Dropout Layer
Introduction
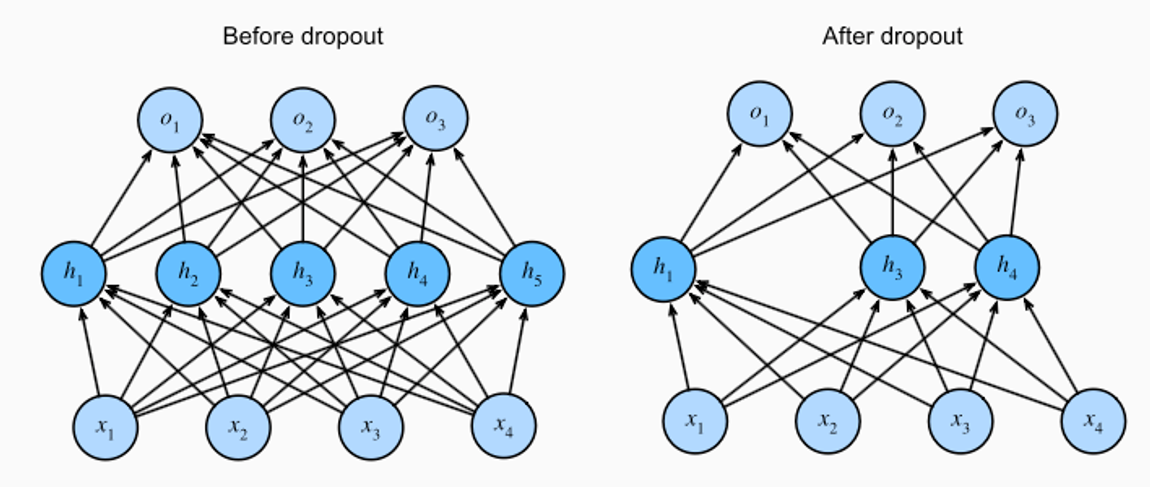
A Dropout Layer is a regularization technique used in neural networks to prevent overfitting. It was introduced by Srivastava et al. in their 2014 paper titled "Dropout: A Simple Way to Prevent Neural Networks from Overfitting". The core idea behind dropout is to randomly "drop" or ignore a subset of neurons during the training phase, which makes the model less sensitive to the specific weights of neurons. This enhances the model's ability to generalize to new data.
Background and Theory
Concept
Dropout operates on the principle that dependency on specific weights within a neural network can lead to overfitting. By randomly removing a fraction of the neurons in a layer during each training iteration, dropout simulates training a large number of thin networks with different architectures. At test time, dropout uses the entire network, but with neuron outputs scaled down appropriately to balance the fact that more neurons are active than during training.
Mathematical Formulation
Consider a neural network layer with an input vector and an output vector . Let be the probability of keeping a unit (neuron) active during dropout, hence is the probability of dropping a unit. Mathematically, the operation of a dropout layer can be represented as follows:
-
Mask Generation: Generate a random binary mask where each entry is sampled from a Bernoulli distribution with parameter .
-
Element-wise Multiplication: The output is computed by element-wise multiplying the input by the mask :
Here, denotes the element-wise multiplication.
-
Scaling at Test Time: During the testing phase, the outputs are scaled by the probability to compensate for the reduced activity during training:
Procedural Steps
Implementation in Training
- Forward Pass: During the forward pass, for each neuron, decide whether it will be dropped out or not based on the probability .
- Backward Pass: During backpropagation, only the gradients of the non-dropped neurons are updated. Neurons that were dropped do not contribute to the gradient.
Implementation in Testing
During testing and real-world application, all neurons are active, but their outputs are scaled by as mentioned.
Implementation
Parameters
dropout_rate:float, default = 0.5
The fraction of input units to drop during training
Applications
Dropout is extensively used in training deep neural networks for tasks such as:
- Image recognition and classification
- Speech recognition
- Natural language processing
Strengths and Limitations
Strengths
- Prevents Overfitting: By randomly dropping neurons, the network becomes less sensitive to specific weights.
- Enhances Generalization: It encourages the network to develop more robust features that are useful in conjunction with many different random subsets of the other neurons.
Limitations
- Increased Training Time: As the network learns with fewer neurons during training, more epochs may be required to converge.
- Not Suitable for All Networks: In networks that are not prone to overfitting or are shallow, dropout might hinder performance rather than helping.
Advanced Topics
Variations of Dropout
- Spatial Dropout: A variation designed for convolutional neural networks that drops entire feature maps instead of individual units.
- DropConnect: A generalization of dropout where individual weights, rather than entire units, are randomly dropped.
References
- Srivastava, Nitish, et al. "Dropout: A Simple Way to Prevent Neural Networks from Overfitting." Journal of Machine Learning Research 15.1 (2014): 1929-1958.
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. "Deep Learning." MIT Press, 2016. (Chapter on regularization for deep learning, including dropout).
