
1. AutoEncoder
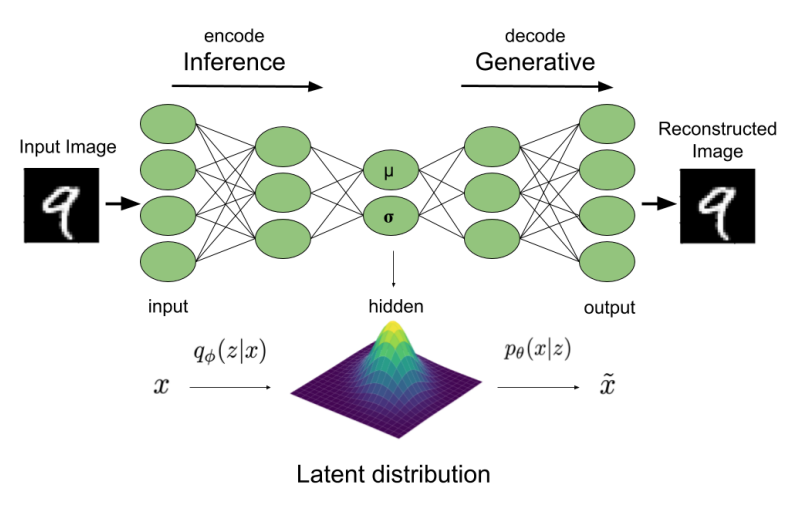
출처: https://wikidocs.net/229887
비지도학습의 오토인코더라는 것이 있다.
오토인코더의 구조는 이와 같다.
CNN, encoder를 이용하여 입력 데이터를 받아서 더 작은 차원으로 압축한다.
이는 차원축소같이 생각하면 된다.
그렇게 압축된 잠재 공간(latent space)를 만들어낸다.
그리고 이 인코더에서 만들어진 압축된 표현을 다시 decoder를 이용하여 복원하는 것이다.
그렇다면 숫자 MNIST를 복원하는 실습을 진행한다.
1.1. 데이터 전처리
(X_train, _), (X_test, _)=keras.datasets.mnist.load_data() # y는 필요없다. 예측을 하는게 아니니까 가져오지 않는다.(_)
X_train=X_train.reshape(-1, 28, 28, 1)/255.0 # 정규화
X_test=X_test.reshape(-1, 28, 28, 1)/255.0
X_train.shape, X_test.shape((60000, 28, 28, 1), (10000, 28, 28, 1))원래는 28x28일때 이미지를 계속 줄여가면서 특성맵을 뽑아냈고 그걸 계산해서 0,1,2,... 로 구분했다면,
이번에는 28x28이라면 그대로 가져가서 그대로 복원해야하는 것이다.
따라서 conv 층에서 신경써야한다.
1.2. ⭐ 모델 구성
인코딩과 디코딩 부분에 헷갈리는 부분이 있어서 주석으로 달아놨다.
헷갈릴 수 있으니 참고해서 진행하기!
autoencoder=keras.Sequential()
# Encoding
autoencoder.add(keras.layers.Input(shape=(28,28,1)))
# 3x3 커널 16개 사용해서 이미지에 합성곱 수행
# 입력 이미지에 3x3 크기로 슬라이딩하며 특징 추출
# 입력 28 28 1 -> 출력 28 28 16 (padding='same') -> 출력 채널 수 = 16개의 특성맵 생성
autoencoder.add(keras.layers.Conv2D(16, kernel_size=3, padding='same', activation='relu')) # 28 28 16
autoencoder.add(keras.layers.MaxPooling2D(pool_size=2, padding='same')) # 14 14 16
autoencoder.add(keras.layers.Conv2D(8, kernel_size=3, padding='same', activation='relu')) # 14 14 8
autoencoder.add(keras.layers.MaxPooling2D(pool_size=2, padding='same')) # 7 7 8
# 공간 크기(가로, 세로)를 절반으로 줄이기 위해 strides=2 사용
# MaxPooling은 가장 큰 값을 뽑아내는데, 그렇게 큰 값만 뽑아내면 이미지 손실이 있을 수 있음
# 그래서 그 대신에 이미지를 복원하거나 생성할때는 MaxPooling보다는 손실이 덜하게 strides=2로 둬서 가는 경우가 많음
# 입력 7 7 8 -> strides=2 -> 출력 4 4 8 (소숫점은 반올림)
autoencoder.add(keras.layers.Conv2D(8, kernel_size=3, strides=2, padding='same', activation='relu')) # 4 4 8
# --------------------------------------------
# Decoding
autoencoder.add(keras.layers.Conv2D(8, kernel_size=3, padding='same', activation='relu')) # 4 4 8
autoencoder.add(keras.layers.UpSampling2D()) # 2배로 확대 -> 8 8 8
autoencoder.add(keras.layers.Conv2D(8, kernel_size=3, padding='same', activation='relu')) # 8 8 8
autoencoder.add(keras.layers.UpSampling2D()) # 2배로 확대 -> 16 16 8
# kernel_size=3 + same padding X(padding='valid'(default))
# CNN에서 Conv가 한 번 수행된 후 출력 크기가 어떻게 계산되는지를 나타내는 공식
# 출력 크기 = ((입력 크기 - 커널 크기 + 2P(2*패딩)) / 스트라이드) + 1
# 출력 크기 = (16 - 3 + (2*0(valid)) / 1 + 1
# 출력 크기 = (16 - 3 + 0) / 1 + 1
# 출력 크기 = 13 / 1 + 1
# 출력 크기 = 14
autoencoder.add(keras.layers.Conv2D(16, kernel_size=3, activation='relu')) # 14 14 16
autoencoder.add(keras.layers.UpSampling2D()) # 2배로 확대 -> 28 28 16
autoencoder.add(keras.layers.Conv2D(1, kernel_size=3, padding='same', activation='sigmoid')) # 28 28 1
autoencoder.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ conv2d (Conv2D) │ (None, 28, 28, 16) │ 160 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 14, 14, 16) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_1 (Conv2D) │ (None, 14, 14, 8) │ 1,160 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 7, 7, 8) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_2 (Conv2D) │ (None, 4, 4, 8) │ 584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_3 (Conv2D) │ (None, 4, 4, 8) │ 584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ up_sampling2d (UpSampling2D) │ (None, 8, 8, 8) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_4 (Conv2D) │ (None, 8, 8, 8) │ 584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ up_sampling2d_1 (UpSampling2D) │ (None, 16, 16, 8) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_5 (Conv2D) │ (None, 14, 14, 16) │ 1,168 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ up_sampling2d_2 (UpSampling2D) │ (None, 28, 28, 16) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_6 (Conv2D) │ (None, 28, 28, 1) │ 145 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 4,385 (17.13 KB)
Trainable params: 4,385 (17.13 KB)
Non-trainable params: 0 (0.00 B)1.3. 모델 학습
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, LambdaCallback
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 원래는 X, Y로 가야하는데, 자기복원이니까 X, X로
autoencoder.fit(X_train, X_train, epochs=30, batch_size=128, validation_data=(X_test, X_test), callbacks=[early_stopping_callback])Epoch 1/30
469/469 ━━━━━━━━━━━━━━━━━━━━ 13s 22ms/step - loss: 0.1009 - val_loss: 0.0957
Epoch 2/30
469/469 ━━━━━━━━━━━━━━━━━━━━ 10s 21ms/step - loss: 0.0967 - val_loss: 0.0941
Epoch 3/30
469/469 ━━━━━━━━━━━━━━━━━━━━ 10s 21ms/step - loss: 0.0951 - val_loss: 0.0926
...
...
Epoch 29/30
469/469 ━━━━━━━━━━━━━━━━━━━━ 10s 22ms/step - loss: 0.0839 - val_loss: 0.0827
Epoch 30/30
469/469 ━━━━━━━━━━━━━━━━━━━━ 10s 22ms/step - loss: 0.0838 - val_loss: 0.08261.4. 예측
pred_imgs=autoencoder.predict(X_test)
X_test.shape[0]이 10000개 중에서 5개를 랜덤하게 5개를 뽑아서 보자.
⭐ 이때 이는 인덱스 5개를 뽑는거다!
random_test=np.random.randint(X_test.shape[0], size=5)
print(random_test)
print(random_test[0])[7270 860 5390 5191 5734]
7270plt.figure(figsize=(5,2))
# random_test: [7270, 860, 5390, 5191, 5734]
# enumerate(random_test): 순회하면서 (i, image_idx) 튜플 하나씩 줌
# i: 루프 인덱스 (0~4) / image_idx: 실제로 뽑힌 X_test의 인덱스
for i, image_idx in enumerate(random_test):
# 실제
ax=plt.subplot(2,5,i+1)
plt.imshow(X_test[image_idx].reshape(28,28), cmap='gray')
ax.axis('off')
# 복원
ax=plt.subplot(2,5,5+i+1)
plt.imshow(pred_imgs[image_idx].reshape(28,28), cmap='gray')
ax.axis('off')
plt.show()

AI Model Developer