
2024.11.10
Credit Card Fraud Detection : 실습
Credit Card Fraud Detection
개요
신용카드 부정 사용 검출에 관한 데이터이다.- 논문 등에서 자주 다루는 주제
- 신용카드와 같은 금융 데이터들은 구하기가 쉽지 않음.
- 그러나 지능화되어가는 현대 범죄에 맞춰 사전 이상 징후 검출 등 금융 기관이 많은 노력을 기울이고 있음.
- 이 데이터 역시, 센서를 이용한 사람의 행동 과정 유추처럼
Machine Learning이용 분야 중 하나.
- Data 다운로드 -
Kaggle, Credit Card Fraud Detection 홈페이지
데이터 개요
- 신용카드 사기 검출 분류 실습용 데이터
- 데이터에
class라는 이름의 컬럼이 사기 유무를 의미 class컬럼의 불균형이 극심해서 전체 데이터의 약 0.172% 가 1 (사기 Fraud)을 가짐
- 또한 금융 데이터이고, 기업의 기밀 보호를 위햄 대다수 특성의 이름은 삭제되어 있음
Amount: 거래금액Class: Fraud or Not 구분 ( 1이면 Fraud )

데이터 받아오기
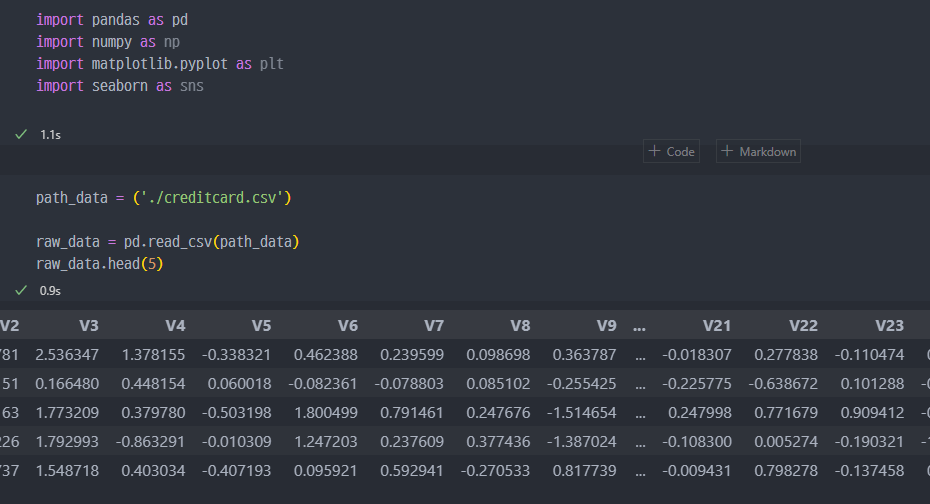
- 데이터 받아와서 확인.
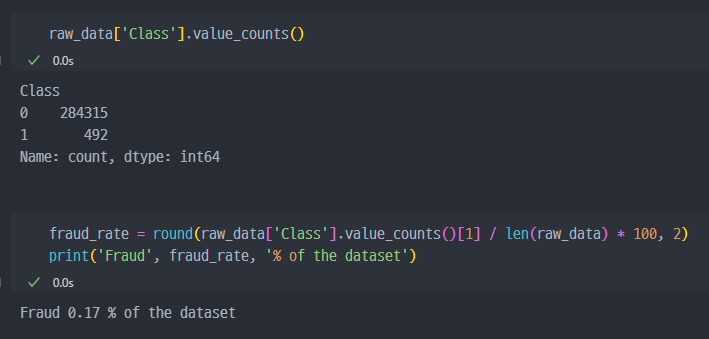
Class컬럼에 있는 0과 1(Fraud)의 개수 확인Fraud로 검출되는 것이 492개 밖에 안된다. ( 전체 중 0.17% )
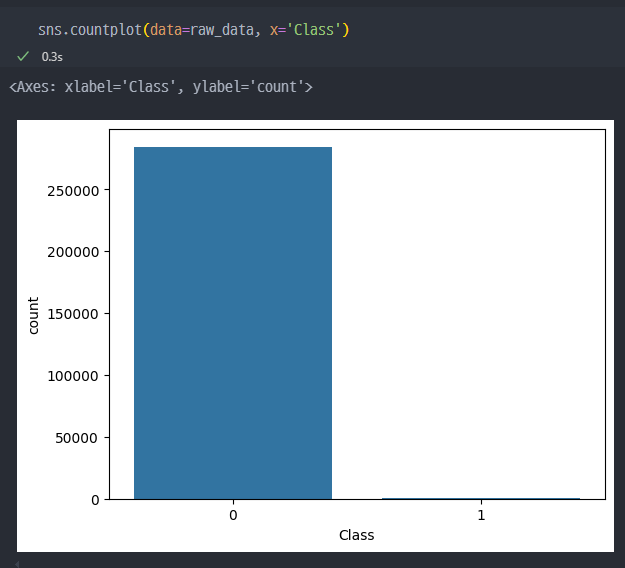
- 그래프로 표현 시, 보다 더 명확하게 차이를 알 수 있다.
데이터 나누기 (X, y)
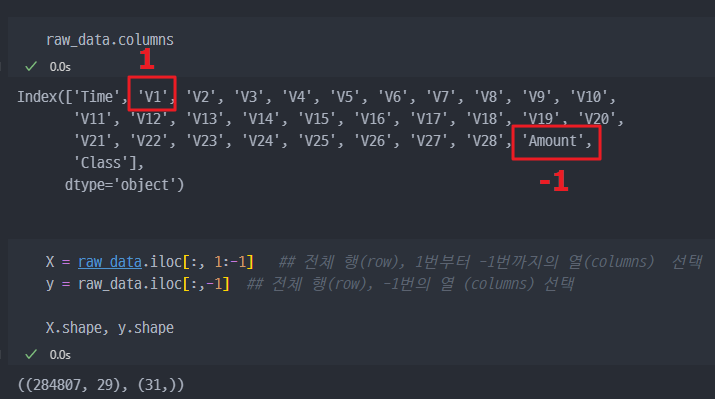
- X, y 데이터 (feature 와 정답값 데이터 나누기)
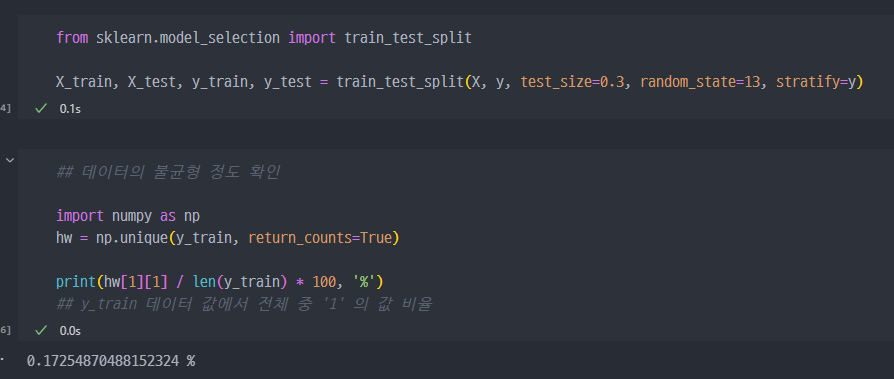
- y_train 데이터에서 전체 데이터 개수 중 1인 값의 비율 확인 (데이터 불균형 확인)
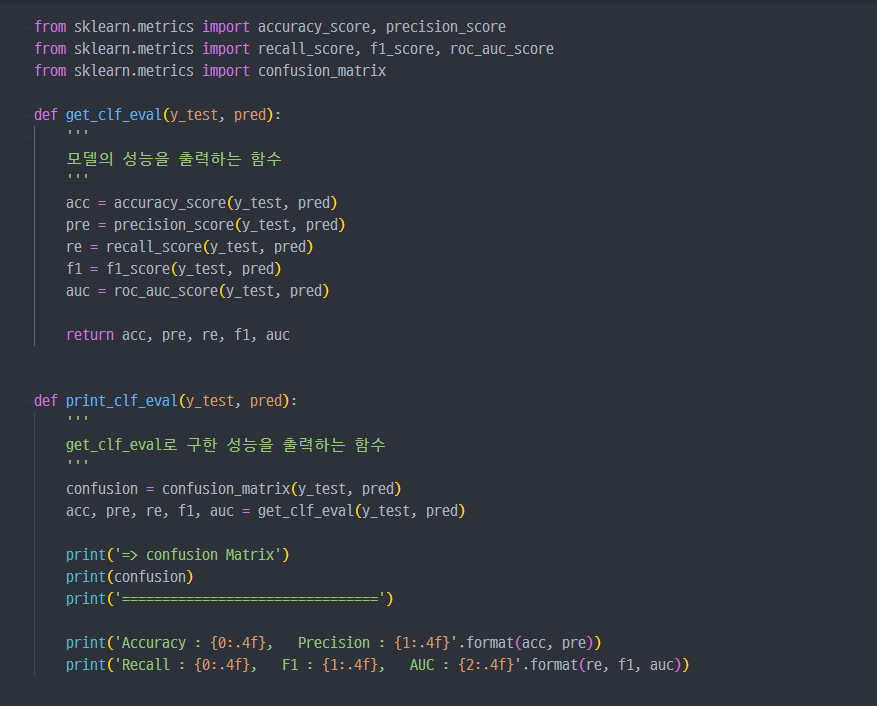
- 모델의 성능을 출력하는 값들을 함수로 만들어서 사용.
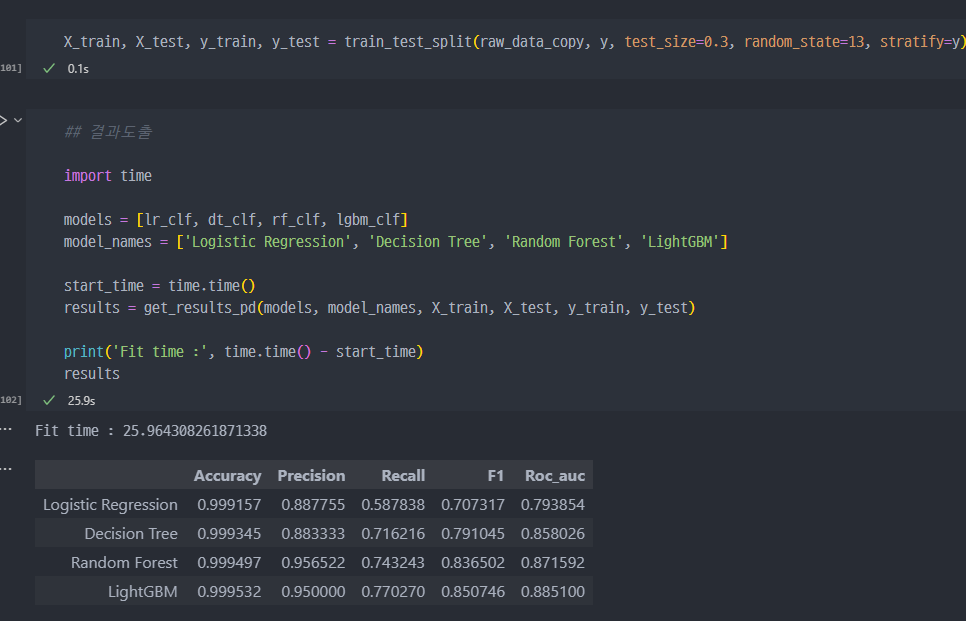
Trial 1 - 전처리 없이 진행
logistic Regression

- Logistic Regression으로 모델링 진행 및 성능 확인.
- Accuracy 가 99%로 출력됨.
-
하지만,
Confusion Matrix를 보면... 85284개는0을0으로 맞추고, 11개는0을1로 잘못 예측하였고,
60개는1을0으로 잘못 예측하였으며, 88개는1을1로 예측함. -
Accuracy는 99%로 매우 높지만,recall을 보면 60%가 안된다. 이 말은1을1이라고 예측한 값이 절반정도라는 것. -
모델의 예측성능을 더 끌어올려야 함을 알 수 있음.
recall은 '실제 양성'인 데이터 중에서 모델이 이를 올바르게 양성으로 예측한 비율을 의미합니다
Decision Tree

- Decision Tree를 이용해서 모델링한 결과
recall성능이 조금 더 개선된 것으로 보인다.
Random Forest - Ensemble
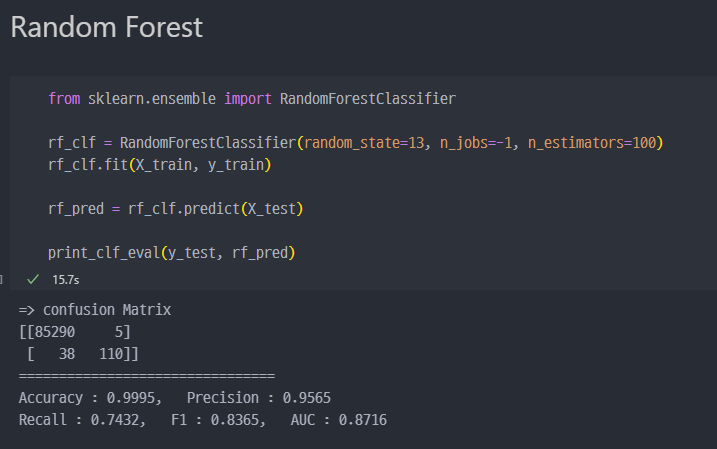
Random Forest로 진행시,recall이 74%로 조금 더 상승한 것을 알 수 있다- 또한, 148개 중에서 110개가 양성을 양성으로 예측한 (바르게 예측) 것을 알 수 있다.
lightGBM
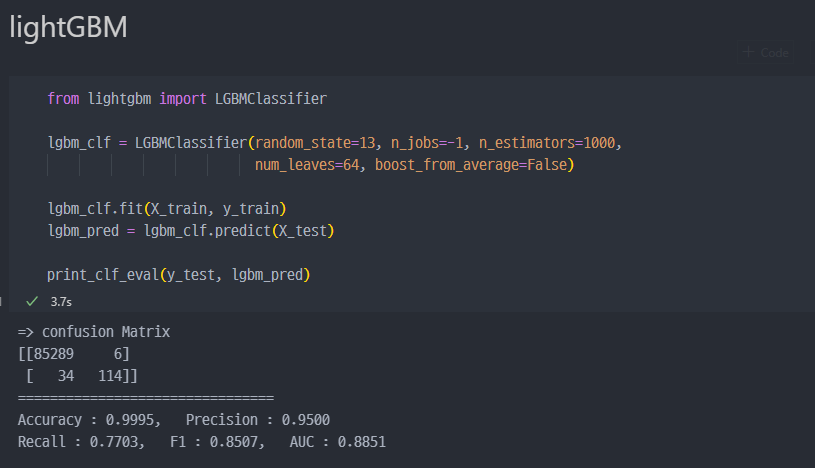
lightGBM으로 진행 시recall이 77%까지 상승되니, 더욱 성능이 개선된다는 것을 알 수 있음.
은행 입장에서는
Recall이 높은 것이 좋을 것이다.Fraud를 잘 적발할 수 있으니..
사용자 입장에서는Precision이 높은 것이 좋을 수 있다. 왜냐하면, 정상 사용자이나Fraud로 의심받는 상황이 낮아진다.
DataFrame으로 정리
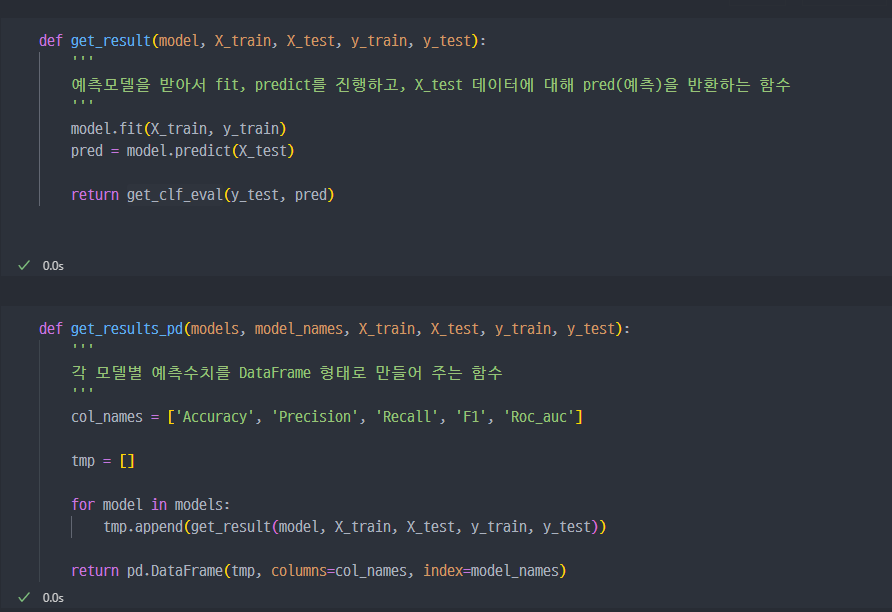
- 모델별 수치값을 데이터프레임 형태로 만드는 함수 생성
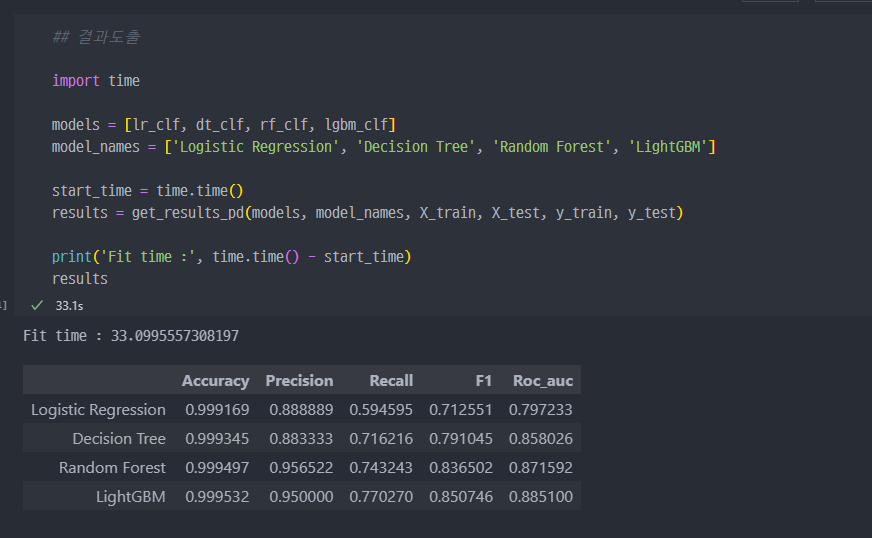
- 위에서 진행했던 4가지 예측모델에 대해서,
DataFrame형태로 받아온 것.
Trial 2 - Scale 적용
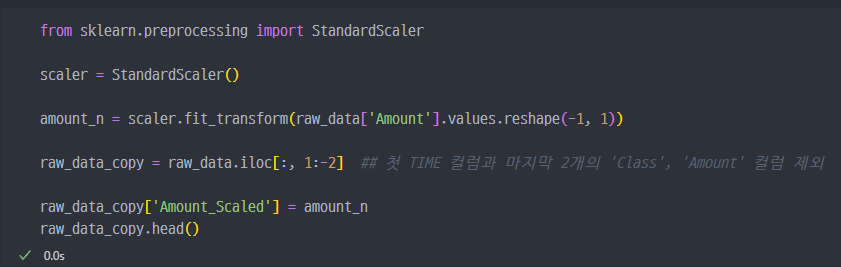
StandardScaler 적용
- Amount 를 보면 특정 구간에만 데이터가 몰려있음을 알 수 있다.

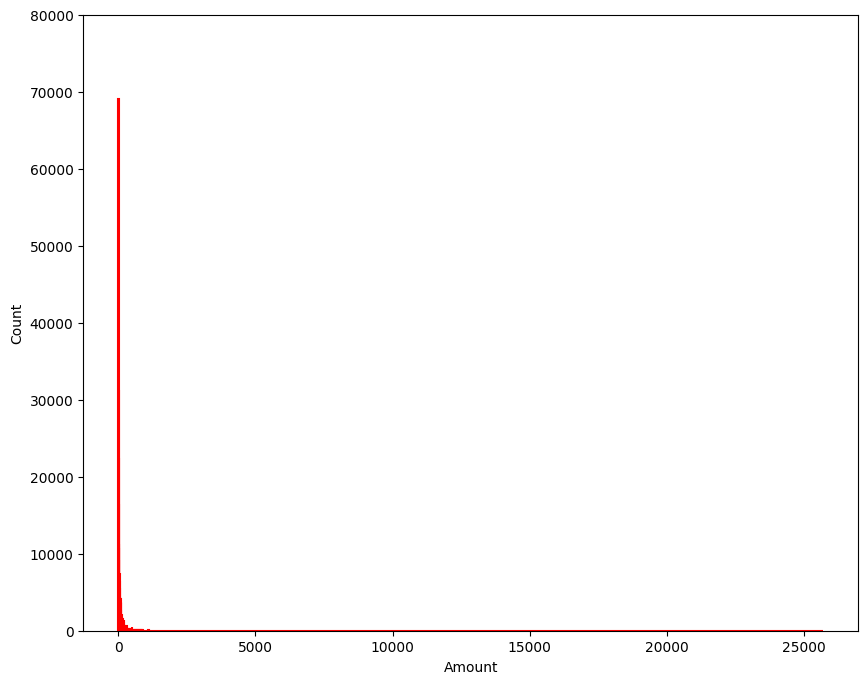
- 그래프로 보면,
Amount, 즉 사용금액이 적은 구간에 대부분이 몰려있는 것을 확인할 수 있다.
- Scaled 된
Amount값을raw_data_copy에 추가
Scaled 된 데이터 모델링
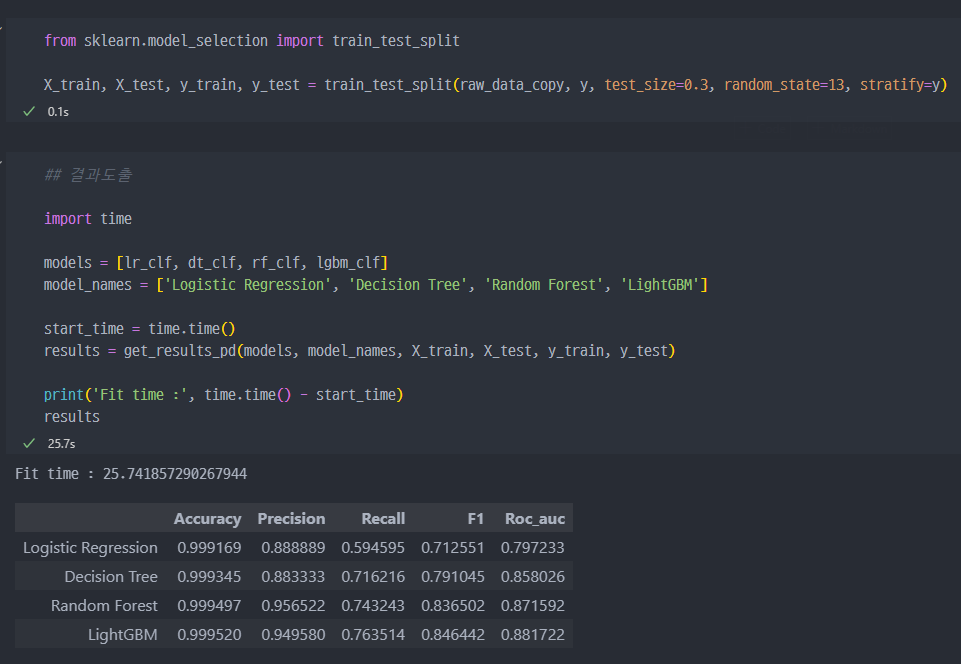
- Scaled된 데이터로 모델링 진행했지만,
recall수치에서는 큰 변화는 없다.
roc_curve
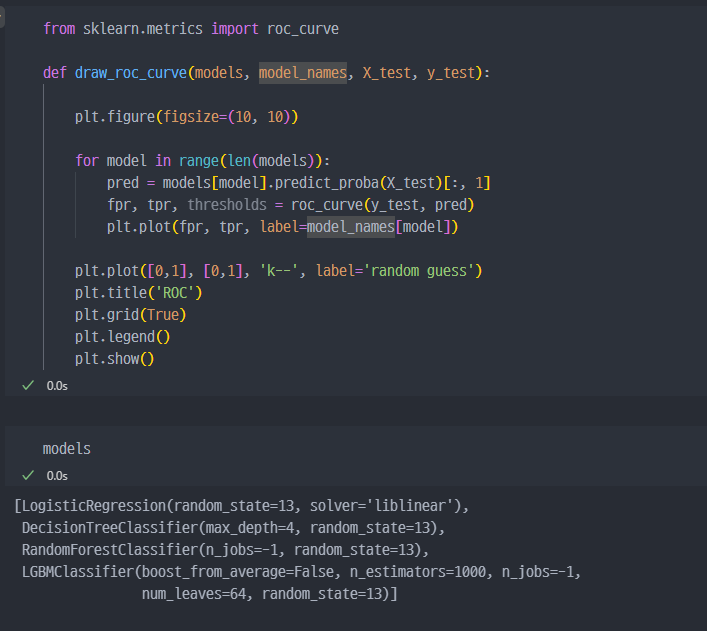
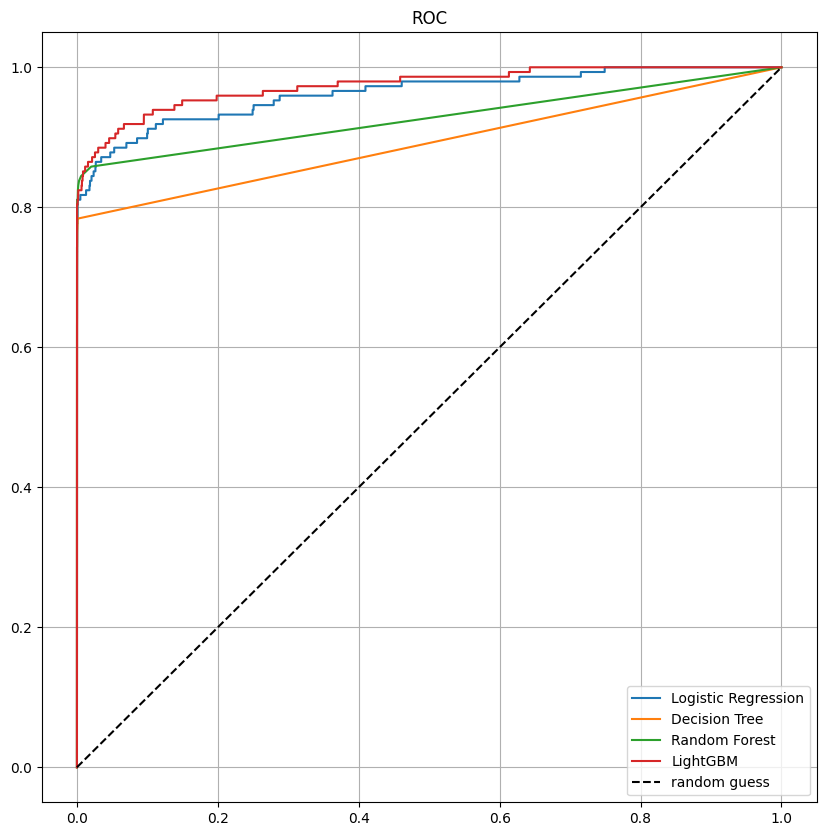
- LightGBM이 제일 좋아보인다.
log scale 적용
Amount값에log를 적용해서 Scale 해본다.- 결과에 어떤 영향을 미치는지 비교해본다.
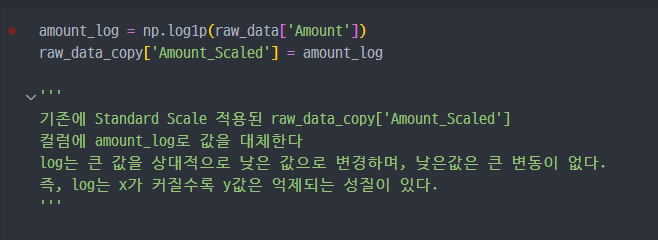
- log scale 진행

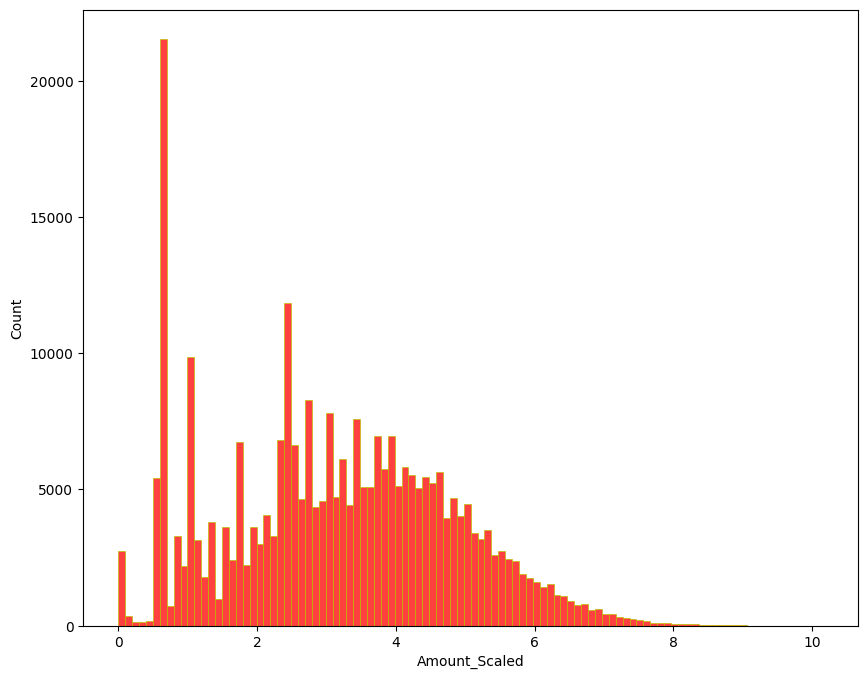
- 그래프 확인. 최초 그래프보다 조금 더 균등하게 분포된 모습을 볼 수 있다.
- log scale 적용 시, 산출되는 성능지표. 큰 차이 없어 보인다..
Trial 3 - Outlier 관찰
- Outlier를 정리하기 위해서 인덱스 파악
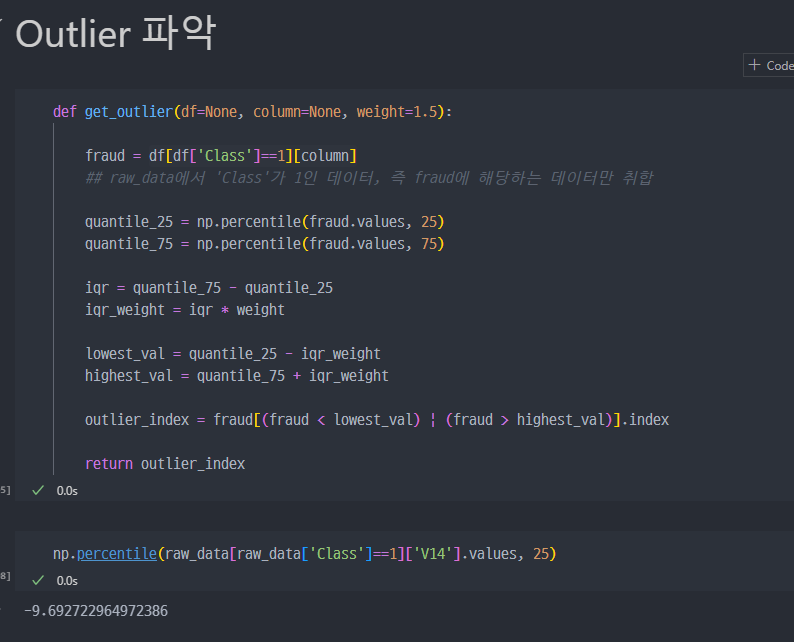
- 특정 컬럼에서
Outlier의 인덱스를 찾는 함수 생성
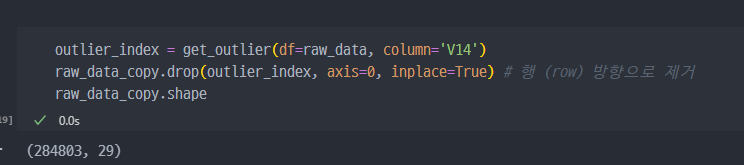
- 컬럼
V14를 기준으로 해서,fraud데이터 기준outlier에 해당하는index를 찾아서 해당 행(row)를 제거
Outlier 제거한 데이터를 가지고, train_test_split진행

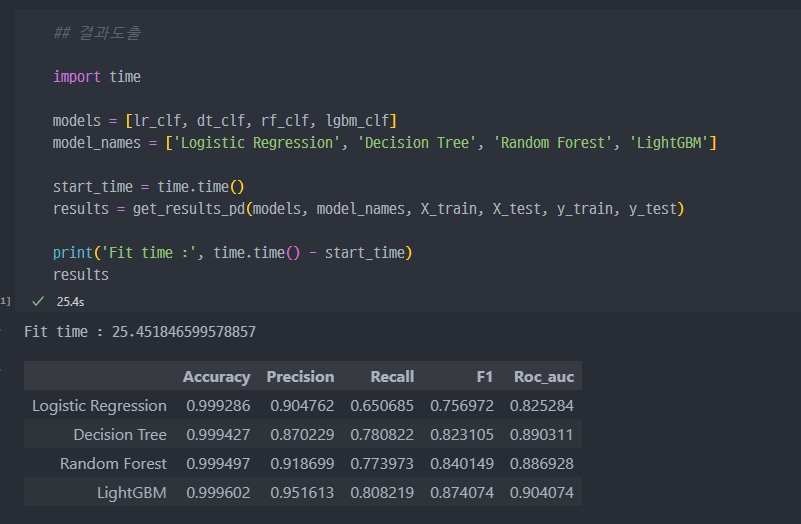
- 특정 컬럼(
V14)의Outlier를 제거하니Recall이 80% 까지 좋아진 것을 확인할 수 있다.
Trial 4 - Oversampling
개념
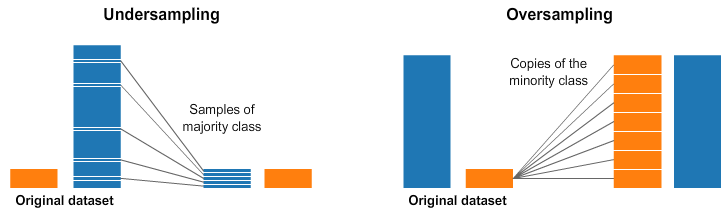
UnderSampling VS OverSampling
- 데이터의 불균형이 극심할 때, 불균형한 두 클래스의 분포를 강제로 맞춰보는 작업
UnderSampling: 많은 수의 데이터를 적은 수의 데이터로 강제 조정OverSampling- 원본데이터의
Feature값들을 아주 약간 변경하여 증식 - 대표적으로 SMOTE(Synthetic Minority Over-Sampling Technique) 방법이 있음
- 적은 데이터 세트에 있는 개별 데이터를
k-최근접 이웃방법으로 찾아서 데이터의 분포 사이에 새로운 데이터를 만드는 방식 imbalanced-learn이라는Python-pkg가 있음
- 원본데이터의
package 설치 (imbalanced-learn)
imblearn 진행

중요사항: OverSampling은 데이터를 결국 왜곡하는 것이므로,Train데이터에서만 데이터 왜곡을 진행해야 하며,Test데이터에서는 진행하면 안된다. 그 경우Test자체가 왜곡되기 때문이다.
OverSampling으로 증가된 데이터 개수 확인
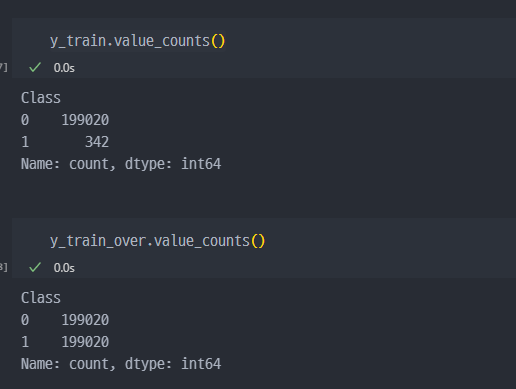
- 강제로
Train데이터에 대해서 증가시킨 것을 확인할 수 있다.
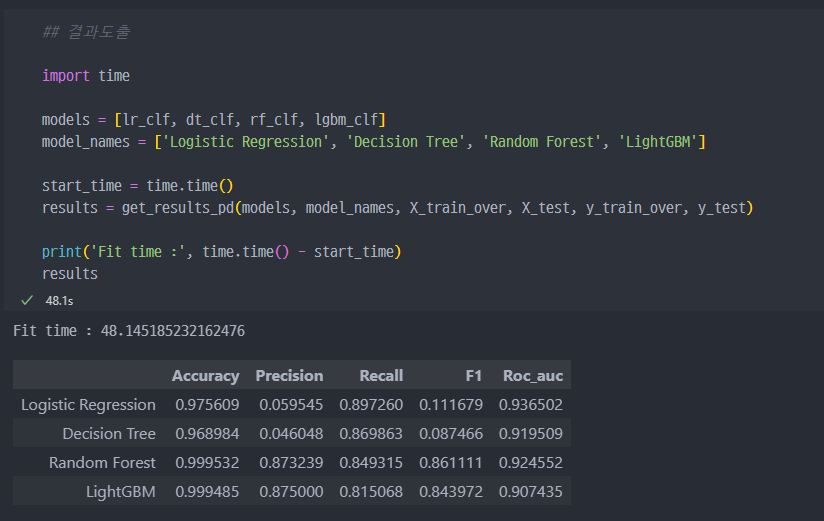
OverSampling진행 시,Recall이 최대 89% 까지 증가하는 것을 알 수 있다.- 이 경우, 전체적으로 보았을 때
Random Forest가 가장 수치가 좋은 것을 확인할 수 있다.
pandas - reshape
reshape(-1, 1)은 NumPy 배열이나 pandas Series 같은 데이터를 변환할 때 사용되며, 특히 머신러닝에서 데이터를 모델에 맞게 형상을 변경할 때 자주 사용됩니다. -1은 남은 차원을 자동으로 계산하도록 지시하는 역할을 합니다.
예시
1차원 배열을 2차원 배열로 변환할 때 유용합니다.
import numpy as np
# 원본 1차원 배열
arr = np.array([1, 2, 3, 4, 5])
# reshape 사용 예시
arr_reshaped = arr.reshape(-1, 1) # 열 벡터로 변환 (5x1 행렬)
print(arr_reshaped)
[[1]
[2]
[3]
[4]
[5]]
여기서 reshape(-1, 1)은 원래 1차원 배열을 2차원 배열로 변환하여 하나의 열을 가진 2D 배열(5x1 행렬)로 만듭니다.
다양한 옵션
reshape(1, -1): 입력 배열을 2D 배열로 변환하며 한 행(row)을 갖는 2D 배열로 변환됩니다. (1xN 행렬)reshape(2, 3): 배열을 2행 3열로 변환합니다. 이 경우, 원래 배열의 원소 개수가 맞아야 합니다.reshape(-1, 2): 자동으로 행의 수를 결정하여 2열을 가지는 2D 배열로 변환됩니다.
# 1차원 배열
arr = np.array([1, 2, 3, 4, 5, 6])
# 2행 3열로 변환
arr_2x3 = arr.reshape(2, 3)
print(arr_2x3)
# 자동으로 행을 맞추고 2열을 가지는 배열로 변환
arr_auto = arr.reshape(-1, 2)
print(arr_auto)
# 1행 N열 배열로 변환
arr_row = arr.reshape(1, -1)
print(arr_row)
[[1 2 3]
[4 5 6]]
[[1 2]
[3 4]
[5 6]]
[[1 2 3 4 5 6]]
주의사항
- 배열의 총 원소 개수는 reshape의 파라미터에 맞게 변환할 수 있어야 합니다. 예를 들어, 6개의 원소가 있는 배열을 reshape(3, 4)로 변환하려고 하면 오류가 발생합니다.
- -1은 배열의 크기를 자동으로 맞추도록 해 주기 때문에 특정 차원을 명시하고 다른 하나를 -1로 쓰면 유용합니다.

(hellow. world)