
2024.12.21
1. MNIST 데이터
2. MNIST_Fashin 데이터
딥러닝을 이용한 MNIST
- MNIST 데이터에 대해서는 kNN에서 설명이 나옴. 링크 : PCA #5
데이터 읽기 (TensorFlow)
One-Hot-Encoding
- MNIST 데이터 역시 0~9까지의 숫자
- 그런데 또 하나의 방법인 loss 함수를
sparse_categorical_crossentropy로 설정하면 동일한 효과이다. (저절로 One-Hot-Encoding 진행된다)
모델의 구조
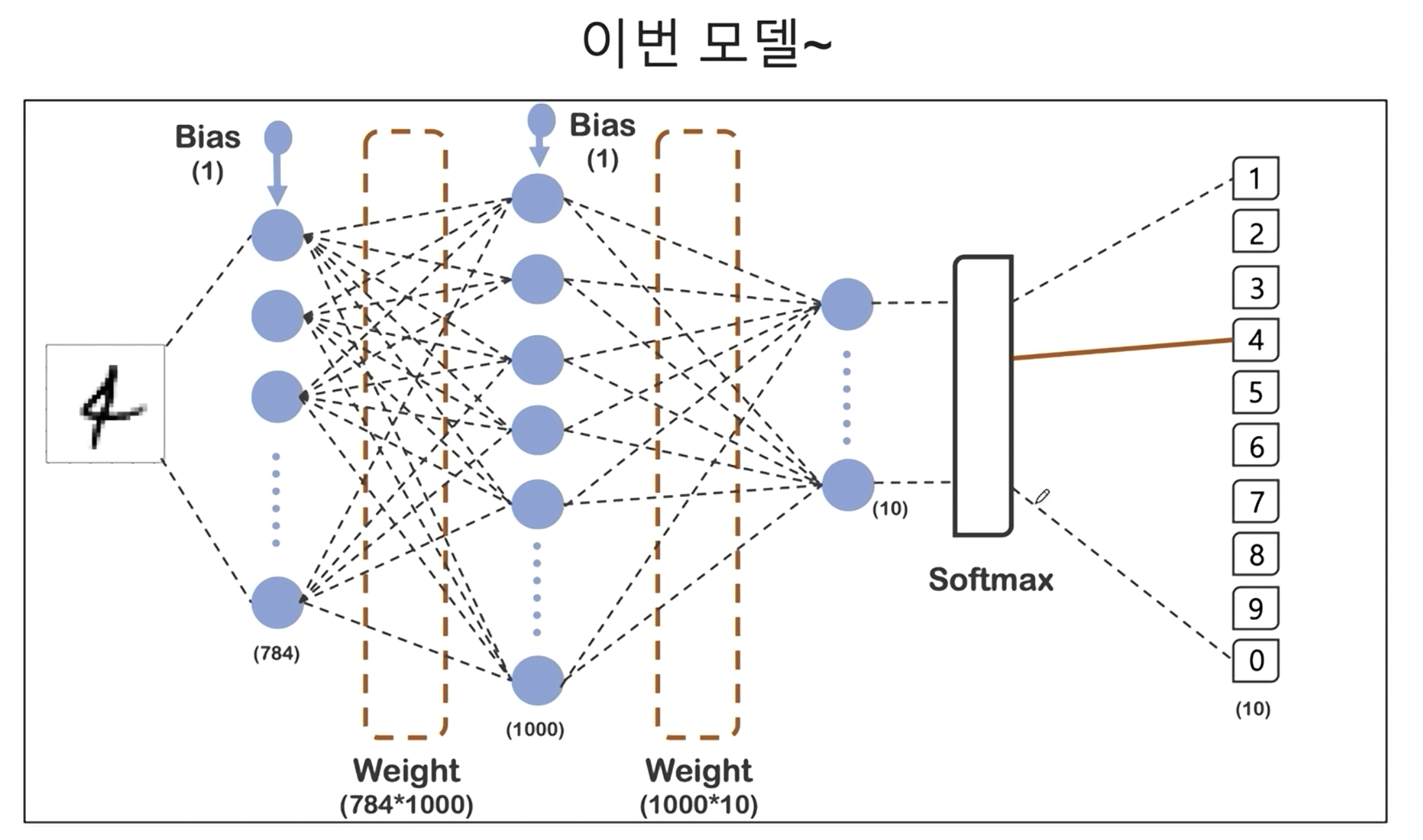
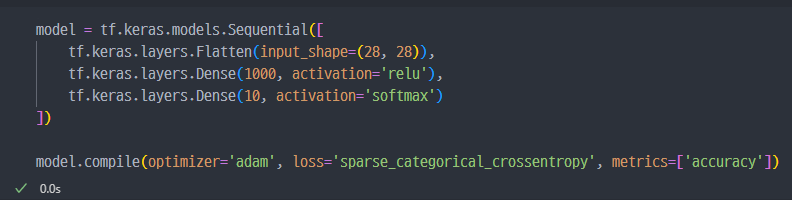
모델 작성
softmax: Multi-Class Classification with NN and SoftMax Function
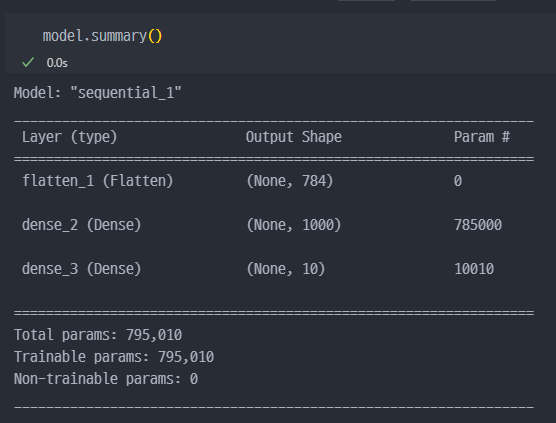
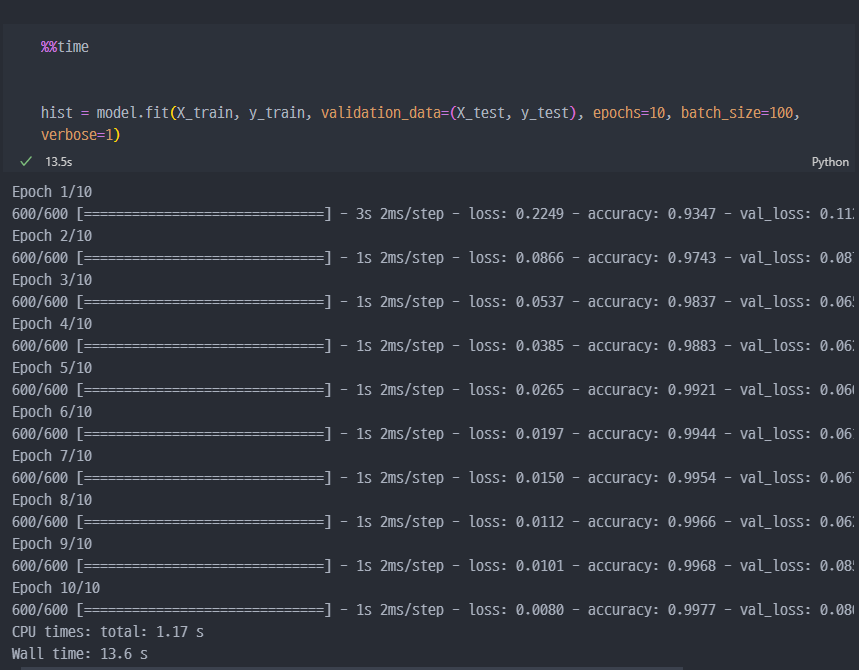
학습진행
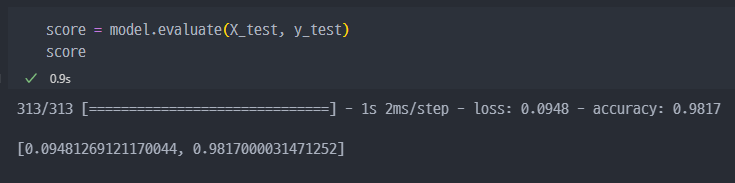
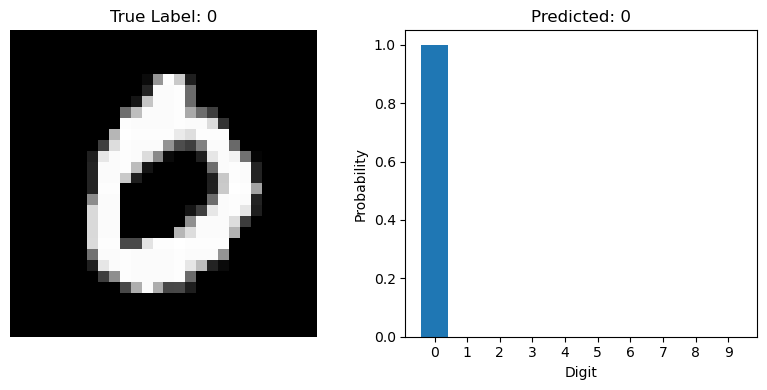
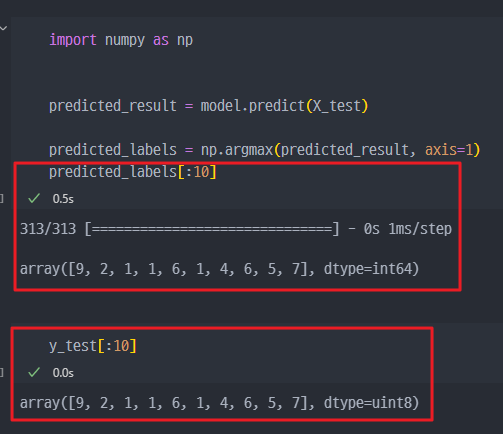
predict_result
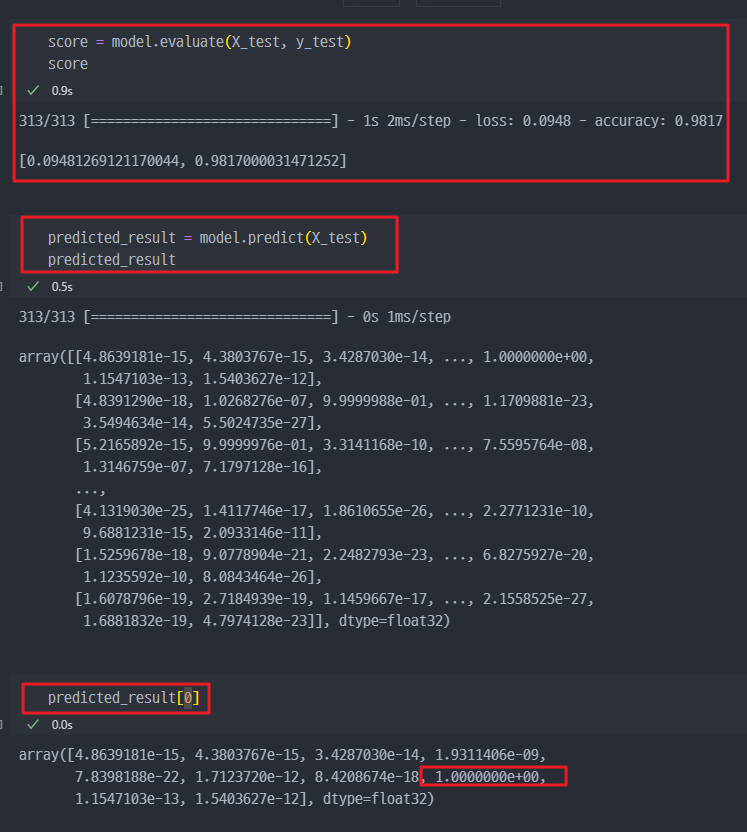
[0]에 대한 결과는 7이다 ( 7번째 값이 제일 1에 가까움)
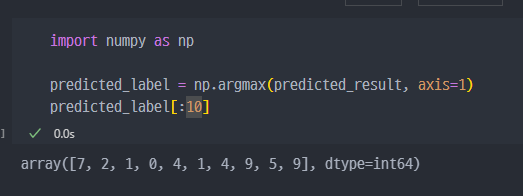
가장 높은 숫자 확인 -> argmax() 함수 적용
predict한 숫자가 무엇인지 10개 조회
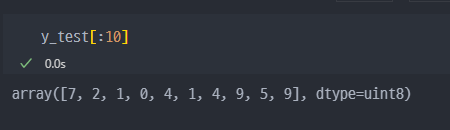
y_test와 비교
y_test와 predict 비교
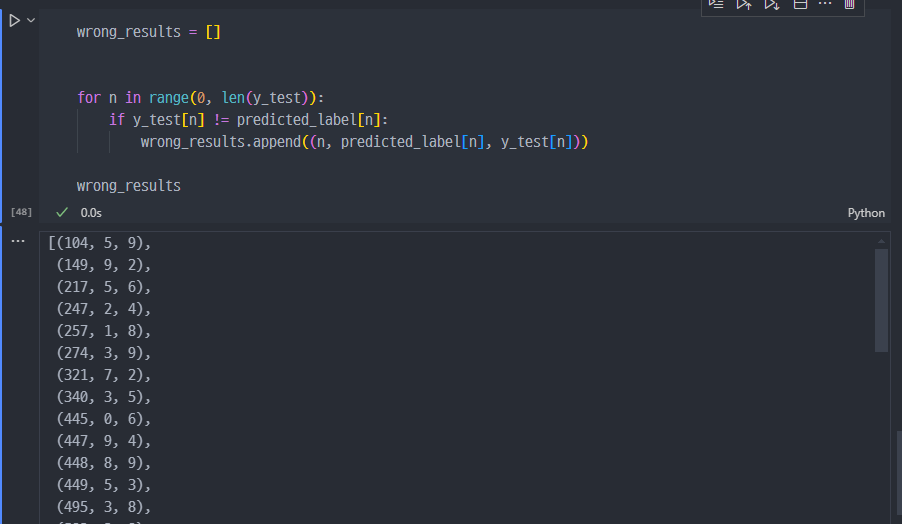
결과비교 1번방법
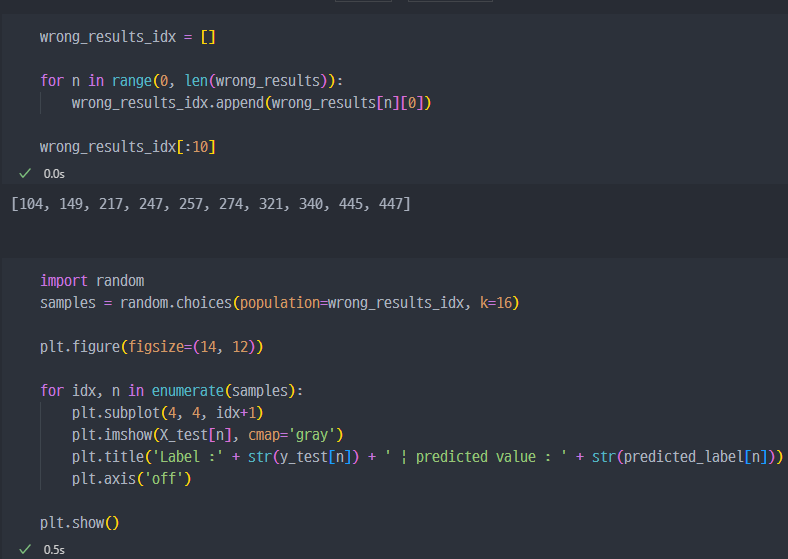

결과비교 2번방법
MNIST fashion data

데이터 읽기
Train,Test데이터를 255로 나누는 이유
정규화의 이유와 효과
1) 픽셀 값의 범위
- MNIST 데이터는 28x28 크기의 흑백 이미지로 구성되며, 각 픽셀 값은 0에서 255 사이의 정수 값입니다.
- 0: 검은색
- 255: 흰색
- 이렇게 큰 범위의 값을 사용할 경우, 모델이 각 픽셀 값의 중요도를 학습하는 데 시간이 오래 걸릴 수 있습니다.
2) 정규화의 의미
- Normalization Value =
- 이를 통해 모든 픽셀 값이 0~1 사이의 범위로 변환됩니다:
- 0은 0, 255는 1.
3) 정규화의 장점
학습 안정화: 큰 값은 경사 하강법(gradient descent)을 수행할 때 급격한 변화(폭발적 그라디언트 문제)를 유발할 수 있습니다. 이를 방지하고 학습이 안정적으로 이루어집니다.더 빠른 수렴: 정규화된 데이터는 더 빠르게 수렴하며, 학습 속도가 빨라질 수 있습니다.모델 성능 향상: 정규화는 신경망의 가중치와 편향이 적절히 조정되도록 도와주어 일반화 성능이 향상됩니다.숫자의 일관성 유지: 다른 특성과 함께 사용할 경우, 데이터가 정규화되면 숫자의 상대적 크기를 유지하며 비교하기 쉬워집니다.

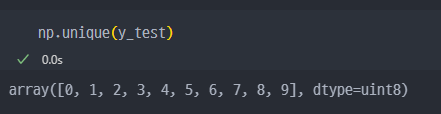
모델작성
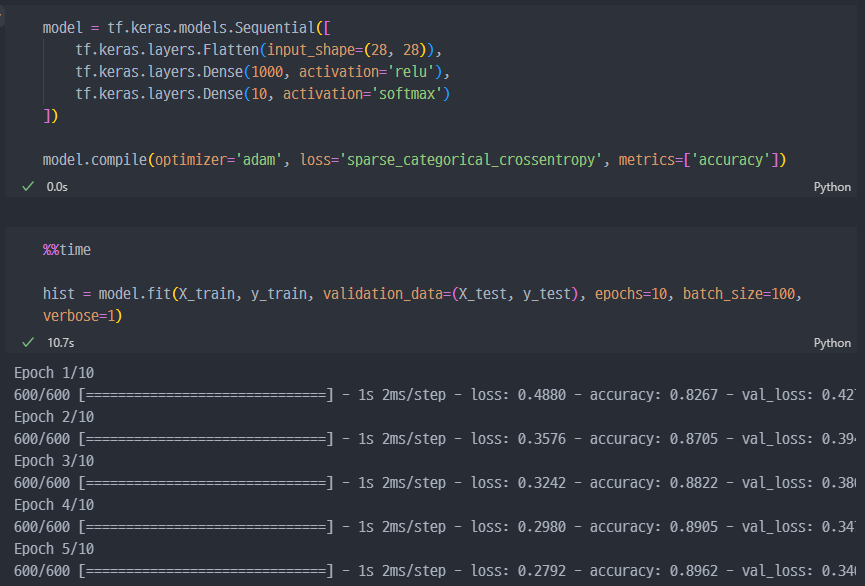
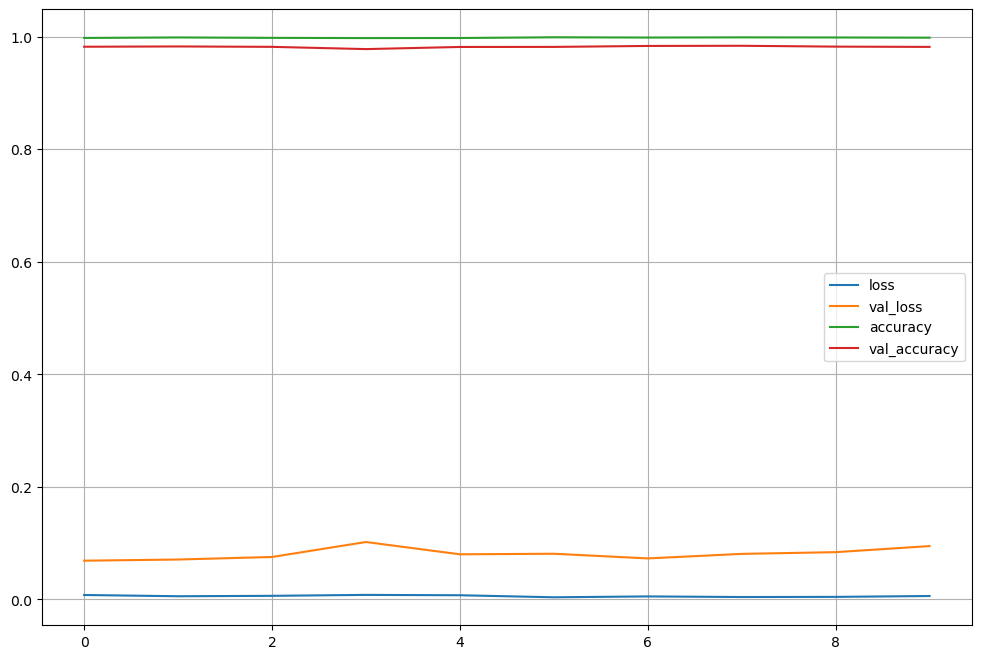
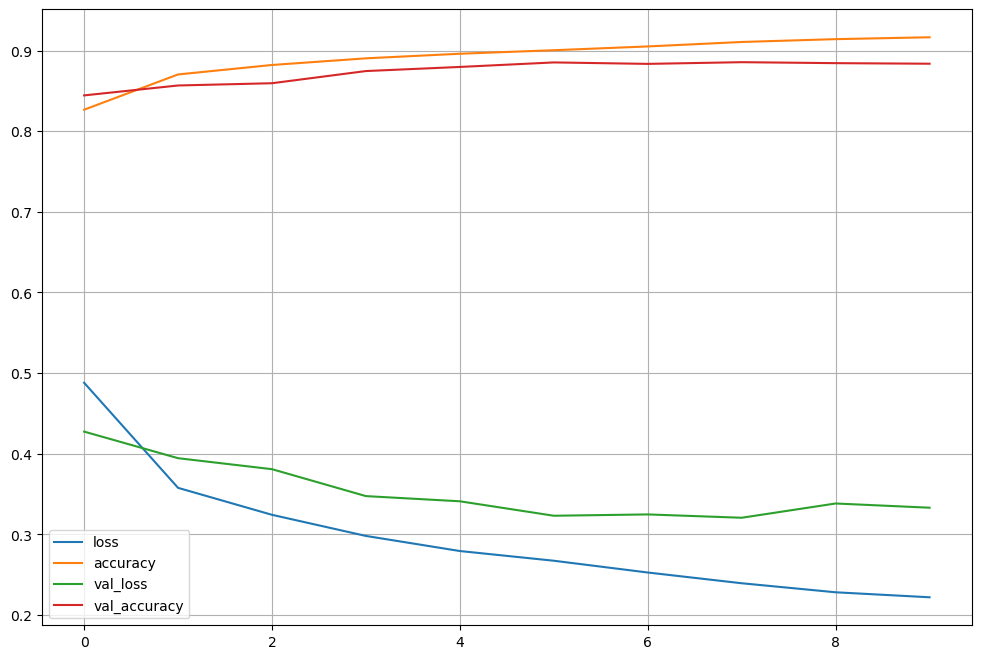
loss, accuracy 그래프 확인
wrong 데이터 확인
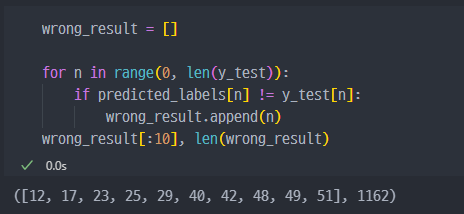
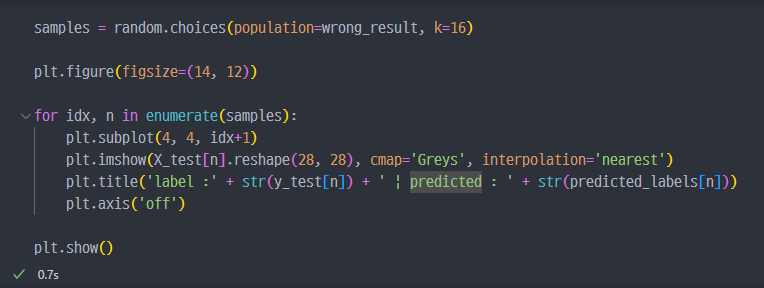


(hellow. world)