📸 Image Classification(이미지 분류)(2)- GoogLeNet, ResNet,DenseNet,SENet,EfficientNet| 내가보려고정리한AI🧐
DeepLearning
Preview
이번 장에서는 GoogLeNet, ResNet가 Degradation problem를 어떻게 해결하였는지 알아보고, DenseNet, SENet, EfficientNet을 통해 Image Classification 성능을 더 높이는 방법을 알아보겠다.
GoogLeNet
GoogLeNet이란
구글에서 제안한 모델로 Christian Szegedy 등에 의해 2015 CVPR에 개제된 "Going Deeper with Convolutions"에서 소개된 모델이다.
GoogLeNet은 2014년 이미지넷 이미지 인식 대회(ILSVRC)에서 VGGNet(VGG19)을 이기고 우승을 차지한 알고리즘이다. GoogLeNet은 19층의 VGG19보다 좀 더 깊은 22층으로 구성되어 있다
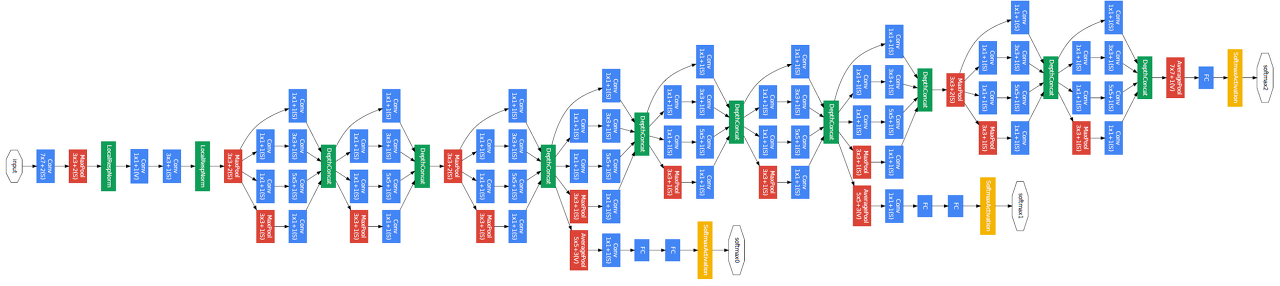
GoogLeNet의 특징
- inception module
- bottleneck layer - 1x1 covolution
- auxiliary classifier
- global average pooling(a single FC layer)
inception module
💁♀️ GoogLeNet은 아래와 같은 총9개의 인셉션 모듈이 있다.
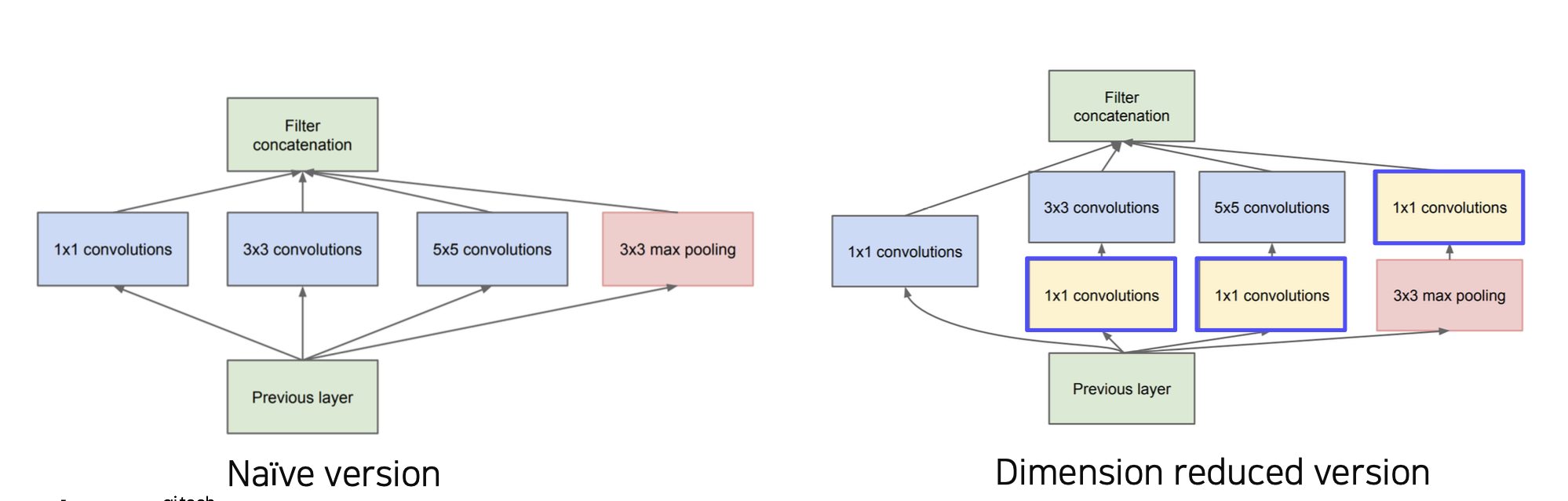
💁♀️ inception module은 기본적으로 (Naïve version)와 같이 이전 layer에서 온 feature map(input data)를 1x1, 3x3, 5x5 convolution, 3x3 max pooling한 값을 채널축으로 concatenate한다.
- 이때 각 Inception module은 1x1, 3x3, 5x5 등 서로 다른 크기의 convolutional filter를 조합하여 구성되는게 아니다.
💁♀️ 이런 inception module은 다양한 특징을 결합해 더 광범위한 특징을 추출하게 한다
🆀 하나의 Layer에서 여러번의 convolution을 진행하면 연산량이 많아질 것 같은데 하나의 inception module은 연산량이 얼마나 될까?
🅰 input data가 28x28x256일때 inception module의 총연산량은 다음과 같다.
[output size]
1x1 conv(padding = 0, kernel의 개수 = 128) = (28 x 28 x 128)
3x3 conv(padding = 1, kernel의 개수 = 192) = (28 x 28 x 192)
5x5 conv(padding = 2, kernel의 개수 = 96) = (28 x 28 x 96 )
3x3 maxpool(padding = 1) = (28 x 28 x 256)
= (28x28(128+192+96+256))
= (28x28x672)[parameter count]
1x1 conv parameter : 28x28x256x1x1x128 = 25,690,112
3x3 conv parameter : 28x28x256x3x3x192 = 346,816,512
5x5 conv parameter : 28x28x256x5x5x96 = 481,689,600
total = 854,196,224
💁♀️ Naïve version inception module을 하나 사용하였을때 연산량이 854M으로 연상량이 엄청 증가 하는것으로 알 수 있다.
💁♀️ 이를 해결하기 위해 Dimension reduced version처럼 1x1 conv로 구성된 bottleneck layer를 추가해주었다
bottleneck layer - 1x1 covolution
💁♀️ 실제 사용된 inception module은 (Dimension reduced version)와 같이 1x1 convolution이 적용된 모델이다
🆀 1x1 covolution는 왜 사용해 주었을까?
🅰 여러 필터를 많이 사용하고 합치면 계산복잡도가 늘어나기 때문에 feature map의 차원를 줄여주기 위해 1x1 convolution을 통해 출력사이즈는 유지하면서 출력 채널의 수는 줄여주었다.
🆀 bottleneck layer가 추가된 inception module은 연산량이 얼마나 될까?
🅰 input data가 28x28x256일때 Dimension reduced version inception module의 총연산량은 다음과 같다.
[output size]
1x1 conv(padding = 0, kernel의 개수 = 128) = (28 x 28 x 128)
1x1 conv(padding = 0, kernel의 개수 = 64) +3x3 conv(padding = 1, kernel의 개수 = 192) = (28 x 28 x 192)
1x1 conv(padding = 0, kernel의 개수 = 64) + 5x5 conv(padding = 2, kernel의 개수 = 96) = (28 x 28 x 96 )
3x3 maxpool(padding = 1) + 1x1 conv(padding = 0, kernel의 개수 = 64)= (28 x 28 x 64)
= (28x28(128+192+96+64))
= (28x28x480)[parameter count]
1x1 conv parameter : 28x28x256x1x1x128 = 25,690,112
1x1 conv + 3x3 conv parameter : 28x28x256x1x1x64 + 28x28x64x3x3x192 =99,549,184(12,845,056 + 86,704,128)
1x1 conv + 5x5 conv parameter : 28x28x256x1x1x64 + 28x28x64x5x5x96 = 133,266,456(12,845,056 + 120,422,400)
(3x3 maxpool+)1x1 conv parameter : 28x28x256x1x1x64 = 12,845,056
total = 271,350,808
- 3x3 convolution시 346,816,512 -> 99,549,184
- 5x5 convolution시 346,816,512 -> 133,266,456
- 총 854,196,224 -> 271,350,808로 3.15배 줄어든 것을 알 수 있다.
💁♀️ 인셉션 모듈은 3x3, 5x5 필터 등을 적용하기 전 1x1 bottleneck layer를 적용하여 input volume을 줄여 계산 cost를 감소시키는 것이 아닌 kernel의 개수를 줄이면서 차원의 수를 줄인다.
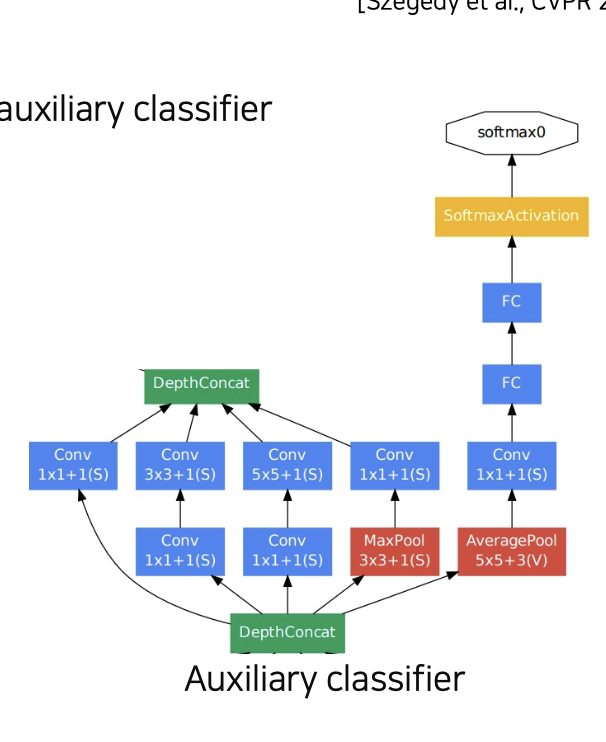
auxiliary classifier
💁♀️ inception modules를 보면 중간 module에 보조 classifier들이 있는 것을 볼수 있는데 이것이 auxiliary classifier이다.
💁♀️ GooLeNet은 22층으로 깊어질수록 Back Propagation시 gradient가 제대로 업데이트가 안되 degradation problem이 발생할 수 있기 때문에 중간중간 gradient를 넣어주므로서 낮은 층 레이어에 gradient가 잘 전달해주기 위해 auxiliary classifier를 사용하였다.(당연히 auxiliary classifier를 학습에만 사용된다)
global average pooling(a single FC layer)
💁♀️ GooLeNet은 분류를 위한 하나의 Fully connected layer만 남기고 나머지 FC layer는 없앰으로서 학습할 parameter 5M개로 매우 감소 시켰다.
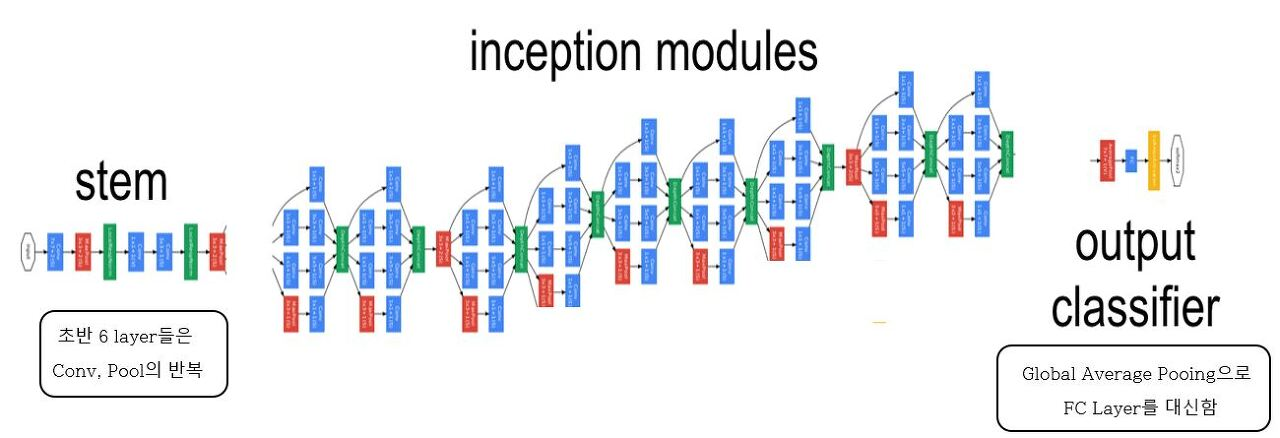
💁♀️ GooLeNet은 stem - indeption modules - output classifier 로 나눌수 있다.
이때 output classifier에서 기존 모델은 Flatten통해 tensor를 vector화 시킨 후 여러 Fully connected layer를 통해 분류를 하는데 비해 GooLeNet은 Global Average Pooling을 사용하므로서 parameter 양을 줄였다.
ResNet
ResNet이란
마이크로소프트에서 개발한 모델로 'DEEP RESidual Learning for Image Receginition'에서 소개되었다.
2015년 ILSVRC에서 우승을 차지한 알고리즘이다. 많은 논문에 인용되었고 다른 CV tasks에서 backboned으로 많이 사용되며 처음으로 인간레벨을 뛰어넘은 모델이다.
[Top-5 validation error 비교]
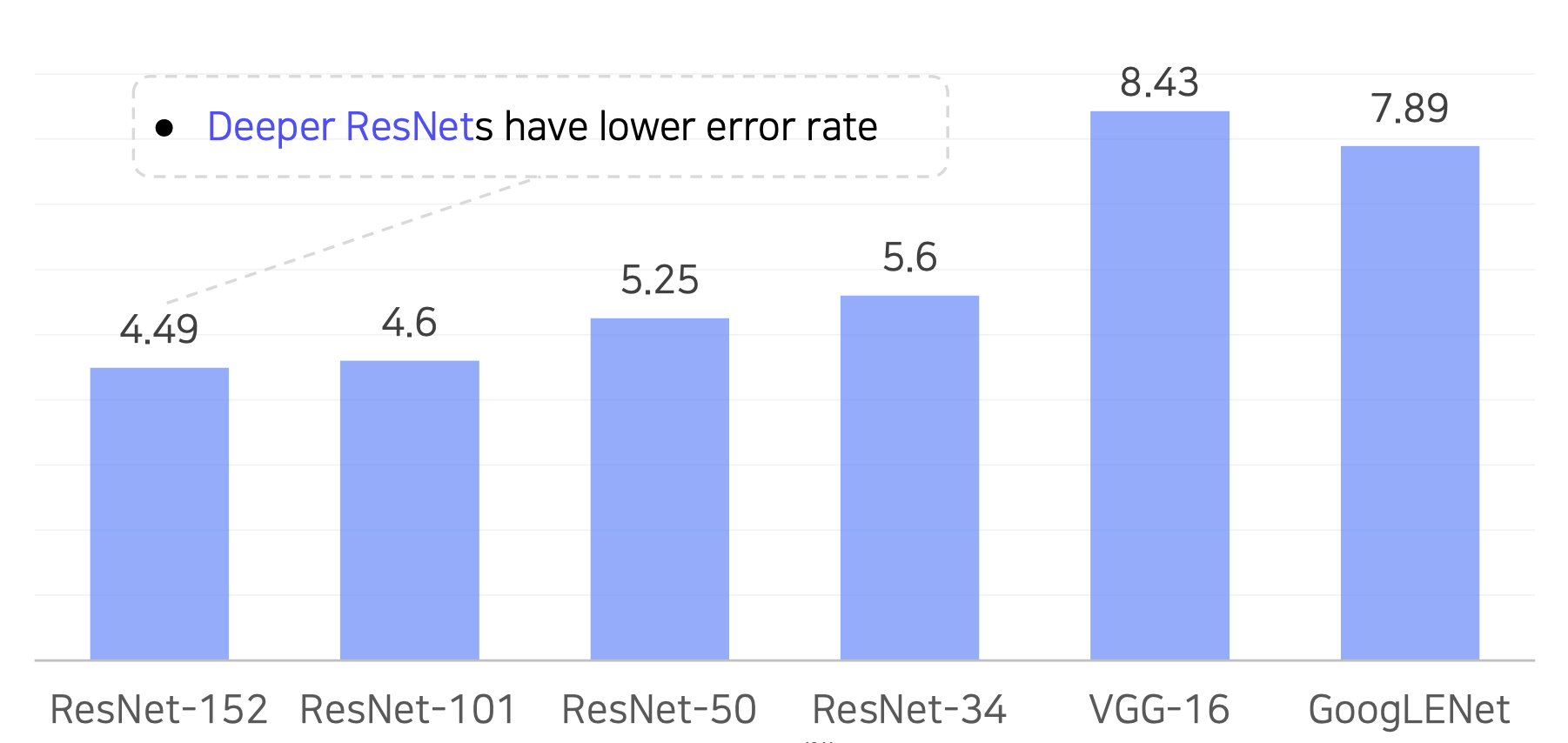
💁♀️ 깊은 레이어를 쌓을수록 더 좋은 성능 lower error rate를 보여준다는 것을 증명하였다.
ResNet 구조
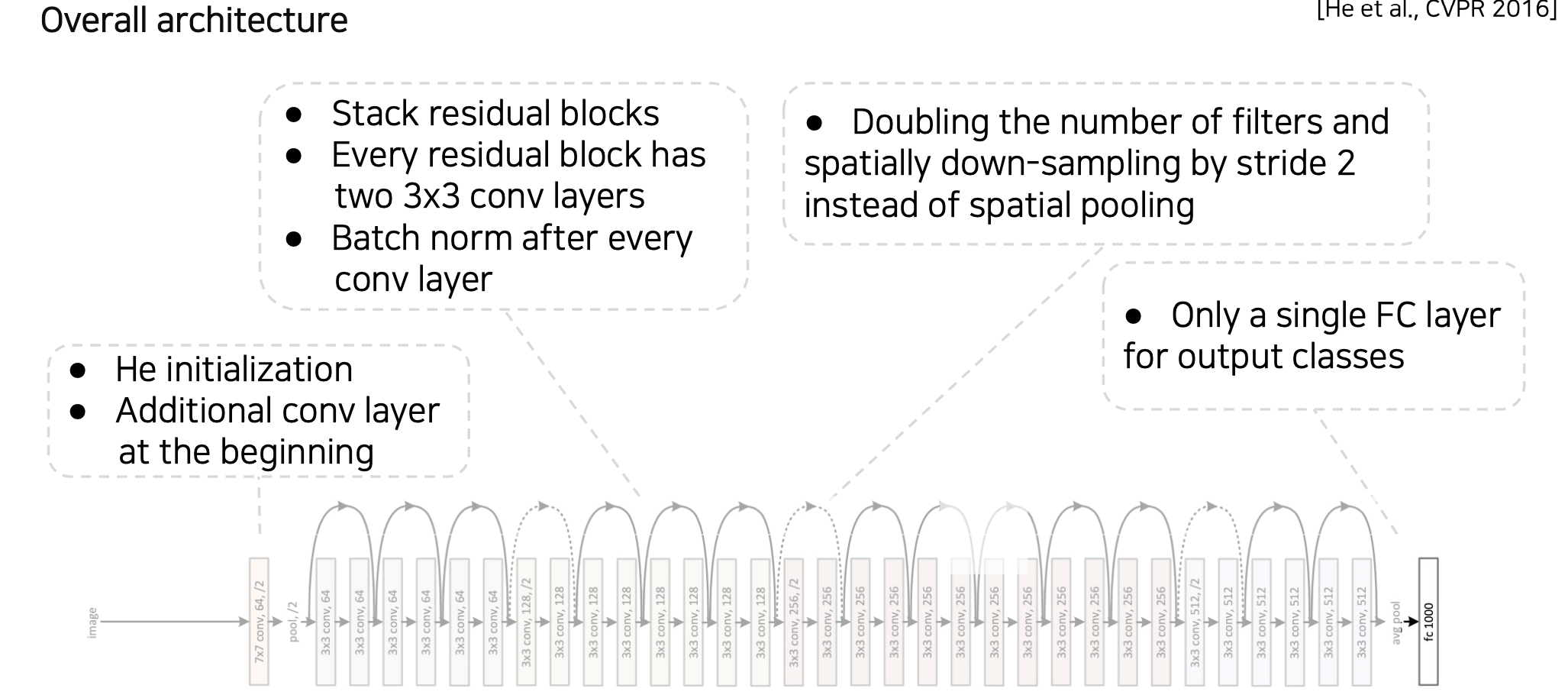
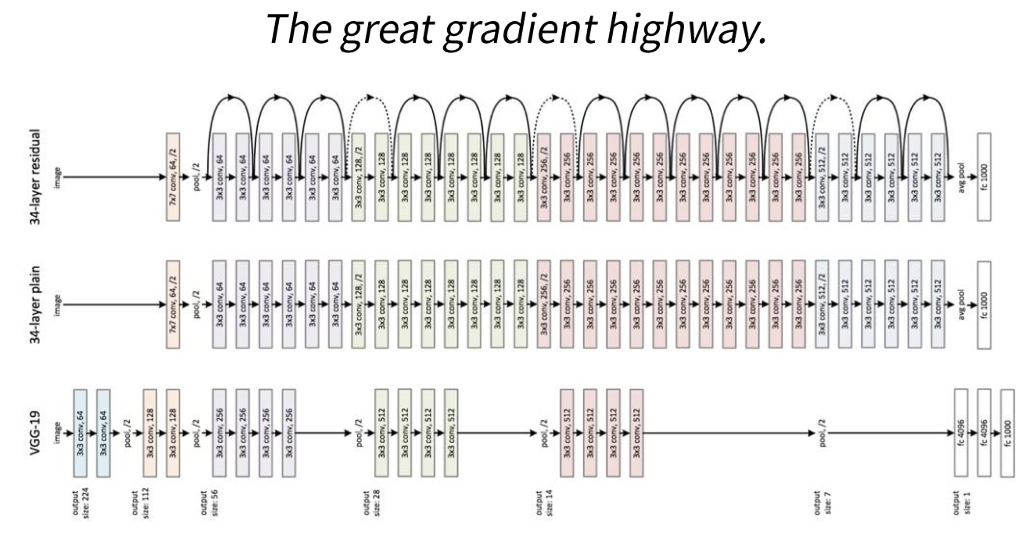
💁♀️ ResNet의 특징
1. residual block
2. he initialization
3. batch normalization
🆀 ResNet은 어떻게 degradation problem를 해결하였을까?
🅰 ResNet은 residual block을 사용하여 깊은 레이어에도 back propagation을 수행할 수 있게 하였다.
residual block
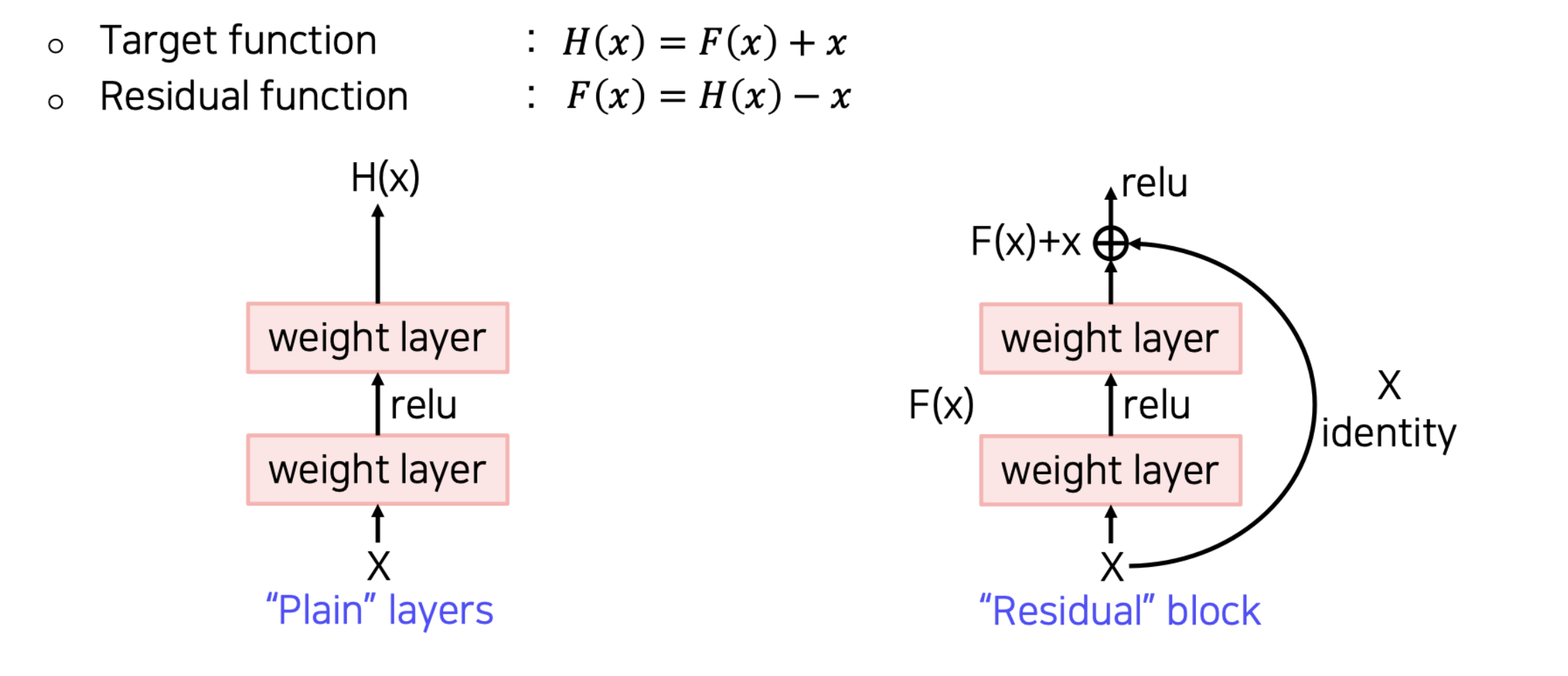
💁♀️ 기존 layers는 input data로 target data H(x)를 얻는 것이 목적이였으나 이와 다르게 residual block는 output값에 input data은 x를 더해 F(x) + x를 최소화하는 것을 목표로 한다.
💁♀️ F(x) = H(x)-x 이고 x는 고정값이므로 F(x)를 최소화한다는 것은 H(x)-x를 0과 가깝게 나는 말이다. 이때 H(x)-x를 residual이라고 한다.
💁♀️ 이때 F(x)에 x를 더해주는 것을 shortcut connection이라고 한다.
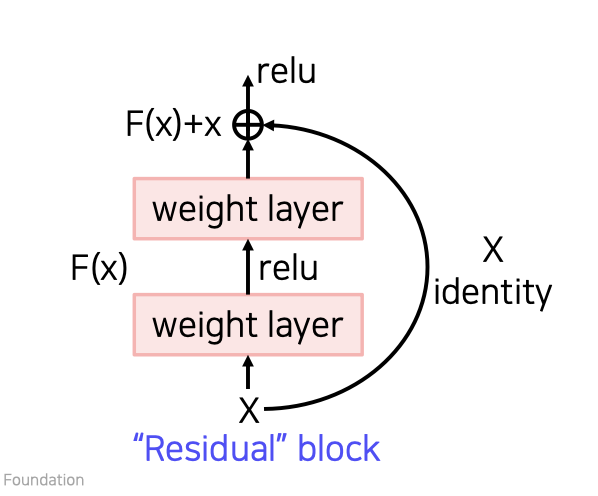
왜 residual block이 성능이 좋을까?
💁♀️ 학습이 진행되는 동안 gradients는 주로 연결된 shorter paths로 오기 때문에 2^n승의 경우의 수로 input과 output에 적용된다
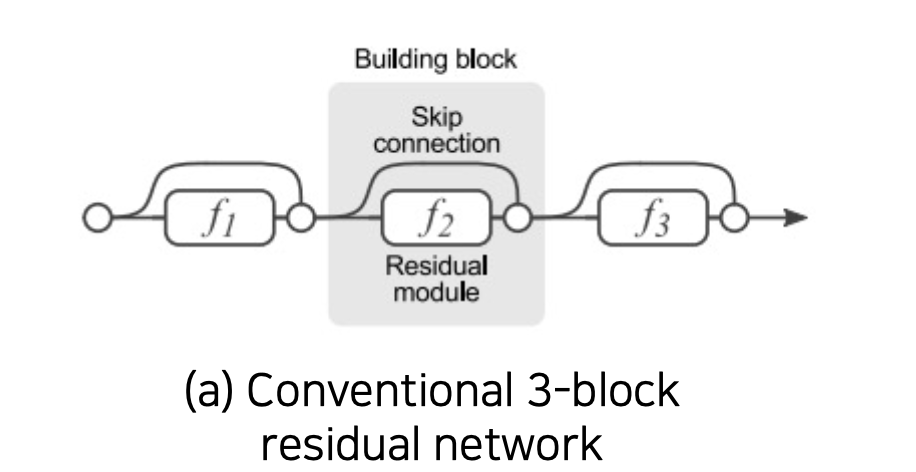
💁♀️ residual block을 추가 할때마다 paths의 number는 2배로 늘어남
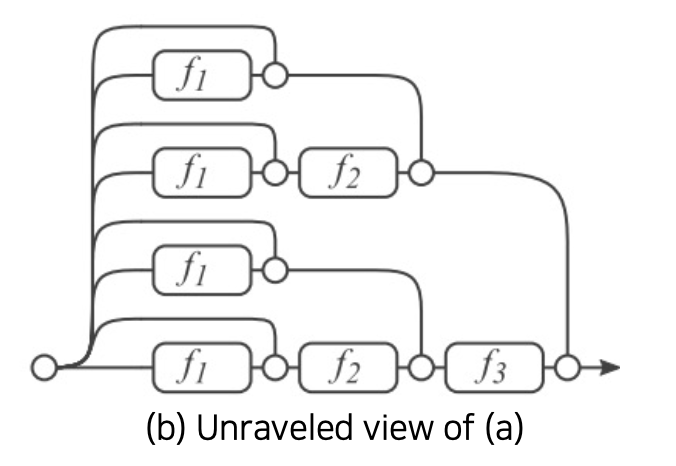
💁♀️ 즉, L개의 block으로 구성된 ResNet은 총 L^2개의 skip connection 을 가지고 있게 된다
he initialization
💁♀️ he initialization은 Glorot 기법의 한계를 극복하기 위해 Kaming He가 2010년에 발표한 'delving deep into rectifier, he et al, 2010'에서 제안된 기법이다.
💁♀️ ResNet에서 일반적인 initialization하면 초기 weight가 크므로 shortcut connection시 더해지는 값이 커지기 때문에 he initialization를 사용하였다.
💁♀️ ReLU함수를 activation으로 사용되는 신경망을 초기화할때 많이 사용된다.
batch nornalizaion
💁♀️ batch nornalizaion은 2015년 구글의 Sergey loffe, Christian Szegedy가 공동으로 발표한 'Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift'에서 소개되었다. 2015년 발표된 이후 딥러닝모델에 대부분 적용되면 ResNet에서도 적용되었다.
💁♀️ Covariate Shift는 학습하는 중에 이전 layer의 파라미터 변화로 현재 layer가의 입력 분포가 바뀌는 현상이다.
💁 batch nornalizaion으로 층으로 들어가는 입력값이 한쪽으로 쏠리거나 너무 퍼지거나, 좁아지지 않게 해준다
DenseNet
2017년 CVPR에서 소개된 'Densely Connected Convolutional Networks'에 나온 모델로 ResNet과 비교하였을때 더 적은 parameter를 이용하여 더 높은 성능을 낸 모델이다.

DenseNet구조
💁♀️ ResNet은 element-wise addition이고 DenseNet은 channel-wise concatenation이다.
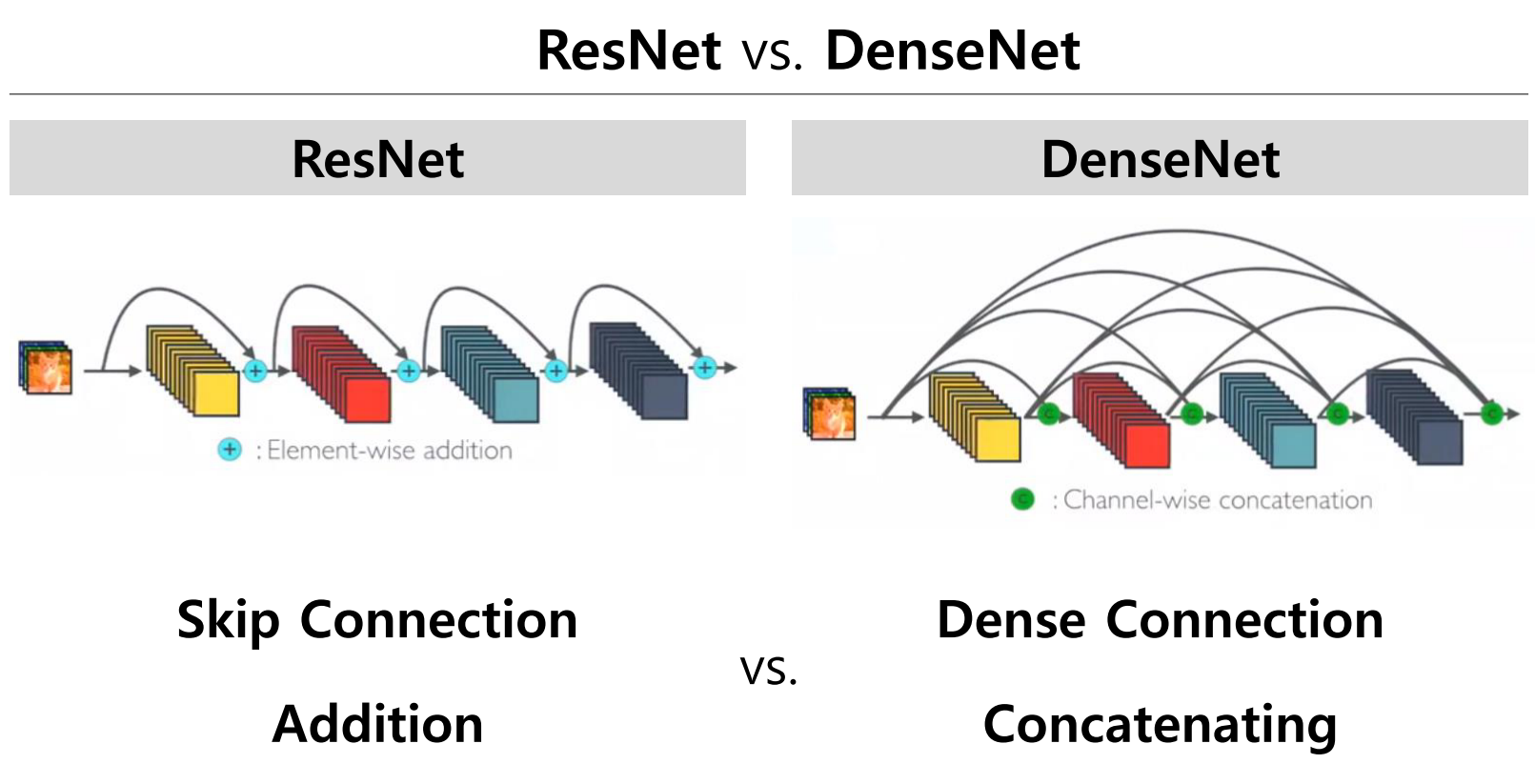
💁♀️ ResNet은 skip connection을 통하여 바로 뒤의 layer를 연결하는 addition 통로가 생기는 반면 DenseNet은 네트워크 이름과 같이 바로 뒤의 layer 뿐만 아니라 더 뒤의 layer 까지 연결한 concatenation 통로가 빽빽하게 만들어진다.
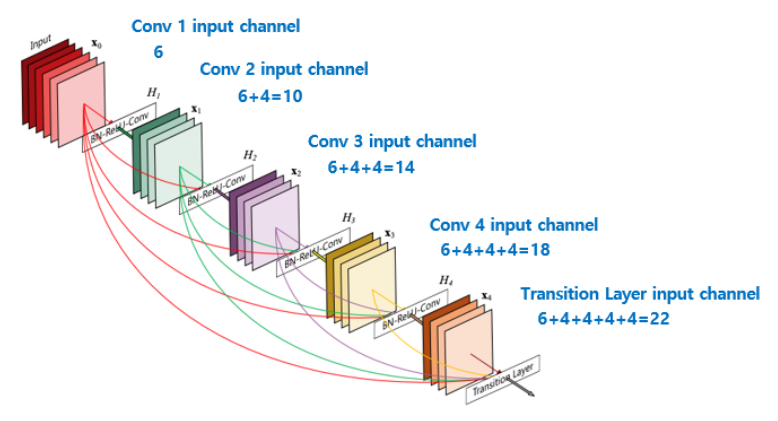
💁♀️ 이전의 출력들이 모든 레이어에 concatenate하면서 dense하게 이루어지고, 상위 레이어에서도 하위레이어의 값을 참조한다
DenseNet 특징
💁♀️ DenseNet은 이런 구조를 통해 아래와 같은 특징을 가진다.
-
특징의 재사용한다(Encourage the reuse of features)
많은 레이어를 통과하여 신경망의 끝에 다다르면, 처음 레이어의 피쳐맵에 대한 정보는 사라질 수 있있는데 DenseNet은 처음 레이어의 피쳐맵을 마지막 레이어의 피쳐맵까지 연결하므로써 feature reuse 하였다.
feature reuse을 통해 정보가 소실되는 것을 방지해 information flow가 향상된다 -
역전파 강화(strengthen feature propagation)
또한 Back Propagation시 초기의 gradient가 소실될 수 있는데, 초기값을 마지막으로 직접 전달하므로 Back Propagation시 값이 직접 전달해 Back Propagation를 강화한다
-
경사 소실 완화(gradient vanishing alleviate)
이러한 Dense한 구조는 강한 gradient flow, information 소실을 방지하여 gradient vanishing alleviate한다. -
파라미터수와 연산량이 적다.
DenseNet은 많은 채널수를 이용한다. 각 레이어의 피쳐맵을 연결하여 다음 레이어로 전달하면, 적은 채널 수의 피쳐맵을 생성하고, 그리고 이 피쳐맵은 이전 레이어의 피쳐맵과 결합하여 다음 레이어로 전달되므로 파라미터 수가 적다.
SENet
'SENet, Squeeze-and-Excitation Networks'에서 소개한 모델로 SENet은 ILSVRC 2017에서 1등을 한 모델이다.
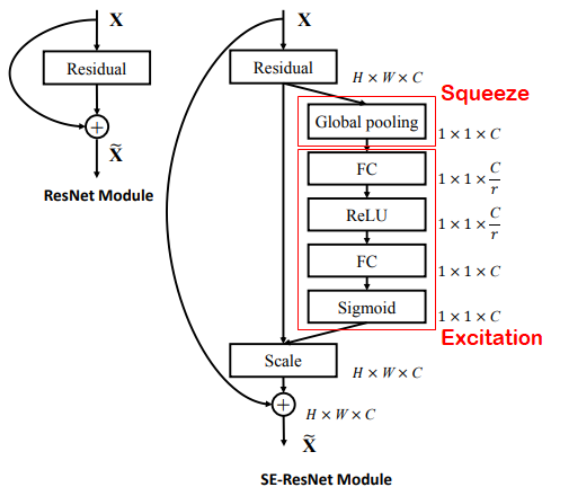
SE Block을 활용하는 모델로 SE Block은 CNN 기반 모델에 부착하여 사용한다. residual 모델, Inception 모델, VGGnet에도 함께 사용할 수 있다.
low-level에서 SE Block은 클래스 상관없이 중요한 특징을 추출하고, High-level에서는 클래스와 관련있는 특징들을 추출한다고 한다.
💁♀️ ResNet와 DenseNet처럼 깊이를 늘리거나 connection을 새로 만드는 것과 달리 채널간의 관계에 주목한 모델이다.
채널 간 interdependency(상호의존도)를 모델링하여 채널의 wise한 응답을 recalibrates(재보정)했다.
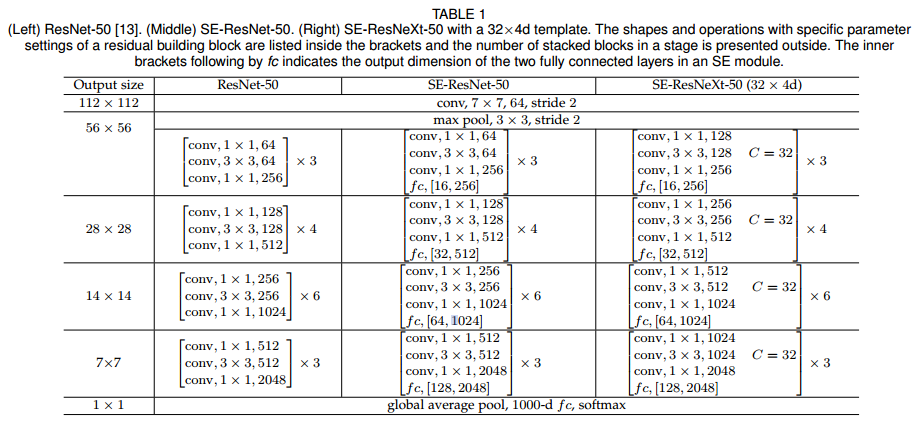
💁♀️ ResNet-50에 부착되어 사용된 것을 알 수 있다.
SENet의 구조
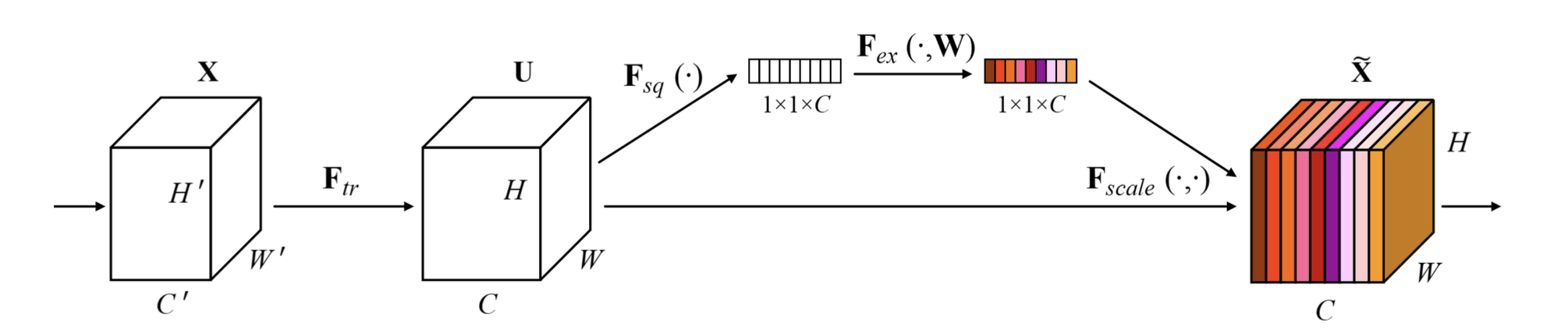
squeeze step
💁♀️ Squeeze는 각 채널을 1차원으로 만드는 역할(압축)을 한다
각 채널별 가중치를 계산하기 위해 각 채널을 1차원으로 만든다.
입력을 global average pooling을 통해 1x1xC로 압축해 각 채널의 공간정보를 없애고 채널의 분포를 구한다. 즉, magnitude(상대적 수치)라고 볼 수 있다.
excitation step
💁♀️ Excitation은 Squeeze에서 생성된 (1x1xC)벡터를 정규화하여 가중치를 부여하는 역할을 한다.
FC Layer를 통해 채널간 연관성 고려해서 채널을 새로 gating(재배열)하기 위한 attention score를 구함
구한 attention score와 squeeze step에서 구한 분포를 활용해 중요도가 떨어지는 것은 낮은 값을(닫히도록) 중요도가 높은 것은 강조하도록(열리도록) activation을 rescaling함
SENet의 성능
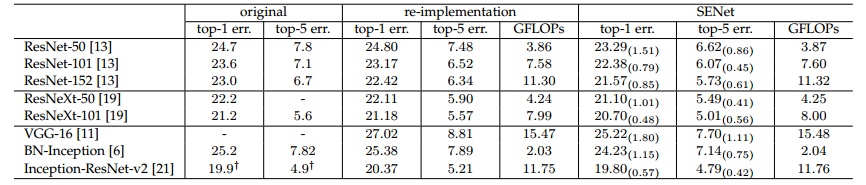
💁♀️ SE Block을 붙였을때 성능이 좋아진 것을 볼 수 있다.
EfficientNet
2019년 5월(Arxiv), ICML에서 Mingxing Tan, Quoc V. Le가 발표한 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'에서 소개된 모델이다.
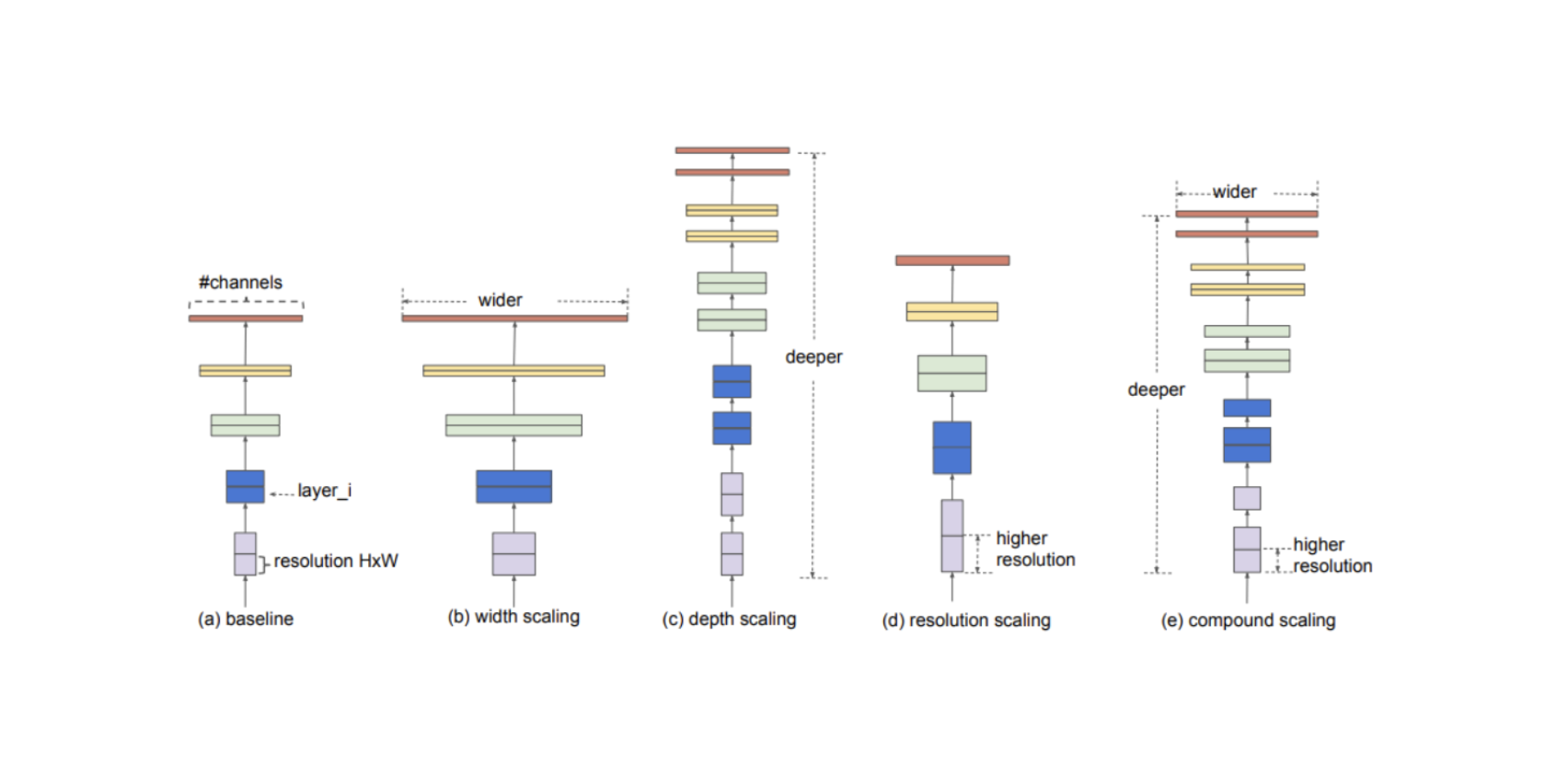
앞선 모델들을 통해 성능을 높이기 위한 방법은 3가지로 귀결됨을 알 수 있다.
👉 more width
- GooleNEt- inception 모듈, , DENSNET 과 같이 채널 축을 늘리는 방법
👉 more deep
- ResNet과 같이 레이어를 많이 쌓기
- (ResNetdms element-wise addition구조이므로 width가 아닌 deep 방식이다)
👉 more resolution scaling
- 해상도 높은 이미지(사이즈가 큰 input data) 학습
💁♀️ 3가지 방법론 각각 어느정도 성능 향상이 있지만 그 증가폭은 서로 다르다
💁♀️ EfficientNet은 이 3가지를 동시에 어떻게 scaling하면 더 좋은 모델이 나오지 않을까? 라는 것에 주목한다.
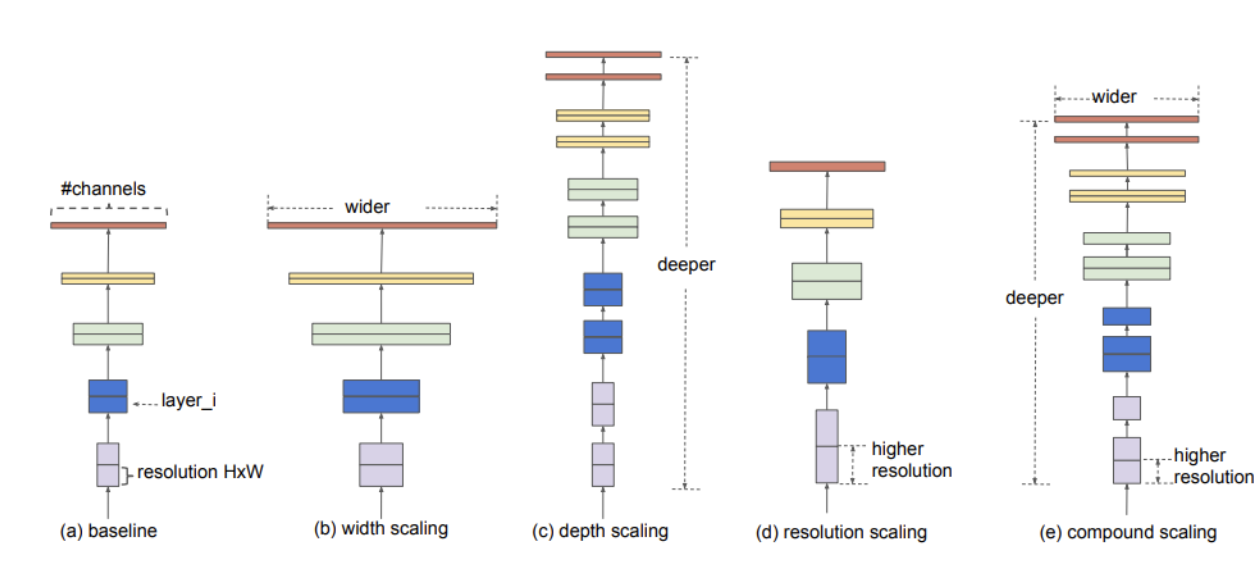
💁♀️ EfficientNet은 이 3가지의 최적의 조합을 AutoML을 통해 찾은 논문이다. 조합을 효율적으로 만들 수 있도록 하는 compound scaling 방법을 제안하며 이를 통해 더 작은 크기의 모델로도 SOTA를 달성한 논문이다.
EfficientNet 성능
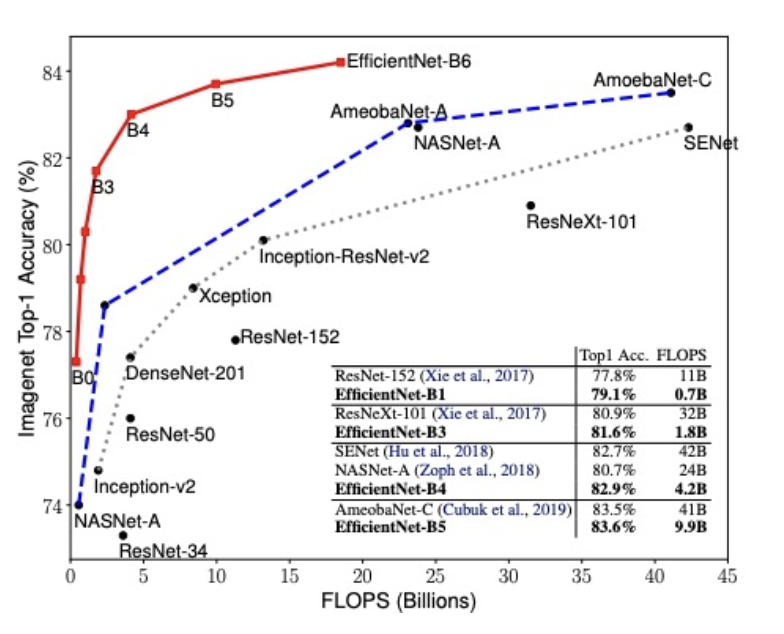
💁♀️ ImageNet에서 기존 ConvNet보다 8.4배 작으면서 6.1배 빠르고 더 높은 정확도를 갖는다.
💁♀️ 사람이 직접 모델링한 모델들보다 훨씬 성능이 좋고,NasNet(강화학습과 RNN을 통해 컴퓨터가 모델링한 모델)보다도 성능이 좋다, 적은 FLOPS(컴퓨터 성능)로 좋은 성능을 냈다
image classification 요약
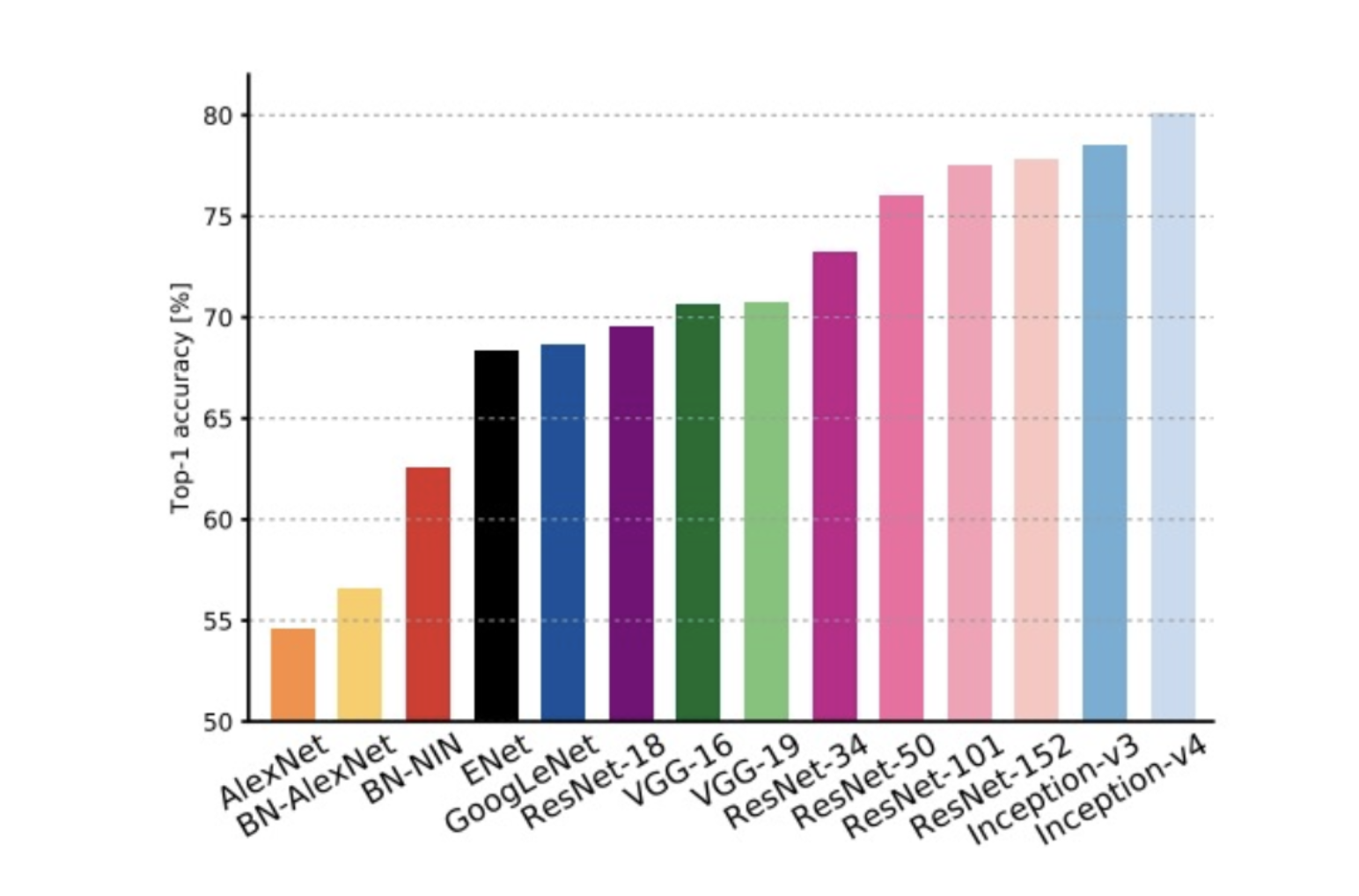
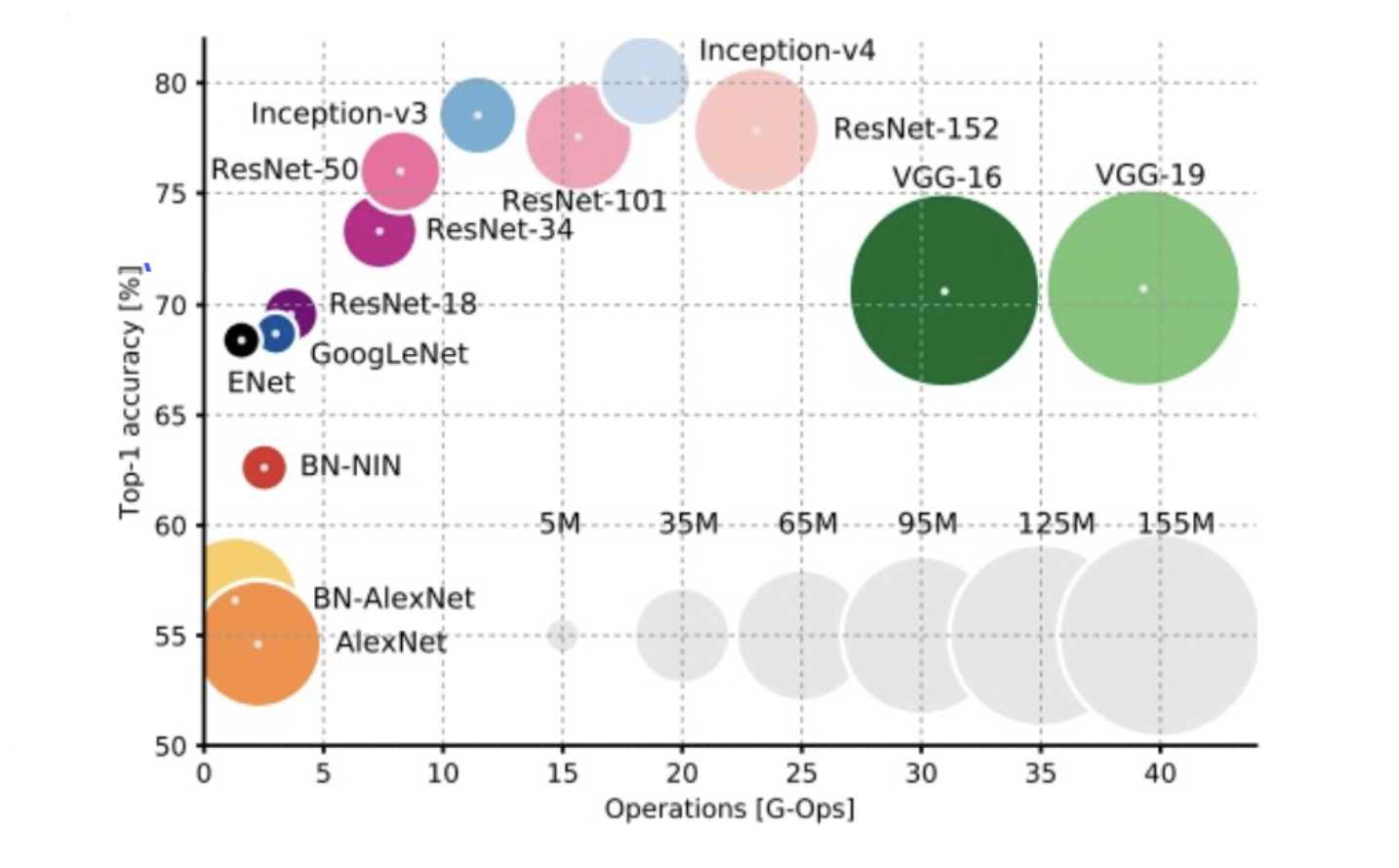
LesNet-5 : 처음 CNN구조를 제안함
AlexEet : 간단한 CNN 모델로, 모델 사이즈가 코고, simple 컴퓨팅 계산, 높은 메모리 사이즈, 낮은 정확도를 가짐
VGGNet : 간단한 3*3conv로 구성되며 가장 높은 메모리, 가장 무거운 컴퓨팅 계산을 지님
GoogLNet : inception module & auxiliary classifier로 VGGNet보다 낮은 컴퓨팅 계산, 메모리 사이즈도 적음, 그러나 Inception 계열 모델 중에서는 크고 느림
ResNet : Moderate efficiency를 가짐
💁♀️ 여러 다른 task의 backbone 모델은 VGG, ResNet 등을 사용한다
Epilogue
이미지 분류는 다양한 어플리케이션에 적용할 수 있고, 실용적이라 관심이 많다.
CV분야의 뼈대되는 방법으로 최근 컴퓨터 비전 발전사에서 허리 역할을 하고 있다.
다음 장에서는 CV분야에서 이미지 분류 외에 다른 Tasks를 다루겠다.
-참고-
- 네이버 부스트캠프 AITech 5기
- [CNN 알고리즘들] GoogLeNet(inception v1)의 구조
- CNN 아키텍처 정리3 - GoogLeNet
- [CNN 알고리즘들] AlexNet의 구조
- ResNet 논문 요약/리뷰
- curaai00-ResNet
- ResNet 구조 이해 및 구현
- 갈아먹는 딥러닝 기초 [2] weight initialization
- DenseNet
- [논문 읽기] DenseNet(2017) 리뷰
- EfficientNet 논문 설명(EfficientNet - Rethinking Model Scaling for Convolutional Neural Networks)
