🖇 상관관계란 무엇인가?
🖇 다중공선성
🖇 상관관계 분석하기
고객 세그먼테이션을 위해 K-Means 클러스터링을 적용하기 전에, 데이터셋 내 특성(feature) 간의 상관관계 분석하는 것이 필요하다.
상관관계가 무엇을 의미하는지, 클러스터링에서 왜 중요한지를 알아보고 다중공선성 문제도 함께 생각해 보았다.
🖇 상관관계란 무엇인가?
상관관계(Correlation) 란 통계학에서 두 변수 간의 관계의 강도와 방향을 의미한다.
쉽게 말해, 한 변수가 변할 때 다른 변수가 어떻게 변하는지를 수치로 표현한 것이다.
상관계수는 일반적으로 -1에서 1 사이의 값을 가지며, 다음과 같이 해석할 수 있다.
| 상관계수 | 해석 |
|---|---|
| +1 | 완벽한 양의 상관관계 (함께 증가) |
| 0 | 상관관계 없음 |
| -1 | 완벽한 음의 상관관계 (한쪽 증가, 다른쪽 감소) |
예시를 통해 상관관계를 이해해 보자.
-
양의 상관관계: 광고비 ↑ → 판매량 ↑
-
음의 상관관계: 운동량 ↑ → 체중 ↓
-
상관관계 없음: 신발 사이즈와 성적
이때 상관관계는 인과관계를 의미하지 않는다.
한 변수의 변화가 다른 변수의 변화를 유발한다고 단정지을 수는 없다. 예를 들어, 아이스크림 판매량과 익사 사고 수는 모두 여름에 증가하지만 인과관계는 아니라는 것이다.
🖇 다중공선성
클러스터링 전에 왜 이러한 상관관계를 확인해야 할까? 에 답을 내기 위해서는 다중공선성(Multicollinearity)을 이해해야 한다.
다중공선성이란 두 개 이상의 독립 변수들 사이에 높은 상관관계가 존재하는 경우를 말한다.
이럴 경우, 클러스터링 과정에서 특정 변수들이 결과에 과도한 영향을 미칠 수 있다. 두 변수가 거의 동일한 정보를 담고 있으면 그 변수들은 클러스터링 과정에서 불필요하게 중복된 영향력을 가질 수 있게 된다.
클러스터링 알고리즘은 두 변수를 서로 다른 정보처럼 인식하지만, 실제로는 거의 같은 정보를 두 번 반영하게 되어 왜곡이 발생할 수 있는 것이다.
커머스 회사의 판매 데이터에 다음과 같은 변수가 있다고 가정해 보자.
광고비,마케팅비,판매량
보통 광고비와 마케팅비는 비슷한 방향으로 움직일 가능성이 높다. 이 둘이 높은 상관관계를 가지면, 모델은 둘 다 중요하다고 착각하고 클러스터 중심에 과도한 영향을 미칠 수 있다.
따라서 유사한 정보를 가진 변수들을 제거하거나, 차원 축소를 통해 중복 영향을 줄이는 것이 좋다.
🖇 상관관계 분석하기
그럼 상관 계수를 시각화하여 다중공선성 문제가 있는지 살펴보자.
- 상관계수 계산하기
import seaborn as sns
import numpy as np
# CustomerID는 제외(drop)하고 상관관계 행렬 계산(corr())
corr = user_data.drop(columns=['CustomerID']).corr()
- 상관계수 히트맵 시각화하기
# 행렬이 대각선을 기준으로 대칭이기 때문에 하단만 표시하기 위한 마스크 생성
# np.zeros_like(): 0으로 가득찬 array 생성, 크기는 corr와 동일
mask = np.zeros_like(corr)
# array의 대각선 영역과 그 윗 부분에 True가 들어가도록 설정
mask[np.triu_indices_from(mask, k=1)] = True
# 히트맵 그리기
plt.figure(figsize=(8, 6))
sns.heatmap(corr, mask=mask, cmap='Greys', annot=True, fmt='.2f')
plt.show()
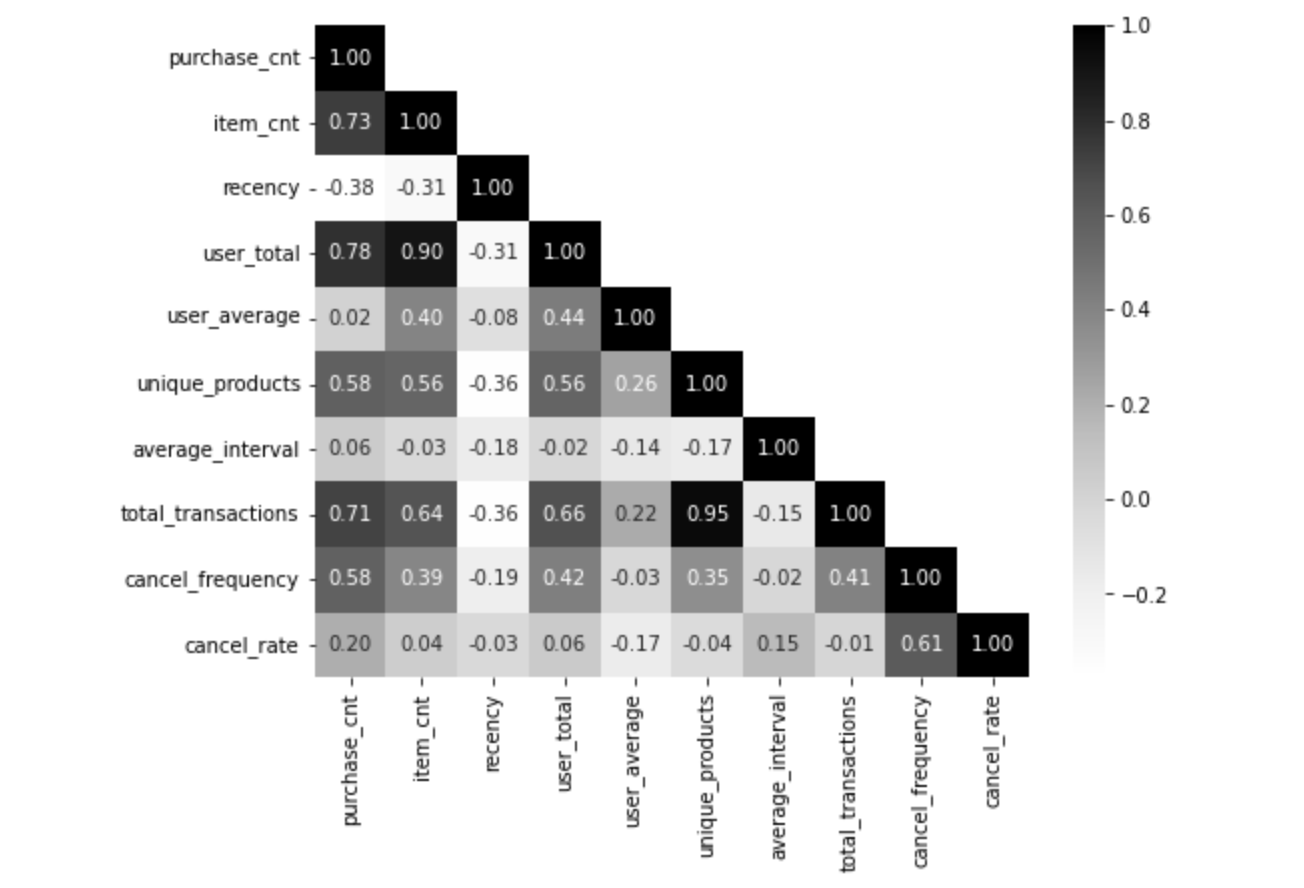 해석 Tip)
해석 Tip)
- 색이 진할수록 상관관계가 강함
- 대각선 근처에 진한 색이 많다면, 특정 변수들이 서로 높은 관련성을 가짐
💡 높은 상관관계를 가진 변수 쌍이 있다면 어떤 조치를 취할 수 있을까?
- 하나만 남기고 제거
- 두 변수를 조합해 새로운 변수 생성
- PCA 등 차원 축소 기법 적용
이후 해당 프로젝트에서 수행할 K-Means 클러스터링은 거리 기반 알고리즘이다.
서로 높은 상관관계를 가진 변수가 여러 개 있으면, 그 변수들이 거리 계산에 중복 반영되어 왜곡된 클러스터 중심이 생성될 수 있다.
따라서 지금처럼 상관관계를 먼저 확인하고, 필요하다면 차원을 축소해주는 것이 중요하다.
이어지는 글에서는 Feature Scaling을 통해,
주성분 분석(PCA)로 다중공선성 문제를 해결하고 K-Means를 적용할 준비를 마무리할 예정이다.
[해당 컨텐츠는 아이펠 캠퍼스 LMS에서 학습한 내용을 재해석한 것으로 무단 복제 및 사용을 금지합니다.]
