
2024.10.27
Logistic Regression
Logistic Regression
로지스틱 회귀와 시그모이드(sigmoid) 함수
-
직선으로 이루어진 예측그래프, 즉 선형회귀 (
Linear Regression)가 모든 상황에 적합한 것은 아니다. 그렇기에 선형이 아닌 다른 형태의 회귀함수, 즉 그래프에 대해 학습한다. -
로지스틱 회귀 모델은 일종의
확률 모델로서 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는통계기법이며 종속 변수가범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류(classification) 기법이기도 하다. -
결과적으로 위처럼 생긴 함수를
sigmoid 함수라 하며... 로지스틱 회귀란 독립변수를 input값으로 받아 종속변수가 1이 될 확률을 결과값으로 하는 sigmoid함수를 찾는 과정이다.
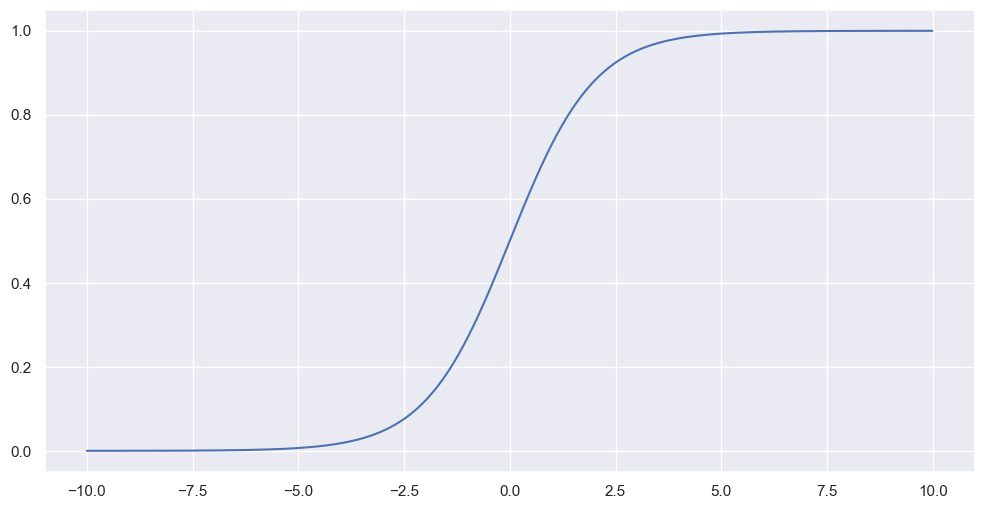
로지스틱 회귀에 사용되는 함수 (그래프)는 위와 같다. 0와 1사이에서 S자 형태로 이루어진 함수를 사용한다.
- 조금 더 보기좋게 표현..
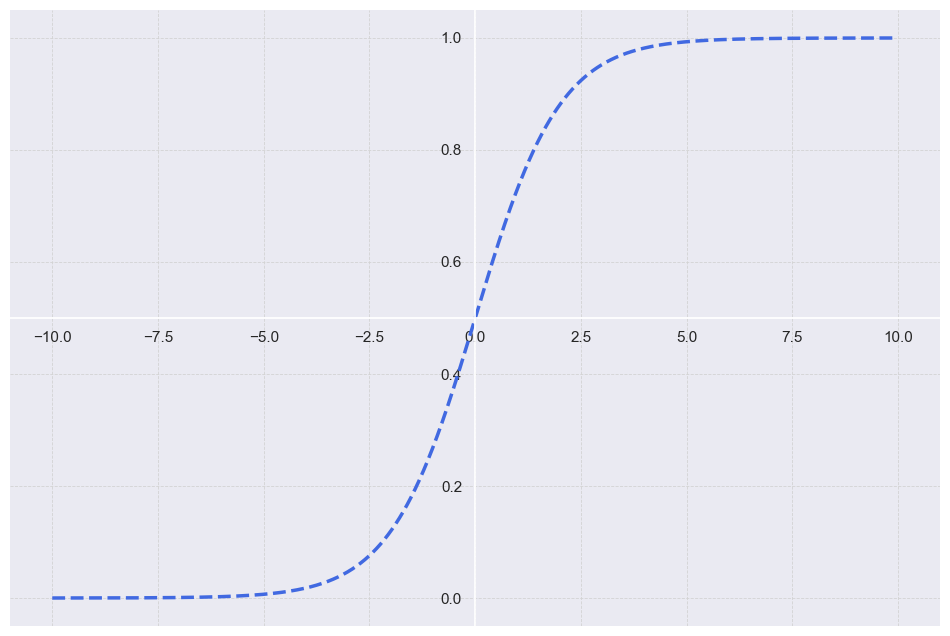
코드는 아래 참조
plt.figure(figsize=(12, 8))
ax = plt.gca() # 설정값을 디테일하게 설정하는 변경하는 방법
ax.plot(z, g, color="royalblue", linestyle="--", linewidth=2.5,)
ax.spines['left'].set_position('zero')
#왼쪽 축 # 제로 포지션 이동
ax.spines['bottom'].set_position('center')
#아래쪽 축 # 센터 포지션 이동
ax.spines['right'].set_color('none')
#오른쪽 축 # 삭제
ax.spines['top'].set_color('none')
#위쪽 축 # 삭제
ax.grid(visible=True, linestyle='--', linewidth=0.6, color='lightgrey')
# 격자 스타일 변경
간단한 실습 진행(1)
1) 데이터 받아오기 및 전처리 과정
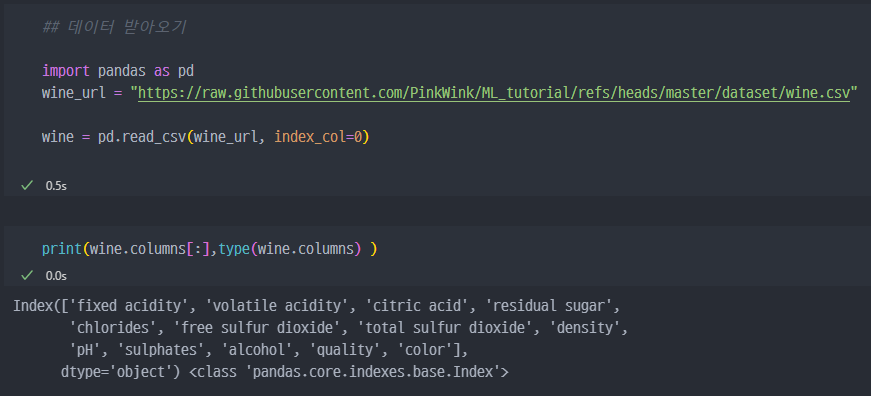
github에 있는 csv자료를 받아와서pandas의DataFrame형태로 저장
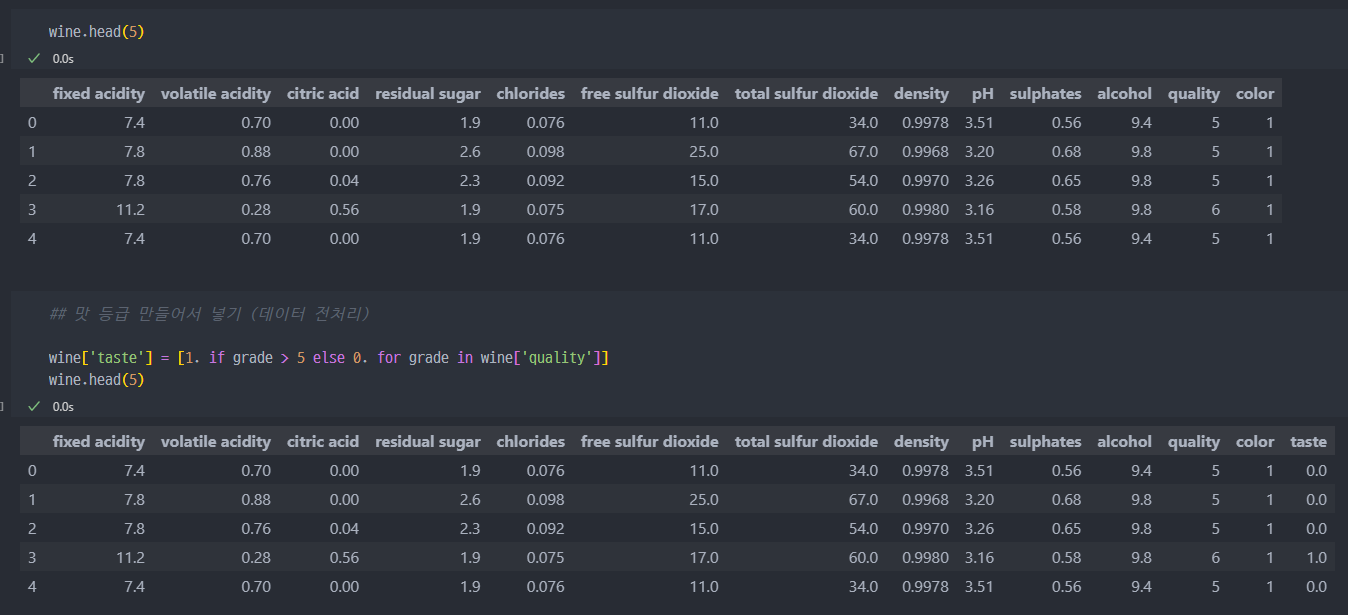
데이터 확인 및
quality컬럼 값을 통해서taste컬럼 생성 및 값 추가
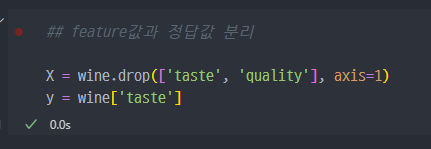
sklearn의 분류모델 사용위해,feature와정답값분류
quality를 통해taste정답값을 생성했으므로, 반드시quality컬럼은 drop해야 한다.
2) Train, Test 데이터 생성 및 간단 Logistic Regression 진행
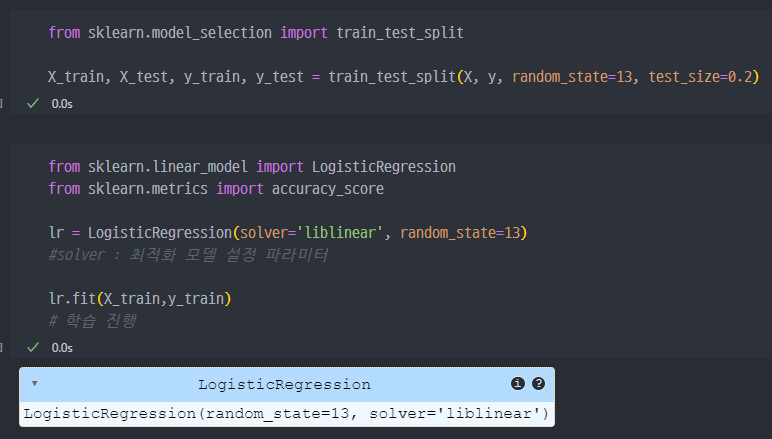
Train,Testsplit을 통해 데이터 분리 및 생성.LogisticRegression을 통한 학습 진행
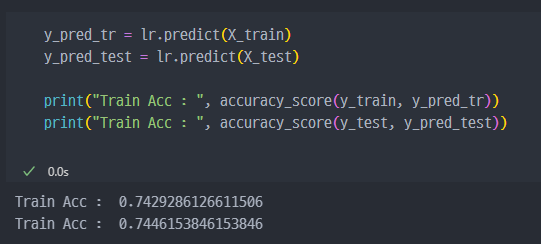
정확도 확인진행.
※ 참고 : 해당 예측모델을 사용하는 예제.
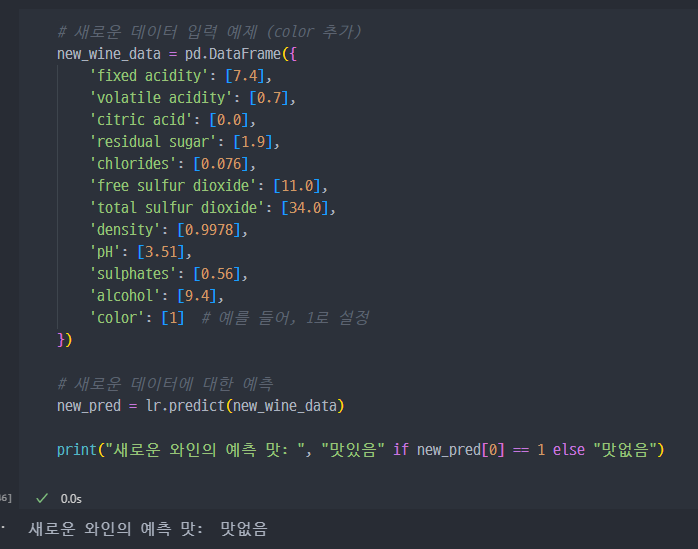
위와 같이, 각
feature에 대한 값들을 주어주면, 학습모델에 의해서맛있음(1)또는맛없음(0)을 예측한다.
3) 스케일러 적용 및 파이프라인 구축
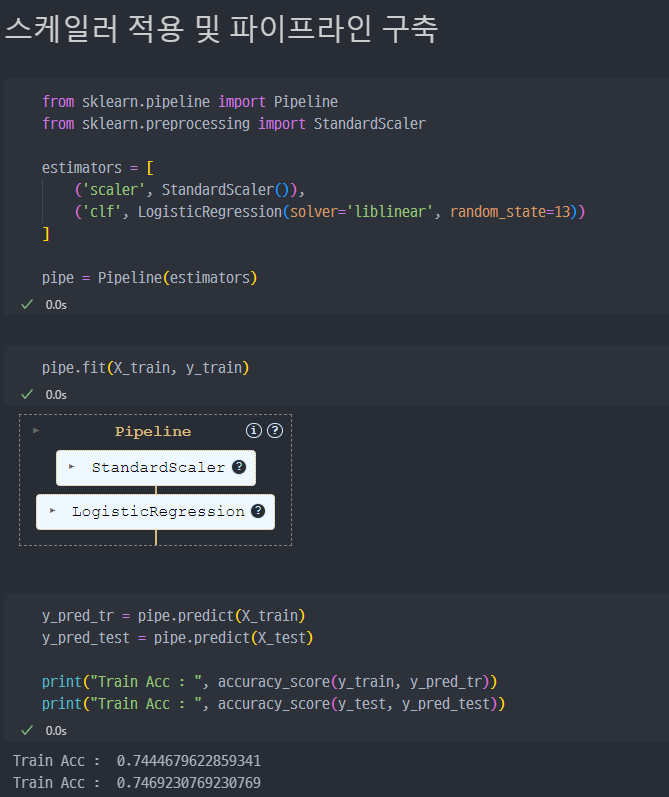
StandardScaler와Pipeline의 개념은 앞장에서 나왔지만, 조금 더 분석이 필요하다.
일단, 기존 대비 아주 미미하지만 개선효과는 있어 보인다 (acc 일부 상승)
4) Decision Tree와 logistic Regression 비교
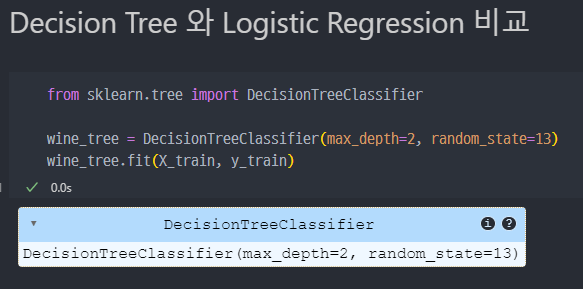
Decision Tree및Fit( )진행
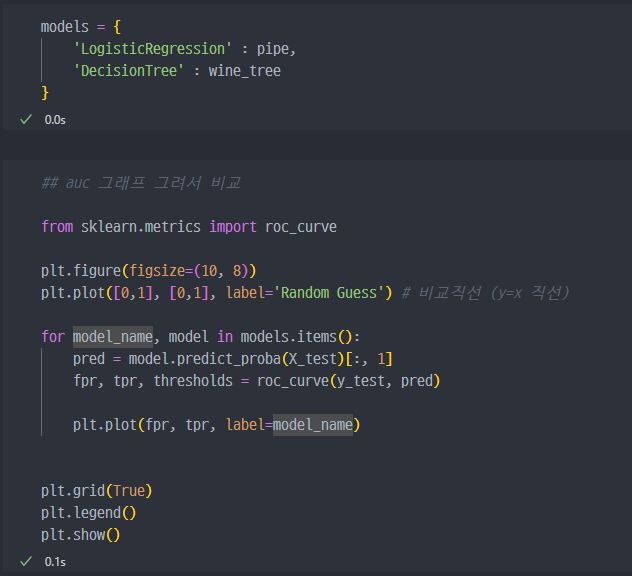
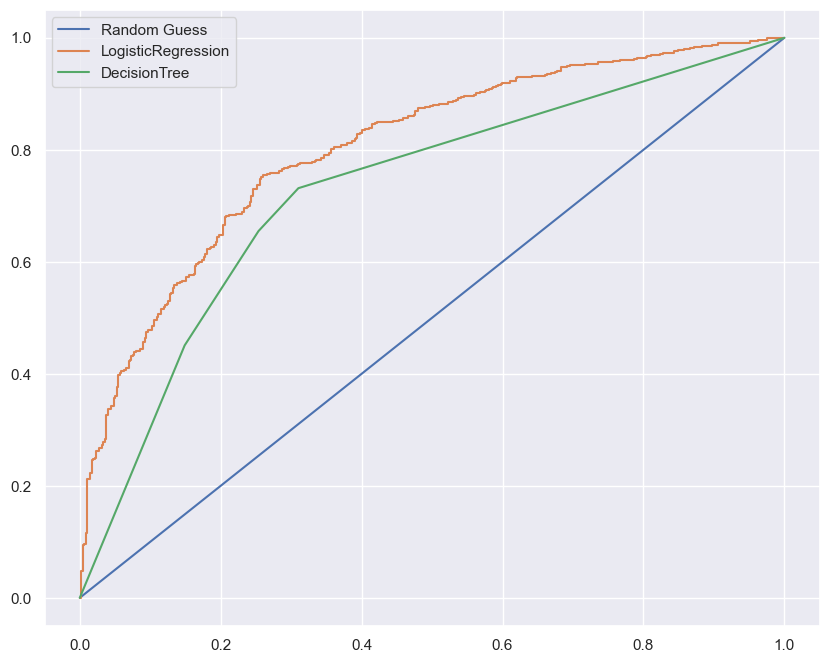
- 모델 두 가지에 대하여
roc 커브 그래프를 통한 비교 진행 roc 커브에서 해당 곡선과 x축 사이 공간의 면적이auc라 불리며, 이 값이1에 가까울 수록 성능이 좋다.- 해당 그래프를 비교했을 경우,
Logistic Regression이Decision Tree곡선보다 더 위에 있으니, 성능이 더 좋은 모델이라 할 수 있다.
이전 강의 내용 참조 ML #7
ROC 곡선Receiver Operating Characteristic Curve은 이진 분류 모델의 성능을 평가하고 비교하는 데 사용되는 그래프로, 다양한임계값(threshold)에서의참 양성 비율(True Positive Rate, TPR)과거짓 양성 비율(False Positive Rate, FPR)을 시각화합니다.AUC란Area Under the Curve는 곡선 아래의 면적을 의미하며, 모델의 분류 성능을 수치화한 지표로 사용됩니다.- AUC의 의미
AUC는 ROC 곡선 아래 면적을 나타내며, 0.5에서 1 사이의 값을 가집니다.AUC= 1 : 완벽한 분류를 의미하며, 양성과 음성을 완전히 구별합니다.AUC= 0.5 : 무작위 추측과 같은 성능을 의미합니다.AUC< 0.5 : 음성과 양성을 반대로 예측하는 경향이 있음을 의미합니다.
간단한 실습 진행(2) : PIMA 인디언 당뇨병 예측 문제
- 50년대까지 PIMA 인디언은 당뇨가 없었음.
- 20세기 말, 50%가 당뇨에 걸림
- 50년만에 50%의 인구가 당뇨에 걸림
1. 데이터 불러오기 및 확인
Feature 특성값
Pregnancies: 임신 횟수Glucose: 포도당 부하 검사 수치BloodPressure: 혈압SkinThickness: 팔 삼두근 뒤쪽의 피하지방 측정값Insulin: 혈청 인슐린BMI: 체질량지수DiabetesPedigreeFunction: 당뇨 내력 가중치 값Age: 나이Outcome: 클래스 결정, 당뇨 유무 (정답값)
github에 저장되어 있는 데이터 불러오기 진행PIMA = PIMA.astype('float')
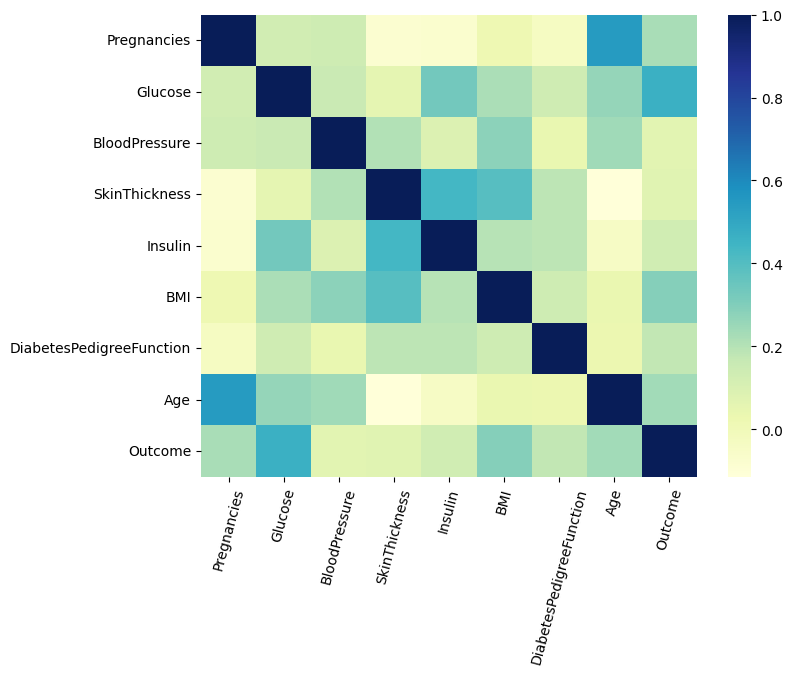
corr()이용하여 상관관계 그래프 확인
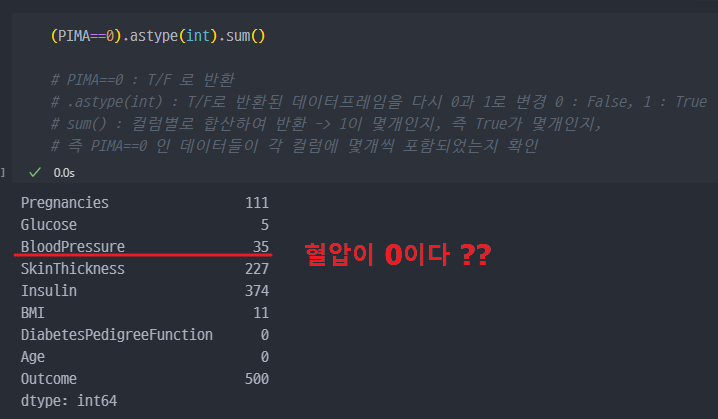
- 데이터 확인하여, 결측치 (이상한 데이터) 확인 및 점검
2. 결측데이터 혹은 오류데이터 수정
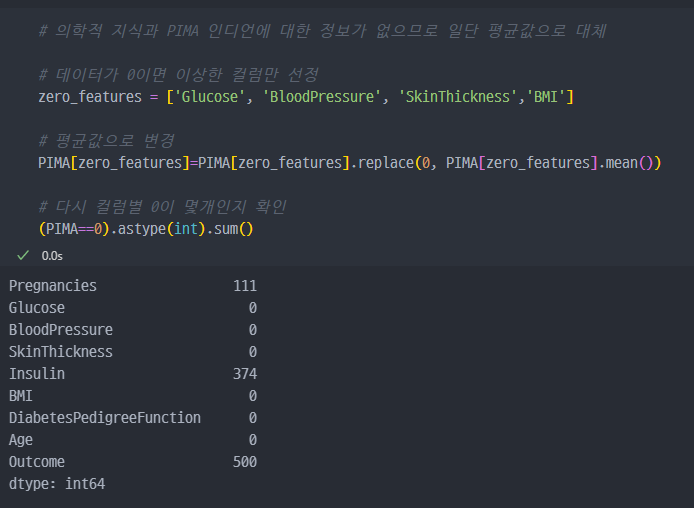
0이면 안되는 컬럼을 선정하여, 해당 컬럼의 평균값으로 대체 진행.
3. 데이터 나누고 ML 진행
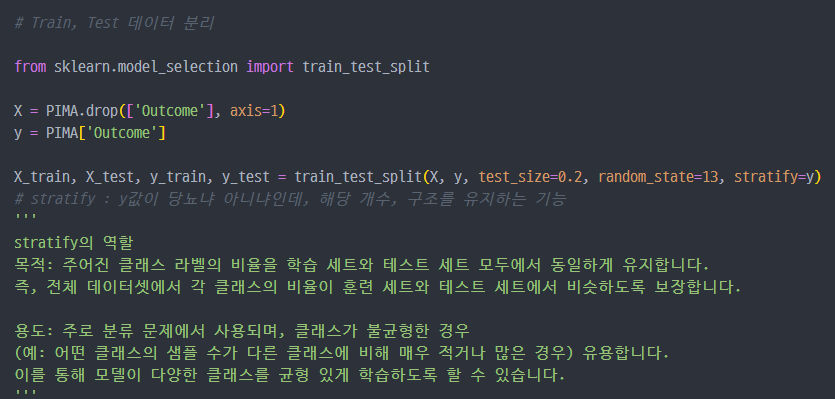
Train_test_split으로X(특성값들),y(정답값) 데이터 나누고..
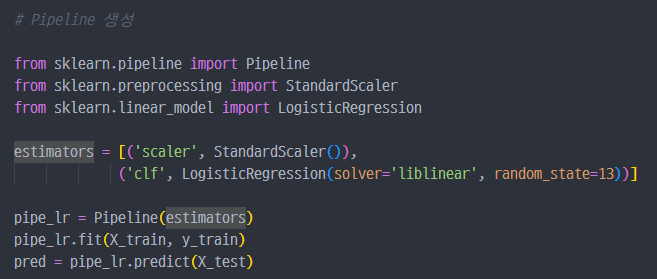
Pipeline생성 및fit() - 학습진행
참고사항
-
Pipeline: 여러 변환 및 모델 학습 단계를 연결하여 작업을 간소화합니다. -
StandardScaler: 데이터를 표준화(평균 0, 분산 1)하는 데 사용됩니다. -
LogisticRegression: 로지스틱 회귀 모델을 구현합니다. -
estimators: 튜플의 리스트로, 첫 번째 요소는 이름(예:'scaler'또는'clf'), 두 번째 요소는 해당 단계에서 사용할 변환기나 추정기입니다.('scaler', StandardScaler()): 데이터를 표준화하는 단계입니다.('clf', LogisticRegression(...)): 로지스틱 회귀 분류기를 정의합니다.solver='liblinear'는 작은 데이터셋에 적합한 최적화 알고리즘을 사용하도록 설정하고,random_state=13은 결과의 재현성을 위해 난수 시드를 설정합니다.
-
pipe_lr: 정의된estimators를 사용하여 파이프라인 객체를 생성합니다. 이 객체는 데이터 전처리와 모델 학습을 순차적으로 수행합니다. -
fit: 훈련 데이터X_train과 레이블y_train을 사용하여 파이프라인을 학습합니다. 이 단계에서StandardScaler가 먼저 호출되어 데이터를 표준화하고, 그 결과가LogisticRegression 모델에 전달되어 학습됩니다. -
predict: 테스트 데이터X_test를 사용하여 학습된 모델에 대한예측을 수행합니다. 이때도 데이터는 자동으로 표준화된 후 로지스틱 회귀 모델을 통해 예측됩니다. 결과는 pred에 저장됩니다.
1. 데이터 전처리(표준화)와 모델 학습(로지스틱 회귀)을 결합하여 파이프라인을 생성합니다.
2. 훈련 데이터를 사용하여 모델을 학습하고, 테스트 데이터에 대한 예측을 수행합니다.
※ Pipeline을 사용하면 여러 단계를 쉽게 연결하고 관리할 수 있어데이터 전처리와 모델링을 보다 효율적으로 수행할 수 있습니다.
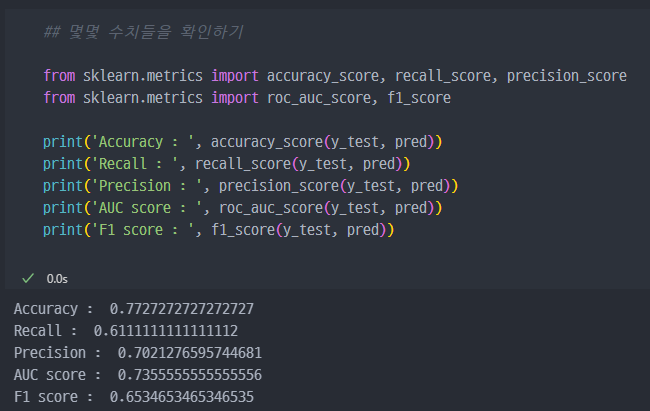
- 각종 모델의 정확도, 예측정확도 등 확인
1. Accuracy (정확도)
값: 0.7727 (약 77.27%)해석: 전체 샘플 중에서 올바르게 분류된 샘플의 비율입니다. 즉, 77.27%의 샘플이 모델에 의해 정확하게 예측되었습니다. 그러나 정확도는 클래스 불균형이 있는 경우 해석에 주의가 필요합니다.
2. Recall (재현율)
값: 0.6111 (약 61.11%)해석: 실제 양성 샘플 중에서 모델이 올바르게 양성으로 예측한 비율입니다. 즉, 61.11%의 실제 양성 샘플이 모델에 의해 올바르게 예측되었습니다. 재현율이 낮으면 모델이 양성을 놓치는 경우가 많음을 의미합니다.
3. Precision (정밀도)
값: 0.7021 (약 70.21%)해석: 모델이 양성으로 예측한 샘플 중에서 실제로 양성인 샘플의 비율입니다. 즉, 70.21%의 예측된 양성 샘플이 실제로도 양성이었습니다. 이는 잘못된 양성 예측(false positive)을 줄이는 데 중요한 지표입니다.
4. AUC score (ROC AUC 점수)
값: 0.7356 (약 73.56%)해석: ROC 곡선 아래의 면적(AUC)으로, 모델의 분류 성능을 평가합니다. AUC 값은 0과 1 사이의 값으로, 1에 가까울수록 성능이 우수합니다. 73.56%는 모델이 양성과 음성을 잘 구분하고 있음을 나타냅니다.
5. F1 score (F1 점수)
값: 0.6535 (약 65.35%)해석: 정밀도와 재현율의 조화 평균입니다. 두 지표 간의 균형을 제공하여, 하나의 지표만 가지고 평가하는 것보다 더 포괄적인 성능 평가를 가능하게 합니다. F1 점수가 65.35%인 경우, 모델의 예측이 어느 정도 신뢰할 수 있지만, 여전히 개선이 필요할 수 있음을 나타냅니다.
종합적인 해석
- 모델의
정확도는 비교적 좋은 편이지만(77.27%),재현율이 낮아(61.11%) 실제 양성 샘플을 놓치는 경우가 많습니다. 정밀도(70.21%)는 양성을 예측했을 때 신뢰할 수 있는 수준이며, 이는 모델이 양성을 잘 예측하고 있음을 나타냅니다.AUC 점수(73.56%)는 양성과 음성을 잘 구분하고 있음을 보여주지만,F1 점수(65.35%)는 성능이 여전히 개선될 여지가 있음을 시사합니다.
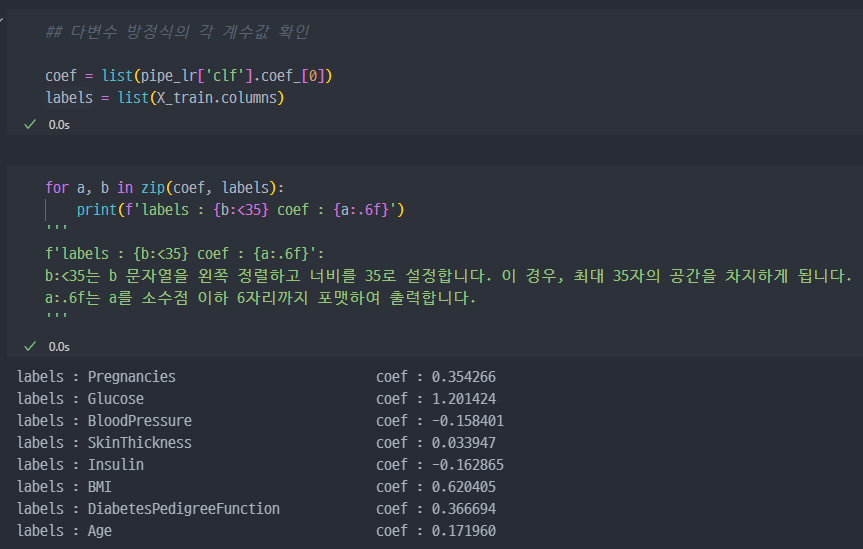
4. 중요한 Features 그래프 작성
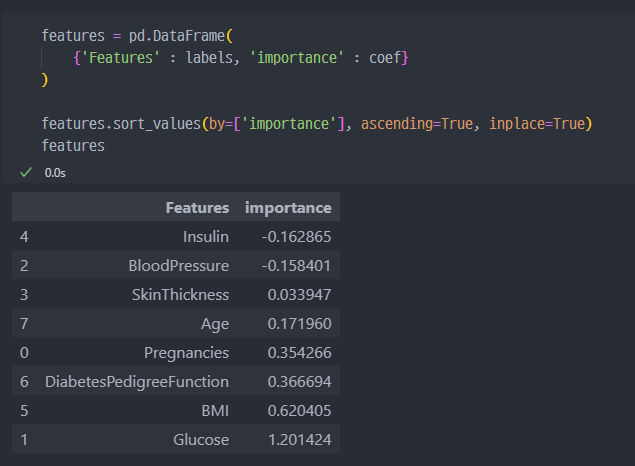
sort추가하여 정렬
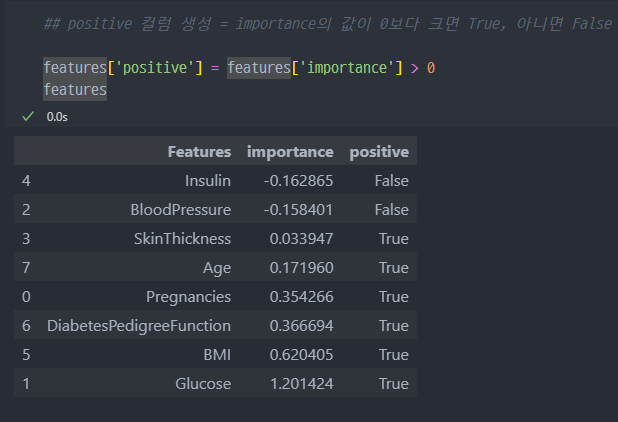
positive컬럼 생성
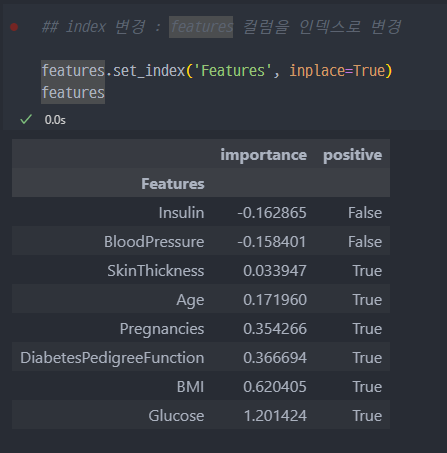
index를Features컬럼으로 변경
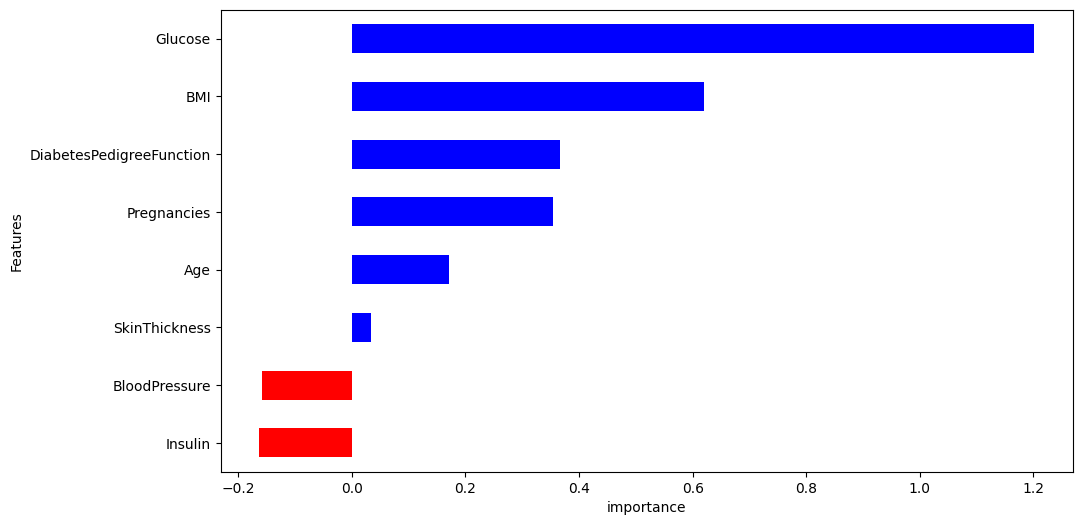
그래프 확인
- 포도당, BMI 등은 당뇨에 영향을 미치는 정도가 높다
- 혈압은 예측에 부정적 영향을 준다
- 연령이 BMI보다 출력 변수와 더 관련되어 있었지만, 모델은 BMI와 Glucose에 더 의존함.
