1. 합성곱 신경망의 구성요소
(1) 합성곱 신경망(CNN, Convolutional Neural Network)
1) 합성곱(convolution)
합성곱 연산은 주로 컴퓨터 비전 및 이미지 처리와 관련된 딥러닝에서 사용되는 중요한 개념 중 하나이다. 이 연산은 이미지에서 특징을 추출하는 데 도움을 준다.
합성곱은 작은 kernel(filter)를 사용해 input 이미지를 훑으면서 각 지역의 특징을 추출한다. 이 필터는 입력 이미지의 작은 부분과 가중치를 곱하고, 그 결과를 모두 더해 특정한 feature map을 생성한다.
이미지 분석에서 사용되는 합성곱은 아래와 같은 형태로 진행된다.
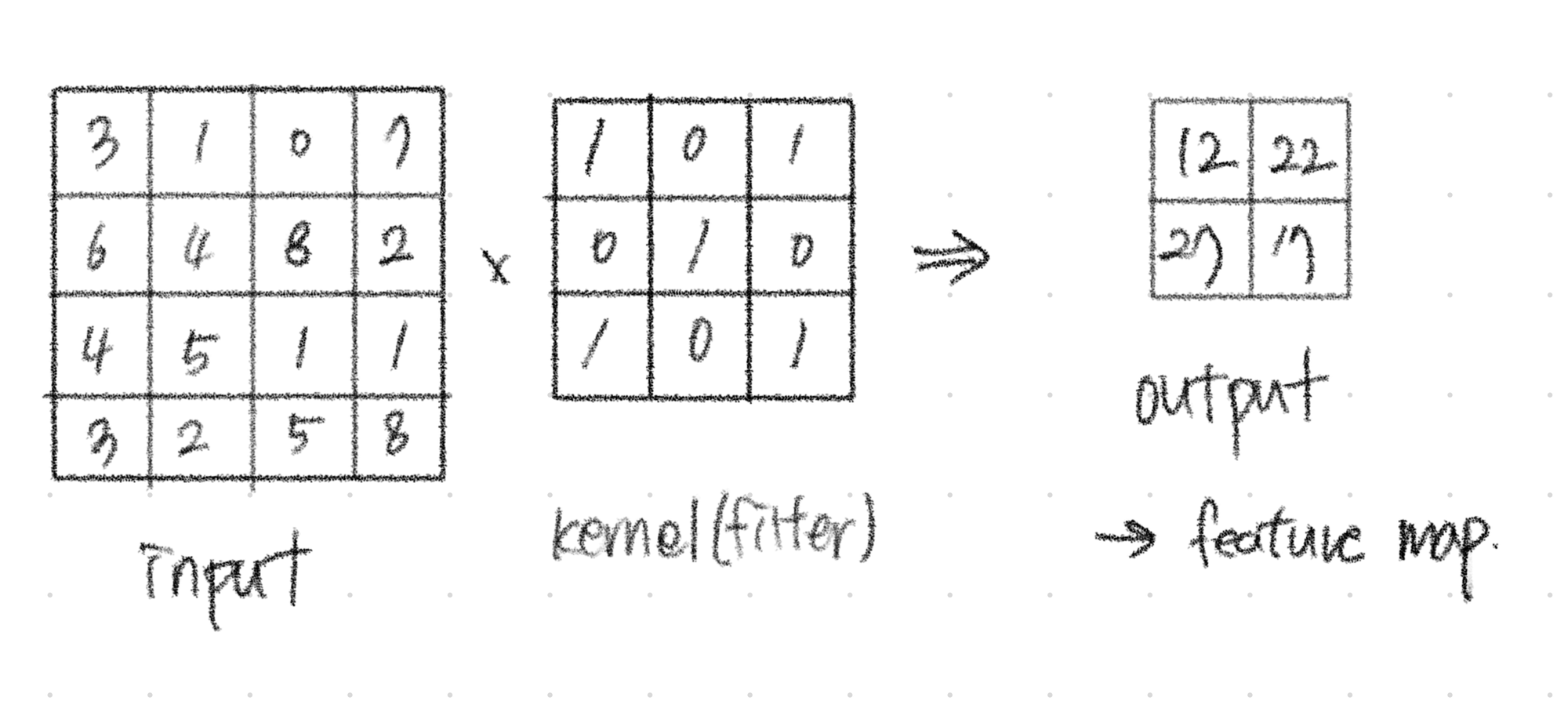
2) 합성곱 신경망(CNN)
합성곱 신경망(CNN)은 한 개 이상의 합성곱 층을 쓴 인공 신경망을 말한다. CNN의 중요 포인트는 이미지 전체보다는 부분을 보는 것, 그리고 이미지의 한 픽셀과 주변 픽셀들의 연관성을 살리는 것이다.
(2) 프로세스
- 입력 레이어 (Input Layer): 이미지나 다른 형태의 데이터가 입력된다.
- 합성곱층 (Convolutional Layer): 이 층에서는 입력 이미지에 여러 개의 필터를 적용하여 특징 맵(feature map)을 생성한다. 각 필터는 입력 데이터의 특정 특징을 감지하는 역할을 한다.
- 활성화 함수 (Activation Function): 주로 ReLU(Rectified Linear Unit)를 사용하여 특징 맵의 비선형성을 도입한다.
- 풀링층 (Pooling Layer): 공간 차원을 줄이기 위해 특징 맵을 다운샘플링한다. 주로 최대 풀링(MaxPooling)이 사용되며, 가장 중요한 정보를 유지하면서 공간 해상도를 감소시킨다.
- 완전 연결층 (Fully Connected Layer): 특징 맵을 1차원 벡터로 평탄화하고, 이를 기반으로 신경망을 구축한다. 이 층에서는 전체적인 패턴을 학습한다.
- 출력층 (Output Layer): 최종 결과를 출력한다. 분류 문제의 경우 클래스에 대한 확률을 제공하고, 회귀 문제의 경우 예측값을 출력한다.
- 손실 함수 (Loss Function): 네트워크의 출력과 실제 값 간의 차이를 측정하여 손실을 계산한다.
- 역전파 (Backpropagation): 손실을 최소화하기 위해 역전파 알고리즘을 사용하여 각 층의 가중치를 조정한다.
- 최적화 (Optimization): 경사 하강법과 같은 최적화 알고리즘을 사용하여 가중치를 조정하고 모델을 훈련시킨다.
(3) 다양한 세부 내용
1) 패딩(Padding)
입력 데이터의 차원을 조절하는 방법이다. 출력 크기를 보장하기 위해 사용되며, 입력 데이터의 사방을 특정 값으로 채우는 것을 말한다.
- 밸리드 패딩(valid padding)
우리가 지금까지 다루었던 즉 패딩을 추가 하지 않은 형태는 엄밀히 말하면 밸리드 패딩(valid padding)을 적용했다고 한다. 이렇게 밸리드 패딩을 적용하고 필터를 통과시키면 그 결과는 항상 입력 사이즈보다 작게 된다.
위에서 언급했던 convolution 모형이 valid padding을 나타낸 것이다. - 풀 패딩(full padding)
밸리드 패딩에서 원소의 연산 참여도가 모두 같은 비율이 아니라는 문제가 발생하기 때문에 그 문제를 해결하기 위해 만들어낸 새로운 패딩 방식이다.
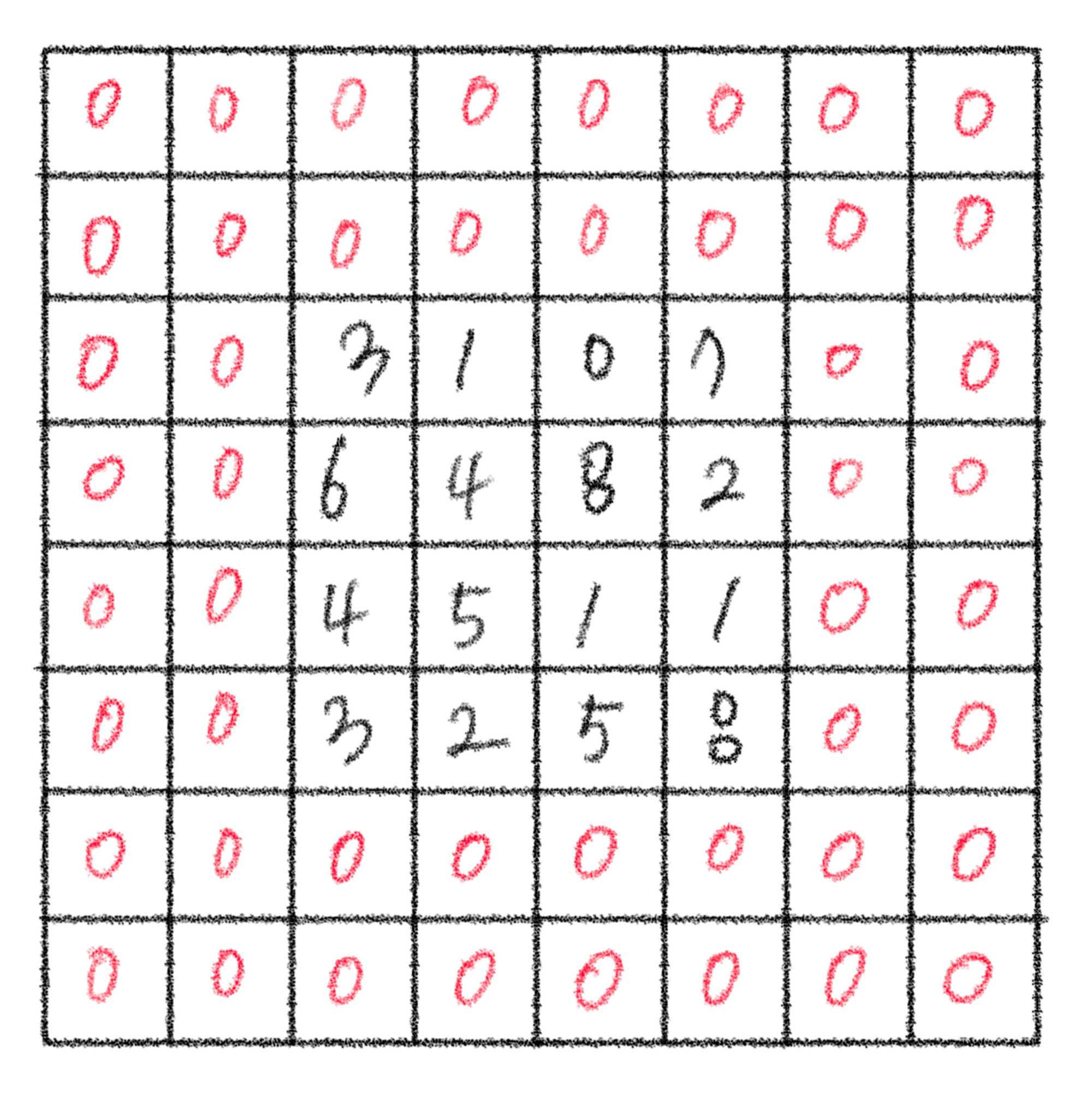
- 세임 패딩(same padding)
세임 패딩은 출력 크기와 입력 크기를 동일하게 유지한다는 특징이 있다.
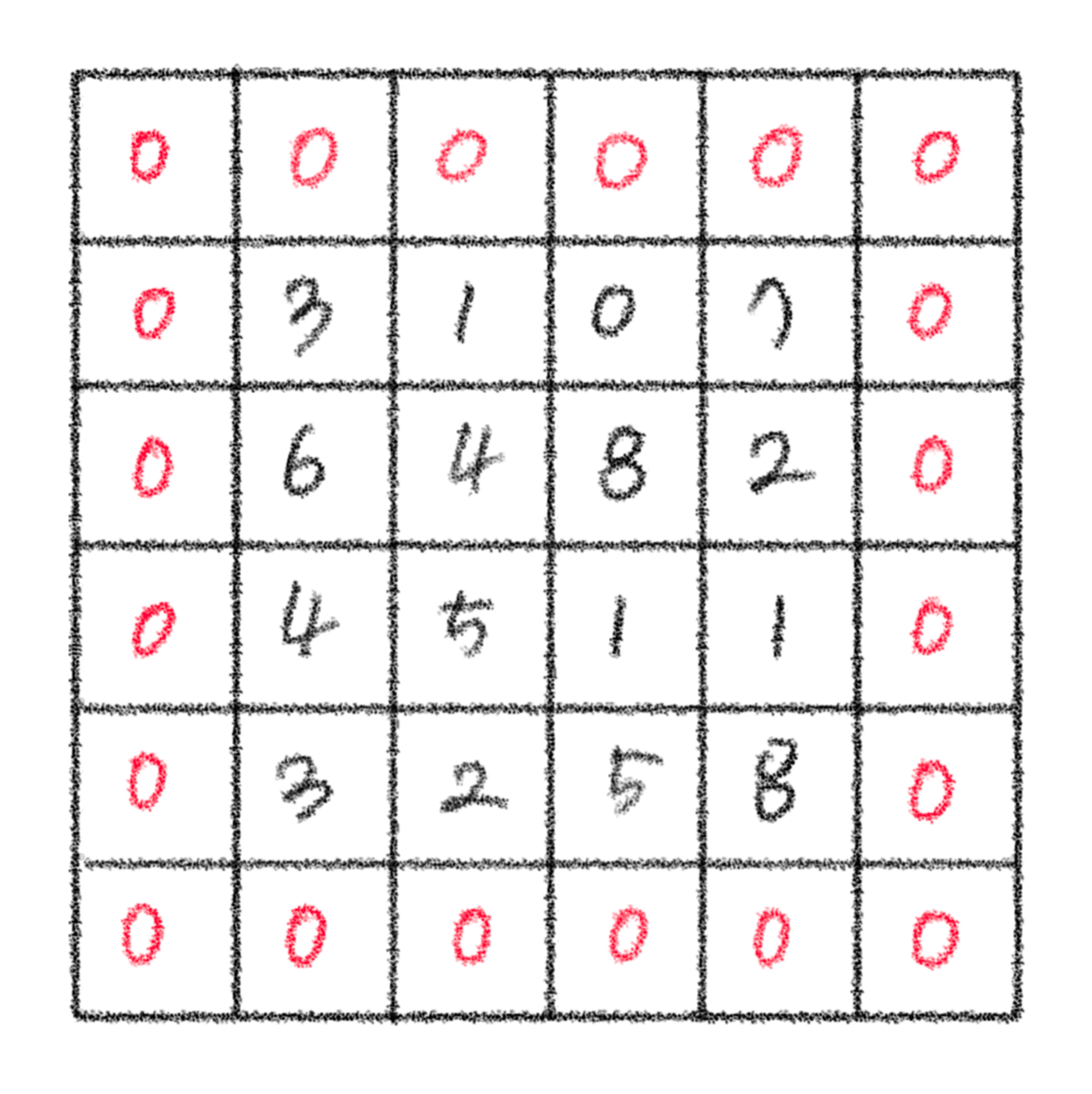
2) 스트라이드(Stride)
스트라이드란, 합성곱 연산(convolution)을 수행할 때 필터(커널)가 입력 데이터를 얼마나 뛰어넘을 지를 결정하는 매개 변수이다. 스트라이드 값은 필터가 한 번에 얼마나 이동할 지를 나타낸다.
큰 스트라이드를 사용하면 출력 크기가 감소하게 되므로, 연산량을 줄일 수 있다. 이는 특히 대규모 이미지나 복잡한 모델에서 중요하다.
작은 스트라이드를 사용하면 공간 차원이 더 많이 유지되며, 모델이 더 많은 공간적인 세부 정보를 학습할 수 있다. 이는 주로 이미지 분할(segmentation)과 같은 작업에서 중요하다.
스트라이드의 조절은 네트워크가 입력 데이터의 다양한 패턴에 민감하게 반응하도록 도와준다. 작은 스트라이드는 미세한 패턴을 잘 인식하게 하고, 큰 스트라이드는 전역적인 특징에 집중하게 한다.
3) 풀링(Pooling)
풀링은 2차원 데이터의 축 방향의 공간을 줄이는 연산이다. 풀링의 종류에는 최대 풀링(Max Pooling), 평균 풀링(Average Pooling) 등이 있다. 이미지 인식 분야에서는 주로 최대 풀링을 사용한다.
- 최대 풀링(Max Pooling)
최대 풀링이란, 대상 영역에서 최댓값을 취하는 연산을 말한다. 정해진 크기 안에서 가장 큰 값만 뽑아낸다는 것이다. 각 영역에서 최대값을 선택하여 특성 맵의 크기를 줄인다. 예를 들어, 2x2 최대 풀링은 각 2x2 영역에서 가장 큰 값을 선택하여 출력을 생성한다. 최대 풀링은 물체의 위치나 방향에 대한 변화에 상대적으로 불변하도록 도와준다.
- 평균 풀링(Average Pooling)
평균 풀링이란, 대상 영역의 평균을 계산한다. 정해진 크기 안의 값들의 평균을 뽑아낸다는 것이다. 각 영역의 평균값을 계산하여 특성 맵의 크기를 줄인다. 최대 풀링과는 달리 노이즈에 강건하게 동작할 수 있지만, 위치 정보를 보존하는 데는 제한이 있을 수 있다.
풀링을 사용하면 공간 차원을 줄여 계산 비용을 감소시키고, 특성을 강조하고 중요한 정보를 유지하면서 불필요한 세부 정보를 제거하여 과적합을 방지한다. 이를 통해 네트워크가 더욱 일반적인 특징을 학습하도록 돕는다.
풀링은 입력 데이터의 공간 차원(가로 및 세로 차원)을 감소시킴으로써 연산량을 줄이고 계산 비용을 낮춘다. 특히 이미지와 같은 대규모 데이터에서 이는 매우 중요하다. 감소된 공간 차원은 네트워크가 더 효과적으로 작동하게 하며, 계산 비용과 메모리 사용을 최적화한다.
