📸 Image Classification(이미지 분류)(1)-LeNet,AlexNet,VGG부터 Degradation까지 | 내가보려고정리한AI🧐
DeepLearning
preview
우린 앞선 CNN과 CV을 통해 인간의 시각적 인지을 모방하는 방법론에 대해 알아봤다이번 장부터는 Computer Vision의 tasks 중 image classification의 발전 과정을 살펴볼것이다. LeNet-5, AlexNet부터 VGG까지 모델들을 알아보며 깊은 layer를 가질 때 발생하는 Degradation problem을 살펴보겠다.
Image Classification란?
Image Classification란
전체 이미지에 lable 또는 class를 할당 하는 작업이다. 이미지는 각 이미지에 대해 하나의 class 가질 것으로 예상되고, 이미지 분류 모델은 이미지를 입력으로 사용해 이미지가 속한 클래스에 대한 예측을 반환단다.
즉. 이미지와 class를 매핑하는 작업으로, 해당 이미지의 category level을 연결하는 지도를 그리는 것이다.
Classification의 발전 과정
🆀 우리가 이세상의 모든 정보를 기억할 수 있다면 모든 이미지를 분류 할 수 있지 않을까? 그렇다면 어떤 방식으로 모든 이미지를 분류해야 할까?
🅰 모든 이미지 데이터를 K-NN(k nearest neighbors)방식을 적용하면 분류할 이미지의 근처 이웃 데이터를 찾고 그 이웃데이터의 label data를 기반으로 분류할 수 있지 않을까?
즉, 검색으로 생각할 수 있을 것이다.
💁♀️ k nearest neighbors : 쿼리 데이터의 가장 가까운 이웃 데이터를 찾고 이웃 데이터의 라벨 데이터를 참조하여 분류하는 것
🆀 하지만 아무리 컴퓨터 성능이 좋아지더라도 세상의 모든 이미지를 가지고 모든 이미지 간 유사도를 계산하면 Time complexity(계산복잡도)와 Memory complexity(메모리 복잡도)가 무한대에 가깝지 않을까?
🅰 그렇다면single layer neural networks인 perceotron 모델을 통해 이미지를 압축해보자
🤦♀️ 하지만 layer가 하나밖에 없는 단순한 모델이라 복잡한 이미지 분류 문제를 풀기엔 너무 단순하다.
🤦♀️ 또한 single fully connected layer network이기 때문에 하나의 특징(정답에 해당하는 특징)을 뽑기위해 모든 특징을 뽑게 되니 모든 데이터를 평균 시킨 것과 같은 결과만 나오면서 계산해야 되는 파라미터가 너무 많다.
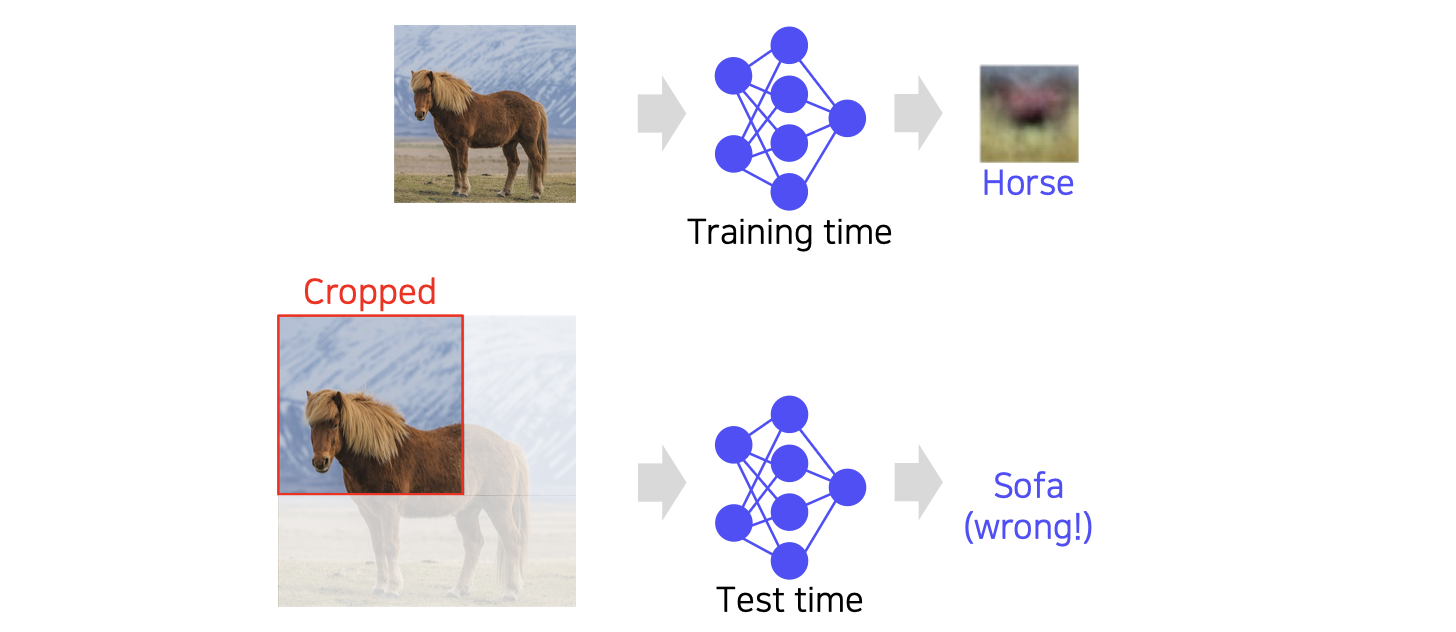
🤦♀️ 학습 데이터와 달리 대상이 잘린 사진이 넣어주면 좋지 못한 결과를 내보내는 문제점 있다.
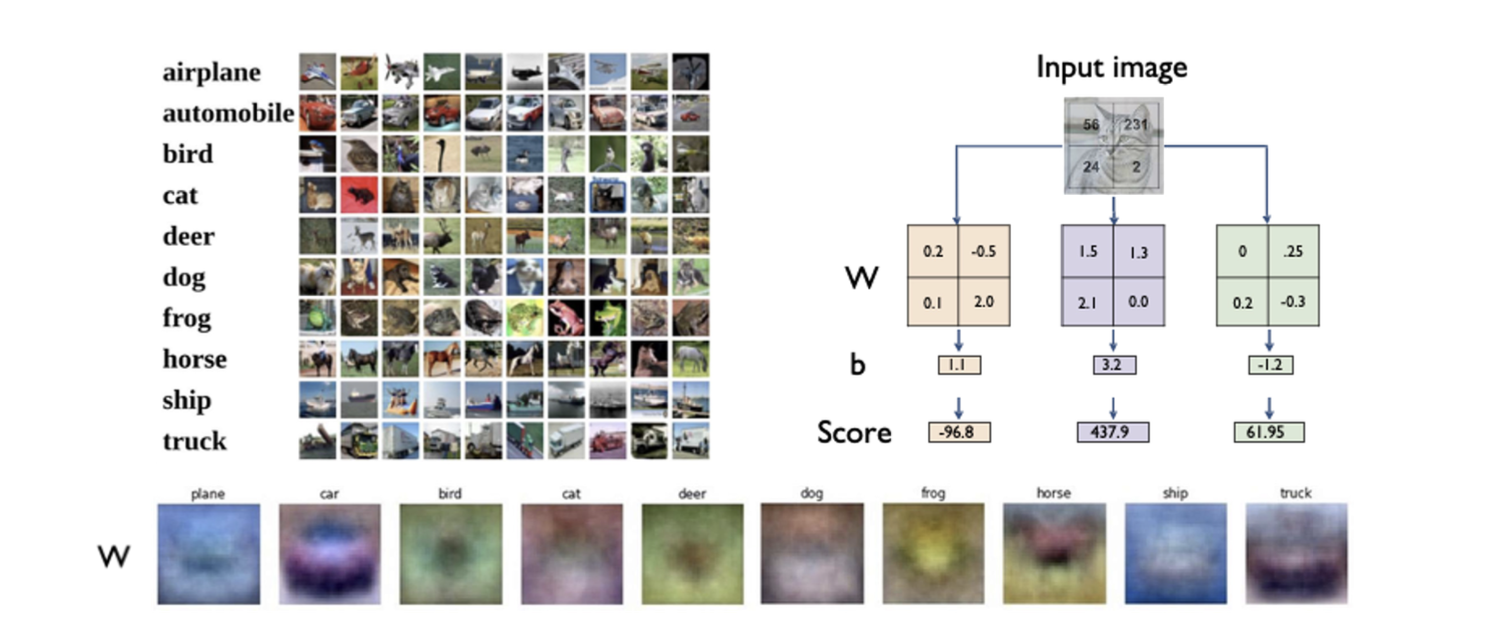
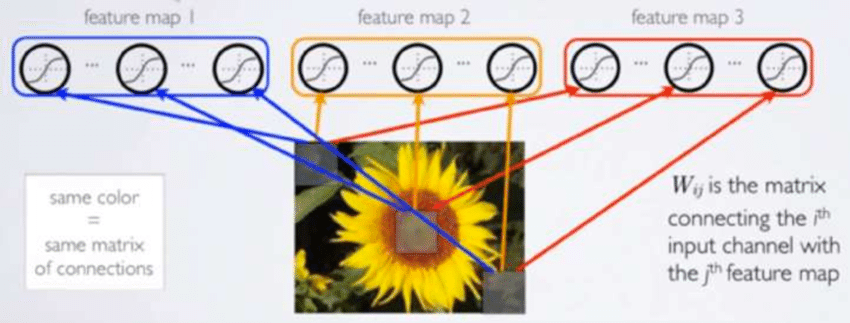
🆀 그렇다면 이미지의 공간적 정보를 추출하면서 파라미터도 적게 계산해야되는 방법이 있을까?
🅰 convolution을 통해서 공간적 특성을 반영해 국부적인 영역만 추출하면 적은 파라미터로 특징 추출이 가능하다!
- 필터가 돌아다니면서 parameter sharing(파라미터 공유)을 하면서 local feature learning을 하므로 적은 파라미터로 대비 효과적으로 특징을 추출한다.
- 따라서 convolution neural networks는 locally connected neural network이다.
💁♀️ CNN은 classification 문제 뿐만아니라 다양한 cv문제에서 backbone이 된다. CNN으로 추출한 특징맵을 이용해 image-level classification, classification+regression, pixel level classification 등으로 발전되었다.
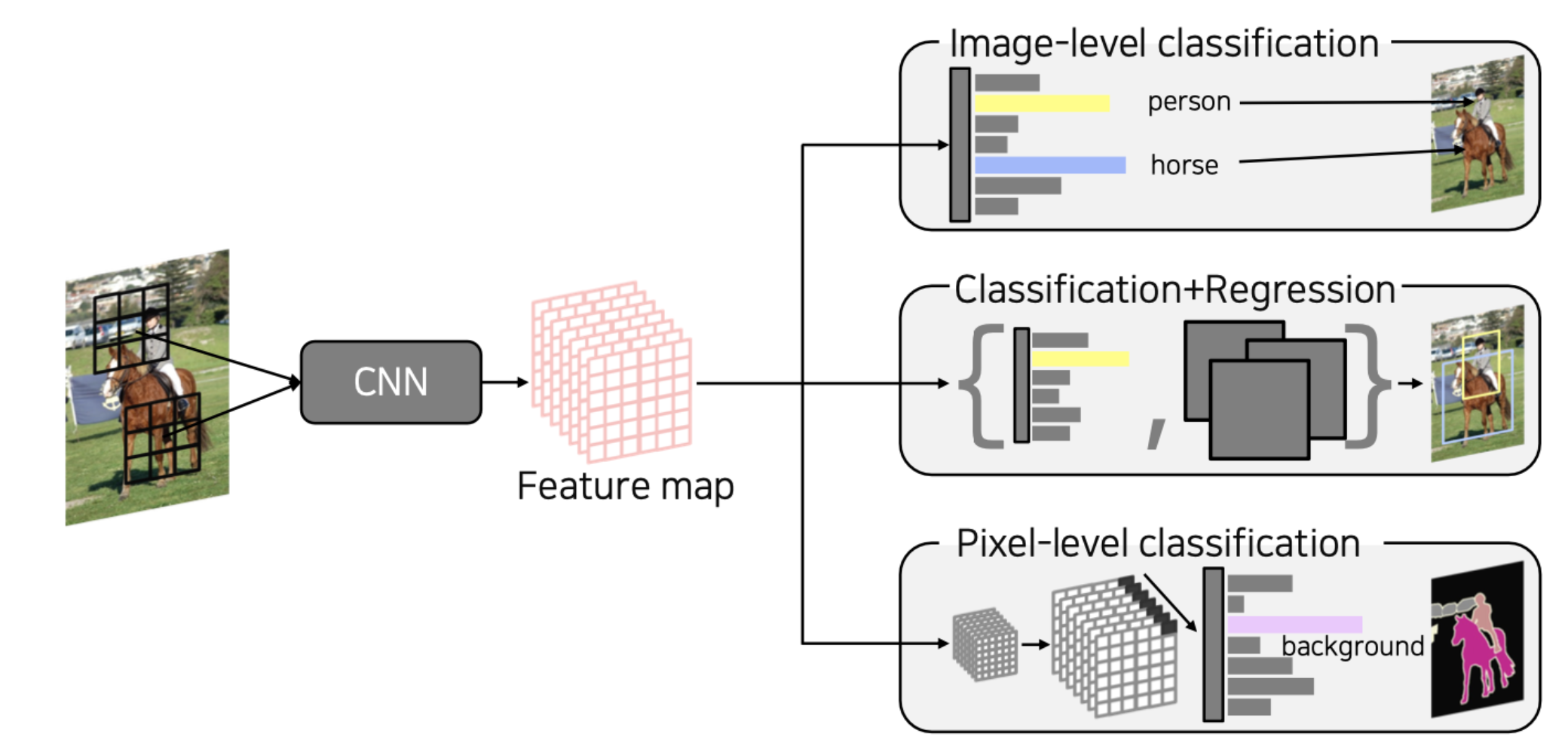
Image Classification의 models
- LeNet5 - 1998
- AlexEet - 2012
- VGGNet - 2014
- GoogLNet - 2015
- ResNEt - 2016
- DenseNet - 2017
- SENet - 2018
- EfficientNet - 2019
LeNet5
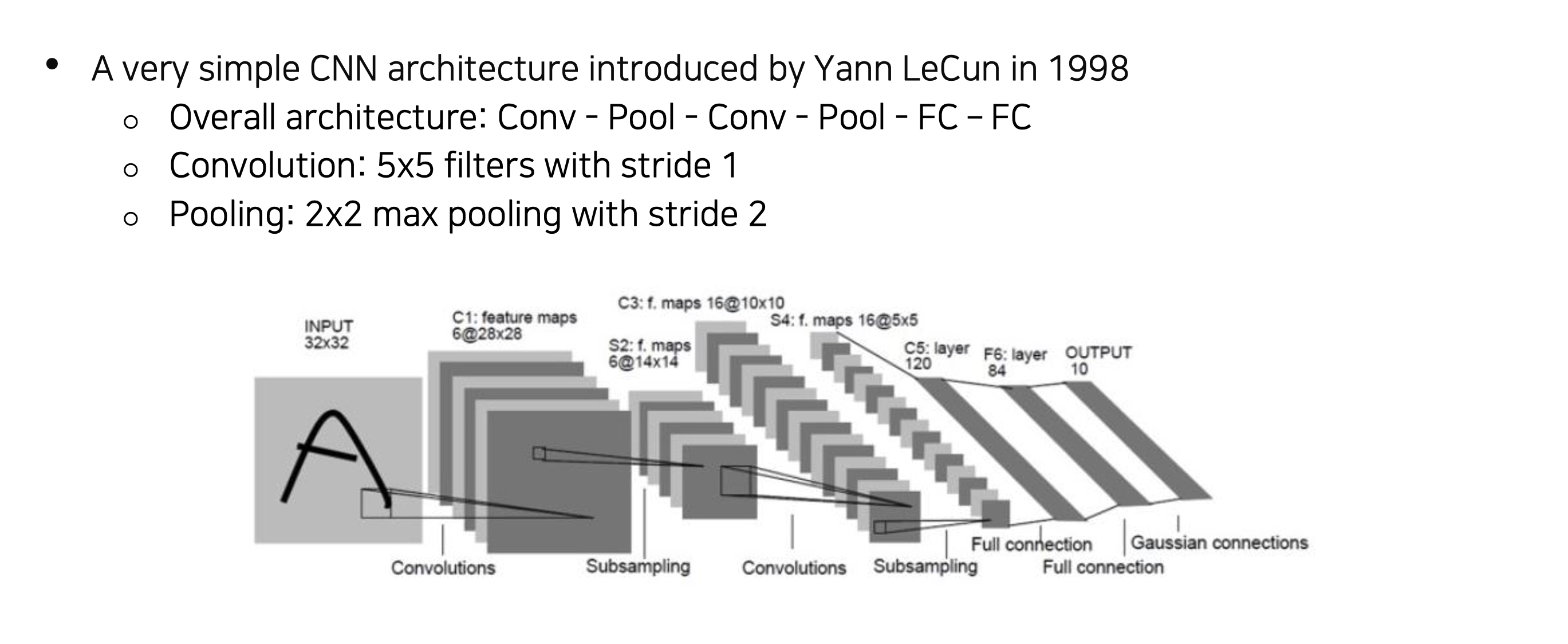
LeNet-5
1998년 Yann LeCun의 논문 'Gradient-Based Learning Applied to Document Recognition' 에 담겨있는 CNN 신경망의 구조를 의미합니다
CNN은 손으로 적힌 우편 번호를 효율적으로 확인하기 위해 고안되었다.💁♀️ Conv(C1) - Subsampling(S2) - Conv(C3) - Subsampling(S4) - Conv(C5) - FC - FC , 약 6만개의 파라미터로 구성되었다.
convolution이 제안된 배경
- 기존의 패턴인식에서는 hand-designed feature extractor로 특징을 추출해 제한된 학습이 이루어지므로 feature extractor 그 자체에서 학습이 이루져야한다
- 기존 패턴인식은 fully-connected multi-layer networks를 분류기로 사용해 많은 파라미터를 계산해야되므로 그에 따라 더 많은 훈련 데이터셋이 필요하고, 메모리 저장공간이 너무 많이 필요하다
- 이미지는 2D구조이므로 인접한 pixel들은 공간적으로 매우 큰 상관관계를 가지고 있는데 fully-connected multi-layer는 이런 변수들을 단순 배열 하므로 공간적 정보를 이용하지 못한다
LeNet5의 특징
- hidden layer의 receptive field를 local로 제안하면서 local featrue를 추출함
- shared weight
- sub-sampling(=pooling)
receptive field
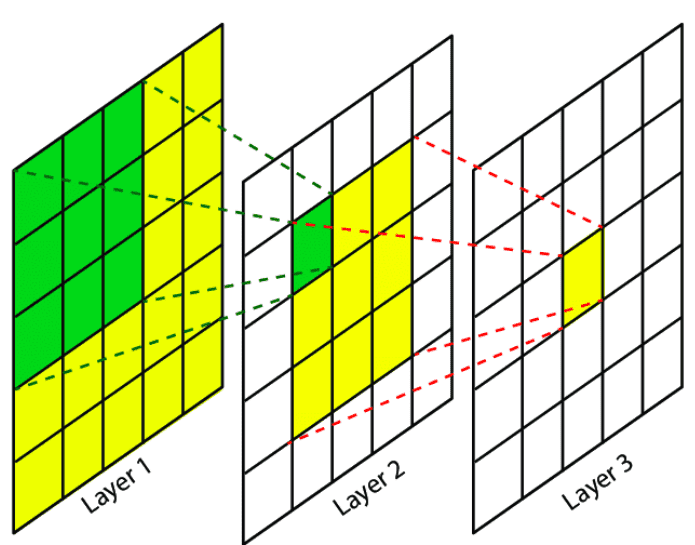
💁♀️ CNN은 이런 문제를 해결하기 filter(kernel)을 통해 layer의 receptive field를 local로 제한함으로써 local feature를 추출했다.
💁♀️ receptive field란 convolution을 거친 output tensor의 하나의 결과값이 원본 이미지에서 담당하는 범위라고 할 수 있다.
💁♀️ 따라서 층이 깊어질수록 더 넒은 receptive field을 갔는 것이다.
receptive field 계산하기
K : kernel(filter) size
L : layers 수
receptive field size = L x (K-1) + 1
🆀 ouput size = (1,1), kernel size = (3,3), layers 2개 일때 receptive field size?(stride 1, input image(5,5))
🅰 receptive field size = (2 x 2 + 1, 2 x 2 + 1) = (5,5)
shared weight
💁♀️ 동일한 weights와 bias를 공유하는 kernel들을 통해 입력에서 모든 위치에서 동일한 특징을 추출한다. 즉, forward pass에서는 kxk kernel과 stride에 맞춰 feature map(input data)을 돌아다니며 계산하지만 back propagation에서는 하나의 Weight집합과 bias만 학습한다.
pooling
💁♀️ 한번 conv 통해 feature map이 생성되면 위치 정보의 중요성이 떨어진다.
각 특징의 위치 정보는 패턴을 식별하는 것과는 무관하고, 입력값에 따라 특징이 나타나는 위치가 다를 가능성이 높아 위치 정보는 잠재적으로 유해하다.
따라서 feature map에서 특징들의 위치에 대한 정확도를 감소시키기 위해 pooling(sun-sampling)을 통해 feature map의 해상도를 감소시켰다.
이때 LeNet5은 average pooling을 수행해 해상도는 감소하고 distortion & shift에 대한 민감도를 감소시켰다.
또한 위치 정보에 대한 손실은 feature map size가 작아질수록 더 많은 filter를 사용하여 다양한 feature를 추출하여 상호보완하도록 하였다.
AlexNet - 2012
AlexNet란
Alex Khrizevsky가 발표한 'ImageNet Classification with Deep Convolutional Neural Networks'에서 소개된 모델이다.
AlexNet 2012년에 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회의 우승을 차지한 컨볼루션 신경망(CNN) 구조이다.
즉, CNN의 부흥에 아주 큰 역할을 한 구조라고 말할 수 있다- https://bskyvision.com/421
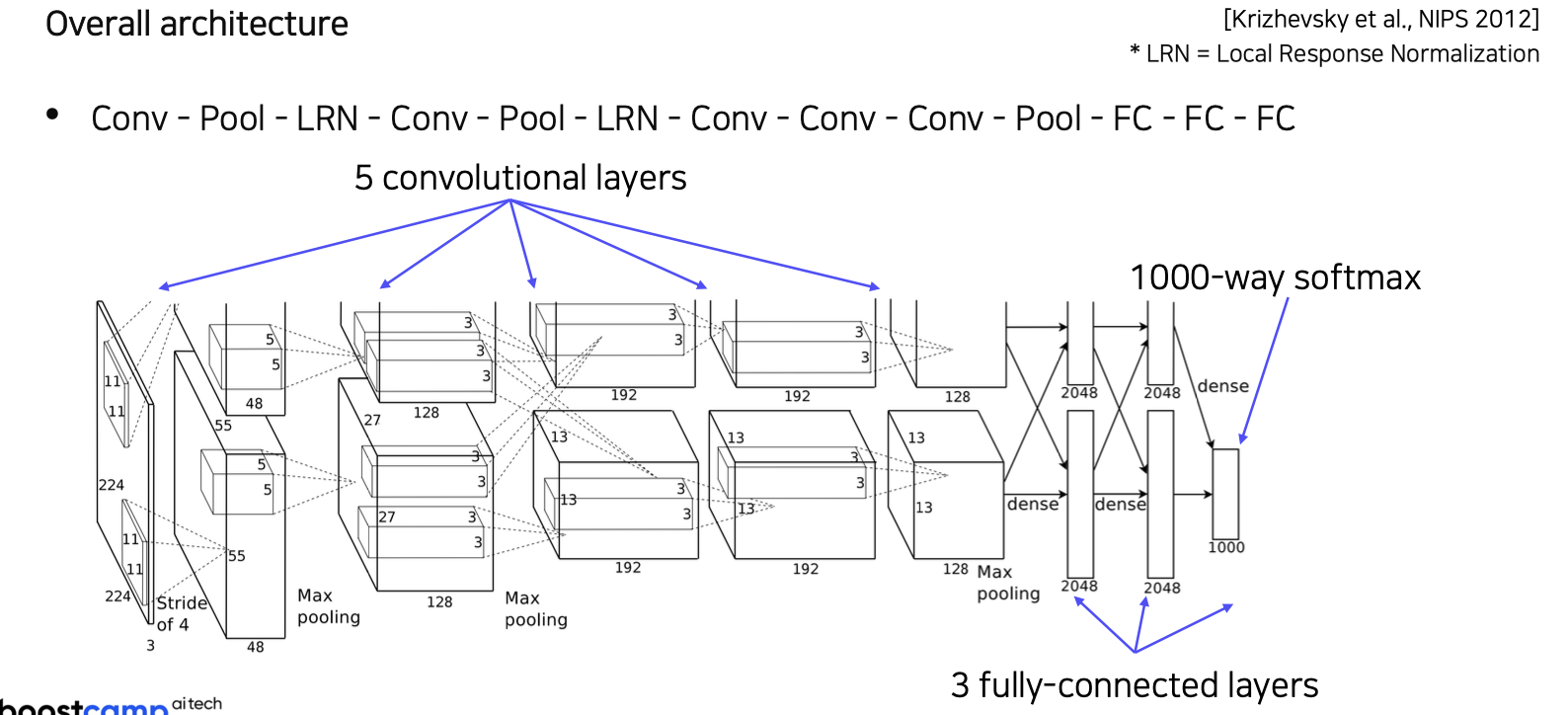
🆀 LeNet-5와 차이점은 무엇일까?
🅰 기본 구조는 유사하나 아래와 같은 차이점이 있다.
- ReLU 함수를 사용하여 gradient vanishing 문제 완화
- 2개의 GPU로 병렬연산을 수행하기 위한 병렬적인 구조
- Local Response Normalization
- overlapping pooling
- Data argumentation(1.2 millions의 ImageNet 학습) & regularization(정규화) 기술인 Dropout 사용
- 11x11 convolution filter 사용
- 7개의 hidden layers, 605K neurons, 60million parameters로 더 커진 모델
AlexNet의 전체 구조
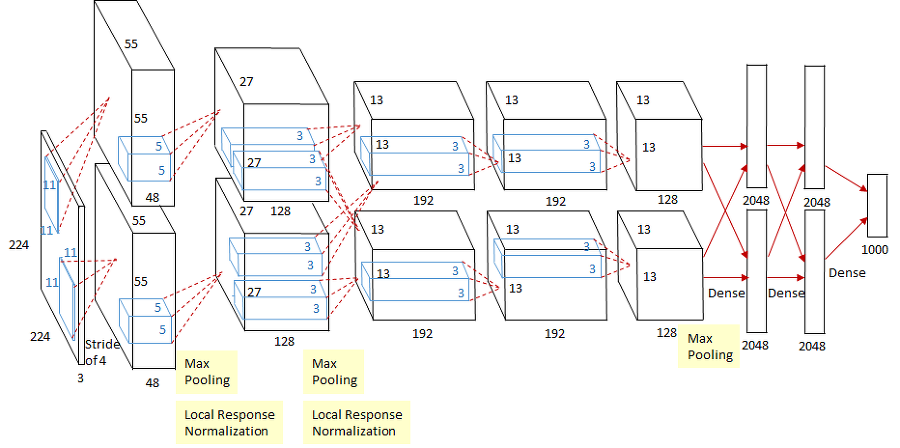
ReLU함수를 사용한 이유?
🆀 ReLU함수를 사용한 이유?
🅰 sigmoid나 하이퍼볼릭탄젠트는 신경망이 깊어질 수록 기울기가 소멸되는 문제 가 발생함
sigmoid 함수는 x값이 작아짐에 따라 기울기가 거의 0으로 수렴하고, 하이퍼볼릭탄젠트 함수도 x값이 커지거나 작아짐에 따라 기울기가 크게 작아지기 때문에 gradient vanishing이 발생한다
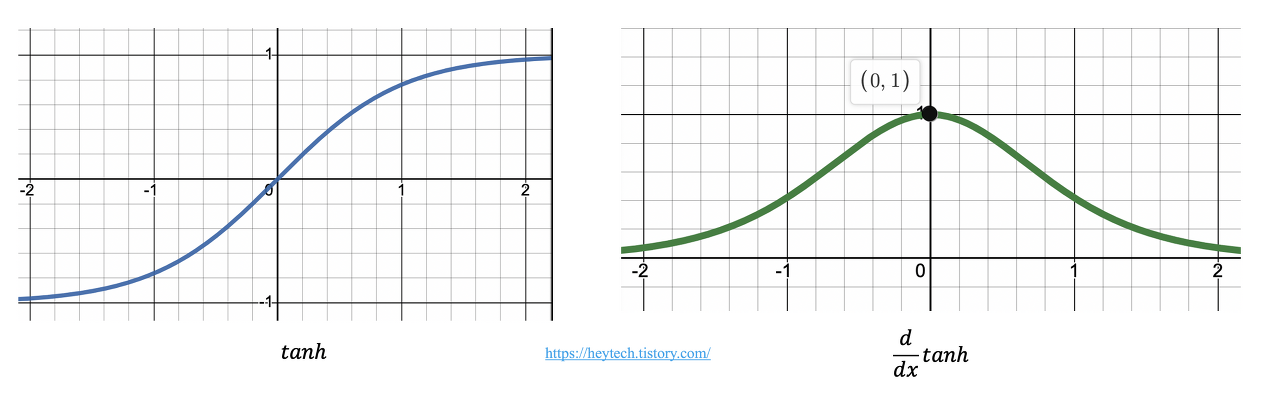
또한 singmoid나 하이퍼볼릭탄젠트 함수는 미분을 위해 연산이 필요한 반면 ReLU함수는 단순 인계값이므로 미분이 쉽다.
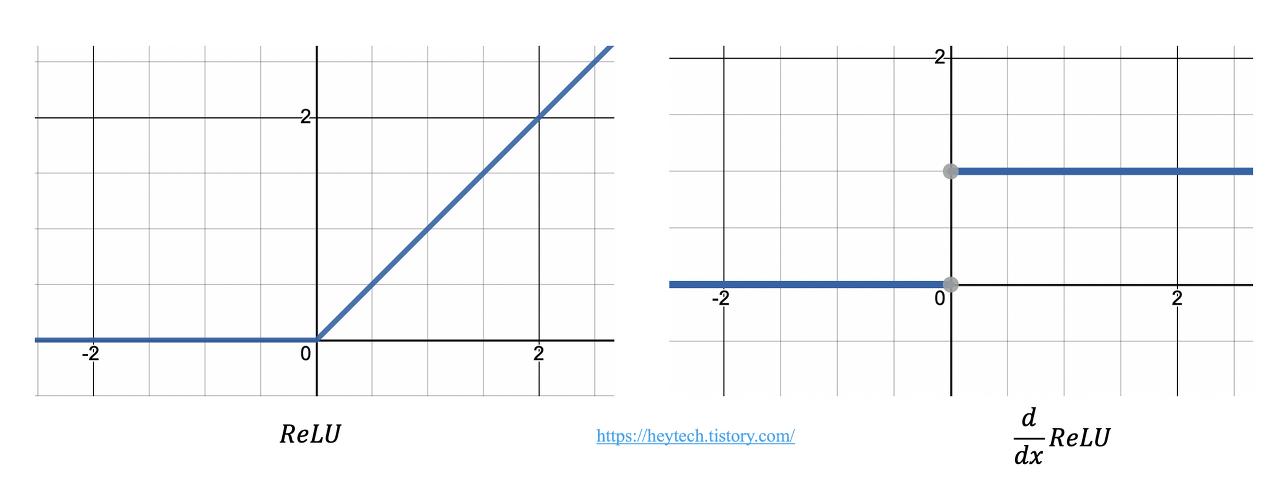
ReLU함수는 정확도를 유지하면서 Tanh보다 6배가 더 빠르고, gradient vanishing 문제 완화된다
AlexNet 이후로는 ReLU를 사용하는 것이 선호되었다.
Local Response Normalization 사용한 이유?
🆀 Local Response Normalization 사용한 이유?
🅰 ReLU함수는 일부 가중치의 출력값이 주변 가중치에 비해 매우 클 수 있기 때문에 그 값을 주변 가중치와 비슷하게 맞춰주는 정규화 방법이다.
-
즉, Excited neuron은 주변에 있는 다른 뉴런에 비해 훨씬 민감하기 때문에 Excited neuron의 주변 뉴런으로 정규화시켜 Excited neuron을 subdue 한다
-
LRN을 사용하면 feature map의 명암을 정규화 시켜준다고 생각하면 된다
-
LRN을 적용했을 때의 변화와 유사한 이미지이다

💁♀️ 이후 모델에서는 LRN은 사용되지 않고 batch nomalization을 사용한다
overlapping pooling
🆀 overlapping pooling이란?
🅰 CNN에서 pooling은 feature map의 크기를 줄이기 위함이고, overlapping pooling은 pooling kernel이 움직이는 보폭인 stride를 커널 사이즈보다 작게 하는 것이다.
💁♀️ LeNet-5에서는 non-overlapping average pooling이 사용하여 반면에 AlexNet은 overlapping maxpooling을 이용하였다.
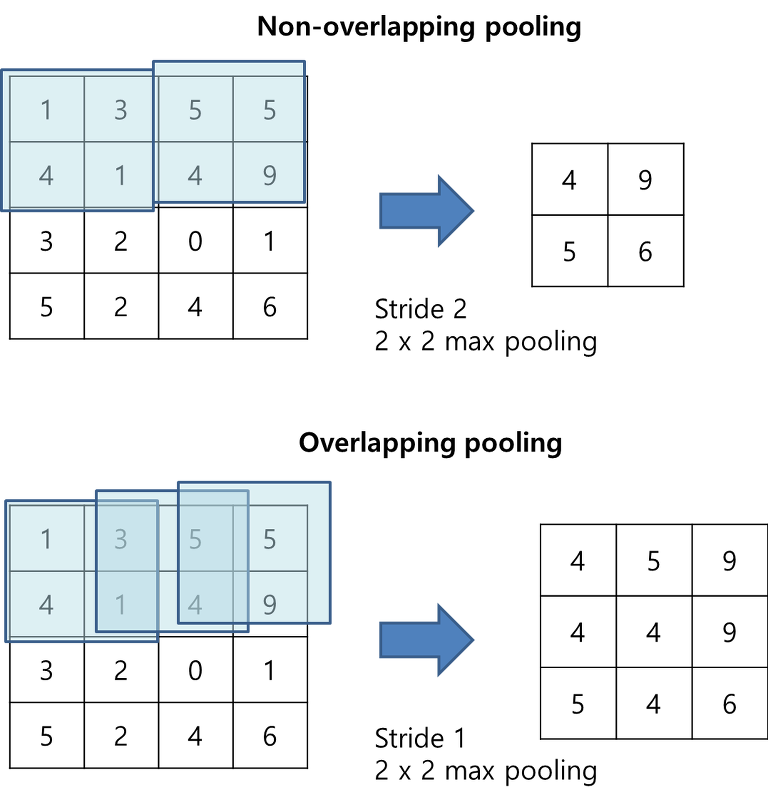
🆀 overlapping pooling을 왜 사용했을까?
🅰 overlapping pooling을 하면 pooling kernel이 중첩되면서 top-1, top-5 에러율을 줄이는데 효과가 있다
💁♀️ top-1, top-5 에러율은 이미지 분류의 성능을 평가하기 위한 에러율이다
- top-1 : 분류기가 예측한 클래스 중 top1이 실제 클래스와 같을 경우의 error
- top-5 : 분류기가 예측한 클래스 중 top5 중에 실제 클래스가 있을 경우의 error
Dropout
💁♀️ over fitting을 막기 위한 규제 기술의 일종이다, fully connected layer의 뉴런 중 일부 뉴런 값을 0으로 바꿔버리면서 학습을 진행하는 것이다.
0이 된 뉴런들은 forward pass back propagation에는 아무런 영향을 미치지 않는다.
Data argumentation
💁♀️ over fitting을 막기 위한 또 다른 방법으로 데이터에 변형을 주어 데이터의 양을 늘리는 것이다
💁♀️ LesNet-5rk 6만개의 파라미터 인것에 비해 AlexNet은 6천만개의 파라미터로 천배 많아졌기 때문에 그만큼 많은 학습 데이터가 필요하다.
11x11 convolution filter
🆀 왜 11x11 kernel을 사용했을까?
🅰 receptive field size를 키우기위해 필터 사이즈를 키웠으나
Larger size filters are used to cover a wider range of the input image
더 넓은 범위의 입력 이미지를 커버하기 위해 더 큰 크기의 필터가 사용됩니다.
🆀 일부에서만 activation map(feature map)이 cross하는 이유는 무엇일까?
🅰 모든 부분에서 cross하면 시간이 오래 걸리기 때문에 일부에서만 수행했다고 한다.
🆀 Fully connected Layers 넘어가기 전 vector화된 tensor의 크기는 어떻게 될까?(2,3D -> 1D로 변환하는 과정)
🅰 2개로 병렬적으로 학습했기 때문에 vector화 과정에서 2048이 아닌 2048X2인 4096개가 된다.
VGGNet - 2014
VGGNet란
옥스포드 대학 연구팀이 발표한 Very Deep Convolutional Networks for Large-Scale Image Recognition 논문에서 소개된 모델이다.
VGG-16 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥러닝 관련 대표적 연구 중 하나로 자리매김하였다.
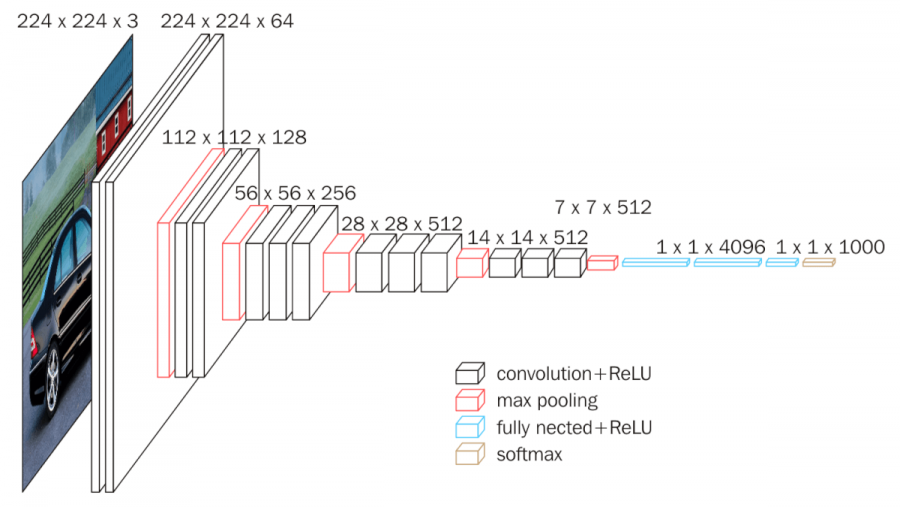
💁♀️ 해당 논문의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하고자 한것이다.
🆀 AlexNet와 차이점은 무엇일까?
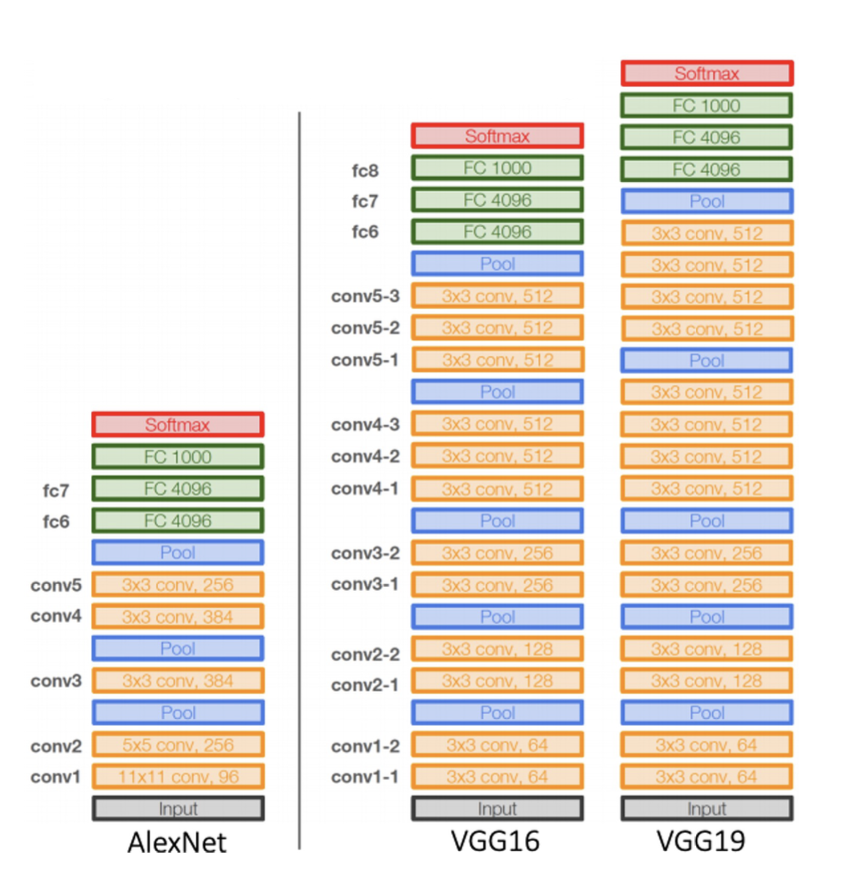
- 오직 3x3 filter, 2x2 max pooling 통해 깊은 네트워크를 만들었다.
- local response normalization를 사용하지 않았다.
💁♀️ AlexNet보다 2배 이상 깊은 네트워크의 학습 성공하였으며 ImageNet Challenge에서 AlexNet의 오차율을 절반(16.4 > 7.3)으로 줄였다.
💁♀️ VGG는 간단한 모델에 배해 높은 결과물을 보여줬음.
VGGNet의 특징
- 3x3 filter, 2x3 max pooling
- local response normalization
3x3 convolution
💁♀️ 3x3 filter를 통해 네트워크의 깊이 16층, 19층 등으로 깊이를 깊게 만들어 성능을 높였다.
🆀 어떻게 16–19 레이어와 같이 깊은 신경망 모델의 학습을 성공했을까?
🅰 filter 사이즈가 크면 이미지의 사이즈가 금방축소 되기 때문에 네트워크의 깊이를 충분히 깊게 만들지 못하지만 모든 convolution layer에서 3x3 filter만 사용하여 네트워크를 깊게 만들었다.
🆀 왜 모든 Convolutional layer에서 3x3 필터만 사용했을까?
🅰 VGG 이전 모델들을 큰 receptive field를 갖기 위해 11x11, 7x7 filter를 사용하였으나 VGG는는 3x3 filter를 반복적으로 사용하여 7x7 filter의 효과를 보았다. 2x2 max pooling를 통해 receptive field 사이즈를 충분히 크게 유지할 하고,
💁♀️ 7x7 filter 1번 수행 VS 3x3 filter 3번 수행
1. 결정 함수의 비선형성 증가
- conv 연산은 ReLU 함수 적용을 포함하므로 7x7 filter 1번 수행은 ReLU 함수 적용을 1번 수행하고, 3x3 filter 3번 수행은 ReLU 함수 적용을 3번 수행한다. 따라서 레이버가 증가함에 따라 비선형성이 증가하고 모델이 특징을 더 잘 식별할 수 있다.
- parameter 수 감소
- 7x7 filter 1개의 parameter 수는 7x7x1 = 49이고, 3x3 filter 3개의 parameter 수는 3x3x3 = 27로 파라미터 수가 크게 감소한다.
💁♀️ 네트워크의 깊이가 깊어지면 feature map은 동일한 receptive field에 대해 더 추상적인 정보를 담게 되므로 주의해야한다.
local response normalization 사용하지 않은 이유
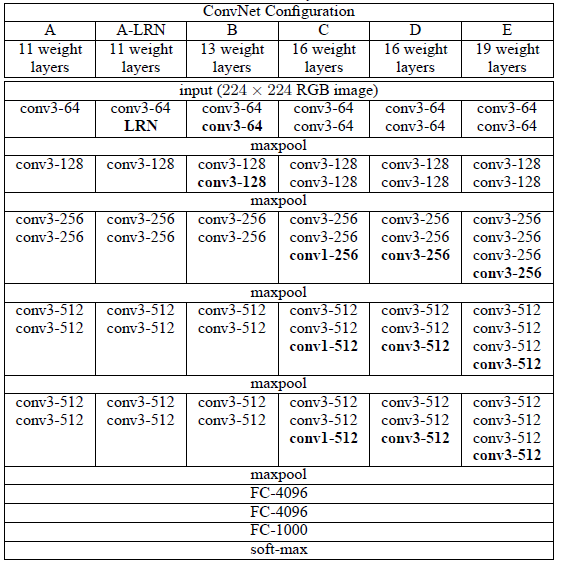
💁 VGG연구팀은 A와 A-LRN 구조의 성능을 비교함으로서 성능향상에는 별로 효과가 없다고 실험을 통해 확인했다
VGG의 한계점
💁♀️ 더 깊은 네트워크는 더 큰 capacity(수용성)와 non-linearity(비선형성) 가능하게 한다. 또한 더 큰 receptive fields를 가지게 해 neural network는 더 깊어지고 더 넓어졌다.
🆀 하지만 더 깊어지는게 더 넓어지는게 반드시 좋을까?
🅰 렐루 함수를 통해 Gradient vanishing 문제를 어느정도 해결했지만 더 깊어진 network는 gradient vanishing(경사소실)과 exploding(경사폭발)을 유발해 최적화를 더욱 힘들게 하며 계산복잡도(computationally complex)가 더욱 늘어난다.
🆀gradient vanishing(경사소실)과 exploding(경사폭발)이 일어나면 어떤 결과 나타날까?
🅰 더 깊은 네트워크는 over-fitting(오버피팅)을 부를것이라는 예측과 다르게 실제로는 Degradation problem을 발생시킨다
Degradation problem
🆀 Degradation problem은 무엇일까?
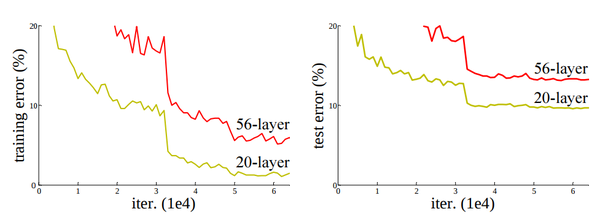
🅰 정확도가 어느 순간 정체 되고 layer가 더 깊어질수록 성능이 더 나빠지는 형상을 말한다.
- Depth가 깊은 상태에서 학습을 이미 많이 진행한 경우 weight들의 분포가 균등하지 않고, Back Propagation시에 기울기가 충분하지 않아 학습을 안정적으로 진행할 수 없는 문제가 발생한다.
- 이것이 over-fitting이라고 생각할 수 있지만 over-fitting은 train data에서는 모델의 성능이 좋은 반면에 test data에서는 성능이 좋지 않은 경우이다.
- 그와 다르게 20-layter보다 56-layer 모델의 성능이 train data, test data에서 모두 더 안 좋은 것을 보면 over fitting 문제가 아니라는 것을 알 수 있다. 즉, optimization이 제대로 적용되지 않는 것이다.
- 또한 layer가 깊어지면서 파라마터 수가 많아져 training error가 증가한다
Epilogue
🆀 그렇다면 이후 모델들은 Degradation problem를 어떻게 해결했을까?
🅰 다음 장에서 Degradation을 해결한 모델인 GoogLeNet,ResNet 등을 소개할 것이다.
-참고-
