Deep Learning
1.[Activation] Rectified Linear Unit (ReLU)
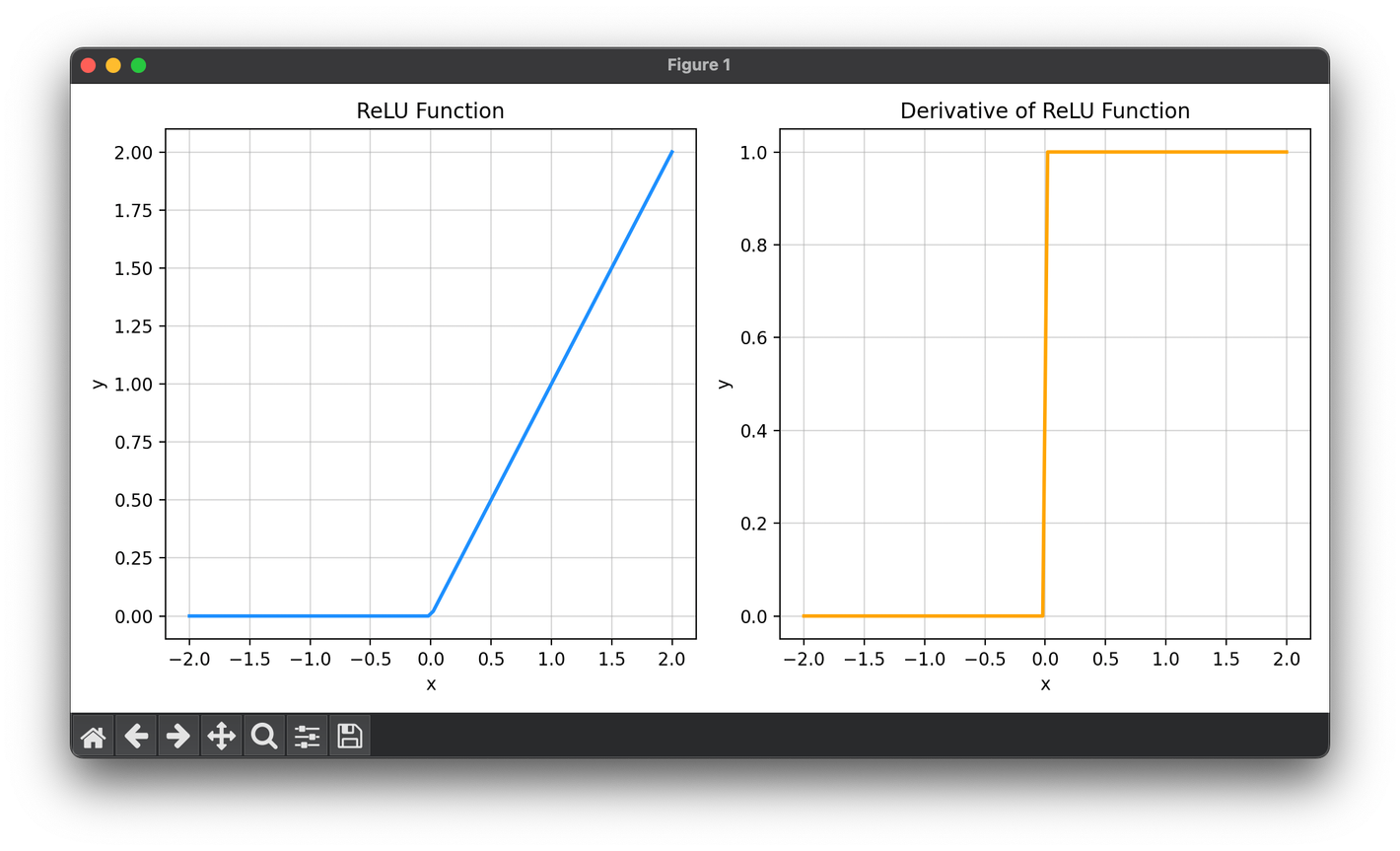
The ReLU function is a fundamental activation function used in the field of machine learning, particularly within neural networks.
2.[Activation] Leaky ReLU
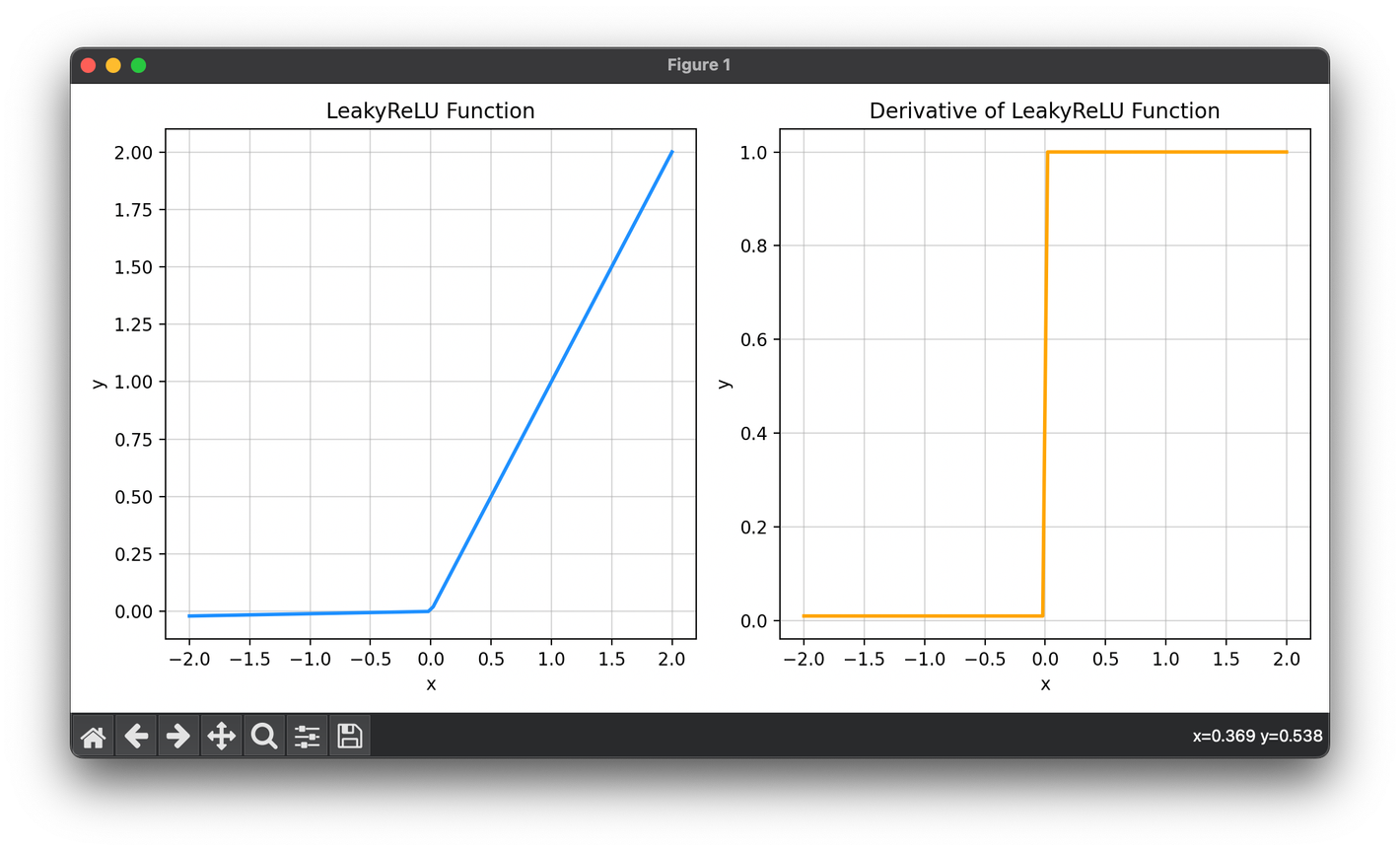
Leaky ReLU is an activation function commonly used in deep learning models, particularly in neural networks. It represents improved version of ReLU.
3.[Activation] Exponential Linear Unit (ELU)
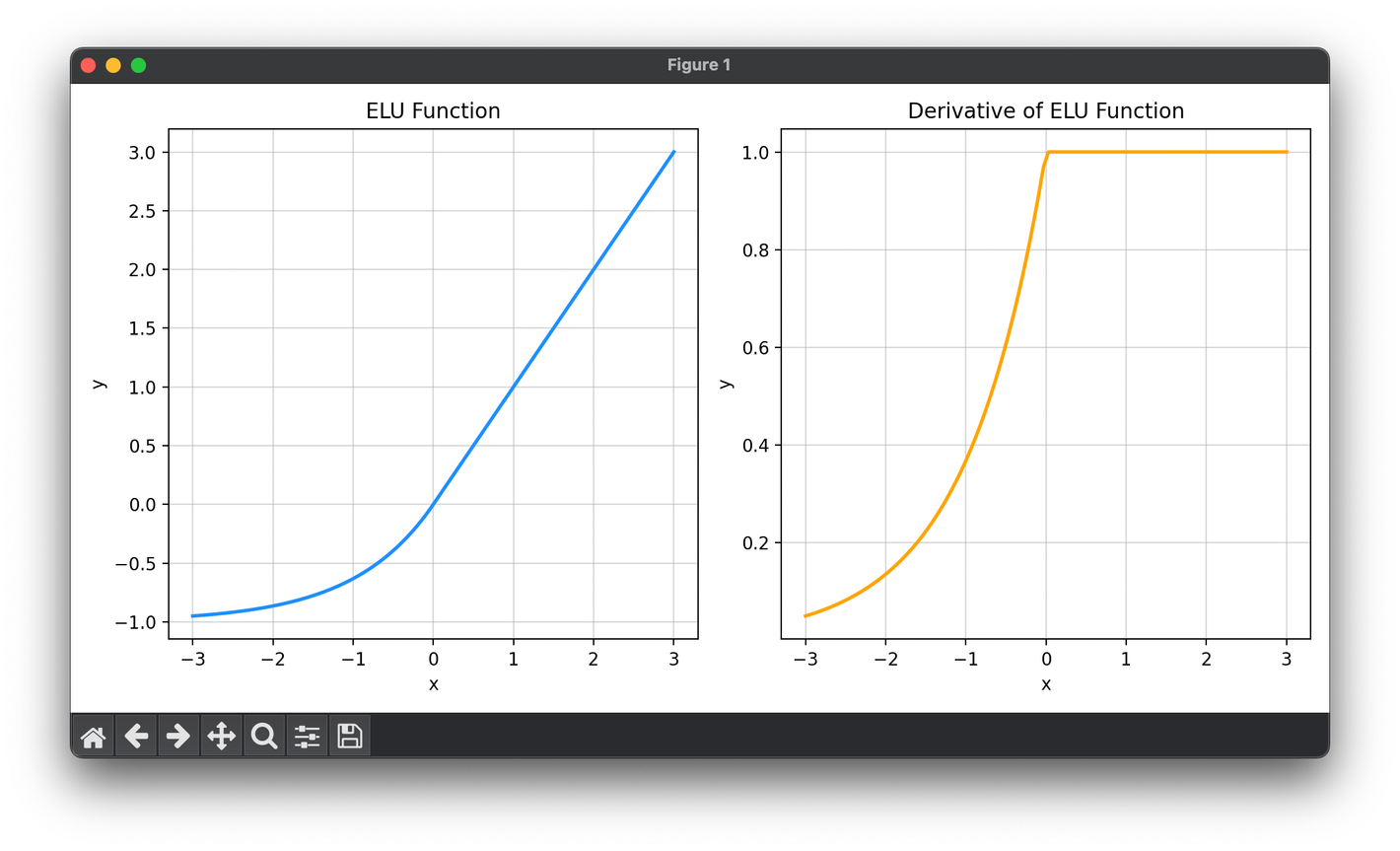
The ELU is a nonlinear activation function used in neural networks, introduced as a means to enhance model learning and convergence speed.
4.[Activation] Hyperbolic Tangent (tanh)
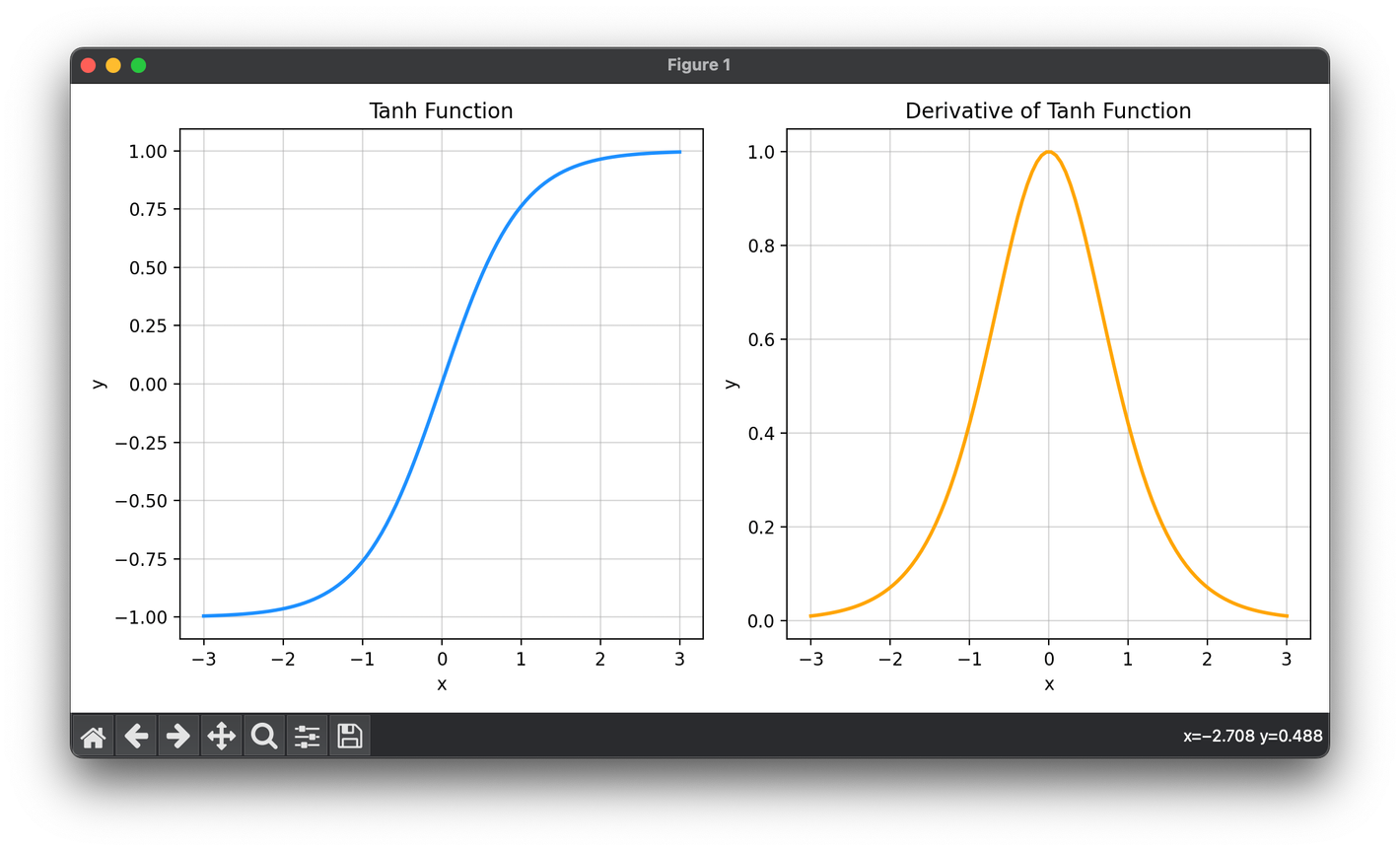
The hyperbolic tangent function, commonly referred to as tanh, is a widely used activation function in neural networks.
5.[Activation] Sigmoid Function
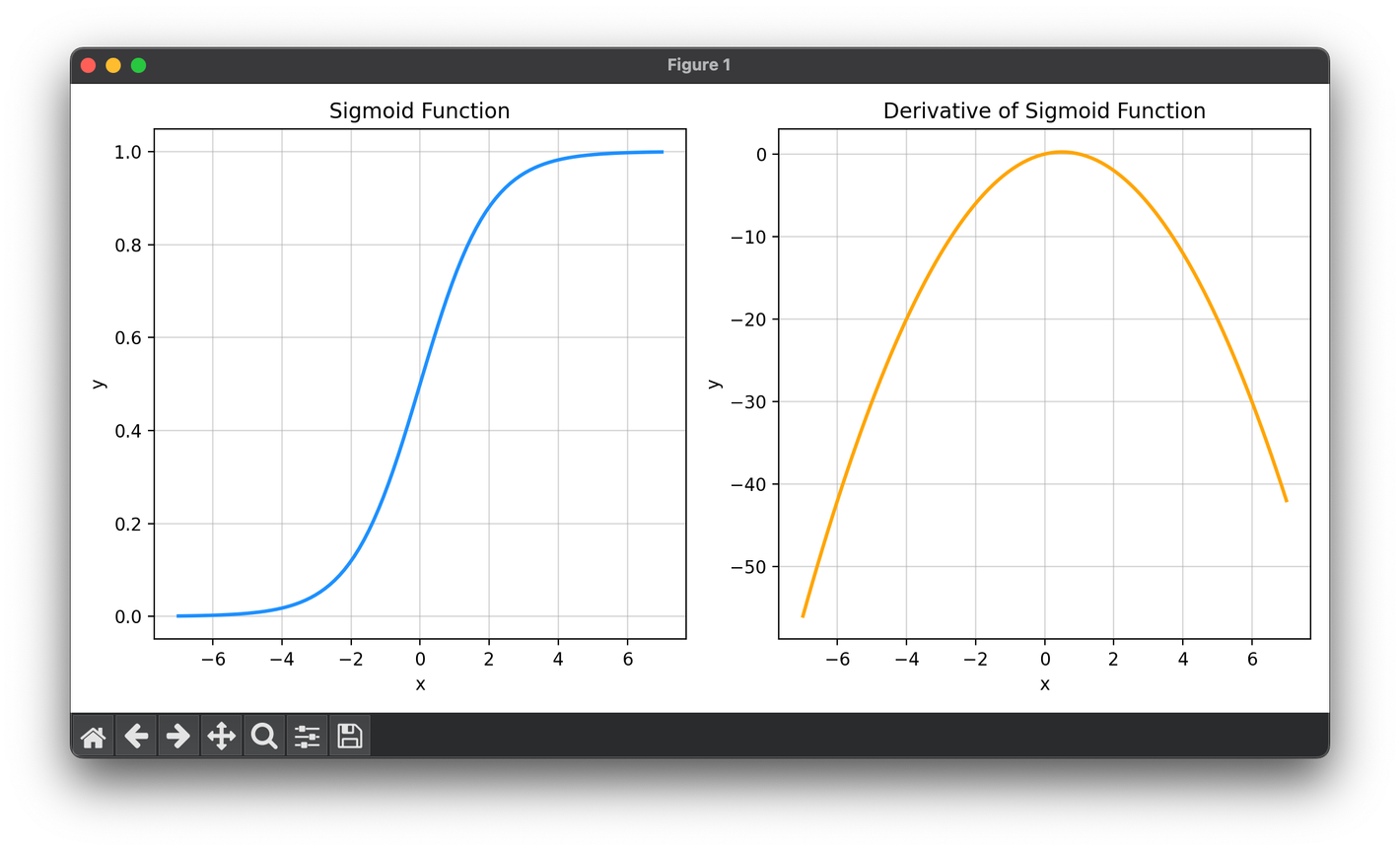
The sigmoid activation function, also known as the logistic function, is a significant activation function in the field of neural network.
6.[Single] Perceptron Classification
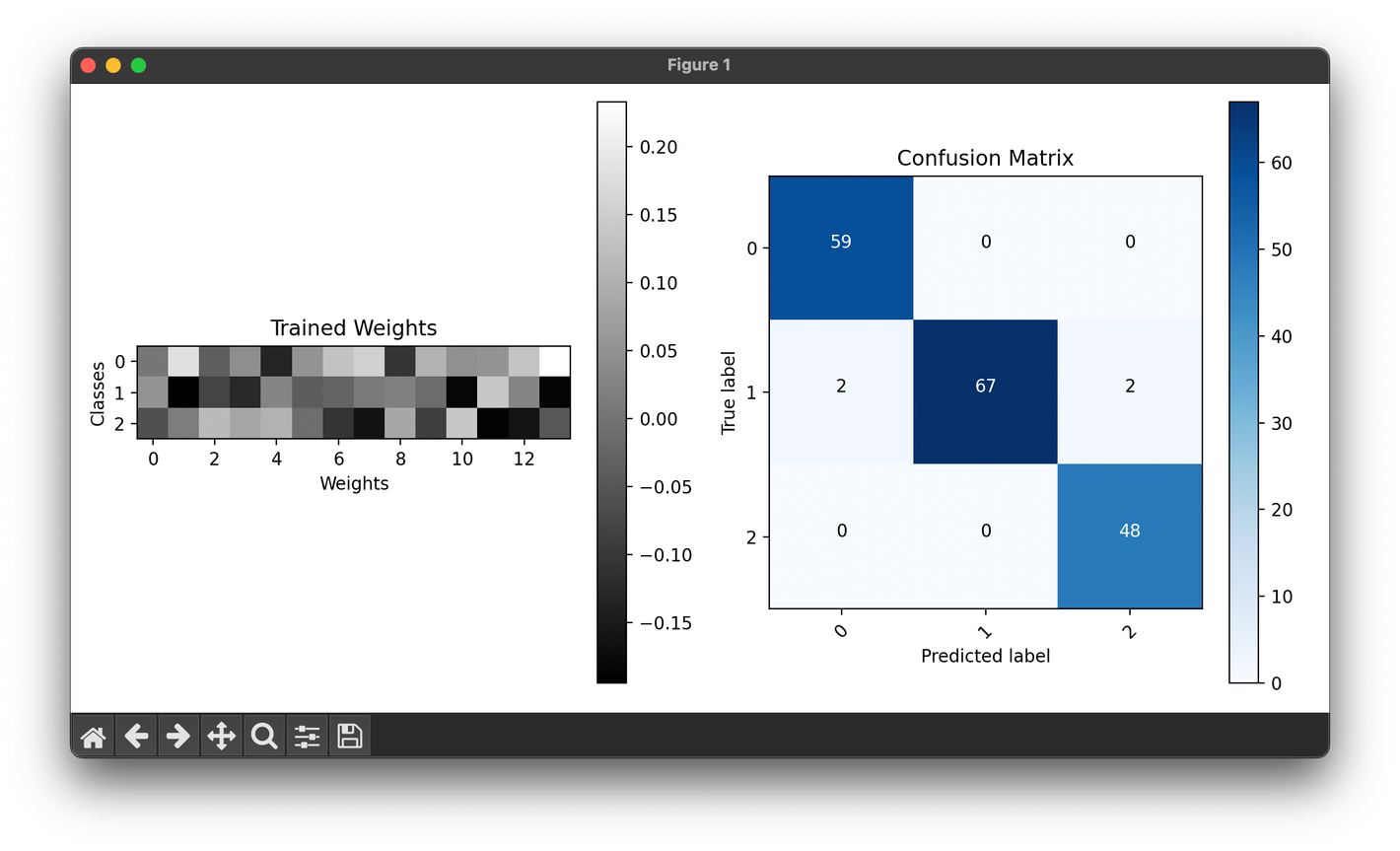
The perceptron is a type of artificial neuron or simplest form of a neural network. It is the foundational building block of more complex neural net.
7.[Single] Perceptron Regression
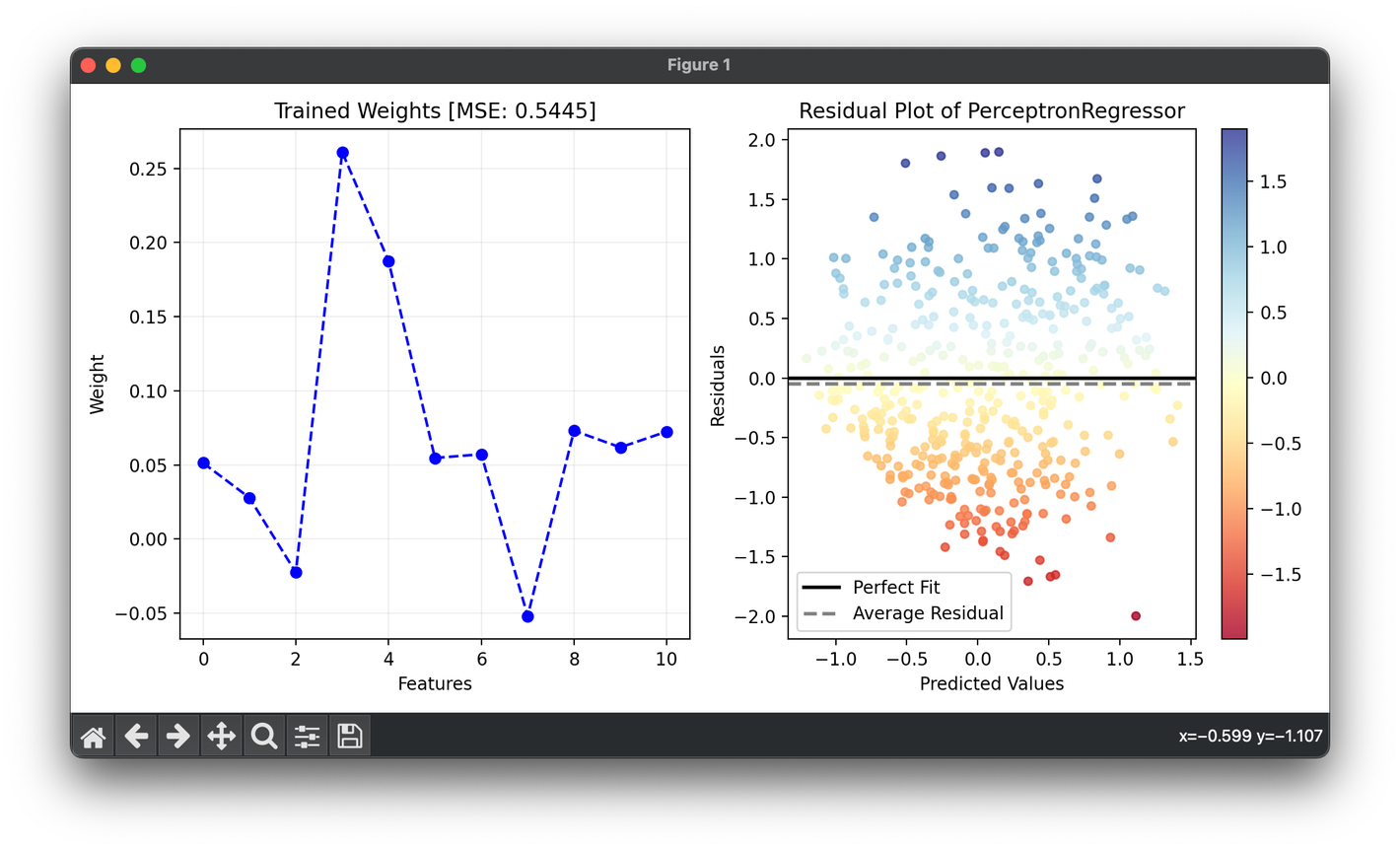
Perceptron regression extends the concept of the perceptron from classification to regression tasks.
8.[Optimizer] Stochastic Gradient Descent (SGD)
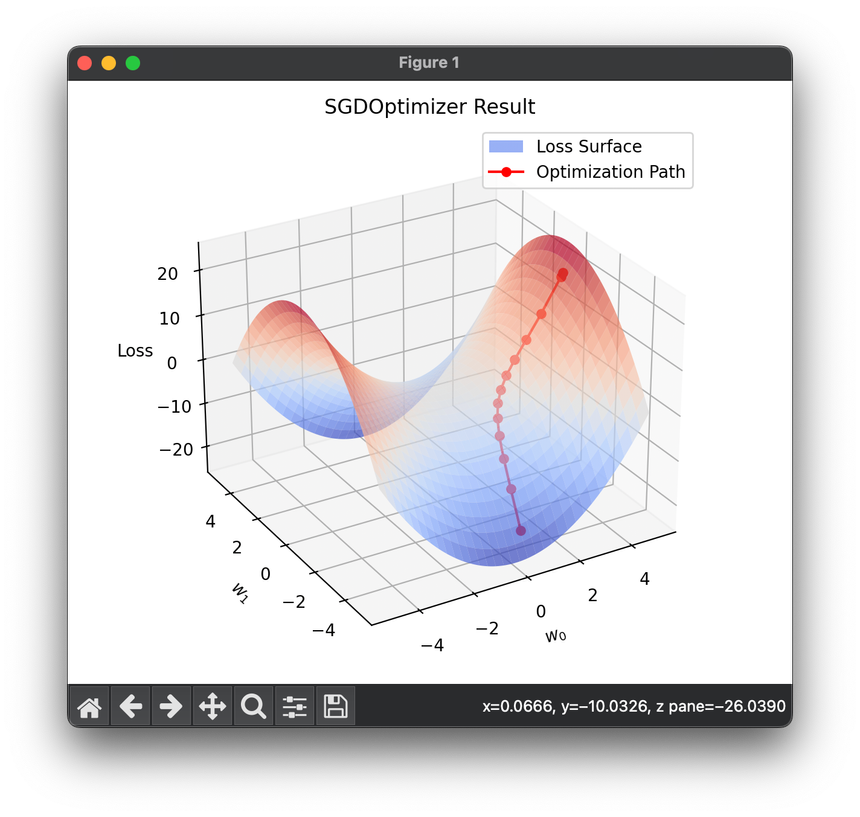
Stochastic Gradient Descent (SGD) is a fundamental optimization technique used widely in machine learning and deep learning for minimizing the loss.
9.[Optimizer] Momentum Optimization
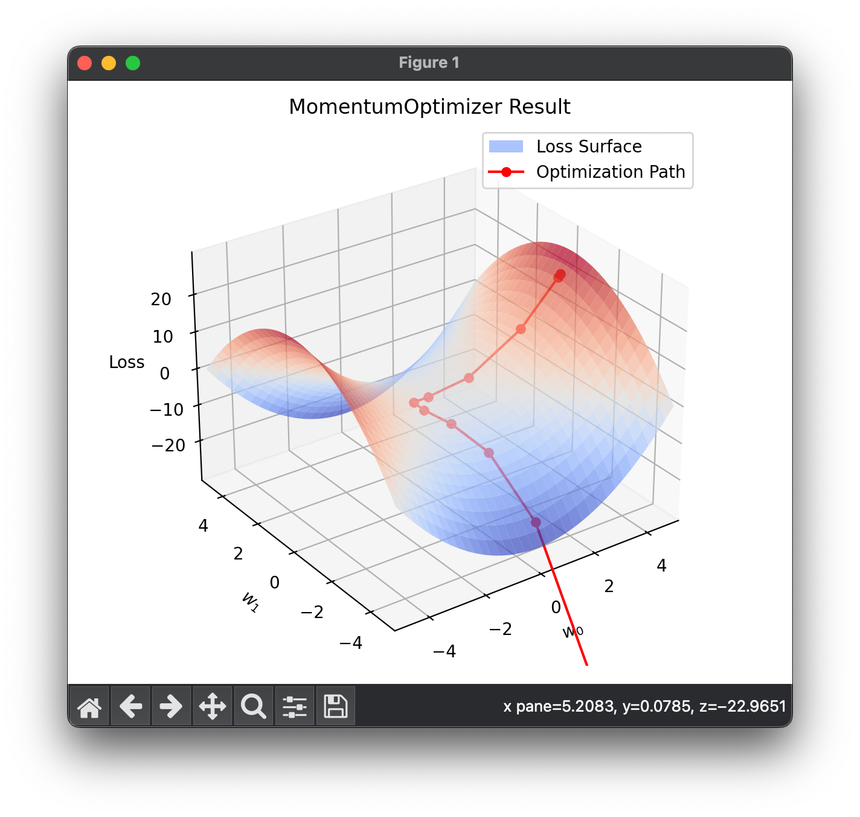
The Momentum Optimizer is an advanced variant of the classical SGD algorithm, designed to accelerate the convergence of gradient-based optimization.
10.[Optimizer] Root Mean Square Propagation (RMSProp)
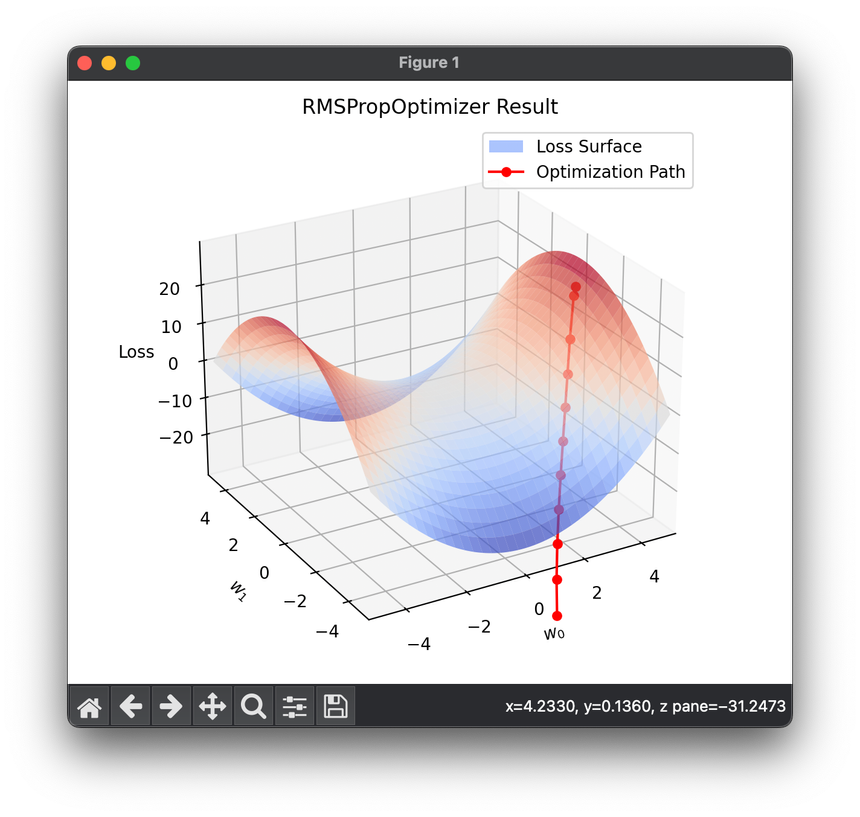
RMSProp is an adaptive learning rate optimization algorithm designed to address some of the drawbacks of traditional SGD methods.
11.[Optimizer] Adam Optimization
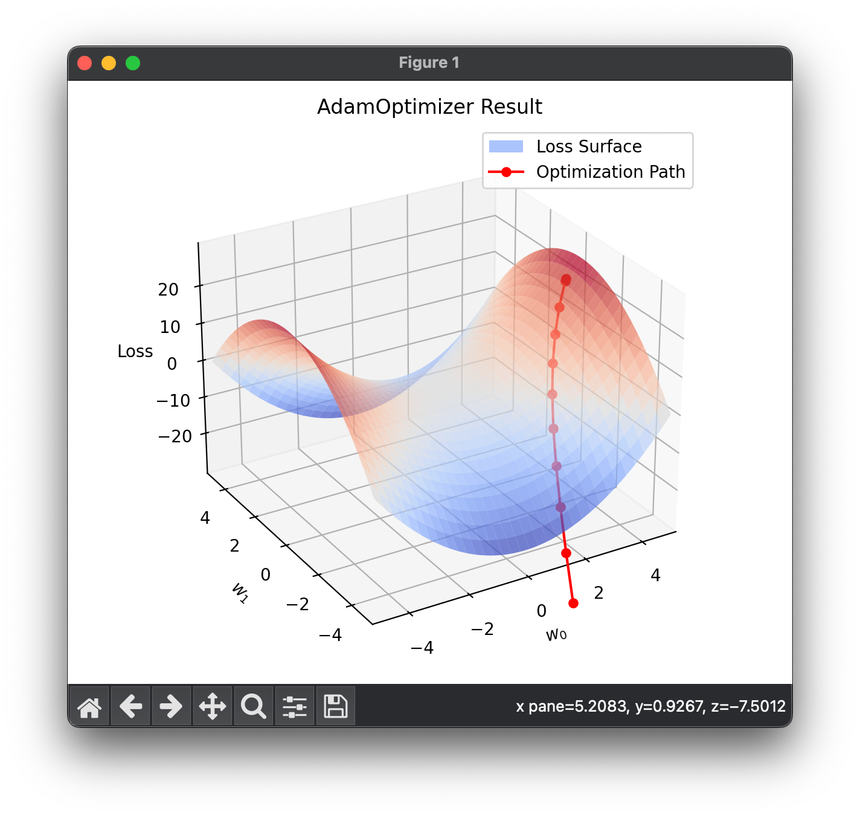
Adam is a popular optimization algorithm widely used in the training of deep neural networks. Introduced by Kingma and Ba in their 2014 paper.
12.[Optimizer] Adaptive Gradient (AdaGrad)
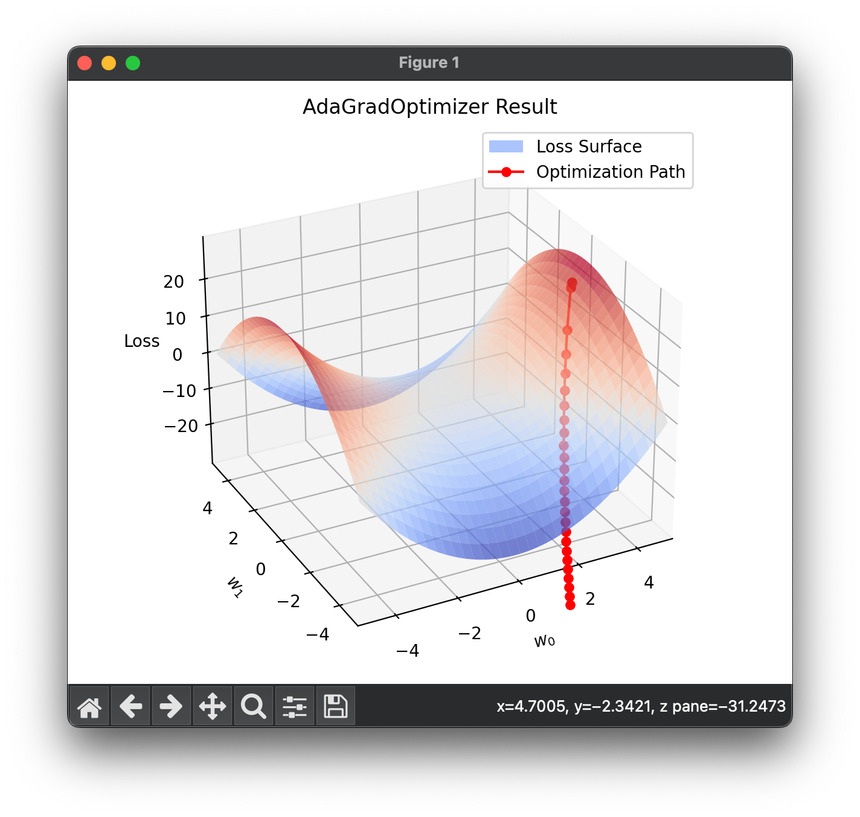
AdaGrad is a gradient-based optimization algorithm that adjusts the learning rate to the parameters, performing smaller updates.
13.[Optimizer] Adaptive Delta (AdaDelta)
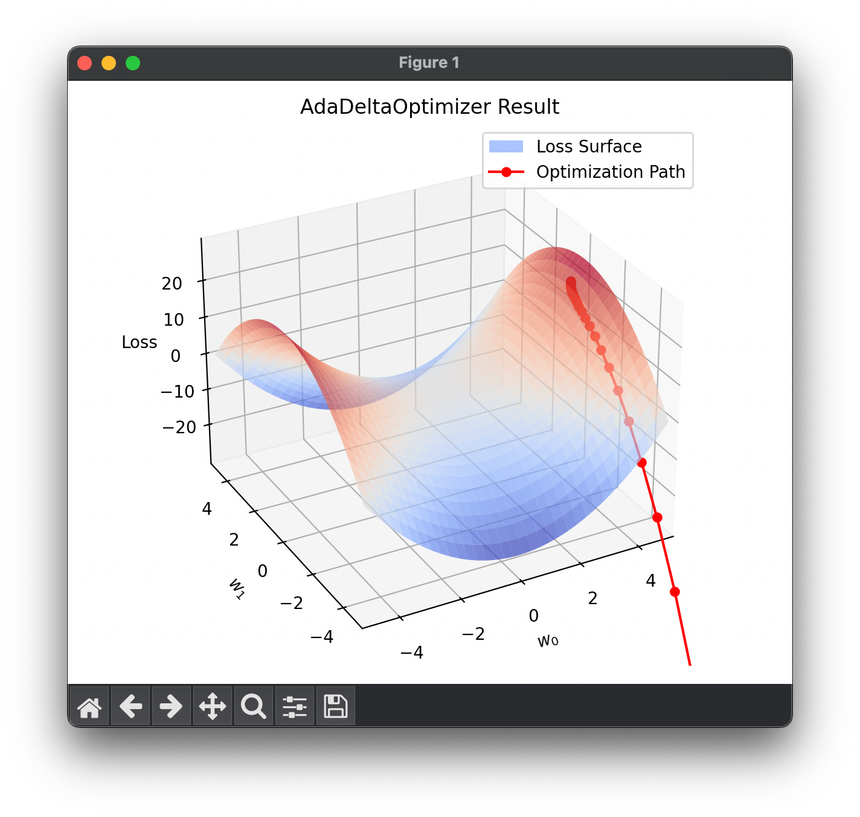
AdaDelta is an optimization algorithm designed to address the rapidly diminishing learning rates encountered in AdaGrad.
14.[Optimizer] AdaMax Optimization
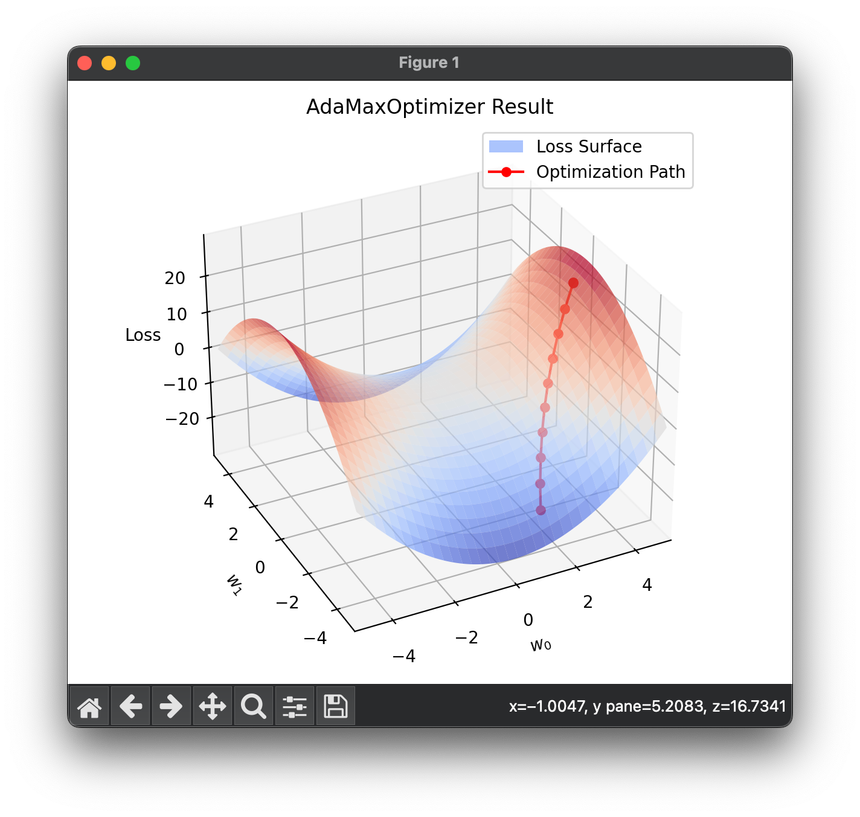
Adamax is a variant of the Adam optimization algorithm, which is itself an extension of the stochastic gradient descent method incorporating momentum
15.[Optimizer] AdamW Optimization
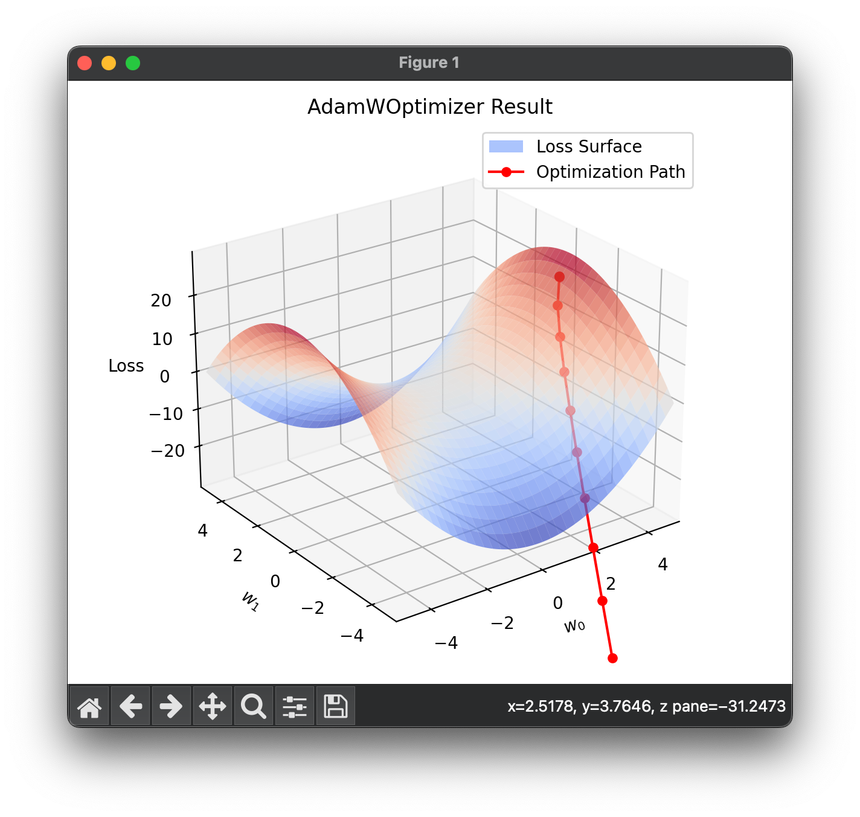
AdamW is an extension of the Adam optimization algorithm, specifically designed to better handle weight decay in the training of deep learning models.
16.[Optimizer] NAdam Optimization
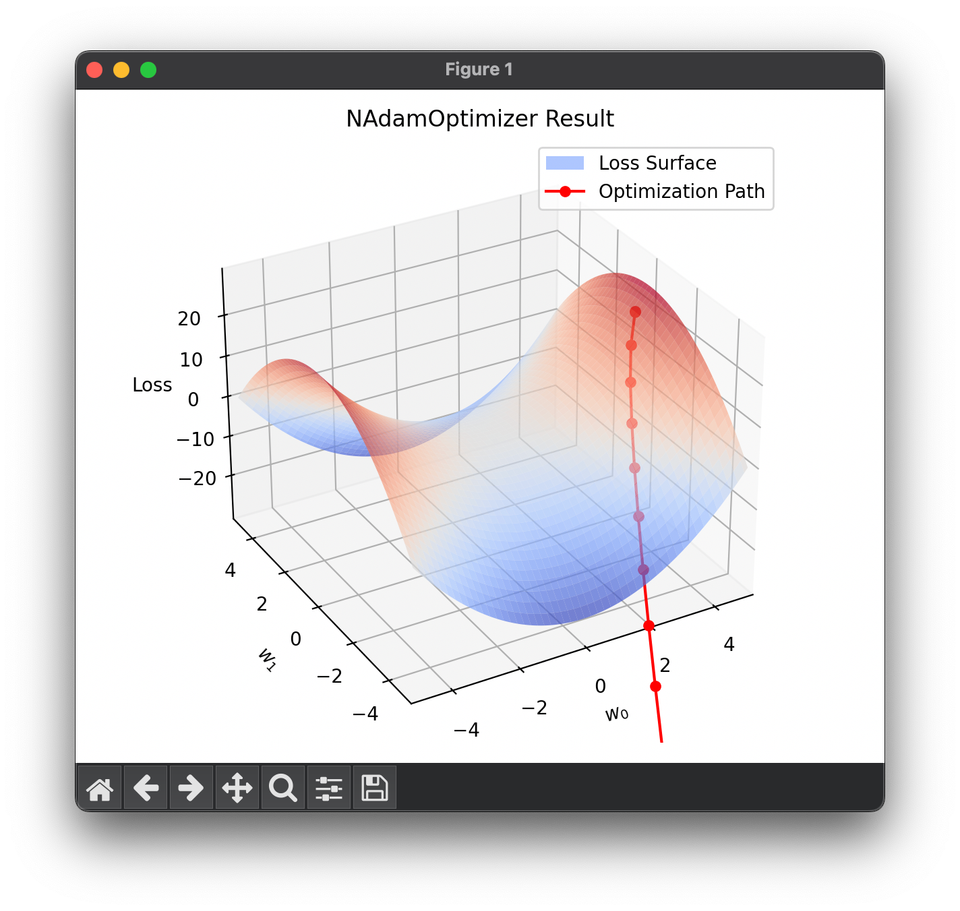
NAdam, or Nesterov-accelerated Adaptive Moment Estimation, is an optimization algorithm that combines the techniques of Adam and Nesterov momentum.
17.[Init] Kaiming Initialization

Kaiming Initialization, also known as He Initialization, is a technique used to initialize the weights of deep neural networks, particularly with ReLU
18.[Init] Xavier Initialization
Xavier Initialization, also known as Glorot Initialization, is a strategy for weight initialization in neural networks.
19.[Layer] Convolution
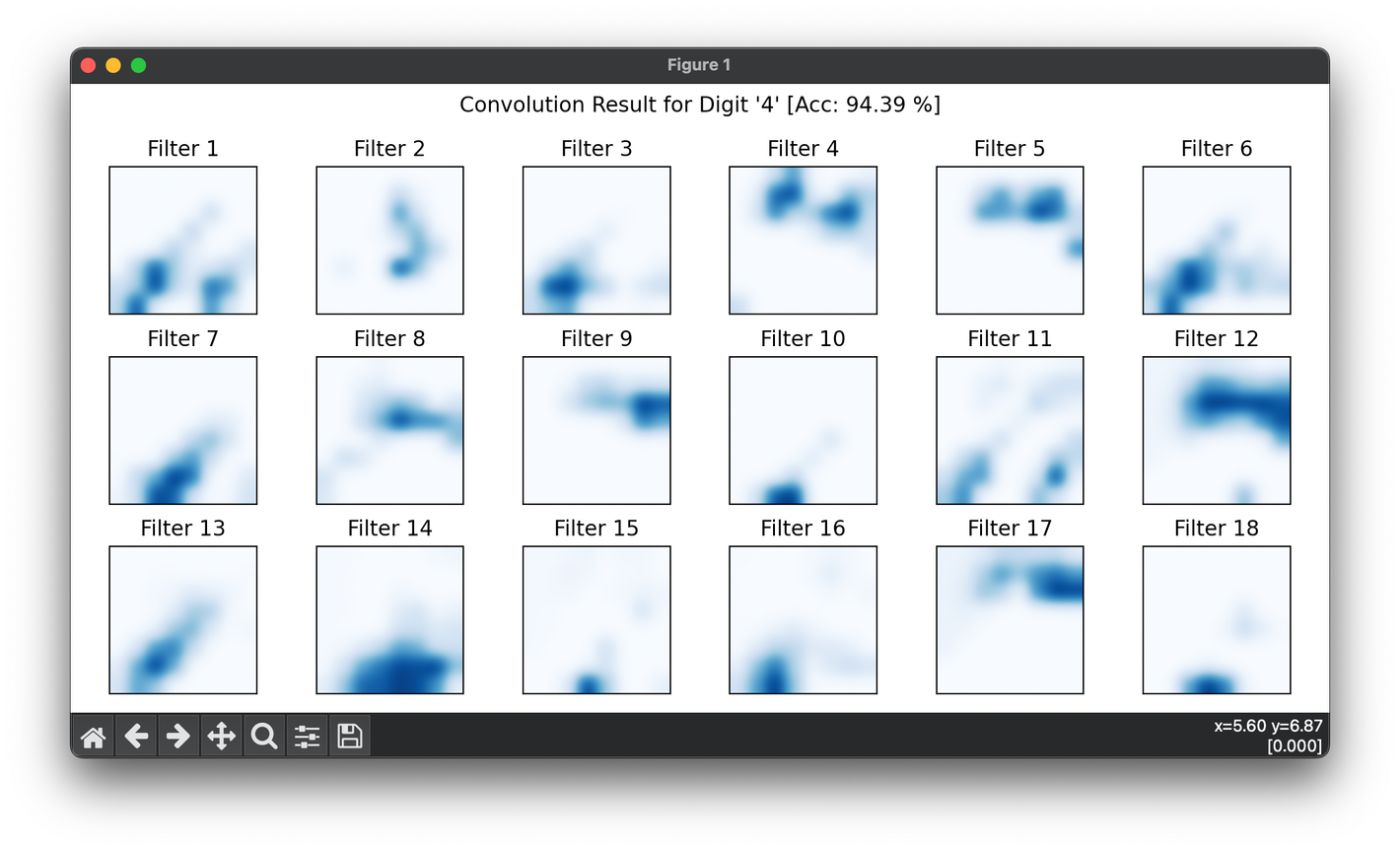
The convolution operation is a cornerstone in many fields such as signal processing, image processing, and machine learning.
20.[Layer] Pooling
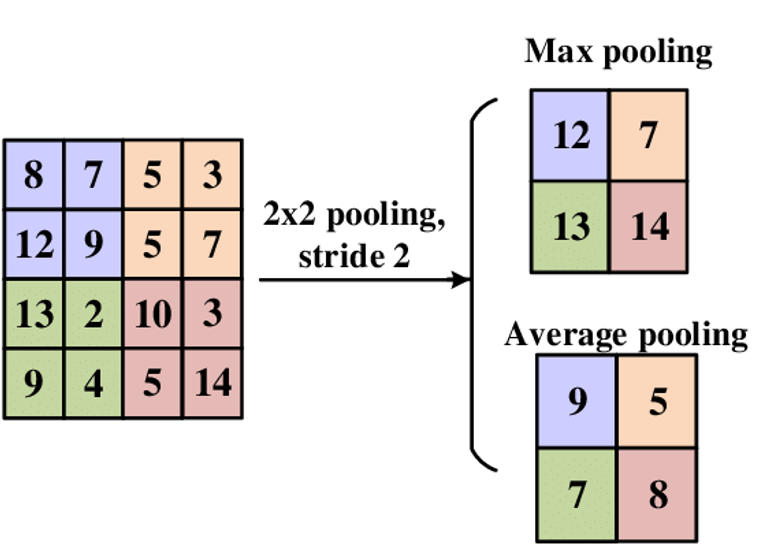
A pooling layer is a common component in convolutional neural networks (CNNs) that reduces the spatial dimensions of the input.
21.[Layer] Dense
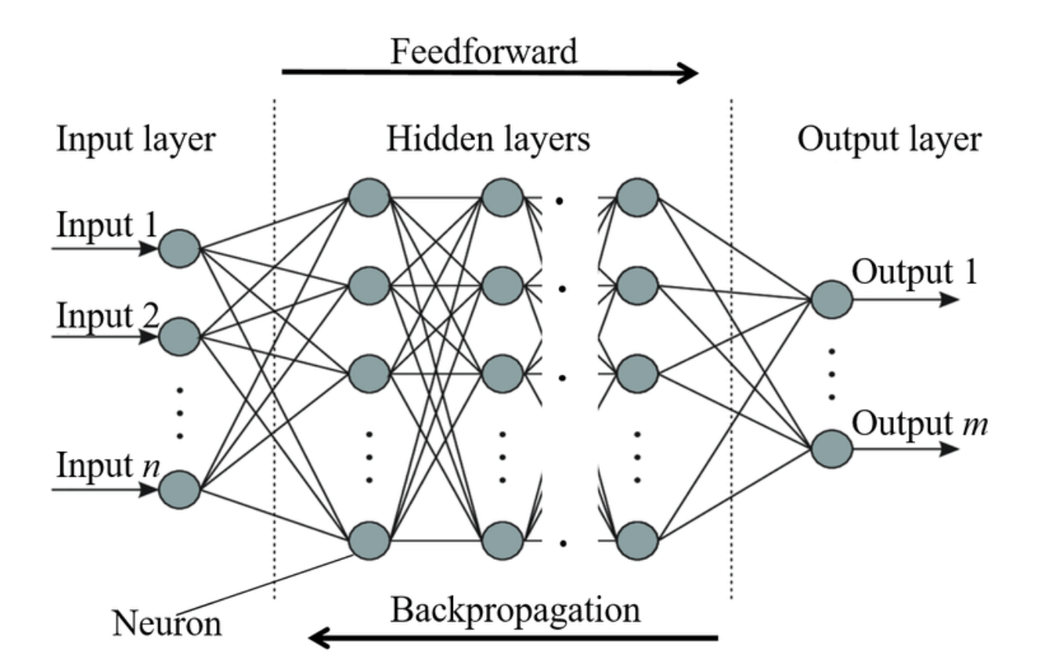
The dense layer, or FC layer, is an essential building block in many neural network architectures used for a broad range of machine learning.
22.[Layer] Dropout
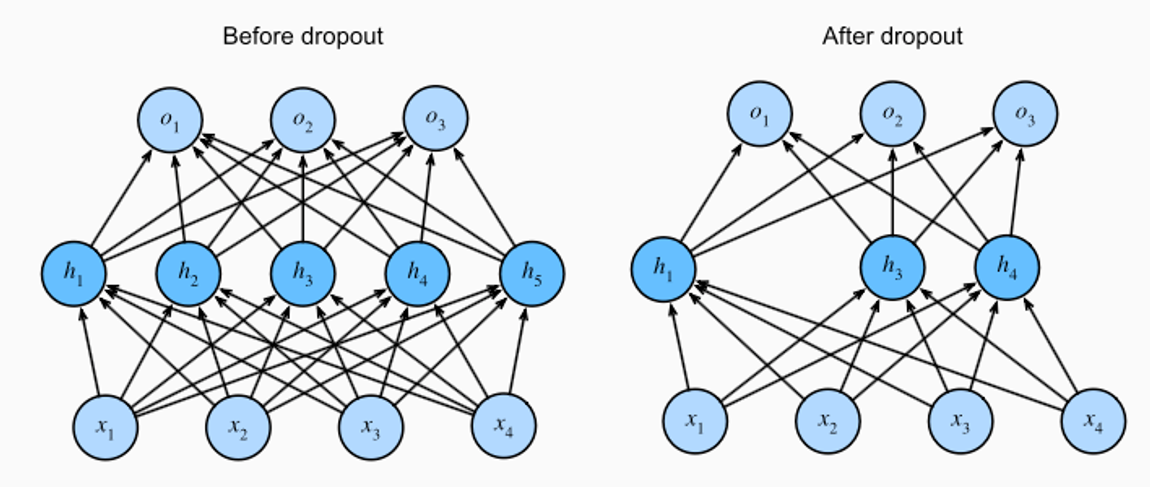
A Dropout Layer is a regularization technique used in neural networks to prevent overfitting.
23.[Layer] Flatten
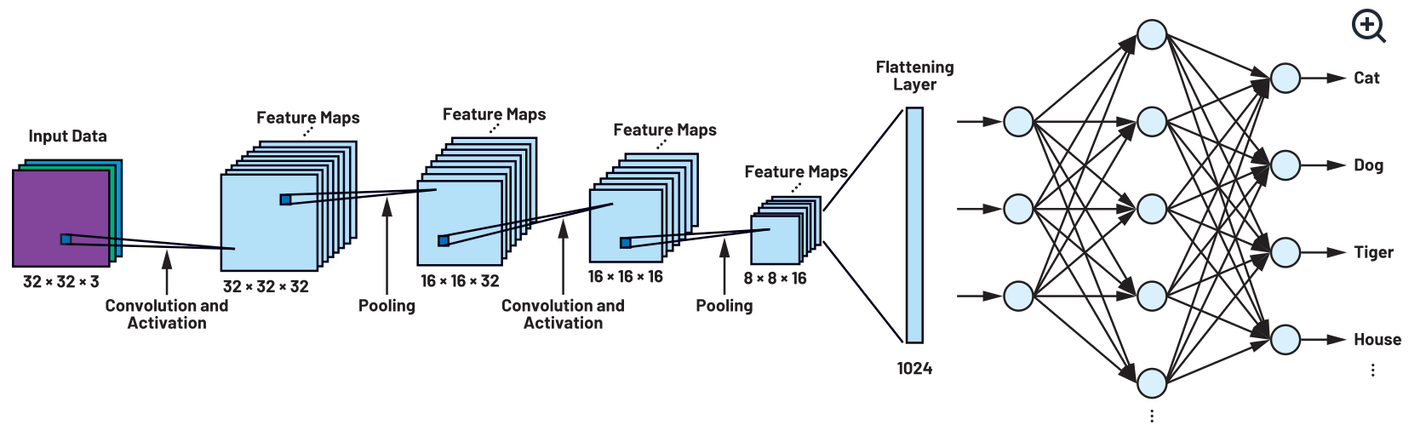
The Flatten layer is a crucial component in the architecture of many deep learning models, particularly those dealing with image and video processing.
24.[Activation] Softmax
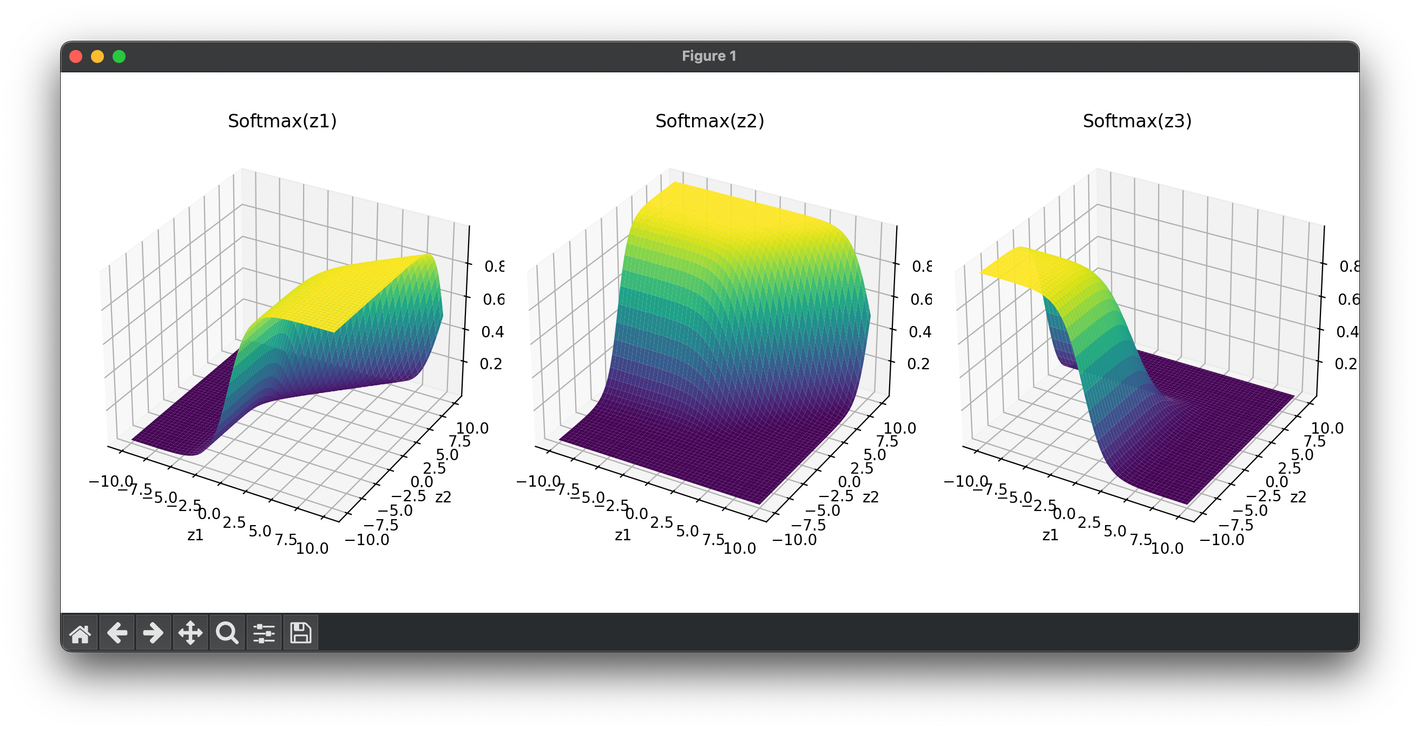
The softmax activation function is a crucial component in the field of machine learning, particularly in the context of multi classification problems.
25.[Activation] Scaled Exponential Linear Unit (SELU)
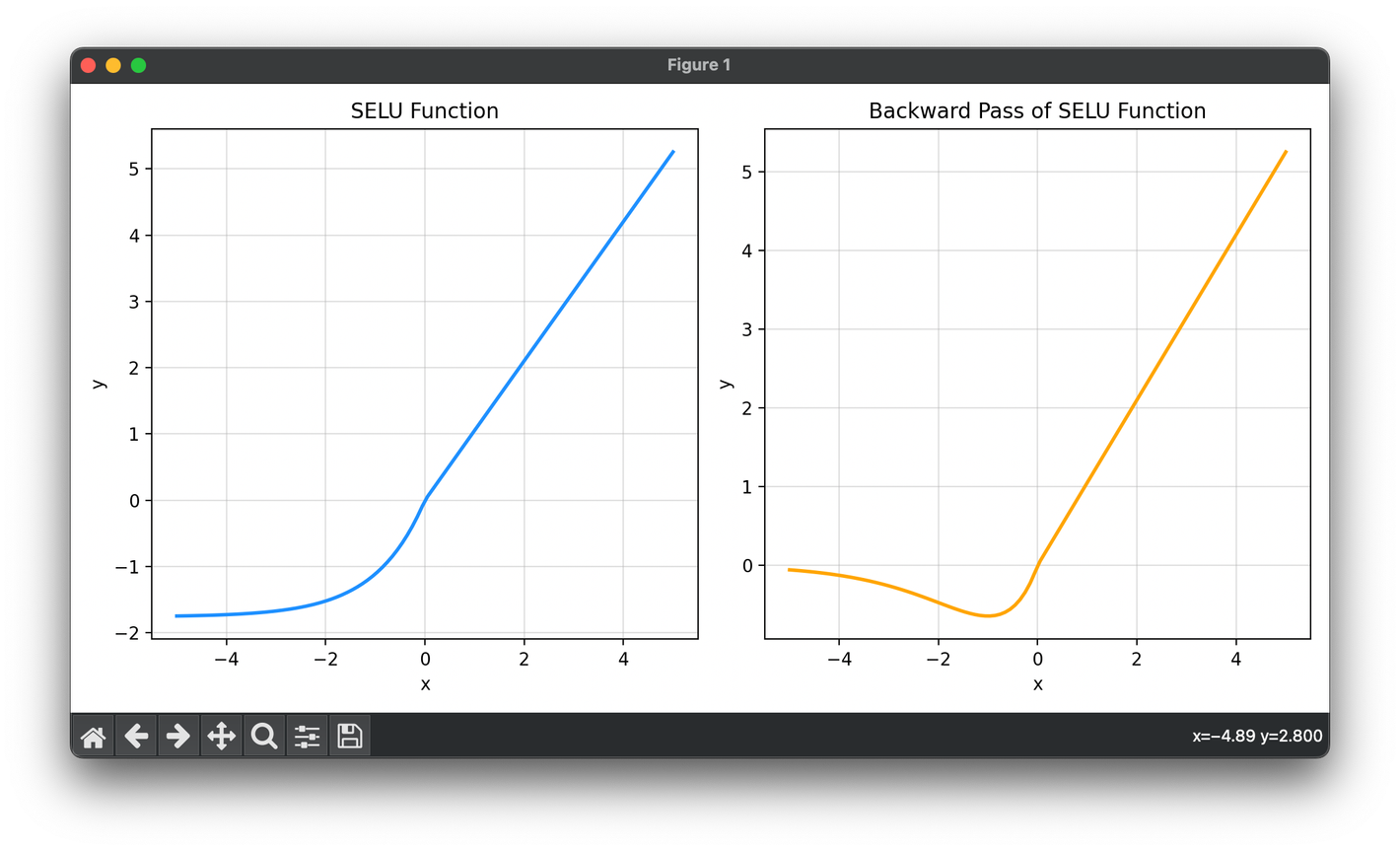
The Scaled Exponential Linear Unit (SELU) is an activation function used in neural networks that automatically induces self-normalizing properties .
26.[Activation] Softplus
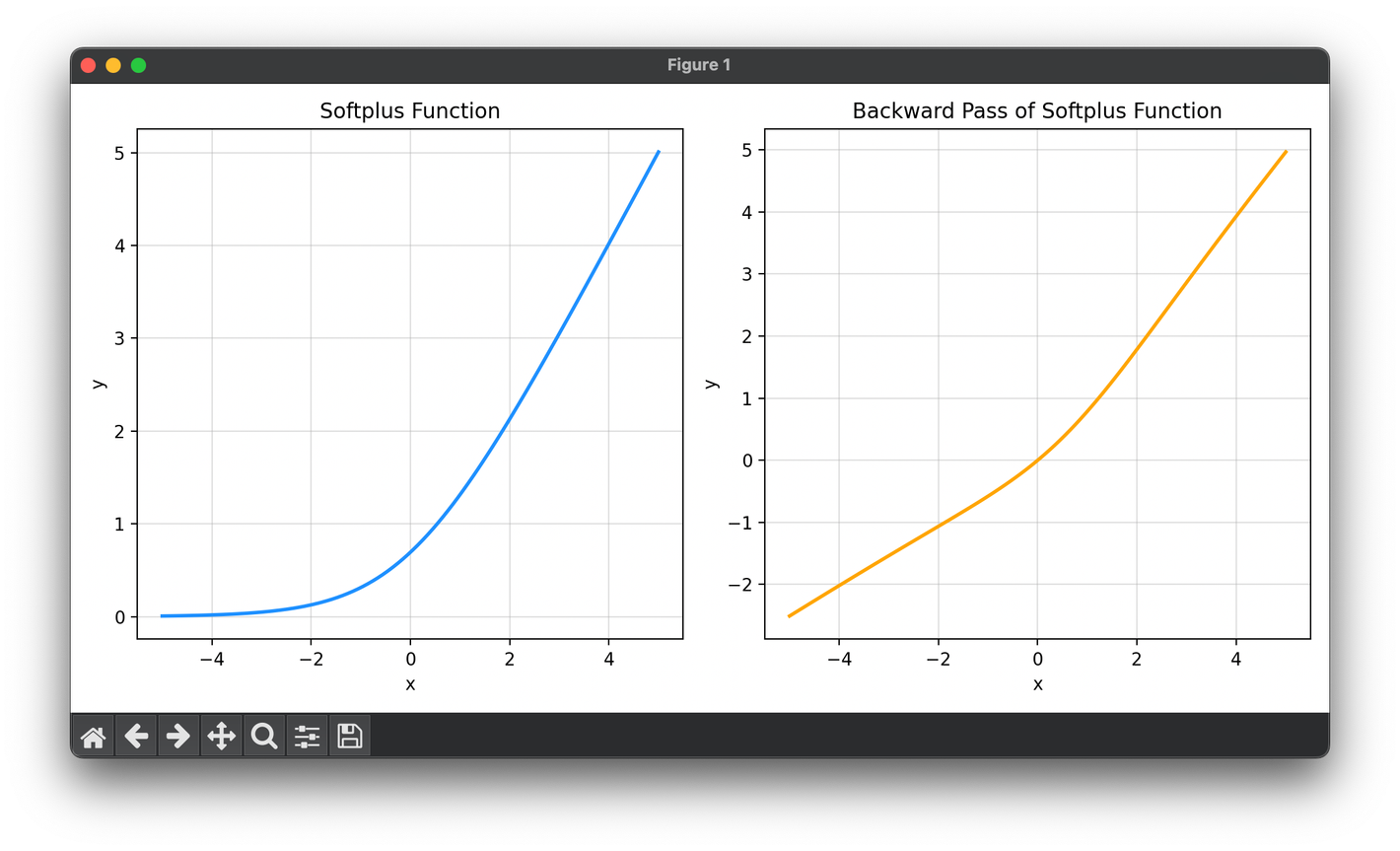
The Softplus activation function is a smooth, nonlinear function used in neural networks as an alternative to the commonly used ReLU.
27.[Activation] Swish
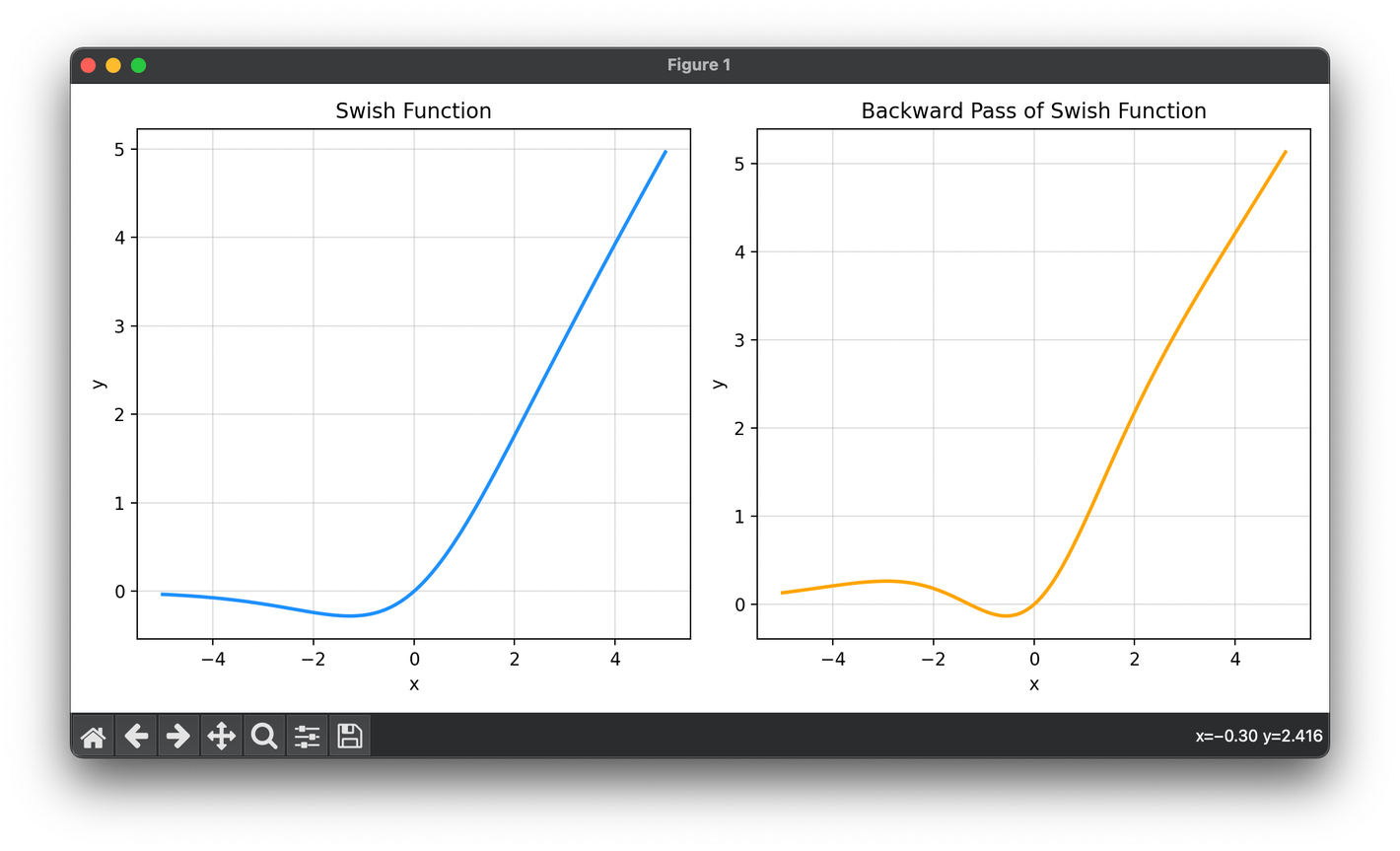
The Swish activation function is a relatively recent addition to the repertoire of activation functions used in deep learning.
28.[Loss] Cross-Entropy Loss
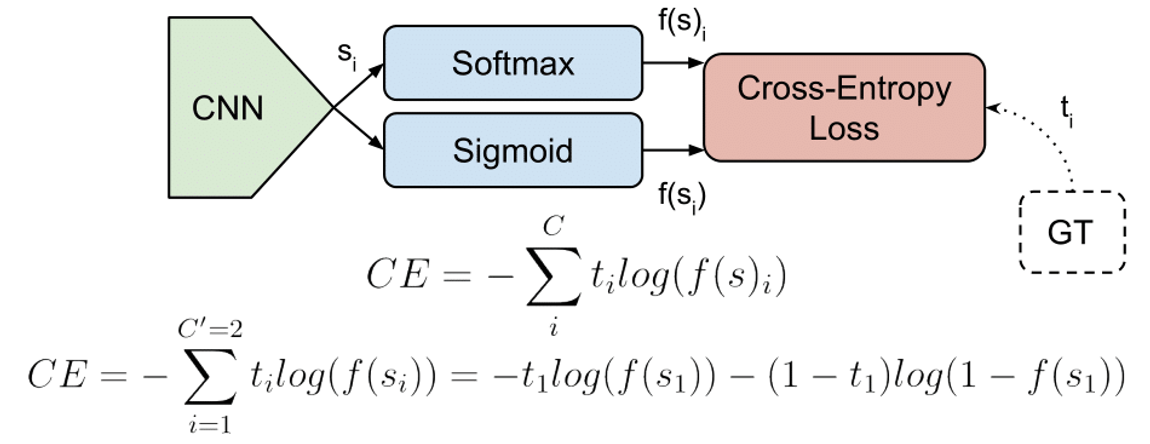
Cross-entropy loss, also known as log loss, measures the performance of a classification model whose output is a probability value between 0 and 1.
29.[Loss] Binary Cross-Entropy Loss
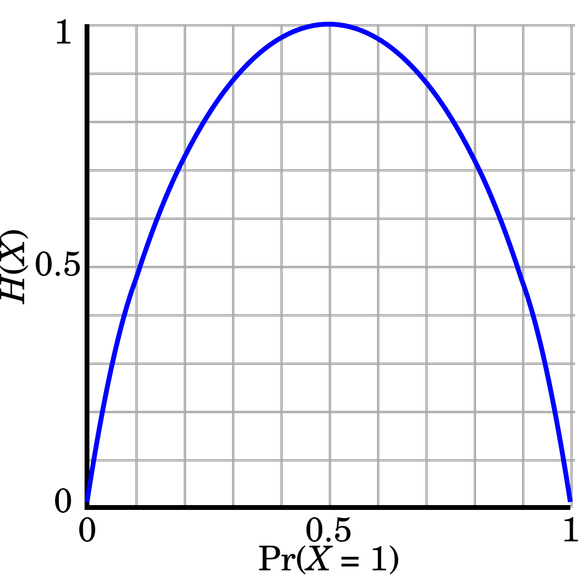
Binary cross-entropy loss is a specific instance of cross-entropy loss used primarily for binary classification tasks.
30.[Network] Multi-Layer Perceptron (MLP)
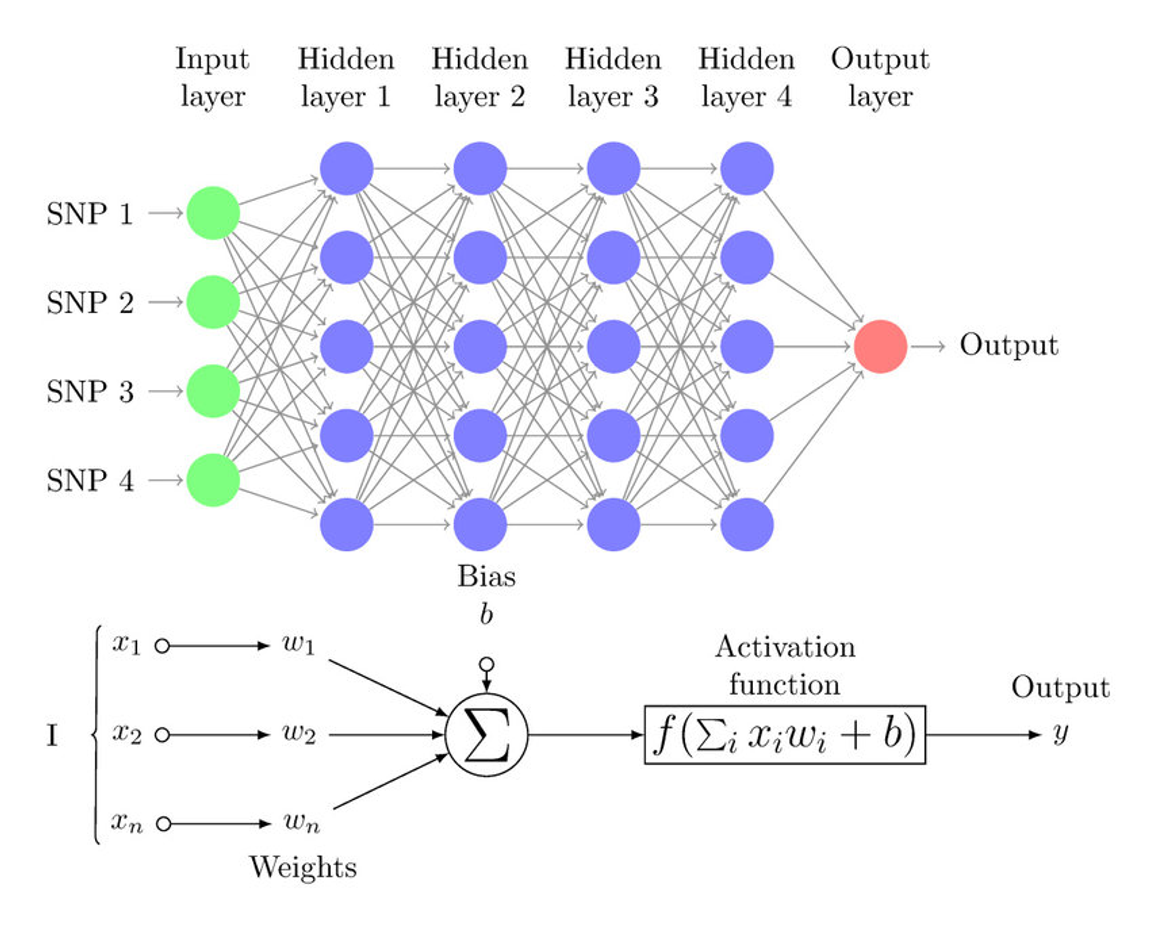
A Multilayer Perceptron (MLP) is a class of feedforward artificial neural network (ANN) that consists of at least three layers of nodes.
31.[Network] Convolutional Neural Network (CNN)
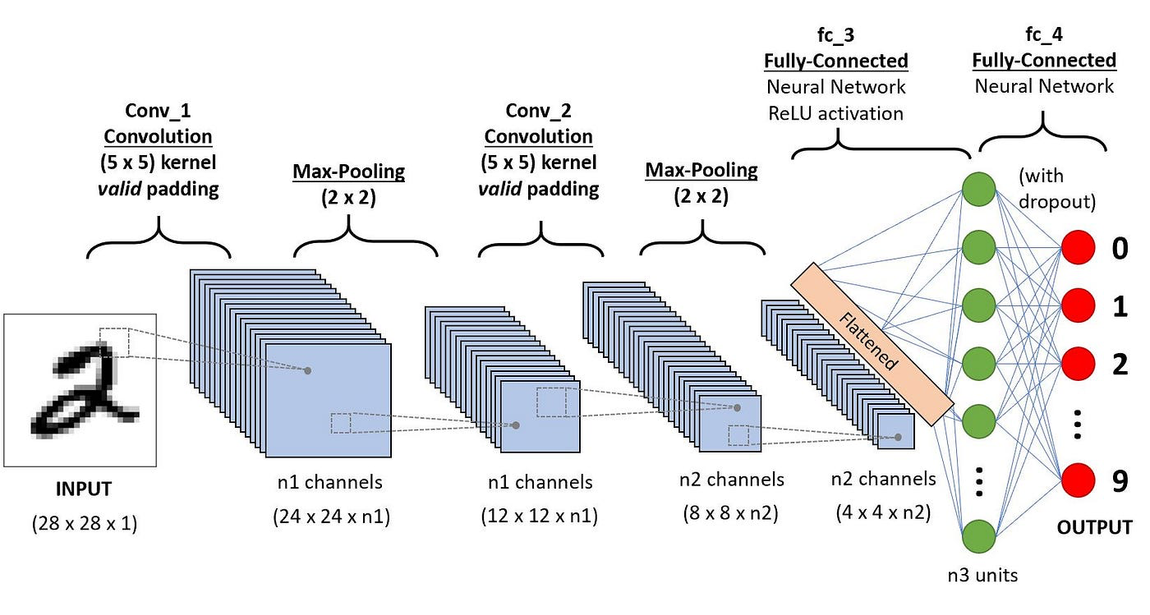
Convolutional Neural Networks (CNNs) are a class of deep neural networks that are primarily used to analyze visual imagery.