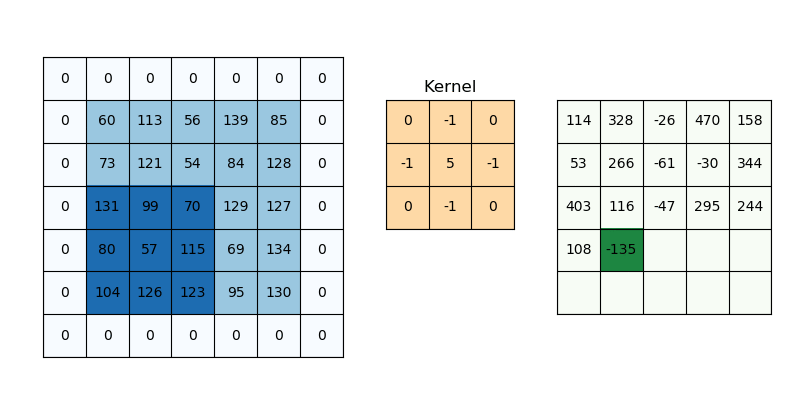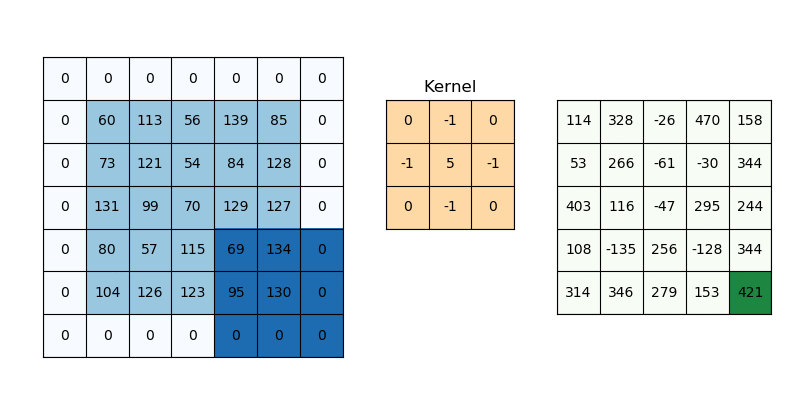
Padding
이미지에 대해 합성곱을 진행할 때 필터의 크기에 따라 feature map의 크기가 변합니다. 필터가 클 수록 출력되는 feature map의 크기는 작아집니다. 이때 이미지 둘레에 padding을 적용하면 출력되는 feature map의 크기를 조절할 수 있습니다. 보통 둘레에 0을 두르는 zero-padding이 많이 사용됩니다. 굳이 padding이 필요할까 생각할 수 있지만, feature map 간에 더해주거나 빼주는 등의 연산이 필요한 경우가 있습니다. 이때 feature map의 크기가 서로 다르다면 연산이 어렵습니다. padding을 통해 feature map의 크기를 조절함으로써 서로 연산이 가능하도록 합니다.
피쳐 맵의 크기를 조절하기 위해서만 padding이 필요한 건 아닙니다. 위의 gif에서 패딩이 없다고 생각해보면, (1, 1) 위치의 값, 즉 모서리에 있는 값은 필터에 단 한번만 연산됩니다. 이미지의 모든 특성이 고르게 feature map에 반영되기 위해서라도 Padding 처리는 꼭 필요합니다.
Stride
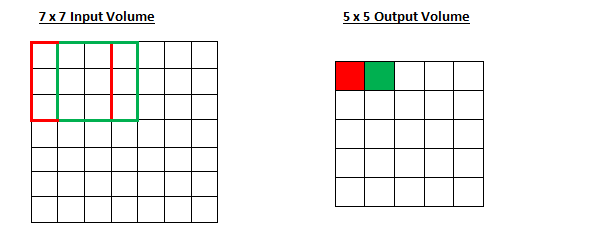
필터의 크기에 따라 피쳐 맵의 크기가 바뀐다고 말씀드렸는데요. 슬라이딩의 보폭에 따라서도 피쳐 맵의 크기가 변할 수 있습니다. 위 이미지에서 stride는 1입니다. 한 칸씩 슬라이딩하고 있습니다. stride가 2일 때는 어떨지도 보겠습니다.
- stride = 1
- stride = 2
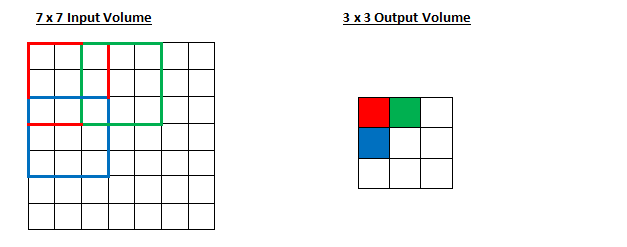
정리하자면, 보폭과 필터가 작을 수록 이미지의 특성을 더욱 꼼꼼하게 feature map에 반영합니다. 대신 출력되는 feature map의 크기가 너무 커서 Filter가 이미지를 한 번에 포착할 수 없게 됩니다.

위 예시는 이미지가 합성곱층을 지나면서 점점 작아지고, Filter가 더 큰 특징을 포착하게 되는 과정을 보여줍니다. 이미지가 너무 클 때 필터는 가로, 세로 등의 부분적 특징을 학습하고, 층이 깊어지면서(=이미지의 크기가 작아지면서) 물체의 일부, 전체 특징을 포착합니다.
그럼 filter의 크기와 stride를 너무 크지 않게 하면서, 이미지의 크기를 줄이는 방법은 없을까요? Pooling을 진행하면 filter와 stride 크기와 관계 없이 feature map의 크기를 줄일 수 있습니다.
3) Pooling
Pooling은 Feature map의 정해진 범위 내에서 가장 큰 값 또는 평균 값을 꺼내오는 방식입니다. 전자를 최대 풀링, 후자를 평균 풀링이라고 합니다. 정해진 범위 안에서 가장 큰 값을 가져옴으로써 이미지의 특징은 보존한 채로 Feature map의 크기를 줄일 수 있습니다.
아래 이미지는 최대 풀링과 평균 풀링을 비교한 그림입니다.

일정한 범위 안에서 연산이 일어나고, 원본 데이터의 크기가 줄어든다는 점에서 Convolution과 비슷하다고 느낄 수 있지만 Pooling에는 학습할 가중치가 없습니다. 또한 필터의 수만큼 채널이 늘어나는 Convoltion과 달리 Pooling에서는 채널 수의 변화가 일어나지 않습니다.
4) 완전 연결 신경망(Fully Connected Layer)
입력 데이터에 대해 Convolution과 Pooling을 진행했다면 최종적으로 분류를 위한 layer와 연결합니다. 이를 완전 연결 신경망이라고 부르며, 다층 퍼셉트론 신경망과 같은 모습입니다. 풀어야 할 문제에 따라 출력층을 설계합니다.

2. CNN 활용
위에서는 주로 이미지 데이터를 기준으로 설명했지만, CNN은 자연어처리에도 사용할 수 있습니다. 문장의 지역 정보를 포착하여 문맥을 고려한 분석이 가능하며, 병렬 처리가 가능해서 연산이 빠르다는 장점이 있습니다.
1) 전이학습
전제는 충분한 양의 학습입니다. 딥러닝 모델은 데이터를 많이 학습하면 학습할 수록 높은 정확도를 보입니다. 하지만, 양질의 이미지를 학습시키기 위한 과정이 너무 번거롭게 많은 시간이 걸립니다.
이를 해결하기 위해 전이 학습을 이용합니다. 전이 학습은 대량의 데이터를 학습한 모델의 가중치만 그대로 가져온 뒤 FCL만 덧붙여서 사용하는 방법입니다. 이때 사전 학습한 모델의 가중치는 데이터의 일반적인 특징을 많이 학습하였기 때문에 어떤 데이터를 넣더라도 준수한 성능을 보입니다. 다음은 대표적인 사전 학습 모델입니다.
VGG

- 구조가 간소하여 여전히 많이 사용되고 있는 모델입니다.
- 모든 합성곱 층에서 3 * 3 크기의 필터를 사용합니다.
- 층을 깊게 쌓음으로써 7 7, 11 11 크기 필터 이상의 표현력을 가질 수 있도록 합니다.
- 활성화 함수로 ReLU를 사용하고, 가중치 초기화로 He 초기화를 사용하여 기울기 소실 문제에 대처합니다.
- FCL에 드롭아웃을 적용하여 과적합을 막습니다.
- 옵티마이저는 Adam을 사용합니다.
GoogLeNet

- 기본적인 합성곱 신경망에 가로로 층을 추가한 모습입니다.
- 세로 방향의 깊이 뿐만 아니라 가로 방향으로도 넓은 신경망 층을 구성하여 병렬로 된 각각의 필터가 각자 다른 가중치와 크기를 가지고 있습니다. 덕분에 이미지의 특성을 폭넓게 추출할 수 있습니다.
ResNet

- 층을 거친 데이터의 출력에 층을 거치지 않는 출력을 더하는 모델입니다.
- 역전파 과정에서 미분을 적용하더라도 1 이상의 값을 보존하여 기울기 소실 문제를 어느정도 해결할 수 있습니다.
