SGD : Stochastic Gradient Descent
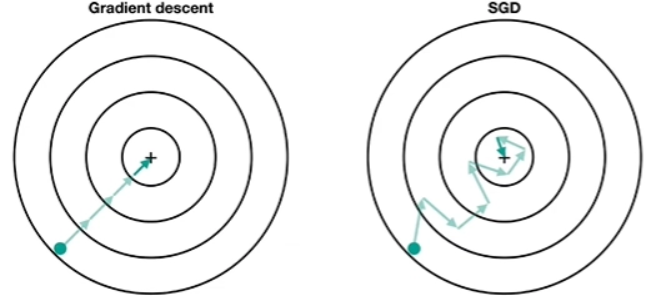
- Random하게 data를 하나씩 뽑아서 Loss를 계산한다.
- 즉 하나만 보고 빠르게 결정
- 비복원 추출이다. (뽑고 다시 주머니로 넣음)
- 왜 SGD가 삐딱하게 최솟값으로 가는 걸까?
- 등고선은 모든 데이터에 대한 Loss를 고려한다.
- Step마다 선택된 data에 대한 최솟값을 향해 가는 것은 맞지만, 하나의 data의 최솟값이 모든 데이터의 최소값을 대표하는 것이 아니기에 삐딱하게 움직이는 것 처럼 보인다.
- GD는 무조건 가까운 minimum으로 가지만, SGD는 좀 더 삐딱하게 움직여 Global minimum을 찾을 가능성이 더 크다.
Mini Batch SGD
- 학습 데이터의 개수가 m개라고 하자.
- GD는 1epoch 당 m back propagation 해야기 때문에 학습 시간이 오래 걸린다.
- SGD는 하나씩만 보니까 너무 성급하게 방향을 결정한다.
- Batch size를 키우면 키울 수록 GD랑 비슷해짐. GD랑 비슷해지면 결국 Local minimum에 빠질 확률이 높아짐.
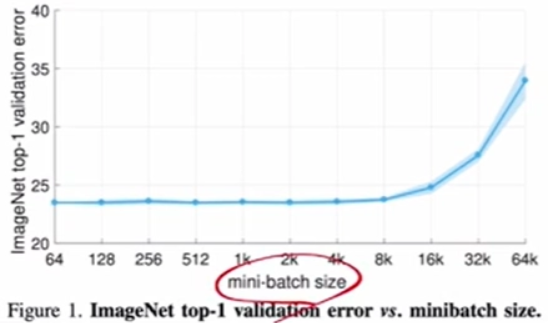
- Batch 크기에 따른 Lr은 어떻게 해야할까?
- Lr를 Batch size랑 같이 키워야한다.
- Linear Scailing Rule : Batch size와 Lr 정비례
- Batch size가 커지면 커질 수록 Gradient가 안정적이기 때문에 Lr을 크게 가져가도 발산하지 않는다.
- 하지만 초반에는 발산 위험이 있기 때문에 Batch size가 크다고 해서 처음부터 Lr을 크게 가져가면 안된다.
- 따라서 Lr Warm up을 사용해야 한다 !
- Lr를 Batch size랑 같이 키워야한다.
출처 및 참고 자료
- Andrew Ng, Improving Deep Neural Network, DeepLearningAI
- 혁펜하임, Easy! 딥러닝
