권철민님의 '딥러닝 CNN 완벽 가이드 - Fundamental 편'을 보며 직접 손코딩으로 따라해보며 공부하는 노트입니다. 데이터는 Keras CIFAR10을 이용합니다. Framework는 Tensorflow를 사용합니다.
계속해서 CNN공부를 하고있는 요즘 강의를 계속 듣다가 한번쯤은 멈춰줘야할 것 같다는 생각이 들어서 주말 하루를 이 velog에 썼다.
뭔가.. 강의 듣고 약간만 따라서 해보고 "아~ 그렇구나."라면서 넘어갔는데 남는게 없는 느낌?
그래서 본격적으로 CNN Model을 구현하고 Data를 전처리하고 ImageDataGenerator를 이용해서 Model을 fit하고 evaluation하는 과정까지 한땀한땀 따라하며 적어냈다.
지금까지 공부한 걸 한번에 테스트하며 정리하는 느낌(실제로도 그렇다)
필요한 경우에는 정식 사이트에도 들어가보고 블로그,벨로그,티스토리 등 '직접' 찾아봤다.
느낀점은 확실히 중간에 한번쯤은 멈춰줘야한다는 것.
확실하게 내것으로 만들기 위해서는 달려가다가 다시 돌아볼 것. 멈추는 건 느린게 아닌 용기인 것 같다. 사실 이 velog를 쓰기전에 "이럴 시간에 강의 하나라도 더 보는 게 낫지 않을까?"라는 생각도 들었지만 velog를 쓰면서 내 머릿속에서 정리되는 것이 느껴졌고 현재 내가 부족한 점이 무엇인지 확실히 알게 되었다.
"이 모든 것이 내 자산이 되면 좋겠다. 훗날 내가 다시 내 기록을 보고 자신감을 얻고, 다시 공부하는 글이 되면 좋겠다. 이 모든게 훗날 내 성장의 발판이 되었으면 좋겠다."
CIFAR10 다운/ 데이터 전처리(Preprocessing)
import numpy as np
import pandas as pd
import os
# tensorflow Module 불러오기
import tensorflow as tf
# seed를 맞추기 위한 Module 불러오기
import random as python_random
# keras.utils의 to_categorical Module을 이용하여 OneHotEncoding 하기 위한 Module
from tensorflow.keras.utils import to_categorical
# sklearn.model_selection의 train_test_split Module -> tr data와 val data만들기 위한 Module
from sklearn.model_selection import train_test_split
# cifar10
from tensorflow.keras.datasets import cifar10tensorflow.keras.datasets에 있는 CIFAR10 Datasets를 load합니다.
cifar10은 총 10가지 종류로 된 이미지가 존재합니다.
지금 하는 과정은 데이터 전처리(Preprocessing) 과정으로 Data를 scaling하여 0~1값으로 바꿔준 뒤 OneHotEncoding을 진행합니다. 딥러닝 Model은 작은 숫자값의 데이터가 들어오는 것을 좋아합니다.
OHE(OneHotEncoding)을 적용하는 이유는 마지막 CNN Model에서 최종 Activation을 Sigmoid가 아닌 Softmax를 이용하기 때문입니다.
OHE를 적용한 이후에는 CIFAR10 데이터를 train_data와 valid_data로 split해줍니다.
split해주는 이유는 train_data에 대한 Overfitting을 방지하기 위해서입니다.
# seed를 설정해서 학습시마다 동일한 결과 유도
def set_random_seed(seed_value):
np.random.seed(seed_value)
python_random.seed(seed_value)
tf.random.set_seed(seed_value)
# 0 ~ 1 사이값의 float32로 변경
def get_preprocessed_data(images, labels, scaling=True):
# scaling = True면 여기 함수에서 scaling을 진행하지만 이번 공부에서는 ImageDatagenerator에서 할거임.
if scaling:
images = np.array(images/255.0, dtype=np.float32)
else:
images = np.array(images)
return images, labels
# OHE 적용하는 함수
def get_preprocessed_ohe(images, labels):
images, labels = get_preprocessed_data(images, labels, scaling=False)
# OHE 적용
oh_labels = to_categorical(labels)
return images, oh_labels
# 학습/검증 데이터 세트 나누고 학습/검증/테스트 데이터 세트 OHE적용
def get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.15, random_state=2021):
train_images, train_oh_labels = get_preprocessed_ohe(train_images, train_labels)
test_images, test_oh_labels = get_preprocessed_ohe(test_images, test_labels)
train_images, val_images, train_oh_labels, val_oh_labels = train_test_split(train_images, train_oh_labels, test_size=valid_size, random_state=random_state)
return (train_images, train_oh_labels), (val_images, val_oh_labels), (test_images, test_oh_labels)
set_random_seed(2021)
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
(tr_images, tr_oh_labels), (val_images, val_oh_labels), (test_images, test_oh_labels) = get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.15, random_state=2021)
print(tr_images.shape, tr_oh_labels.shape, val_images.shape, val_oh_labels.shape, test_images.shape, test_oh_labels.shape)output
(42500, 32, 32, 3) (42500, 10) (7500, 32, 32, 3) (7500, 10) (10000, 32, 32, 3) (10000, 10)
CIFAR10 Image
우선 CIFAR10 데이터가 어떤 그림인지 확인해볼 필요가 있다.(matplotlib도 연습해볼겸..)
show_images()함수를 선언하여 앞으로 필요시 쉽게 원하는 데이터를 확인할 수 있다.
CIFAR10의 Labels인덱스에 따른 정답은 ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']이다.
show_images()에서 squeeze연산을 하는 이유는 labels[i]는 Vector다.([a]꼴)
squeeze 연산을 여기에 적용하면 Scalar가 되므로 Index로서 활용 가능하므로 np.squeeze를 이용한다. 참고로 확장은 np.expand_dims()이다.(labels 자체는 numpy array이므로 squeeze 사용)
# CIFAR10 이미지를 개괄적으로 확인하기 위해 matplotlib이용
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
# CIFAR10의 인덱스에 따른 정답
names = np.array(['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'])
# Image와 Label을 넣은 정답과 사진을 보여주는 함수
def show_images(images, labels, ncols=8):
figure, axs = plt.subplots(figsize=(22, 6), nrows=1, ncols=ncols)
for i in range(ncols):
axs[i].imshow(images[i])
# labels[i]는 vector이므로 scalar로 변
label = labels[i].squeeze()
axs[i].set_title(names[int(label)])
show_images(train_images[:8], train_labels[:8], ncols=8)
show_images(train_images[8:16], train_labels[8:16], ncols=8)output

Model Compile 생성/ Compile
# CIFAR10 Image size는 (32, 32, 3)이므로 Size는 32로 설정
IMAGE_SIZE = 32
# BATCH_SIZE는 32일때 Model 성능이 좋았으나 시간문제로 64로 설정
BATCH_SIZE = 64keras의 ImageDataGenerator를 이용하여 Data를 Augmentation한다.
주의할 점은 학습 데이터는 Augmentation을 하지만 검증 데이터는 하면 안된다.(rescale 제외)
검증 데이터는 Model의 성능을 시험하는 단계이기 때문이다.
다만, 학습 데이터를 rescale했으므로 검증 데이터 또한 rescale해야한다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Data Augmentation 적용하기 위해 keras.preprocessing.image 의 ImageDataGenerator Module 이용
train_generator = ImageDataGenerator(
horizontal_flip=True,
# 앞선 전처리 과정에서 scale=False로 두었기에 여기서 진행
rescale=1/255.0
)
# 검증 데이터는 rescale만 진행해야함.
valid_generator = ImageDataGenerator(rescale=1/255.0)
flow_tr_gen = train_generator.flow(tr_images, tr_oh_labels, batch_size=BATCH_SIZE, shuffle=True)
flow_val_gen = valid_generator.flow(val_images, val_oh_labels, batch_size=BATCH_SIZE, shuffle=False)가장 지겨운 순간이었다..
CNN Model을 만드는 일. 공부한 것을 일일이 타이핑치니 손목이 많이 아팠다..
create_model이라는 함수를 선언해준다. Model을 만들때 이 함수를 이용하여 Model을 바로 만들 수 있다. input값으로는 CIFAR10 데이터가 들어오는데 CIFAR10 데이터는 (60000, 32, 32, 3)크기이므로 shape = (32, 32, 3)으로 설정한다. (Batch Size는 제외하므로)
그다음 Filter개수를 늘려가면서 CNN Model을 만들어준다.
Conv2D에 바로 Activation을 집어넣지 않은 이유는 Batch Normalization을 진행하기 위해서다. Batch Normalization을 진행함으로써 데이터가 왜곡되지 않도록 도와준다.
Batch Normalization을 진행하고 Activation은 Relu를 적용했다.
MaxPooling도 적용해주어 classification layer와 연결하기 쉽도록(?) 해준다. 그리고 이미지의 특징을 더 잘 뽑아내게 해준다.
Classification layer에서는 feature map을 Flatten하는 기법 대신에 GlobalAveragePooling하는 기법을 선택했다.
GAP 연산을 이용하면 기존의FC layer에 비해 location 정보를 덜 잃게된다. 물론 그렇다고 Flatten이 GAP에 비해 무조건적으로 안 좋은건 아니다. Channel수가 상대적으로 많으면 GAP가 더 좋은 성능을 낸다랄까..
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Conv2D, Dropout
from tensorflow.keras.layers import Flatten, Activation, MaxPooling2D, GlobalAveragePooling2D
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping, LearningRateScheduler
def create_model(verbose=False):
# 4차원이 들어오므로 3차원 입력(batch_size 제외)
input_tensor = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(input_tensor)
x = BatchNormalization()(x)
# Activation은 Relu
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# MaxPooling 적용
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=128, kernel_size=3, padding='same')(x)
x = Activation('relu')(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=2)(x)
x = Conv2D(filters=256, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=256, kernel_size=3, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# strides=2일때 Padding=same이면 input과 output 크기가 같아지는게 아님
# 남는 공간이 없도록 바꿔주는 역할을 Padding이 수행함
x = Conv2D(filters=512, kernel_size=3, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# Classiffication layer
x = GlobalAveragePooling2D()(x)
x = Dropout(rate=0.5)(x)
x = Dense(50, activation='relu')(x)
x = Dropout(rate=0.2)(x)
output = Dense(10, activation='softmax', name='output')(x)
model = Model(inputs=input_tensor, outputs=output)
if verbose:
model.summary()
return model그 다음으로 model을 이전에 만든 create_model()로 만들고 Compile해준다.
Optimizer는 Adam, Loss Function은 categorical_crossentropy를 이용했다. crossentropy에는 binary crossentropy와 categorical crossentropy가 있다.
하지만 마지막 layer에서 activation을 softmax로 두었기 때문에 categorical crossentropy를 사용했다.
만약 sigmoid같은 이진 분류 activation이었다면 binary crossentropy를 이용했을 것이다.
callbacks는 learning rate를 업데이트 시켜주는 ReduceLROnplateau, 성능이 계속해서 나아지지 않을 때 조기에 멈춰주는 EarlyStopping을 사용한다.
monitor는 검증 데이터의 loss로 하고 loss는 작을수록 좋기 때문에 mode는 min으로 한다.
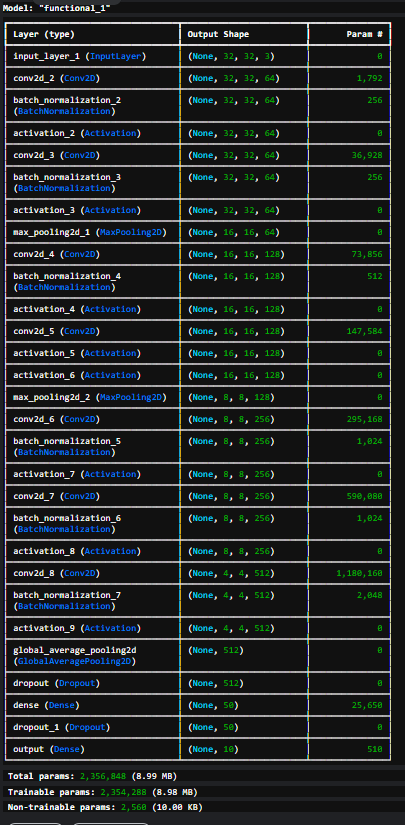
model = create_model(verbose=True)
model.compile(optimizer=Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, mode='min', verbose=1)
ely_cb = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)output
그리고 model.fit을 해준다.(학습을 시켜준다)
이때 학습 데이터와 검증 데이터는 앞서서 ImageDataGenerator에 flow해주었기 때문에 model.fit에 그대로 넣어주면 된다. callbacks는 앞서 만든 EarlyStopping과 ReduceLROnplateau를 이용한다. epoch는 40회로 한다.
generator를 iteration시켜주면 그때서야 input값이 Augmentation된다. 그때 fit의 인자인 x, y가 반환되므로 x=generator해주면 x,y가 나오므로 y 데이터는 입력해주지 않아도 된다.(x=images, y=labels)
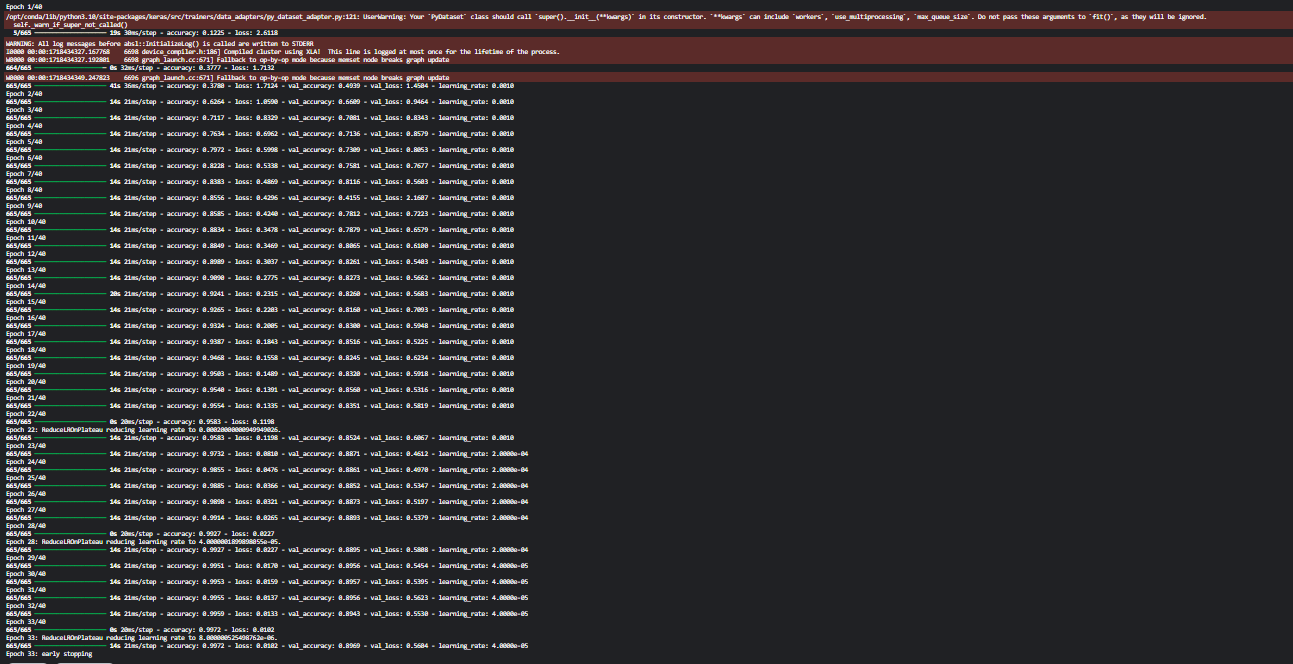
history = model.fit(flow_tr_gen, epochs=40,
validation_data=flow_val_gen,
callbacks=[rlr_cb, ely_cb])output
Model을 fit했으니 evaluate해봐야한다.
그런데 이렇게 코드를 한땀한땀 따라서 공부해보다가 Model의 evaluation이 어떻게 작동하는지 궁금해졌다.
결론은 해결 못함... 많이 찾아봤는데 내 검색능력(?)이 부족해서인지 잘 모르겠다. 이건 차차 더 공부해보기로 했다.
아무튼 우리가 학습시킨 Model을 evaluate시킨다. 이때도 마찬가지로 ImageDataGenerator를 이용한다. 아까 말했듯이 return값이 x, y(images, labels)이기 때문에 하나만 입력한 것으로 보인다.
여기서 주의할 점은 마지막 test_generator도 검증 데이터 generator와 마찬가지로 flip과 같은 Augmentation을 적용하면 안된다는 점이다. 학습 데이터를 Augmentation한 이유는 test_data나 val_data에 대해서 좋은 성능을 내기 위한 것이다. test_data와 val_data는 바뀌지 않는 것이다.
다만, rescale은 해줘야한다. 학습 데이터의 범위가 0~1로 Normalization 했기 때문이다.
# Model을 test할때도 ImageDataGenerator 이용
test_generator = ImageDataGenerator(rescale=1/255.0)
flow_test_gen = test_generator.flow(test_images, test_oh_labels, batch_size=BATCH_SIZE, shuffle=False)
model.evaluate(flow_test_gen)output

성능은 보다시피 정확도 89%로 나쁘지는 않았지만 이게 최선같지는 않다.
과도한(?) Augmentation을 적용하면?
이부분은 간단하게 넘어갈 것이다.
왜냐하면 학습하려는 데이터 CIFAR10의 특성상 조금만 더 Augmentation을 해줘도 Model 성능이 떨어지기 때문이다. 실제로 우리가 32by32by3짜리의 이미지를 볼 일은 거의 없다.
한마디로 아래 코드정도의 Augmentation은 과한 Augmentation 적용이 아니라는 말이다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_generator = ImageDataGenerator(
rotation_range=20,
zoom_range=(0.7, 0.9),
horizontal_flip=True,
vertical_flip=True,
rescale=1/255.0
)CIFAR10 데이터 기준으로 저정도의 Image Augmentation을 적용하면 성능이 저하된다고 한다.
하지만 그것은 CIFAR10 데이터가 화질이 너무 나쁘기 때문에 더 그런 것 같다.
여기서의 핵심은 다시 한번 말하지만 이정도는 전혀 과한 Augmentation이 아니다.
Error In Studying/ 궁금증
① tensorflow.keras.layers import Sequential, Model -> keras.models...
Sequential, Model은 keras.layers에 있는게 아니라 keras.models에 있다.

② MaxPooling()() -> MaxPooling()(x)...
Functional API 쓸 때 func()(x) inputs 꼭 넣어주어야한다.
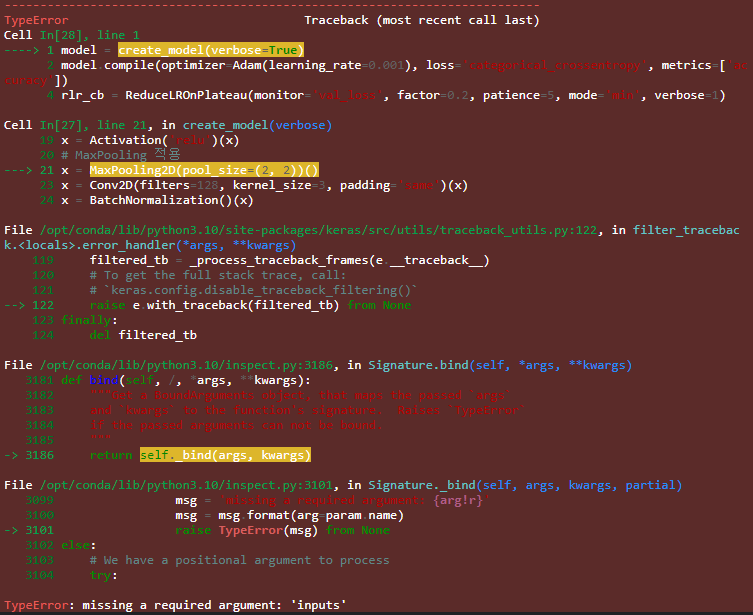
③ 이거는 error까진 아닌데 왜 나는건지 잘 모르겠다.
뭐가 막 무시당했다? 막 그러는데.. 열심히 찾아봐도 잘 안 나온다.. 더 찾아봐야겠다.

④ evaluate의 작동 원리..? 어디서 찾아봐야하냐....
참고자료
#참고자료1
train_test_split 사용 방법 및 데이터를 train /test(validation) 분리 이유
#참고자료2
06-08 벡터와 행렬 연산
#참고자료3
1_2. tf.keras.layers.Dropout
#참고자료4
문과생도 이해하는 딥러닝 (10) - 배치 정규화
#참고자료5
[딥러닝] 풀링(Pooling) 왜할까?
#참고자료6
GAP (Global Average Pooling) : 전역 평균 풀링
#참고자료7
손실함수 간략 정리(예습용)

내용이 개 에바네요