-1. 들어가기 전에
관련 논문들
- blip2
- whisper [34]
- Robust speech recognition via large-scale weak supervision
- https://proceedings.mlr.press/v202/radford23a/radford23a.pdf
- 2023, 3500회 인용
- https://github.com/openai/whisper
- 71600 stars
- Stable Vicuna [10]
- 논문이 있는건 아님
- https://github.com/Stability-AI/StableLM?tab=readme-ov-file
- 158000 stars
- Eva-clip: Improved training techniques for clip at scale [39]
- https://arxiv.org/pdf/2303.15389
- 2023, 356회 인용
- https://github.com/baaivision/EVA
- 2300 stars
- https://arxiv.org/pdf/2303.15389
- Mvbench: A comprehensive multi-modal video understanding benchmark
논문 4줄 요약
- Video Language Model(ViLM)을 비디오 데이터 셋 기반 학습 관점에서 다룬 논문. 2가지 알고리즘을 제안함.
- [VideoChat-Text] 비디오 데이터를 (여러 목적의 딥러닝 모델을 활용해서)
video class, video caption, clip caption, clip tags, dense caption, subtitle, object 종류 및 위치 등을 표시한 text로 변환 하여 이를 LLM의 input으로 활용해서 VQA 등을 수행 - [VideoChat-Embed] Video Language Model(ViLM)을 Video text data를 활용해서 end-to-end training 시키는 방법 (Visual Encoder, QFormer, LLM은 Frozen시키고, modality 정렬 부분만 추가 학습 시키는 것)
- [VideoChat-Text] 비디오 데이터를 (여러 목적의 딥러닝 모델을 활용해서)
- Visual instruction tuning (A.K.A. llava) 의 비디오 버전으로, Video Instruction tuning 데이터를 생성하는 방법을 제시 (Detailed Video Descriptions 데이터 + Video Conversations 데이터)
7. 한계점
- 장기 비디오 처리의 어려움:
- VideoChat-Text와 VideoChat-Embed 모두
1분 이상의 장기 비디오를 처리하는 데 어려움을 겪습니다.- 이는
긴 비디오의 맥락을 효과적이고 효율적으로 모델링하는 것이 복잡하고 지속적인 연구 과제이기 때문
- 이는
- 또한 사용자 친화적인 상호 작용을 제공하면서 긴 비디오를 처리할 때
응답 시간, GPU 메모리 사용량 및 시스템 성능에 대한 사용자 기대치를 균형 있게 조절하는 것이 어려움
- 시공간적 및 인과 추론 능력의 미흡:
- 시스템의 시공간적 및 인과 추론 능력은 아직 초기 단계
- 이러한 한계는 현재의
instruction 데이터 규모와 구축 방법,전체 시스템 규모및사용된 모델에 기인
- 이러한 한계는 현재의
시간에 민감하고 성능이 중요한 응용 분야에서의 성능이 별로임:
- 예를 들어,
자가 중심적인 작업 지시 예측및지능형 모니터링과 같은 분야에서의 성능 격차를 해결하는 것은 지속적인 과제
1. 소개
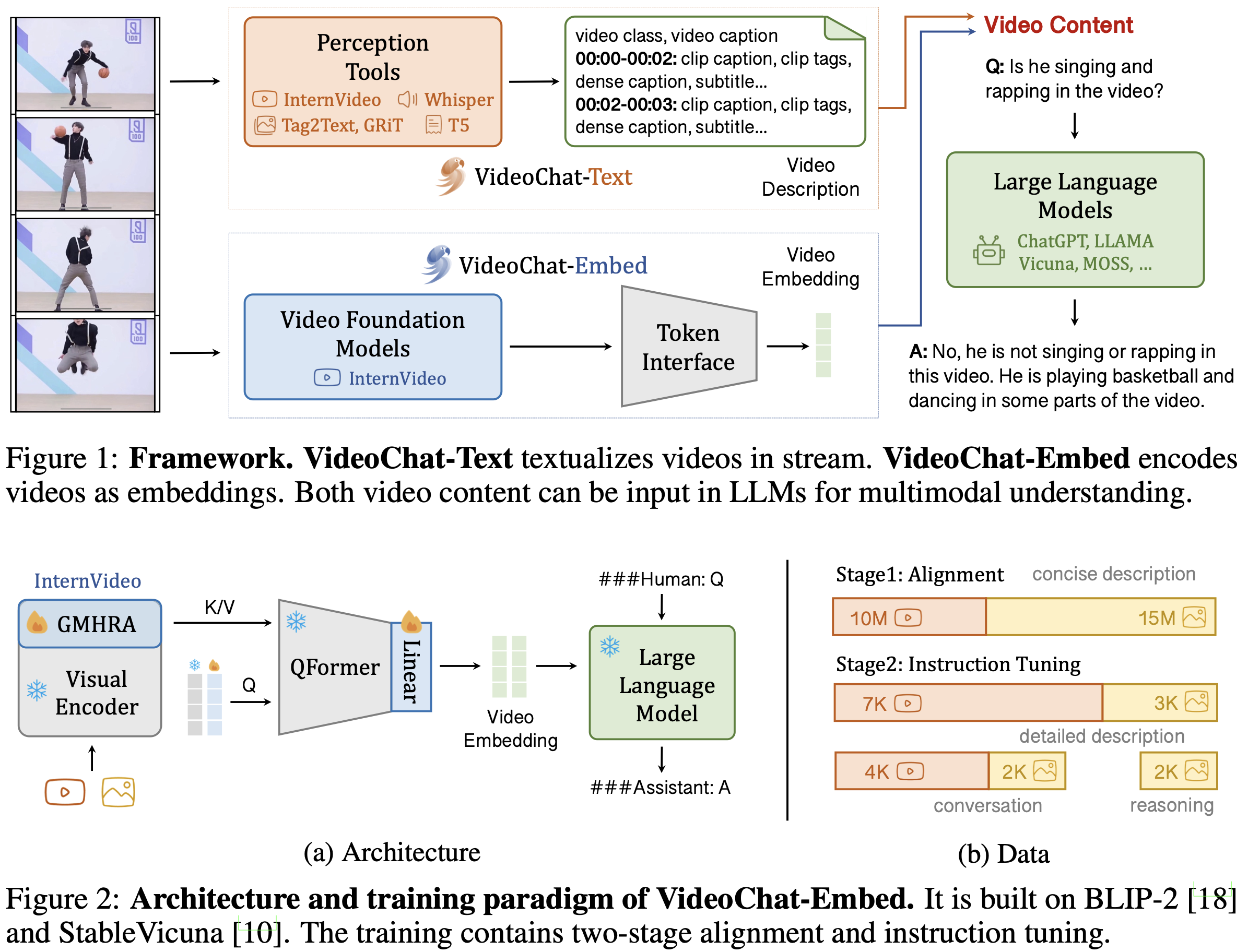
- 현재의 비디오 이해 패러다임은 특정 작업(예: 비디오 classification)에 맞춘,
사전 학습된 비디오 모델의 튜닝 접근법에 한정되어,- 비디오 콘텐츠에 대한 일반적인 시공간적 이해를 제한하고 있음
- 최근 연구에서
이미지 중심의 multi modal 대화 시스템이 주목받고 있습니다.- 이러한 시스템은 사전 학습된
대형 언어 모델(LLM),이미지 인코더,추가 학습 가능한 모듈을 활용하여 이미지에 대한 깊은 이해를 가능하게 합니다. - 이를 통해 사용자와의 다중 라운드 대화를 통해 이미지 관련 작업을 수행할 수 있음
- 이러한 시스템은 사전 학습된
- 하지만
비디오 중심의 multi modal 대화 시스템은 아직비디오 데이터 중심의 관점에서 공식적으로 다루어지지 않았습니다. - 저희의 초기 비디오 중심 다중 모달 대화 시스템은 (이 논문에서
VideoChat-Text방법을 의미)- 비디오 이해 문제를 ->
자연어 처리(NLP) 질문-응답으로 변형하였습니다.- 방법:
공개된 비주얼 모델을 활용하여 비디오 콘텐츠를 텍스트화한 후, LLM의 input에 통과시켜 질의응답을 수행 - 그러나 이는 비디오를 텍스트 설명으로 변환하는 과정에서
시각 정보의 손실과시공간적 복잡성의 과도한 단순화를 초래
- 방법:
- 비디오 이해 문제를 ->
2. 관련 연구
2.1. 비디오 기반 모델
- 비디오-언어 도메인에서 표준 패러다임:
대규모 비디오-텍스트 pre-training후 ->다운스트림 작업의 fine-tuning- 예: video foundation model self-supervised pre-training 방법:
- 예: video foundation model constrastive pre-training with language 방법:
- 초기 방법들은
사전 학습된 비주얼 및 언어 인코더를 사용하여오프라인 비디오 및 텍스트 특징을 도출하였지만,
- 최근에는 엔드투엔드 학습의 효과가 입증됨
- 일반적으로
마스킹된 언어 모델링,비디오-텍스트 매칭,비디오-텍스트 대조 학습등 두세 가지의 pre training 작업을 포함
- 일반적으로
2.2. 대형 언어 모델
- 최근 대형 언어 모델(LLM)의 발전은 언어 생성, in-context learning 등 놀라운 능력을 보여줌
2.3. LLM을 활용한 다중 모달 이해 (VLM)
- LLM의 성공은, 비전 모델과 LLM을 결합하여 다중 모달 추론과 작업을 수행하는 시스템의 개발을 가속화
- Visual instruction tuning은 시각적 지시 작업에 대해 LLM을 fine-tuning하는 기술을 도입하여
- 이미지 기반 작업에서 GPT-4 수준의 대화 성능에 근접
3. method
- VideoChat은 비디오 이해를 위해 두 가지 접근 방식을 제안합니다: VideoChat-Text와 VideoChat-Embed입니다. (
대화 중심의 비디오 이해 시스템) - VideoChat-Embed 시스템은
비디오와 언어의 Foundation 기 학습된 모델을, 학습 가능한 신경 인터페이스를 통해 통합하여,시공간적 추론,이벤트 위치 지정,인과 관계 추론에 뛰어난 성능을 보임
3.1 VideoChat-Text
- 데이터 전처리:
주어진 비디오에 대해 ffmpeg를 사용하여 저속 FPS로 주요 프레임을 추출하여,T개의 비디오 프레임과 관련 오디오를 생성
3.1.1. 사용한 Perception Models
- 추출된 프레임과 오디오를 다양한 모델에 입력함으로써, 아래의 다양한 정보를 얻습니다.
행동 레이블,프레임 요약,비디오 태그,상세 설명,객체 위치 좌표,비디오 내러티브,타임스탬프 및 기타 세그먼트 관련 정보- VideoChat-Chat-Centric-Video-Understanding 용어정리
- 비디오 및 이미지 모델 [46, 34, 20, 48, 15, 33]을 결합하여
행동[46, 20, 21] (InternVideo [46] 사용),객체[45, 15],객체 주석 및 위치[48] 등을 분석
InternVideo 사용
- Action Labels: "자전거 타기", "강아지 달리기"
Whisper 사용
- 비디오 내 오디오 데이터를 활용함으로써 비디오 설명의 풍부함을 더욱 향상시킵니다.
- input
- 오디오
- output
- text
Tag2Text, GRIT 사용
- input
- 비디오
- output
- 비디오 설명 text
- 비디오 설명 tag
3.1.2 프롬프트 시스템 (Prompt System)
- 위 각각 모델들의 대부분은 출력이 독립적인 경향이 있지만,
- 사전 학습된 T5 언어 모델 [34]을 사용하여 설명을 더 명확하게 다듬습니다.
- 비디오를 다양한 비전 모델에 입력하여 여러 텍스트화된 비디오 출력을 얻은 후, 이를 템플릿(Table 1)에 따라 구성하여 LLM의 입력으로 제공

- 이후, LLM에 맥락을 제공하여 입력된 텍스트(인식 모델로부터 생성된 구조화된 비디오 정보)를 통해 비디오를 "보는" 것처럼 상상하게 하고 사용자와 대화를 진행하도록 합니다.
- 이러한 프롬프트는 Table 2에 나와 있습니다.
Table 2: 시스템 프롬프트
시스템이 텍스트화된 비디오를 이해하고 문서의 관련 내용을 기반으로 응답하도록 합니다. 비디오와 무관한 질문에는 답하지 않도록 설정합니다.
프롬프트 예시:
당신은 비디오 맥락을 기반으로 대화를 진행하는 챗봇입니다. 주어진 맥락을 기반으로 주로 답변하며, 태그 정보를 수정하거나 비디오에 포함된 인물이나 객체와 관련된 지식을 활용할 수도 있습니다. 타이밍 설명은 초당 1/FPS의 설명으로 시간을 변환할 수 있습니다. 설명할 때는 주로 타이밍 설명을 참조하세요. 밀도 캡션은 5초마다 내용을 제공합니다. 타이밍으로 이를 구분할 수 있습니다. 하지만 비디오 줄거리를 임의로 생성하지는 마세요.시작!
비디오 맥락의 시간 순서: textualizing_videos (Table 1의 내용)
질문: question
3.1.3. 성능 분석
- 10초 분량의 비디오 클립을 NVIDIA-A10 GPU로 약 2초 안에 처리
- 그러나 텍스트를 소통 매체로 사용하는 것은 -> 비디오 인식 모델의 디코더 성능을 제한하여 -> 표현 능력을 제약함
- LLM에 비디오에서 더 풍부한 시각적 정보를 제공하려면 -> 보다 고급의 인식 모델을 사용해야 하지만 이는 VideoChat-Text의 효율성과 충돌할 수 있습니다.
- 또한, VideoChat-Text는 Visual Instruction Tuning 방법의 [25]의 잠재적 이점을 충분히 활용하지 못합니다.
고오급 Instruction 데이터셋으로 weight를 Visual instruction Tuning 하지 못하는 구조이므로.
3.2. VideoChat-Embed
- 비디오와 언어 기반 모델을 결합하고, 학습 가능한
비디오-언어 토큰 인터페이스(VLTF)를 추가로 사용 - 더 나은 모달리티 간 최적화를 위해,
언어 친화적인 비디오 기반 모델(비디오와 언어를 이용하여 pre-training을 한 모델)을 채택- 예: internvideo
- 하지만 논문을 읽어보니, EVA-CLIP을 visual encoder로 사용한 것 같음 (아래에 설명 나옴)
- 비디오의 중복성을 고려하여 [41], VLTF를 도입하여 cross-attention 를 활용해 비디오 토큰을 압축
- 학습 과정에서,
새롭게 통합된 GMHRA, 쿼리 및 선형 투영을 제외한 대부분의 매개변수는 고정됩니다. - 우리는 (비디오 데이터만 쓰는게 아닌,) 이미지 데이터를 공동 학습에 도입합니다(Figure 2b).
3.2.1. Architecture
- 이 논문에서는 VideoChat-Embed를 BLIP-2(Q-former 구조 사용)와 StableVicuna(pretrained-LLM)[10]를 기반으로 구현(Figure 2a).
- 단계 1: 위 그림에서 VIDEO로부터 key/value 를 도출하기 위해,
- 사전 학습된 ViT-G(39) 를 Global Multi-Head Relation Aggregator(GMHRA)와 결합하여 사용
- 39: Eva-clip: Improved training techniques for clip at scale
- CLIP 논문이랑 input / output은 똑같은데, 효율적 학습방식을 제시한 것임
- 비디오 input들을 token화 한것 -> 이미지 1장당 (d,) shape vector 도출
- Global Multi-Head Relation Aggregator(GMHRA)
- 이는 InternVideo [46]와 UniFormerV2 [20]에서 사용된 시간적 모델링 모듈
- GMHRA는 영상의 모든 spatiotemporal 토큰(즉, 영상의 각 공간·시간 위치에 해당하는 feature)을 하나의 “글로벌 영상 토큰”으로 요약하기 위해 고안되었습니다.
- Visual Encoder 로 부터 생성한 (B, L, C) 토큰을 input으로 받아 (B, 1, C) 의 압축된 토큰을 출력해주는 역할
- 여기서 L =
T * token_H * token_W
- 여기서 L =
- 39: Eva-clip: Improved training techniques for clip at scale
- 사전 학습된 ViT-G(39) 를 Global Multi-Head Relation Aggregator(GMHRA)와 결합하여 사용
- 단계 2: 토큰 인터페이스로는
사전 학습된 QFormer와 추가 linear-projection를 사용하며,- 비디오 맥락 모델링을 위해 추가적인 쿼리 토큰이 보완됩니다. (Video query 개수를 많이 설정했다는 뜻으로 이해했는데, 확인 필요)
- BLIP-2 를 공부하면 어떤 과정인지 쉽게 이해 가능
- 이를 통해 대화에 적합한 컴팩트한 LLM 호환 비디오 임베딩을 얻을 수 있습니다.
- 아래와 같이 2단계로 학습합니다.
- 1단계에서는
대규모 비디오-텍스트 fine-tuning(쉬운 데이터셋 like Video - caption dataset)을 통해 비디오 인코더를 LLM에 정렬 (Like BLIP-2 스타일) - 2단계에서는
비디오 설명과 비디오 질문-답변 쌍이라는 두 가지 유형의 비디오 instruction 데이터를 사용하여 시스템을 조정 (Like Visual Instruction Tuning 스타일)
- 1단계에서는
3.2.2. Instruction Data 만드는 법
- VideoChat-Text의 도움을 받아 비디오 정보를 텍스트를 기반으로 만든 후,
- 이것을 input으로 이용하여 GPT-4를 이용해 데이터를 생성
3.2.2.1. Detailed Video Descriptions 데이터 생성 방법
- 제공된 비디오 설명을 GPT-4를 사용하여 비디오 내러티브(비디오에 대한 자세한 설명)로 요약합니다(Table 5).
Table 5: Detailed Video Descriptions 예시

주어진 비디오
Human:<Video>video_embed</Video> 비디오는 \(t_0, t_1, ..., t_T\) 초에서 샘플링된 \(T\)개의 프레임을 포함합니다.
Human: 비디오의 분위기와 사건들을 생생하고 묘사적인 서사로 표현하세요.
Assistant:
처음에, 긴 갈색 머리를 가진 젊은 여성이 배낭을 메고 절벽 끝에 서서 아름다운 산 풍경을 바라보고 있는 모습이 보입니다. 그녀는 경이로움에 잠겨 몇 초 동안 서 있습니다. 다음으로, 그녀가 천천히 몸을 돌리며 두 팔을 활짝 펴는 모습이 보입니다. 그런 다음, 그녀가 협곡을 마주 보며 몇 걸음 뒤로 물러나고 여전히 두 팔을 활짝 편 채 서 있는 모습이 보입니다. 그녀는 풍경의 웅장함을 만끽하는 듯합니다. 마지막으로, 그녀는 배낭을 맨 채로 절벽 가장자리에 자신감 있게 서 있습니다. 마치 산을 정복한 것처럼 보입니다.
비디오 전반에 걸쳐 협곡의 광활한 풍경과 배경에 있는 산들이 보입니다. 하늘은 일부는 흐리고, 일부는 맑은 파란색으로 아름다운 대비를 이룹니다. 전체적으로 이 젊은 여성은 풍경에 매료되어 두 팔을 활짝 펼치며 매 순간을 즐기고 있는 듯합니다.
- 이는 비디오의 시간적 진행을 강조하여 비디오의 전개를 설명
- 관련 프롬프트는 Table 3과 4에 나와 있습니다.
- 첫 번째 프롬프트는
예측된 다양한 텍스트 레이블을 ->일관되고 진화하는 이야기로 변환하며,
- 두 번째 프롬프트는
- 서사를 명료하고 일관되게 개선하고, 환각(hallucination)을 최소화
- 첫 번째 프롬프트는
- 우리는 임의로 선택된 비디오 7,000개에서 설명을 생성했습니다.
Table 3: Detailed Video Descriptions을 위한 프롬프트
주어진 프롬프트
Human: origin_caption으로 제공된 비디오입니다. 비디오의 내용을 시간 순서에 따라 설명합니다: textualizing_videos.
"first", "next", "then", "finally"와 같은 순서 부사를 사용하여 이 비디오를 자세히 설명하세요. 특정 시간을 언급하지 마세요. 가능한 한 많은 세부 정보를 포함하세요. 보이는 모든 것을 말하세요. 설명은 150자 이상 200자 이하로 작성하세요.
Table 4: Detailed Video Descriptions 후처리를 위한 프롬프트
주어진 프롬프트
Human: 주어진 문단의 오류를 수정하세요. 반복되는 문장, 의미 없는 문자, 영어가 아닌 문장 등을 제거하세요. 불필요한 반복을 제거하세요. 미완성된 문장을 다시 작성하세요. 설명 없이 결과만 반환하세요.
문단이 이미 올바른 경우, 입력 문단을 그대로 반환하세요. 설명은 하지 마세요.
3.2.2.2.Video Conversations 데이터 생성 방법
- 비디오 설명을 바탕으로 ChatGPT와 함께 설명적, 시간적, 인과적 콘텐츠에 관한 세 가지 유형의 프롬프트를 사용하여 다중 회차 대화를 생성
- 설명적 부분은 주로 LLaVA [25]의 주요 포인트를 계승합니다.
- 시간적 및 인과적 부분의 경우, 각각 시간 인식/추론과 설명/의도 및 원인 발견에 초점을 맞춘 프롬프트를 제안합니다(Table 6).
- 우리는 임의로 선택된 비디오 4,000개에서 다중 회차 대화를 생성했습니다.
- 비디오 대화의 예는 Table 7에 나와 있습니다.
Table 7: Video Conversations 예시

주어진 비디오
Human:<Video>video_embed</Video> 비디오는 \(t_0, t_1, ..., t_T\) 초에서 샘플링된 \(T\)개의 프레임을 포함합니다.
Human: 비디오에서 무슨 일이 일어나고 있나요?
Assistant: 비디오에서는 젊은 여성이 스마트폰을 들고 해변에서 밤하늘 아래 바다 위로 지는 노을을 찍고 있는 실루엣이 보입니다. 그런 다음, 다른 몇 명의 실루엣이 사진을 찍고 휴대폰을 들여다보는 장면이 나타납니다.
Human: 비디오에서 객체 간 상호작용을 설명해 줄 수 있나요?
Assistant: 비디오 속 사람들의 실루엣은 스마트폰을 들고 있으며, 그녀는 해변에서 바다 위로 지는 노을을 찍고 있습니다.
Human: 이 장면의 위치는 어디인가요?
Assistant: 이 장면은 바닷가, 즉 밤에 바다 근처의 해변에 위치해 있습니다.
Human: 비디오에서 시간에 따라 어떤 변화가 발생하나요?
Assistant: 비디오가 진행되면서 하늘의 색이 주황색에서 회색으로 변합니다. 또한, 해변에서 사람들이 사진을 찍고 휴대폰을 들여다보는 행동이 나타납니다.
Table 6: Video Conversations를 위한 프롬프트
주어진 프롬프트
Human: 단일 비디오를 관찰하고 있는 AI 비주얼 어시스턴트로서, 비디오의 설명이 시간 순서대로 제공됩니다. 이 설명에는 객체 유형, 위치(좌표 사용), 속성, 객체 간 상호작용, 동작, 환경 등이 포함됩니다.
이 설명을 기반으로 비디오를 직접 보고 있는 것처럼 모든 질문에 답변하는 것이 과제입니다.
비디오의 시각적 콘텐츠를 다루는 질문을 포함하세요. (DESCRIPTIVE) 예:
- 객체 유형, 속성, 객체 수, 동작, 위치
- 객체 간 상대적 위치
- 시간에 따라 객체 동작이나 위치의 변화
- 객체 간 상호작용
다음으로, 시간적 인식과 추론과 관련된 질문을 포함하세요. (TEMPORAL) 예:
- 사람이 특정 사건 이전이나 이후에 한 행동
- 특정 사건이나 동작의 시간 정보
마지막으로, 비디오 콘텐츠와 관련된 복잡한 질문도 포함하세요. (CASUAL) 예:
- 객체나 동작에 대한 배경 지식
- 비디오에서 발생하는 사건 논의
- 반사실적 주제 (예: 남자가 비디오에서 휴대폰을 가지고 놀고 있는데 그것을 잃어버린다면 어떻게 될지)
- 등장인물의 감정이나 행동의 이유 설명
- 비디오의 이야기나 장면이 어떻게 진행될지 예측
비디오 설명을 제공받는 동안 시간에 따른 시각적 변화와 이러한 변화의 이유 또는 원인을 묻는 질문에 우선 순위를 두세요. 단일 프레임에서 추론할 수 있는 질문보다는 이런 질문이 우선입니다.
불확실한 세부 사항에 대해서는 묻지 마세요.
복잡한 질문에 답할 때는 설득력 있고 체계적인 내용을 제공하기 위해 상세한 예제나 추론 단계를 포함한 철저한 답변을 작성하세요. 필요하면 여러 단락으로 답변하세요.
제공된 설명으로 답변할 수 없는 질문에 대해서는 “제공된 비디오에는 그런 정보가 나타나지 않습니다”라고 답변하세요. 텍스트 설명에서 나온 것이라고 언급하지 마세요.강조된 부분에서 볼 수 있듯이, AI 비주얼 어시스턴트는 정적인 이미지보다는 비디오와 관련된 측면을 질문하도록 권장됩니다.
