드디어..! 올해 나의 목표중 하나인 스스로 project를 해보는 velog를 작성하려고 한다.
이 project를 구상하고 구현하기까지 한 3일정도가 걸린 것 같다.
사실 3일정도면 짧은거라고 알고있긴 합니다만..
아무튼 열심히 했다. 오래(?)걸린만큼 이 게시물도 굉~장히 길지 않을까 싶다..
그리고 사실 모델 성능은 그렇게 좋지 못하다..ㅎ
Competetion은 이미 진행된 Plant Pathology 2020 - FGVC7이다.
긴 여정이 될 나의 첫 project !
두구두구..... 시작!
0. Image File Info
우선, 대회에서 제공하는 File의 형식을 알아볼 필요가 있다.
제공 File을 Kaggle에 가져와보니 다음과 같았다.
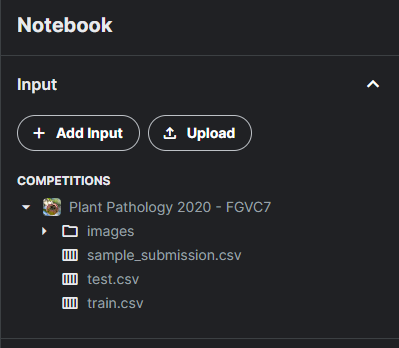
이후에는 다음 코드로 File Info를 시각적으로 확인해보려고 했다.
import numpy as np
import pandas as pd
import os
# Image의 Path를 확인해본 결과 /kaggle/input/plant-pathology-2020-fgvc7/images까지 들어가 각 foriegn key로 들어감.
# jpg파일임
for directory, _, files in os.walk('/kaggle/input/plant-pathology-2020-fgvc7'):
for file_name in files:
path = os.path.join(directory, file_name)
print(path)output
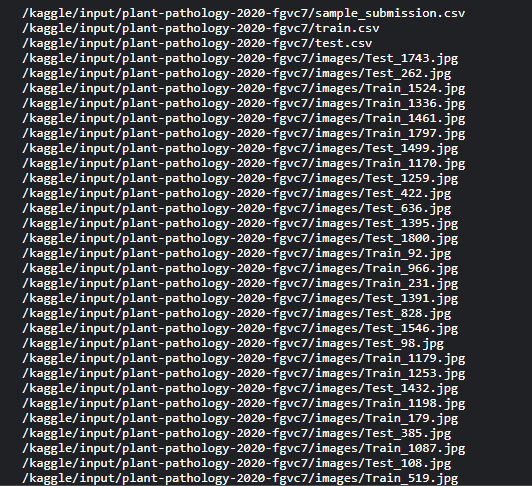
'/kaggle/input ~ images/'이후에는 각 Image name이 있는 것을 확인할 수 있다.
Image의 총 수가 궁금해졌다.
메모리를 생각해야하기 때문에!
Image의 개수를 구하는 코드는 다음으로 작성해봤다.
# 총 Image Data는 3642개임.
paths = []
for directory, _, files in os.walk('/kaggle/input/plant-pathology-2020-fgvc7/images'):
for file_name in files:
path = os.path.join(directory, file_name)
paths.append(path)
print(len(paths))output

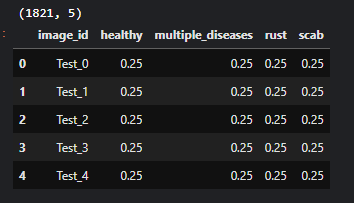
그 이후 대회에서 본보기(?)로 보여준 sample_submission.csv 파일을 열어서 어떤 형태로 제출해야하는지 알아보았다.
# 우선 제출 형식을 알아보았다.
# 1821개 test Image를 각각 확률 예측을 해서 csv파일로 제출하면 될 것 같다.
# image_id 컬럼은 지우면 안되는 것 같다.
sample_submission_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/sample_submission.csv')
print(sample_submission_df.shape)
sample_submission_df.head()output
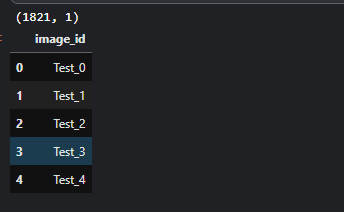
test.csv 파일도 한번 확인해봤다.
test 파일에는 image_id만 나와있다. 이를 이용해서 path를 만들고 위 submit 형식으로 만들어줘야겠다고 생각했다.
# test csv는 image_id만 나와있다.
# 이를 이용하여 submit file을 완성하면 될 듯 하다.
# 경로는 image_id를 이용하여 만들어내면 된다.
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
print(test_df.shape)
test_df.head()output
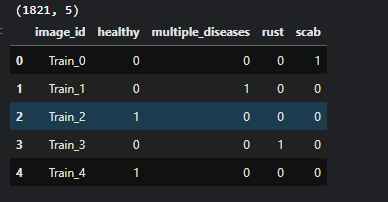
다음은 train.csv 파일을 확인해본 결과다.
# train csv는 image_id, labels로 구성되어있다.
# path를 만들어줘야할 것 같다.
train_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/train.csv')
print(train_df.shape)
train_df.head()output
1. Image Info
이제 파일 형식을 확인해봤으니 Image가 어떻게 되어있는지 확인해봐야한다.
가령, Image의 사이즈가 다를 수도 있기 때문이다. 다행히 여기서는 다 동일한 크기의 Image이다.
다음 코드를 통해 Image를 살펴보았다.
함수 show_grid_image를 잘 기억할것 ! -> 바로 다음 Augmentation에서 쓰임.
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
# Image_Size는 (1365, 2048)인 것을 알 수 있다.
# Size가 크니 메모리 주의를 할 필요가 있다.(BATCH_SIZE조심하기!)
def show_grid_image(paths, ncols=6, augmentor=None):
figure, axs = plt.subplots(figsize=(24, 24), ncols=ncols)
for i, path in enumerate(paths):
image = cv2.cvtColor(cv2.imread(path), cv2.COLOR_BGR2RGB)
if augmentor is not None:
image = augmentor(image=image)['image']
axs[i].imshow(image)
print(image.shape)
show_grid_image(paths[:6])output

Image 크기는 1365 X 2048임을 알 수 있다.
상당히 커서 놀랐다..
아..안돼 메모리..
2. Augmentation
Image Augmentation은 Albumentation을 이용했다.
총 2개를 만들어봤다.
1번은 상하좌우 변화만 가하는 Augmentor.
2번은 1번에 Noise, 선명함을 가하는 Augmentor.
import albumentations as A
# 색의 변화에 민감할 것 같으므로 channel shift와 같은 변화는 주지 않았다.
augmentor_01 = A.Compose([
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5)
])
augmentor_02 = A.Compose([
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.ShiftScaleRotate(shift_limit=0, scale_limit=(0.5, 1.0), rotate_limit=90, p=0.5),
A.RandomBrightnessContrast(brightness_limit=(-0.2, 0.2), contrast_limit=(-0.2, 0.2), p=0.2),
A.Blur(p=0.2),
A.CLAHE(clip_limit=4.0, p=0.5)
])augmentor 1, 2를 적용한 Image 결과를 살펴보자.
show_grid_image(paths[:6], augmentor=augmentor_01)
show_grid_image(paths[:6], augmentor=augmentor_02)output

3. Callback
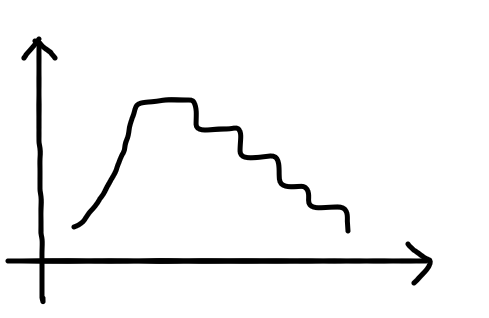
"Model을 fit할 때 Callback함수를 빼먹을 수는 없지!"라는 생각을 하며 Custom Callback을 만들어 보았다.
Learning rate를 조절해주는 함순데 그림으로 표현하면 다음과 같은 느낌..?
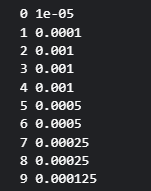
이를 함수로 구현하면
# Custom Callback 함수 만들기
def lrfn(epoch):
LRSTART = 1e-5
LRMAX = 1e-3
DECAYSTEP = 1
DECAYRATE = 0.5
UPSTEP = 3
UPRATE = 10
if epoch < UPSTEP:
return LRSTART * (UPRATE**epoch)
elif epoch == UPSTEP:
return LRMAX
else:
return LRMAX * DECAYRATE**((epoch-UPSTEP)//2)
for i in range(10):
print(i, lrfn(i))output
Callback은 다음으로 총 3개를 만들었다.
사실 원래는 ModelCheckpoint Callback을 안 만들었는데 Model 성능이 왔다갔다해서 넣어봤다.(하지만 그럼에도 결과는 처참했ㄷ..)
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ModelCheckpoint
file_path = '/best_model.weights.h5'
custom_callback = LearningRateScheduler(lrfn, verbose=1)
ely_callback = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)
checkpoint_callback = ModelCheckpoint(filepath=file_path, monitor='val_loss', mode='min', save_best_only=True, save_weights_only=True, verbose=1)4. Sequence Dataset (+ Validation Data)
이 부분은 가장 애를 먹었던 부분이다.(Error가 나를 죽이려고했다.)
Model을 fit할 때 train/valid/test Dataset를 넣어줘야하는데 이때 dataloader를 넣어주기 위해 Sequence Dataset를 만들어줬다.
여기서는 원하는 Batch_Size만큼 Image를 가져와 Augmentation, resize, preprocess 하는 방식으로 작동하게 했다.
from tensorflow.keras.utils import Sequence
import sklearn
class DataLoader(Sequence):
def __init__(self, paths, labels, IMAGE_SIZE, BATCH_SIZE, augmentor, prefunc, Shuffle):
self.paths = paths
self.labels = labels
self.IMAGE_SIZE = IMAGE_SIZE
self.BATCH_SIZE = BATCH_SIZE
self.augmentor = augmentor
self.prefunc = prefunc
self.Shuffle = Shuffle
if self.Shuffle:
pass
def __len__(self):
return int(np.ceil(len(self.paths) / self.BATCH_SIZE))
def __getitem__(self, index):
paths_batch = self.paths[index * self.BATCH_SIZE : (index + 1) * self.BATCH_SIZE]
if self.labels is not None:
labels_batch = self.labels[index * self.BATCH_SIZE : (index + 1) * self.BATCH_SIZE]
image_batch = np.zeros(shape=(paths_batch.shape[0], self.IMAGE_SIZE[0], self.IMAGE_SIZE[1], 3))
for i, path in enumerate(paths_batch):
image = cv2.cvtColor(cv2.imread(path), cv2.COLOR_BGR2RGB)
if self.augmentor is not None:
image = self.augmentor(image=image)['image']
image = cv2.resize(image, (self.IMAGE_SIZE[1],self.IMAGE_SIZE[0]))
if self.prefunc is not None:
image = self.prefunc(image)
image_batch[i] = image
if self.labels is not None:
return image_batch, labels_batch
else:
return image_batch
def on_epoch_end(self):
if self.Shuffle:
self.paths, self.labels = sklearn.utils.shuffle(self.paths, self.labels)
else:
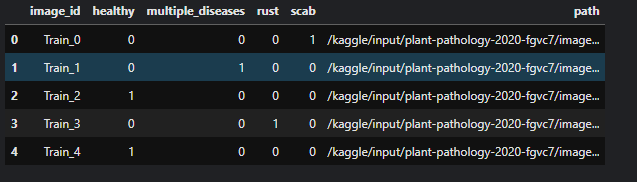
passtrain.csv 파일을 DataFrame 형식으로 바꿔준 후 path를 새로운 칼럼으로 넣어주었다.
train_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/train.csv')
train_df['path'] = '/kaggle/input/plant-pathology-2020-fgvc7/images' + '/' + train_df['image_id'] + '.jpg'
train_df.head()output
다음으로 validation dataset를 만들어주었다.
from sklearn.model_selection import train_test_split
train_paths = train_df['path'].values
train_labels = train_df[['healthy', 'multiple_diseases', 'rust', 'scab']].values
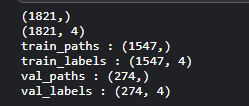
print(train_paths.shape)
print(train_labels.shape)
tr_paths, val_paths, tr_labels, val_labels = train_test_split(train_paths, train_labels, test_size=0.15)
print('train_paths :',tr_paths.shape)
print('train_labels :',tr_labels.shape)
print('val_paths :',val_paths.shape)
print('val_labels :',val_labels.shape)output
이렇게 나누어준 Train/Valid Dataset를 Sequence Dataset로 만들어주었다.
from tensorflow.keras.applications.efficientnet import preprocess_input as efc_pre_func
from tensorflow.keras.applications.xception import preprocess_input as xcp_pre_func
IMAGE_SIZE = [341, 512]
BATCH_SIZE = 4
train_dl = DataLoader(paths=tr_paths, labels=tr_labels, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=augmentor_01, prefunc=xcp_pre_func, Shuffle=False)
val_dl = DataLoader(paths=val_paths, labels=val_labels, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=augmentor_01, prefunc=xcp_pre_func, Shuffle=False)5. Create Model 만들기
이제 DataLoader도 만들어주었으니 학습시킬 Model을 만들어줄 차례다.
나는 여기서 Model을 Xception, EfficientNetB7을 이용할 예정이다.
다음 Create_Model함수를 잘 기억해두자!
막지막 Config할 때 많이 쓰인다.
from tensorflow.keras.applications import Xception, EfficientNetB7
from tensorflow.keras.layers import Input, GlobalAveragePooling2D, Dense, Dropout
from tensorflow.keras.models import Model
# model을 만들어주는 함수.
# xception/efficientb7을 이용.
def Create_Model(model_name, IMAGE_SIZE, nclasses, info=False):
input_tensor = Input(shape=IMAGE_SIZE)
if model_name == 'xception':
pre_model = Xception(include_top=False, weights='imagenet', input_tensor=input_tensor)
elif model_name == 'efficientb7':
pre_model = EfficientNetB7(include_top=False, weights='imagenet', input_tensor=input_tensor)
x = pre_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(units=1000, activation='relu')(x)
x = Dropout(0.5)(x)
preds = Dense(units=nclasses, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=preds)
if info:
model.summary()
return model6. Train Model 만들기
이제 5번 과정에서 만든 Create_Model함수를 이용해 Train 시킬 Model을 만들어야한다.
xception과 efficient Model을 만들었다.
ImageSize는 기존 이미지의 1/4정도로 만들어주었다.
메모리가 터져 나가기 때문에..
IMAGESIZE = (341, 512, 3)
xcp_model = Create_Model(model_name='xception', IMAGE_SIZE=IMAGESIZE, nclasses=4, info=False)
eff_model = Create_Model(model_name='efficientb7', IMAGE_SIZE=IMAGESIZE, nclasses=4, info=False)output

성공!
7. Model 학습시키기
여기서 model_train함수도 잘 기억해두어야 한다!
마찬가지로 Config에서 잘 쓰임
아무튼 앞에서 만들어준 Model을 이용해 Model을 생성한 후 DataLoader로 만들어준 train_dl/val_dl을 이용해 Model을 fit해주는 model_train함수를 만들어주었다.
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import AUC
# optimizer는 Adam으로 설정, metrics는 Competetion에 맞게 AUC를 이용.
def model_train(model_name, epoch, verbose=0):
if model_name == 'xception':
my_model = xcp_model
elif model_name == 'efficientb7':
my_model = eff_model
my_model.compile(optimizer=Adam(0.001), loss = 'categorical_crossentropy', metrics=[AUC()])
my_model.fit(train_dl,
epochs=epoch,
validation_data=val_dl,
callbacks=([custom_callback, ely_callback, checkpoint_callback]),
verbose=1)
return my_modelmodel_train을 이용해 학습시켜봤다.
epoch는 우선 10회로 주었다.
xcp_name = 'xception'
eff_name = 'efficientb7'
epochs = 10
# 우선 model은 xception pretrained model을 이용할거임.
model = model_train(model_name=xcp_name, epoch=epochs, verbose=1)최적의 model을 load해준다.
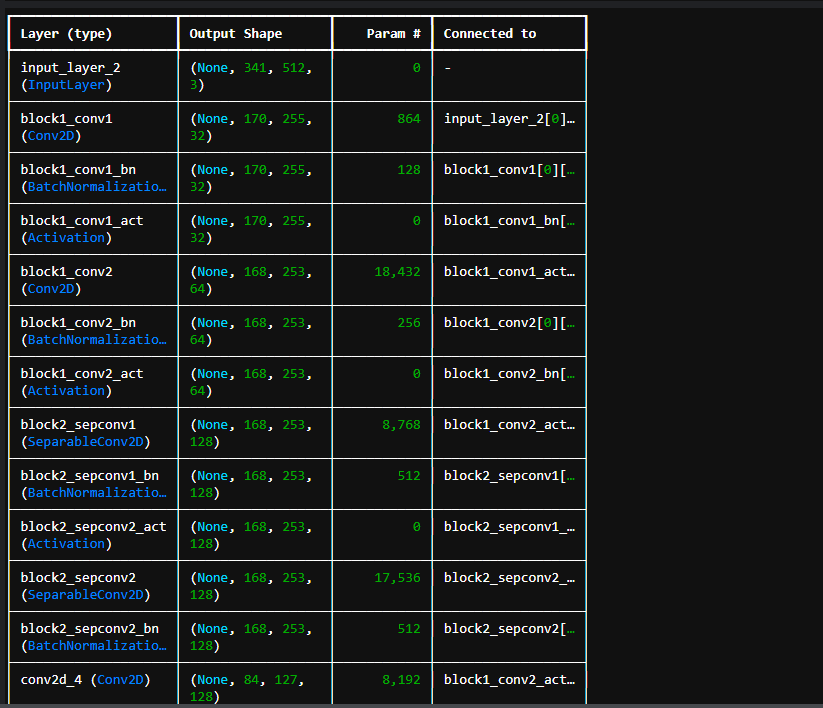
근데 초반에 했을 때 오류(?)가 좀 있었기 때문에 model.summary()를 통해 한번 시각적으로 제대로 Model이 Load되었는지 확인해줬다.
다행히 잘 작동한다.
나중에서야 알게된거지만 여기서 문제가 난게 아니라 test_dataloader를 만드는 부분에서 문제가 생겼다.
from tensorflow.keras.models import load_model
model = load_model(file_path)
model.summary()output
8. test image Predict
Model을 만들어 train도 시켰으니 내가 만든 Model으로 예측해볼 차례다.
test_dataloader를 만든후 predict해줬다.
# test dataloader 만들기(예측 용도 data loader)
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
test_df['path'] = '/kaggle/input/plant-pathology-2020-fgvc7/images' + '/' + test_df['image_id'] + '.jpg'
ts_paths = test_df['path'].values
test_dl = DataLoader(paths=ts_paths, labels=None, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=None, prefunc=xcp_pre_func, Shuffle=False)마지막으로 model.predict로 예측해준다.
예측한 결과는 preds 변수에 받아준다.
preds = model.predict(test_dl)output

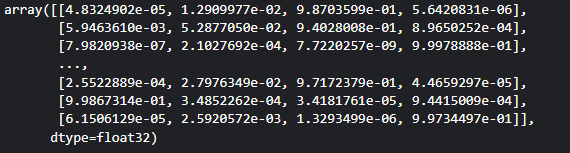
혹시나(?) 하는 마음에 preds를 출력해줬다.
다음과 같이 잘 작동한 것을 알 수 있다.
여기서 예측값이 1.0, 1.0, 1.0, 1.0.... 나오면 뭔가 잘못된 거다! 내가 그랬음..
predsoutput
9. Submit File 만들기
Model 예측값을 받았으니 Competetion에 제출할 csv file을 만들어줘야한다.
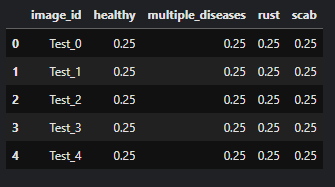
우선, 제출 형식을 보고 만들 수 있도록 다시 시각적으로 출력해봤다.
초반에 한번 출력했지만 너무 멀리있다..
submit_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/sample_submission.csv')
submit_df.head()output
test csv file도 한번 출력해준다.
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
test_df.head()output
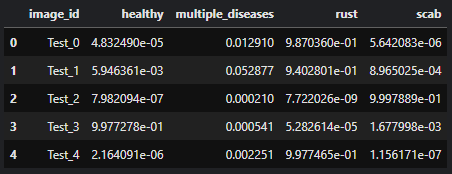
이제 본격적으로 제출할 파일을 만들 차례다.
아래는 앞에서 trained Model이 예측한 preds를 DataFrame으로 만든 후, pandas의 concat을 이용하여 image_id를 붙여넣는 코드이다.
형식에 따르기 위해서 image_id를 넣었다.
predict_df = pd.DataFrame(preds)
predict_df.columns = ['healthy', 'multiple_diseases', 'rust', 'scab']
model_preds_submit_df = pd.concat([test_df, predict_df], axis=1)
model_preds_submit_df.head()output
최종적으로 DataFrame 형식인 model_preds_submit_df를 csv file로 바꾸어준다.
주의할 점은 'index=False'로 해주어야 한다. 제출할 때 index는 필요없기 때문이다.
이렇게 하면 /kaggle/working에 submit01.csv파일이 생긴다.
# submit file 만듬.
submit_csv = model_preds_submit_df.to_csv('submit01.csv', index=False)output
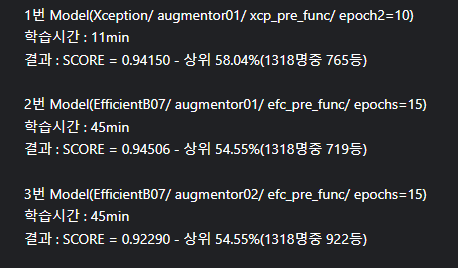
Submit01.csv는 Score : 0.94150로 760~770등 정도이다.(상위 58%)

솔직히 나는 이정도에서 만족했다. 처음으로 해보는 Competetion이기도 했고 자신감도 없었기 때문이다. 하지만 지금까지 배운 모든 방법을 동원해 부딪혀봤다.
10. Model 최적화
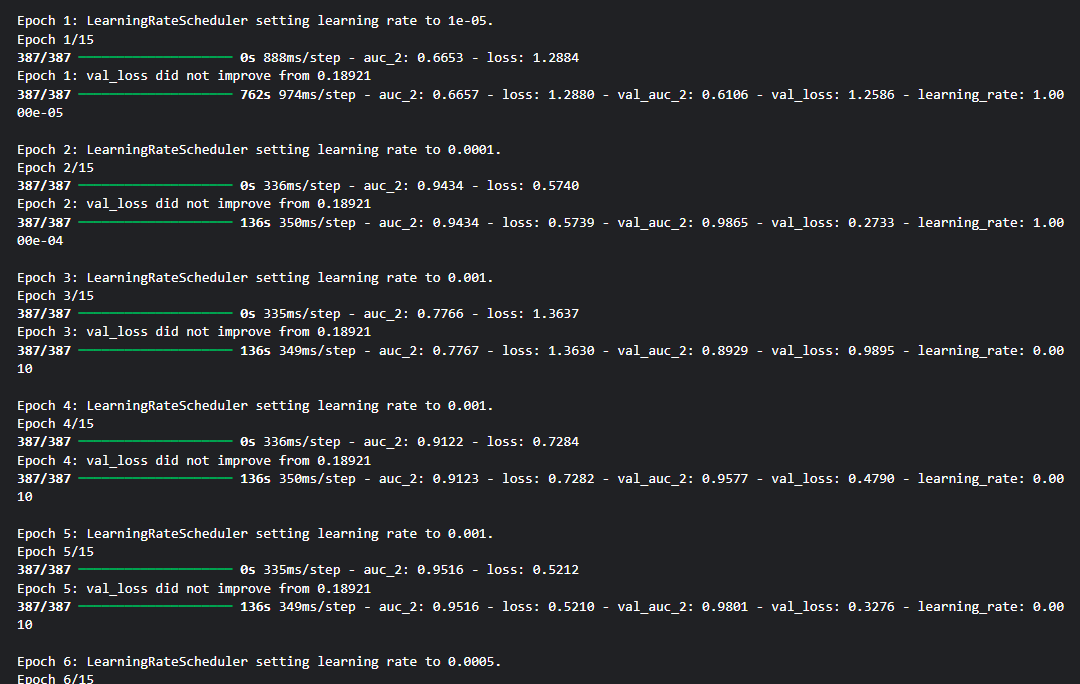
이번엔 Model을 EfficientNetB07로 바꾸고 Epochs= 10->15로 늘려봤다.
model은 그냥 덮어쓰기 했다.
이전 model보다 더 나아질거라는 확신(?)이 있었기 때문에..는 장난이고 실수다..! 하지만 학습시간이 오래걸려서 다시 할 엄두가 안났다.
다.행.히.도 잘 학습이 된 것 같다!
Model 학습 시간은 대략 45분정도 걸린 것 같다.
# epoch 15회로 늘리고 Model은 efficientb07 적용.
epochs = 15
model = model_train(model_name=eff_name, epoch=epochs, verbose=1)output
아까와 같은 방법으로 submit02.csv file을 만들어서 제출해준다.
model.load_weights(file_path)
preds = model.predict(test_dl)
predict_df = pd.DataFrame(preds)
predict_df.columns = ['healthy', 'multiple_diseases', 'rust', 'scab']
model_preds_submit_df = pd.concat([test_df, predict_df], axis=1)
sumit_csv = model_preds_submit_df.to_csv('submit02.csv', index=False)결과는..!
다음과 같이 기존의 0.94150보다 올랐다!(뿌듯)
output

이번에는 Model을 EfficientNetB07로 유지하고 augmentor를 augmetor_02로 변경해준 후 epoch는 15회로 하고 Model을 fit해주려고 한다.
앞에서 augmetation 부분에 augmentor_01과 augmentor_02를 만들었었다.
augmentor_01은 상하좌우 반전만 가능하게 한 light한 augmentor였다.
그렇기에 train_auc는 0.9986정도까지 올랐지만 test에서는 그렇지 못했다.
한마디로 Overfitting이 발생했다.
당연히 이렇게 될 것을 예상(?)하고 좀더 다양한 기법을 적용한 augmentor_02를 만들어 두었다.
다만 노이즈나 색상 변화에는 Image 특성상 민감할 것 같아 자제를 한 augmentor다.
코드는 다음과 같다.
# epoch 15회로 늘리고 Model은 efficientb07, augmentor = augmentor02로 적용.
xcp_name = 'xception'
eff_name = 'efficientb7'
IMAGE_SIZE = [341, 512]
BATCH_SIZE = 4
train_dl = DataLoader(paths=tr_paths, labels=tr_labels, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=augmentor_02, prefunc=efc_pre_func, Shuffle=False)
val_dl = DataLoader(paths=val_paths, labels=val_labels, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=augmentor_02, prefunc=efc_pre_func, Shuffle=False)
epochs = 15
model = model_train(model_name=eff_name, epoch=epochs, verbose=1)output
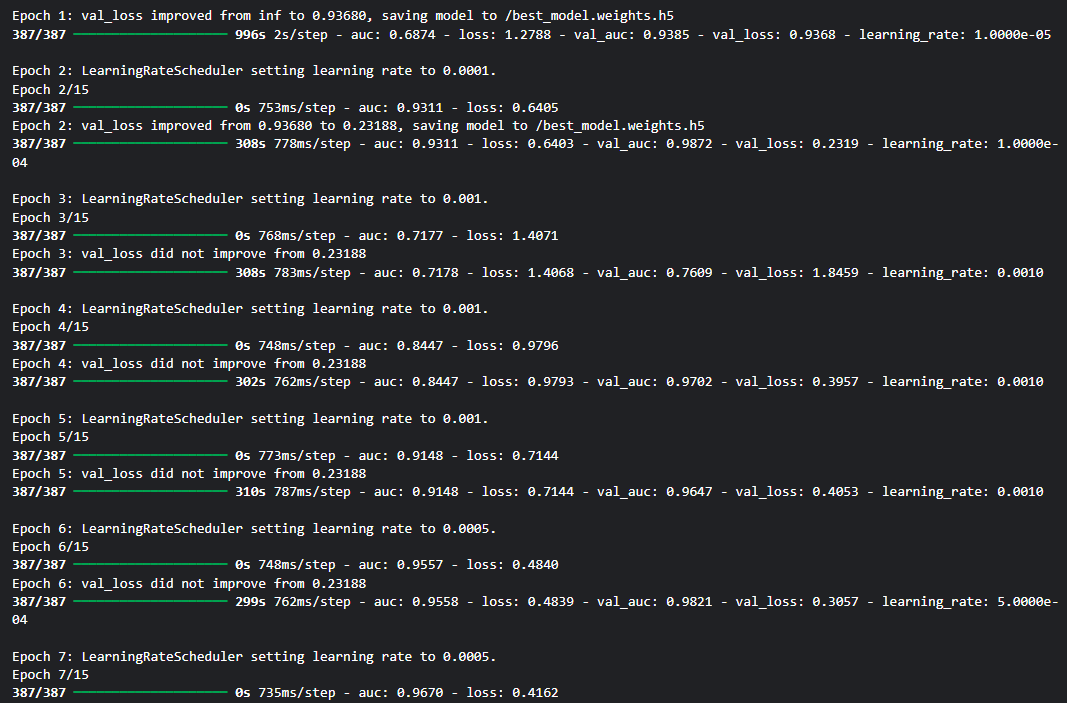
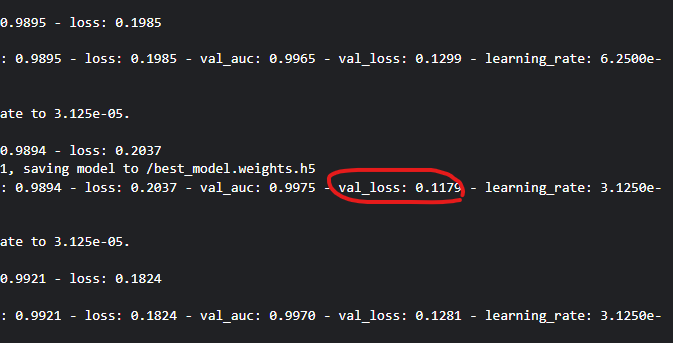
아직 test_image에 적용은 안해봤지만 느낌이 좋다..!
val_loss가 0.1179로 기존보다 더 감소했기 때문이다.
다음으로 기존과 마찬가지로 Trained Model을 이용해 test_dl을 예측해보고 submit.csv를 만들었다.
model.load_weights(file_path)
# test dataloader 만들기(예측 용도 data loader)
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
test_df['path'] = '/kaggle/input/plant-pathology-2020-fgvc7/images' + '/' + test_df['image_id'] + '.jpg'
ts_paths = test_df['path'].values
test_dl = DataLoader(paths=ts_paths, labels=None, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=None, prefunc=efc_pre_func, Shuffle=False)
preds = model.predict(test_dl)
predict_df = pd.DataFrame(preds)
predict_df.columns = ['healthy', 'multiple_diseases', 'rust', 'scab']
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
model_preds_submit_df = pd.concat([test_df, predict_df], axis=1)
sumit_csv = model_preds_submit_df.to_csv('submit03.csv', index=False)성공!
이렇게 제출을 했는데..

성능이 더 떨어져버림..
augmentor의 blur때문인가..?
여기서 더 augmentor를 변경시키기에는 내가 너무 지쳤다.. 그냥 도전에 의의를 두자.. 현재 내 한계는 상위 54퍼인걸로,,
11. Config
마지막으로 지금까지 작성한 진행과정을 최대로 줄여서 함수화 시켜봤다.
Class Config에는 변수를 원하게 바꿔주면 된다.
# sequence dataset을 만드는 과정부터 Model train까지 필요한 정보들 class config로 구성하기.
class Config:
# 아래로 DataLoader에 필요한 정보들
TR_PATHS = tr_paths
TR_LABELS = tr_labels
VAL_PATHS = val_paths
VAL_LABELS = val_labels
IMAGE_SIZE = IMAGE_SIZE
BATCH_SIZE = BATCH_SIZE
AUGMENTOR = augmentor_02
PRE_FUNC = efc_pre_func
SHUFFLE = False
# 아래로 Create Model/Train Model에 필요한 정보들
MODEL_NAME = 'efficientb7'
MODEL_IMAGESIZE = IMAGESIZE
NCLASSES = 4
INFO = False
EPOCHS = 15
VERBOSE = 1def DataLoader_to_Train_Model(config=Config):
train_dl = DataLoader(paths=config.TR_PATHS,
labels=config.TR_LABELS,
IMAGE_SIZE=config.IMAGE_SIZE,
BATCH_SIZE=config.BATCH_SIZE,
augmentor=config.AUGMENTOR,
prefunc=config.PRE_FUNC,
Shuffle=config.SHUFFLE)
val_dl = DataLoader(paths=config.VAL_PATHS,
labels=config.VAL_LABELS,
IMAGE_SIZE=config.IMAGE_SIZE,
BATCH_SIZE=config.BATCH_SIZE,
augmentor=config.AUGMENTOR,
prefunc=config.PRE_FUNC,
Shuffle=config.SHUFFLE)
my_model = Create_Model(model_name=config.MODEL_NAME, IMAGE_SIZE=config.MODEL_IMAGESIZE, nclasses=config.NCLASSES, info=config.INFO)
my_model.compile(optimizer=Adam(0.001), loss = 'categorical_crossentropy', metrics=[AUC()])
my_model.fit(train_dl,
epochs=config.EPOCHS,
validation_data=val_dl,
callbacks=([custom_callback, ely_callback]),
verbose=config.VERBOSE)
return my_modeldef Preds_Model_to_Submit_csv(file_name, config=Config):
my_model = DataLoader_to_Train_Model()
test_dl = DataLoader(paths=ts_paths, labels=None, IMAGE_SIZE=IMAGE_SIZE, BATCH_SIZE=BATCH_SIZE, augmentor=None, prefunc=None, Shuffle=False)
preds = my_model.predict(test_dl)
test_df = pd.read_csv('/kaggle/input/plant-pathology-2020-fgvc7/test.csv')
predict_df = pd.DataFrame(preds)
predict_df.columns = ['healthy', 'multiple_diseases', 'rust', 'scab']
model_preds_submit_df = pd.concat([test_df, predict_df], axis=1)
submit_csv = model_preds_submit_df.to_csv(file_name, index=False)
return submit_csvfile_name = 'submit04.csv'
submit_csv = Preds_Model_to_Submit_csv(file_name)이상 여기까지 나의 '첫' 프로젝트였다.
나는 나름대로 성공이였다고 믿고싶다.
최선을 다해 공부한 CNN이었고 성능이 평범했더라도, 1300명중 700등을 했더라도 아직 내가 발전할 가능성은 무궁무진하다고 생각한다.
앞으로는 Object Detection 등 다른 기법을 공부해보려고 한다.
그럼에도 CNN은 따로 project나 책이나 영상을 보며 공부하려고 한다.
아직 부족하다. 많이 부족하다. 계속해서 가보자..
12. Model predict submit
이건 뭐.. 처참한 결과다 ㅎ
배운점
1. train/validation DataLoader를 preprocess하는 과정을 취했으면 test DataLoader에서도 마찬가지로 같은 preprocess function을 취해줘야한다.
2. validation DataLoader를 만들때 Augmentation 기법을 적용하지 않는게 좋다.
