읽은날짜 : 2021.01.04
2023.02.01 기준 citation : 7306
Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7794-7803).
본 논문은 non-local operator를 신경망에 적용해서 image classification, object detection 등 다양한 CV 태스크에 성능을 올렸다가 전부임.
본 논문에서 소개하는 non-local opeartor는 쉽게 말해 이미지 내에 멀리 떨어져있는 feature 들의 관계를 학습할 수 있게 하는 것임. 근데 논문에서도 밝혔다시피 transformer에서 영향을 받았다고 했는데 transformer를 이미지 데이터에 알맞게 변형한 ViT가 1년인가 2년 후에 나왔음.
ViT(Visual Transformer)는 이미지에 적용할 수 있는 transformer 구조인데, 애초에 transformer 구조 자체가 global + local relationships 을 반영하기 때문에 본 논문처럼 non-local operator가 따로 필요없음
Introduction
첫문장 시작이 다음과 같다.
Capturing long-range dependencies is of central importance in deep neural networks.
여기서 long-range dependency는 말그대로 data sequence나 어떤 input에서 서로 멀리 떨어져있는 element들 사이의 관계를 의미함.
딥러닝에서 long-range dependency가 중요한 이유는 본 논문에는 서술되어있지 않으나, 뇌피셜로 적어보면
-
더욱 meaningful한 representation을 얻기위해. 예를 들어 언어 영역에서 문제를 푼다고 가정할 때, 어떤 대명사가 무엇을 뜻하는지 알려면 그 문장 내부만 보는 것이 아니라 앞 뒤 문장, 또는 글 전체를 파악하고 있어야 함.
-
여러 연구에서 보여졌듯이 성능적인 측면에서 좋아짐. 왜냐하면 이를 고려해서 학습된 모델은 input data가 가지고 있는 context를 더욱 잘 이해할 수 있으니깐
-
1번 이유랑 어느정도 비슷한 건데, 모델이 short-sighted 되는 것을 막아주는 역할도 할 수 있을 것 같음. 전체적인 맥락 또는 context를 파악하지 못하고 local한 정보만 추출하는 모델이 되지 않게 하기위해 long-range dependency를 얻는 것이 중요하다고 할 수 있음.
CNN 같은 경우 global relation을 파악하려면(넓은 receptive field) conv-layer를 많이 쌓거나, pooling layer를 사용해야하는데, 이러한 과정은 계산 비효율, 어려운 최적화 등의 문제가 있음.
따라서 본 논문에는 한번의 연산을 통해 전체 영역의 정보를 얻을 수 있게 하는 non-local operation을 소개함.
Related work
다른 내용도 많지만 본 논문에서는 직설적으로 self-attention에 영향을 많이 받았다고 하기에 이에 대해서만 간략하게 설명함.
우선 [Attention is all you need] 논문에서 transformer 구조를 제안했으며, 최초는 아니지만 self-attention을 적용해서 local, global representation을 모두 얻을 수 있게 학습함.
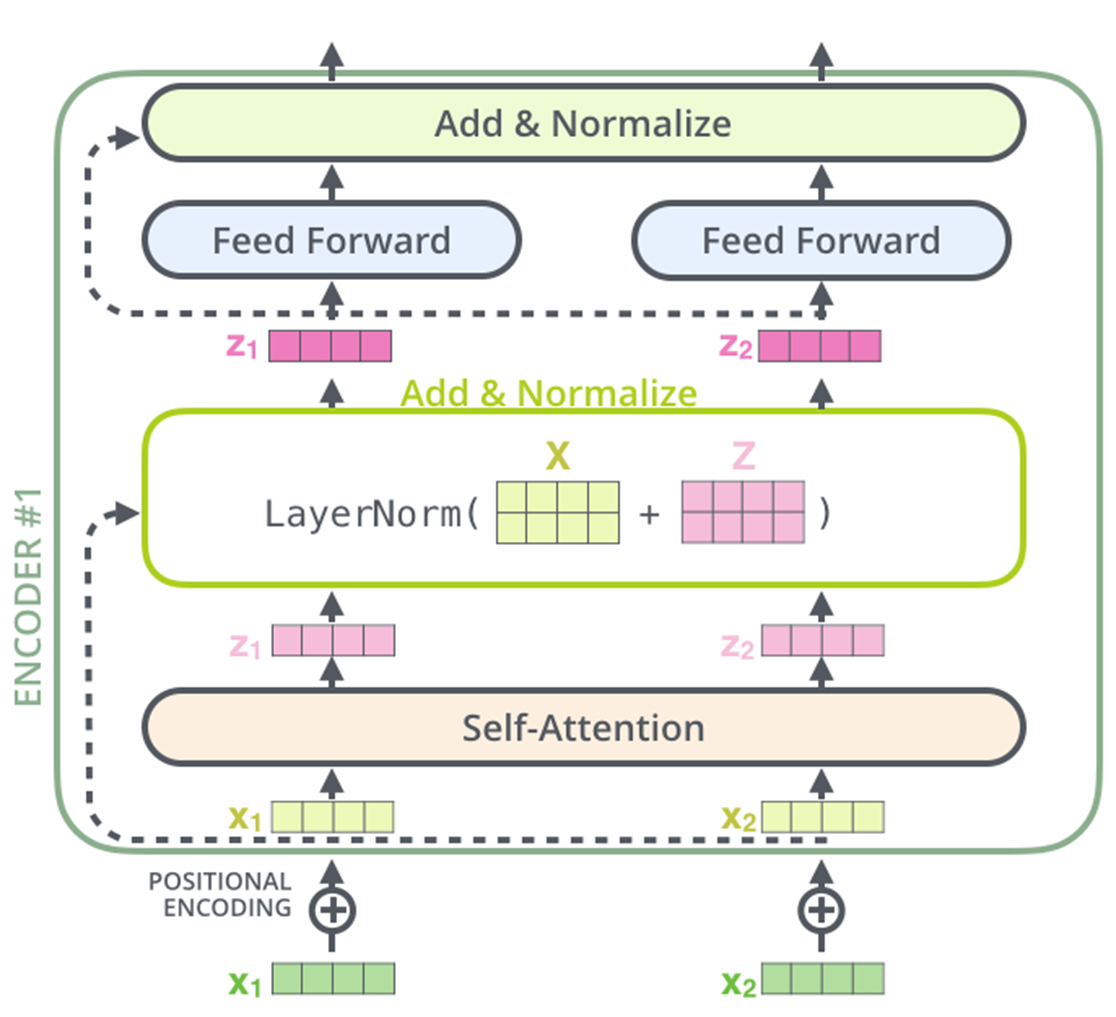
-
어떤 input 이 들어오면, 위치정보 파악할 수 있게 positional encoding을 해주고 self-attention layer로 들어가게 됨.
-
에 대한 Query vector를 만들어주는 , Key vector를 만들어주는 , Value vector를 만들어주는 를 통해 를 계산.
-
아래식을 통해 를 계산
-
그 후에 LayerNorm 이라는 층에 들어가는데 여기서부터는 본 논문과 관련이 없어서 생략.
Non-local Neural Networks
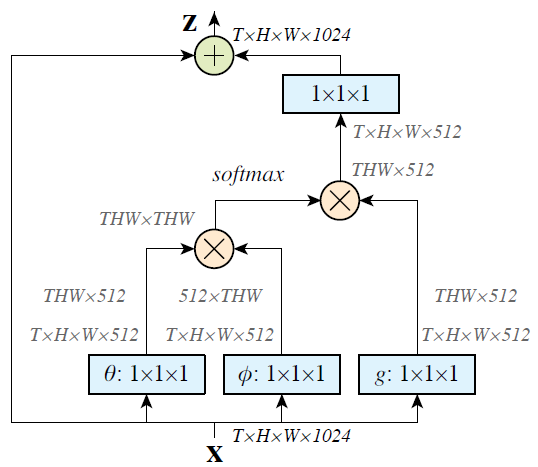
해당 그림은 본 논문의 그림인데 얼추 보더라도 위의 transformer의 encoder에서 self-attention을 계산하는 것과 동일.
어떤 input 가 각각 를 통해 계산되고 그 둘이 어떤 연산을 수행하는 것이 위에서 본 attention 식에서 와 매치됨.
또한 를 통해 얻어진 값과 가 어떤 연산을 수행하는 것도 동일함.
Formulation

는 position에 대한 index임.
이때 는 와 서로 다른 position에 존재하는 모든 사이의 relation을 계산하여 스칼라를 내뱉는 함수.
는 위치에 있는 input 의 representation을 계산해주는 함수임.
Instantiations
본 논문에서는 는 간단하게 그냥 로 정의함.
아까 말했듯이 어떤 두 element 사이의 유사도(relation)을 계산하는 함수인데 Gaussian, Embedded Gaussian, Dot product, Concatenation 을 해보았다고 하는데 식은 각각 아래와 같음.
- Gaussian
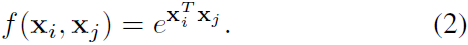
-
Embedded Gaussian

-
Dot product
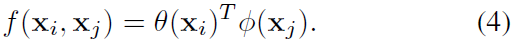
-
Concatenation
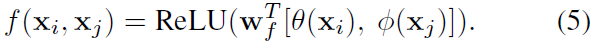
위의 (1) 식을 통해 를 계산하면 마지막으로 non-local block으로 들어감.
Non-local block
다음과 같은 식을 non-local block으로 정의함.

부분은 residual connection 이라고 이해할 수 있음.
Video Classification Models
실험에 사용한 모델들에 대한 설명, implementation details 등
Experiments on Video Classification
주요 실험들만 간단하게 살펴보면 우선

차례대로
-
어떻게 similarity를 계산하는지는 큰 차이가 없지만 global하게 계산해주는 것 자체가 성능에 영향을 미침
-
Non-local block을 어디에 추가했는지에 따른 차이에 대한 실험인데, 마지막에 넣었을 때는 spatial information이 부족하기 때문에 성능이 낮았다고 함.
-
Non-local block을 깊게 쌓았을 때 어떻게 변화하는지 알아본 실험. 일반적으로 더 많이 쌓을수록 좋지만, ResNet-101의 5-block, 10-block을 보면 어느정도 global 정보를 반영하면 saturate 된다는 것을 알 수 있음
-
Non-local block을 time, space, space-time 중 어디에 적용하는 것이 좋은가에 대한 실험인데, 직관적으로도 실험적으로도 space-time에 적용하는 것이 좋음.

Figure 3
위의 실험은 화살표의 시작점이 이고 끝점들은 attention score(편의상 말한건데 본 논문에서는 )가 가장 높은 20개를 보여주는 것임.
제안하는 방법의 취지와 걸맞게 유의미하면서 멀리있는 정보도 반영할 수 있다는 것을 보임.
Extension: Experiments on COCO
위랑 다르게 object detection, instance segmentation 태스크에 대해 수행한 실험.
Critics
-
general task에 대해 적용, ablation study 등 보여줄 수 있는 실험은 모두 한 것 같음
-
사실 related work에 있던 내용인데, 2005년에 나온 논문인 A non-local algorithm for image denoising 에서 영감을 받아서 새롭게 CNN에 적용한 점
-
Transformer의 self-attention 구조를 CNN에 잘 녹인 점
-
또한 Figure 3의 실험이 직관적이면서 제안하는 방법의 효과를 잘 보여주는 것이 좋았음.
-
방법론적인 측면이나 논문 자체에서 크게 단점이라고 생각되는 부분은 없음.
-
를 계산할 때 존재하는 모든 포지션 에 대해 유사도를 계산하는데 이를 조금 개선시킬 수 있지 않았을까
-
Figure 3에서 space relation을 보여주었는데 action recognition task 이기 때문에 time relation도 나타낼 수 있었으면 좋았을 것 같음.
