
Q. sample의 분류는 hyper plane 을 기준으로 score 값을 계산하는데, 이때의 hyper plane을 구성하는 모델파라미터 w가 학습을 하면서 조정이 된다. 새로운 데이터가 들어오면 정밀한 분류를 위해서 조정이 필요한데, 이때 조정은 어떻게 이루어질까?
1. SVM : Support Vector Machine
-> 최대 margin을 확보하는 것이 목적이다.
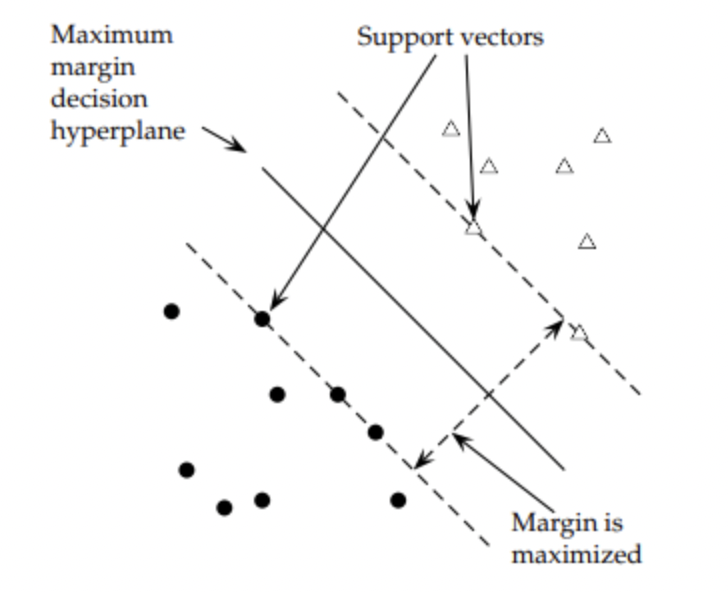
점선과 점선 사이에 서로 가장 마진을 크게 잡으면 중간의 실선이 된다.
(참고로, 점선은 positive/negative sample중에 가장 상대에게 가까운 값 => minimum margin = support vector)
(1) Linear classification 진행
(2) linear classification의 Hyperplane에 대하여 각 클래스(분류된 집단) 별로 가장 가까운 점에 대해 수선의 발을 내린다.
(3) 이 점과 직선사이의 거리를 support vector라고 하고, 두 선을 만드는 것을 support vector machine이라고 한다.
(4) support vector(w *2 = margin, margin과 w는 역수의 관계이다.
(5) 우리의 목적은 w를 최소화하는 것이다.
Support vector간의 마진(사이의 거리)을 최대화하는 것이 최적화 전략이다.
outlier에 대해서 안정적인 성능을 제공할 수 있다는 장점.
2. 어떻게 margin을 계산할까?
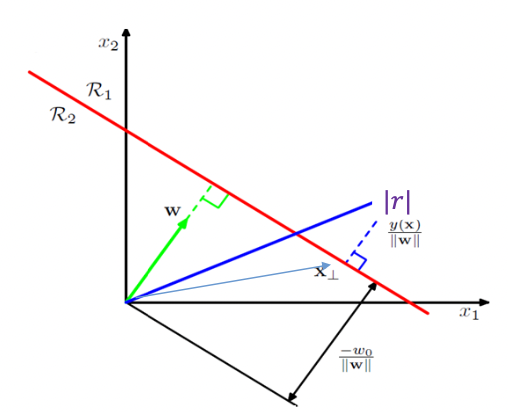
가운데 실선이 h(x)=0.
-> hyper plane으로부터 떨어져있는 support vector간 거리를 최소화하기 위해서는 SVM에서는 다양한 최적화 방식을 이용한다.
3. Hard margin SVM
: linearly separability한 경우에만 가능
sample constraints
Support vector 값들에 의해서 h(x)가 어떻게 결정되는지에 대하여.
h(x) = W^Tx+b인데 이 값이 1보다 크면 positive, -1보다 작으면 negative
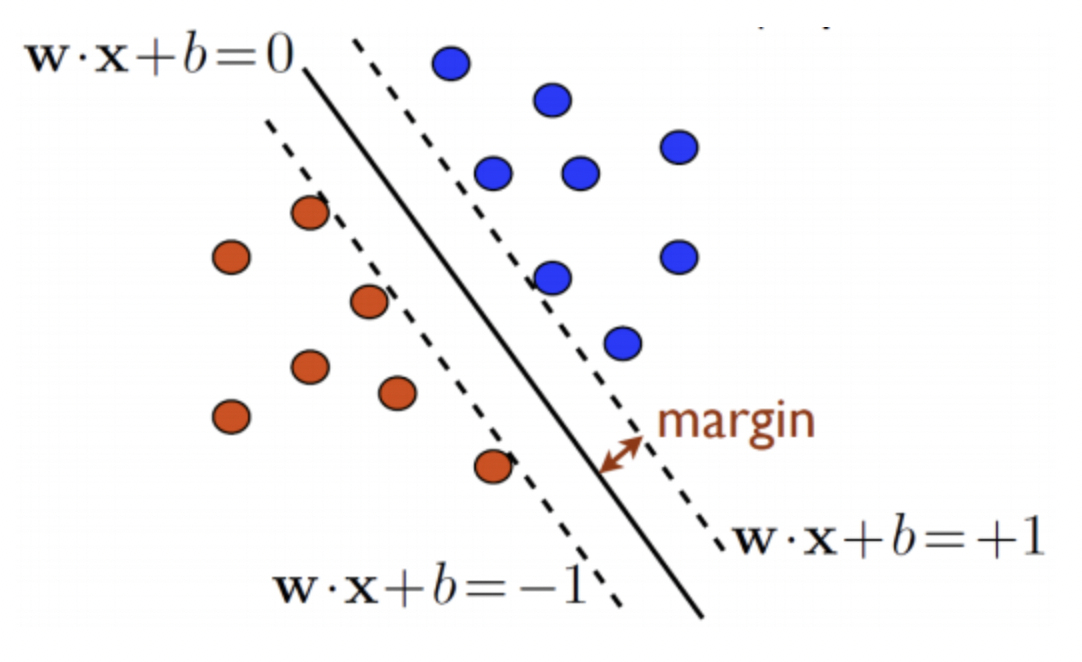
그리고 그 사이 -1~1이 margin이 된다.

-> h(x)로부터의 거리가 1이면 *2해서 2가 된다. (margin은 h(x)위아래로 같은 값을 가지므로)
-> 식으로 표현하면 이렇게 되고, w값을 줄이는 것이 해결할 문제이다. (Svm primal problem)
W norm의 제곱 (||w||^2)을 최소화하자

4. Hard margin SVM의 장단점
(1) 장점 : 분류 문제와 예측 문제 둘 다 사용 가능, 오버피팅이 덜하다, 정확도가 높은 편이다, 사용이 쉽다
(2) 단점 : 선형이 아닌 경우 사용이 힘들다 -> kernel 이용
5. Soft margin SVM
: 에러를 어느정도는 용인을 하는 범위까지 가능
6. Nonlinear transform, kernel trick
(linear하지 않은 경우에 사용 가능한 쪽)
-> 2차원 샘플을 좀 더 고차원 샘플로 매핑하는 함수를 이용한다.
** Kernel함수 : linearly seperable하지 않은 data sample들이 있다고 할 때, 차수를 높여 linearly seperable하게 만드는 과정

7. ANN : Artificial Neural Network
(1) nonlinear classification model
(2) DNN의 기본
x0이 입력됨 -> w0, w1, w2 등이 linear combination됨 -> activation function에 의해 score값을 활용해 sigmoid함수 등을 통해 nonlinear한 형태로 변환 -> classifier
8. 활성화 함수 activation functions
: sigmoid를 쓰거나, ReLU를 쓰거나, leaky ReLU
score값을 활성화 함수를 이용해 nonlinear한 관계로 매핑하는 역할을 수행
입력 신호의 총합을 출력 신호로 변환하는 함수를 활성화함수라고 한다.
Non linear함수들이 계층적으로 쌓여감에 따라 signal spade에서의 복잡한 신호의 패턴을 조금 더 정확하게 분류할 수 있다.
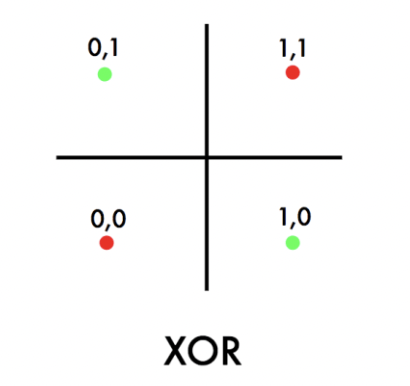
XOR problem : Linear classification으로는 풀 수 없는 문제 (위 그림에서 어떻게 선을 두어도 분류를 할 수 없음)
-> multilayer perceptron을 활용해 해결할 수 있다.
7. Multilayer perceptron (MLP)
: XOR 문제는 선형 모델(linear classification)로 풀 수 없었는데, neural network를 여러 개의 층으로 쌓는 multilayer로 해결할 수 있게 되었다.
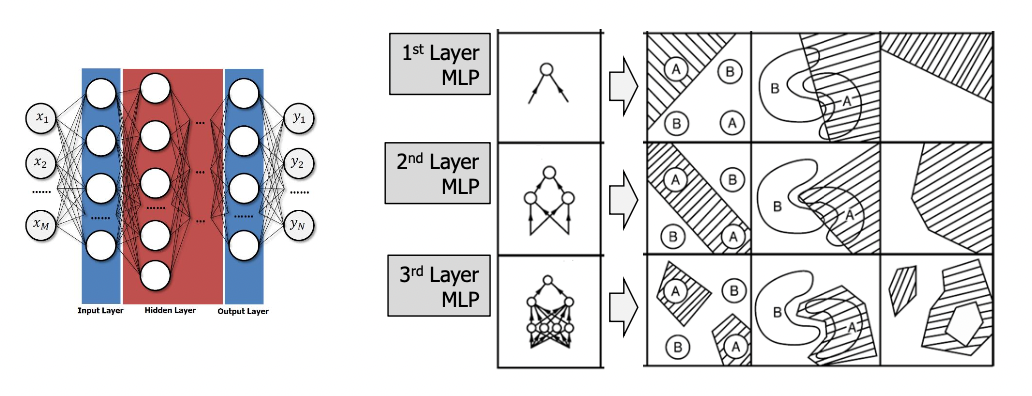
레이어가 많아질수록 더 분류가 명확해지는 것을 확인할 수 있다.
8. Neural network가 어떻게 XOR 문제를 풀었는가?
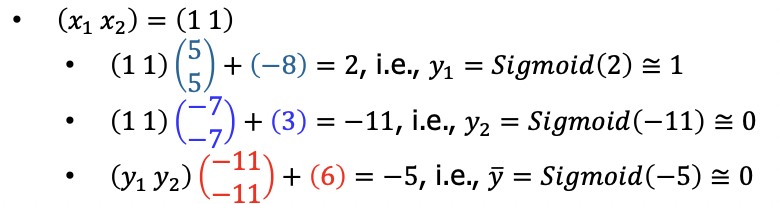
-> 입력값과 파라미터의 연산 -> 활성화함수 -> 1 또는 0의 signal로 출력
9. ANN의 한계
ANN -> computer vision 분야나 image recognition 에 많이 사용된다.
그러나 계층의 개수를 계속 늘려간다고 할지라도 어느순간 성능이 낮아지는 문제가 생김 -> gradient vanishing problem 때문!
Gradient vanishing problem : 모델이 학습하는 과정에서 학습파라미터를 chain rule을 통해 학습하게 되는데, 이때 계층이 깊어질수록 gradient 값이 작아지고, 학습이 잘 이루어지지 않는다는 문제가 생김.
: 그래서 back propagation이 나오게 되었다. -> deep learning model, convolution neural network
* 아무리 딥러닝 모델이 발전하더라도 지도학습의 기본적인 매커니즘이 기반이 되기 때문에 잘 알아둘 것!
* 퀴즈
- Support vector machine은 nonlinear classification에 적용할 수 있다.
-> true. Nonlinear 한 다차원 형태를 linearly seperate하게 만들 수 있기 때문임. - Neural network은 nonlinear한 classifier이다.
-> false. Activation function에 의해 gradient가 사라지는 구간이 있다.
