
단층과 다층 퍼셉트론을 ANN이라고 하며 이 다음에 배우는 내용이 CNN이다.
그 다음에 진행하는 내용이 RNN이다.
그런데 프로젝트를 진행하기 위해 RNN으로 잠시 넘어가 LSTM에 대해 배웠던 것이다.
이제 CNN쪽으로 다시 방향을 틀어보자.
1. CNN(Convolutional Layer)
딥러닝의 구조는 그대로 가며,
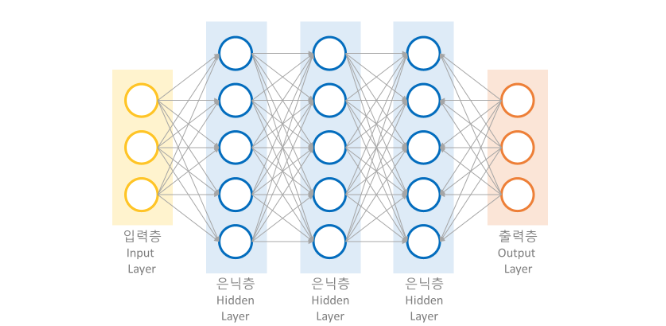
출처: https://velog.io/@posisugar31/딥.한.끝-3.-딥러닝-구조와-모델
출력층이 결국에는 이미지 분류이므로 0인지, 1, 2인지 등으로 출력이 되는 것이다.
LSTM도 이 구조를 그대로 가져가다가 gate들이 들어가는데,
그와 똑같이 CNN도 무언가가 들어간다.
먼저 완전 연결 계층(Affine 계층)이라는 개념에 대해 알아야하는데,
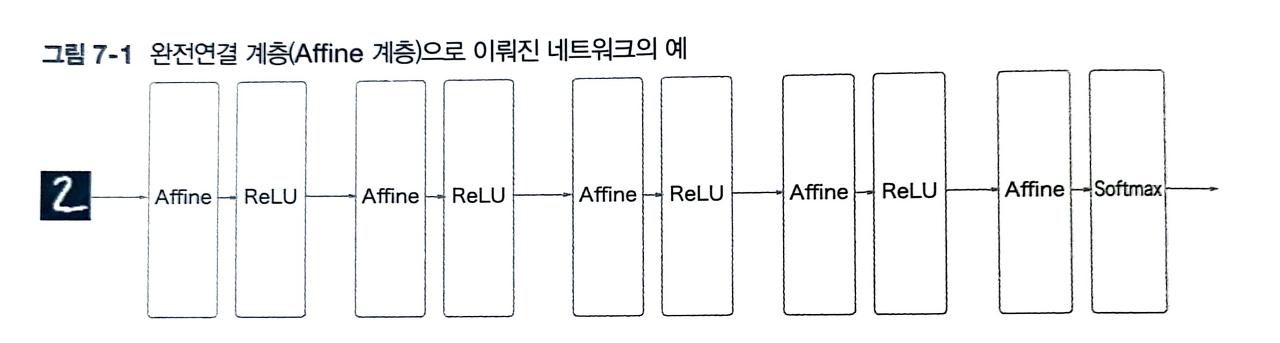
출처: https://portrait-of-youngblood.tistory.com/80
이와 같이 하나의 은닉층에 Affine과 ReLU가 활성화 함수로 들어간다.
그리고 이들 앞에 합성곱(Conv) 계층과 풀링(Pooling) 계층이 추가되는 것이 합성곱 신경망인 CNN의 구조이다.
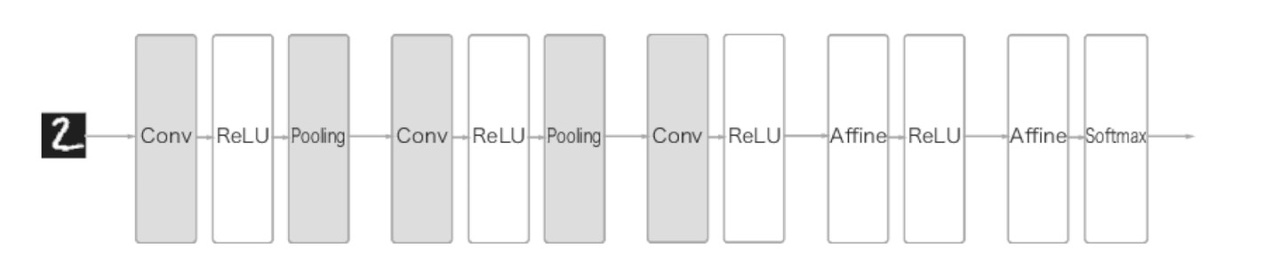
출처: https://portrait-of-youngblood.tistory.com/80
1.1. 필터(커널)
이 Conv 계층의 연산은 다음과 같다.
입력 데이터가 5x5일때, 커널이라는 행렬과의 연산을 수행하는데,
커널의 행렬이 3x3이라고 하면 다음과 같다.
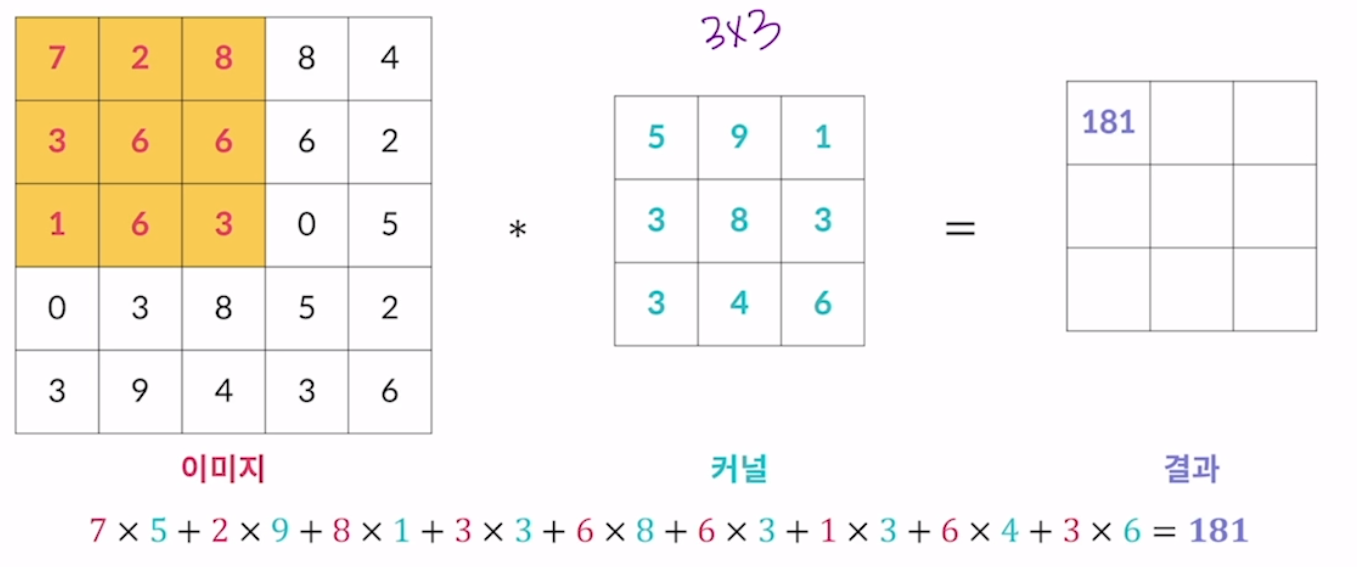
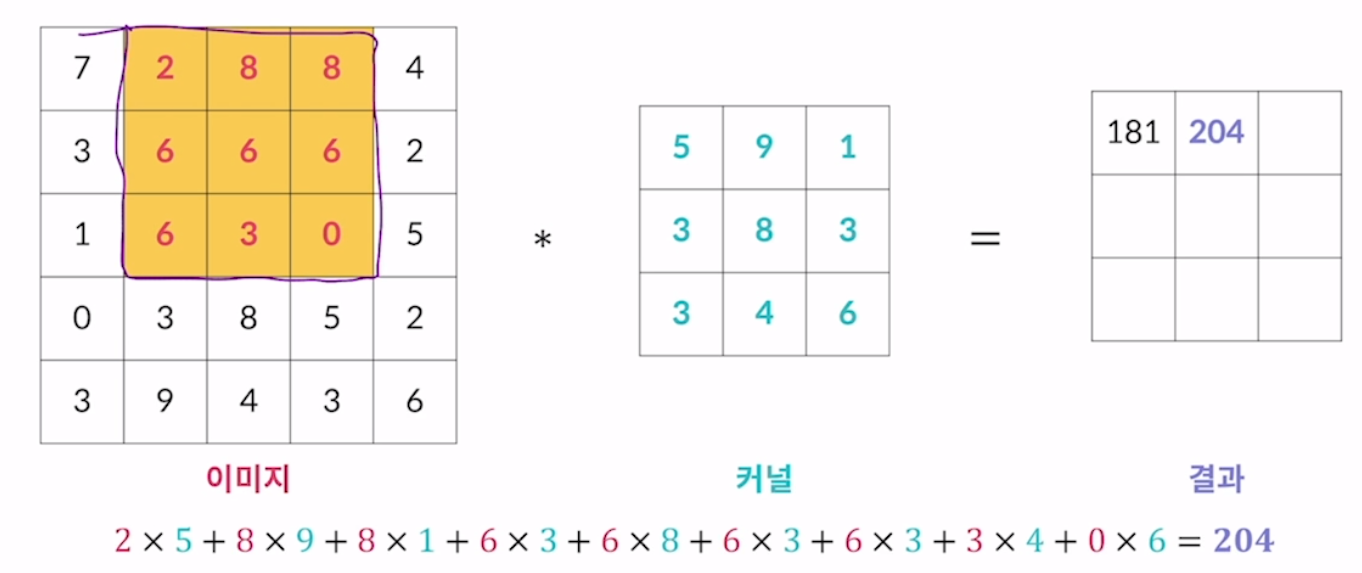
출처: https://velog.io/@7ryean/CNN-Convolution-%EC%97%B0%EC%82%B0
이렇게 이동하며 결과 행렬을 채워가는데, 이를 특성 맵이라고 한다.
결국에는 곱해지면서 줄어들 수 밖에 없고, 줄어들면서 특징을 뽑아내는 것이다.
코드로 보면 굉장히 간단하다.
keras.layers.Conv2D(10, kerner_size=(3,3), activation="relu")
3x3의 커널을 10개 만드는 것이다.
1.2. 패딩(Padding)과 스트라이드(Strides)
그런데 이렇게 커널을 곱해줘서 특성 맵을 뽑으면 크기가 조정이되는데, 만약 입력 맵과 출력 맵의 크기를 동일하게 해주려면 패딩(Padding)이라는 것을 이용한다.
패딩의 여러 종류 중 Same Padding의 경우는,
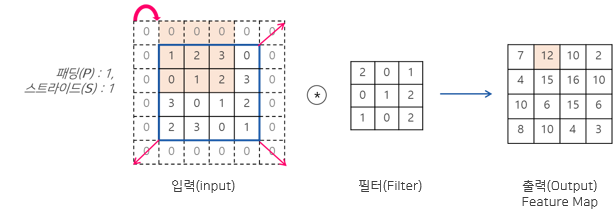
출처: https://jackarp.github.io/nlp/CNN/
이와 같이 0으로 채워서 기존의 4x4를 유지시킬 수 있다.
이때는 앞선 코드에서 padding 부분만 더해주면 된다.
또, 그림을 보면 스트라이드(S): 1 라는 부분을 볼 수 있는데,
이는 얼마만큼 이동할지를 나타내는 것으로 default는 1이다.
따라서 만약 2일 경우는 두칸씩 움직인다고 보면 된다.
keras.layers.Conv2D(10, kerner_size=(3,3), padding="same", strides=1, activation="relu")
1.3. 풀링(Pooling)
입력 데이터가 Conv 연산으로 줄어들었고, 나온 특성 맵을 더 줄여주는 풀링(Pooling)이라는 것이있다.
이 풀링에는 크게 최대 풀링(Max Pooling), 평균 풀링(Average Pooling), 그리고 글로벌 평균 풀링(Global Average Pooling)이있다.
그 중 2x2 최대 풀링(Max Pooling)의 경우는 다음과 같다.
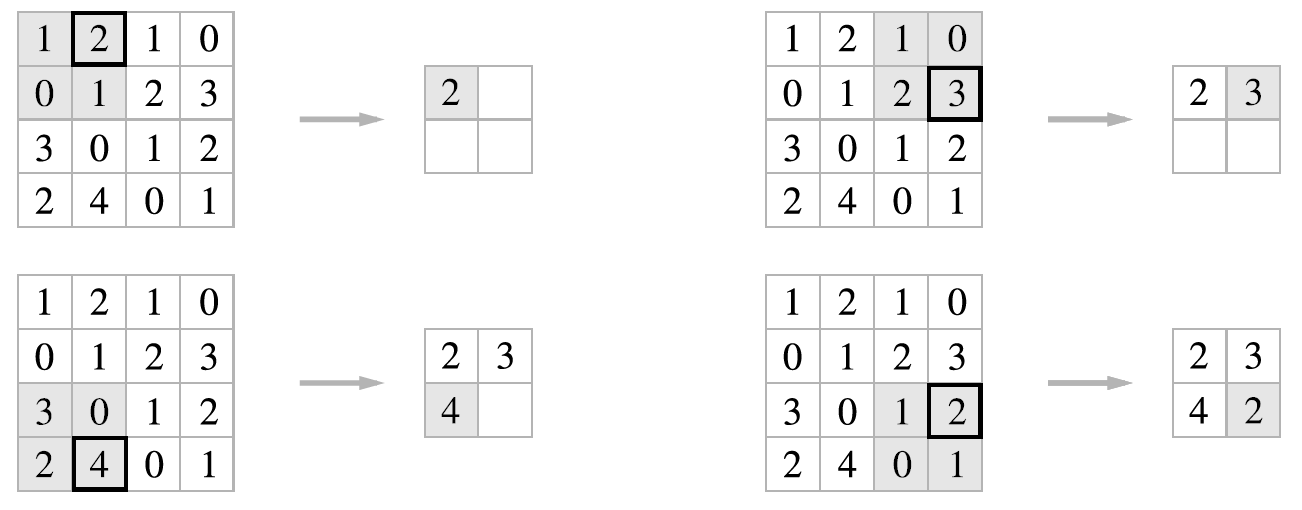
출처: https://jackarp.github.io/nlp/CNN/
keras.layers.MaxPooling2D(2, strides=2, padding='valid')
참고로 여기서 valid padding이란 패딩 없이 그대로 사용하는 것을 말하여 지금까지 해왔던 것과 동일하다.
same padding처럼 입출력을 같이 유지하지 않고, 위 1.2. 패딩의 그림에서 가장자리(0)은 계산에서 제외하는 것이다.
1.4. 정리
출처: https://portrait-of-youngblood.tistory.com/80
이렇게하여 Conv 계층에서 필터(커널) -> 패딩과 스트라이드 -> 풀링 -> ...(반복)... 이후 앞서 설명한 완전 연결층(Fully Connected Layer or Affine 계층)이 이어지는 것이다.
즉 전체 CNN의 흐름은 다음과 같다.
입력 이미지 (3차원: Height x Width x Color)
↓
[합성곱 계층] Convolution Layer
↓
[활성화 함수] ReLU 등
↓
[풀링 계층] MaxPooling Layer
↓ (이 과정을 여러 번 반복 가능)
↓
[평탄화] Flatten Layer → 3D → 1D 벡터
↓
[완전 연결 계층] Dense Layer
↓
[출력] (Softmax 등)
특징 추출(합성곱/풀링) -> 분류(완전연결층)으로 나뉜다.
Dense층으로 가기 전에 반드시 1차원 으로 펴줘야 한다.
마지막에는 0이 0.7, 1이 0.3이 나온다면 오차를 줄이기 위해서 역전파로 진행 후 다시 진행하는 똑같은 흐름이다.
역전파 과정을 설명하자면,
1. 출력층에서 오차를 계산하고
예측값 vs 실제값 -> loss 계산 (e.g., CrossEntropy)
-
Dense Layer (완전연결층)에서
오차를 기준으로 가중치와 bias에 대한 기울기(gradient) 계산
이후 오차를 다음 계층으로 전파 -
Flatten 계층
shape만 변환하고 기울기 그대로 전달
⭐ Conv 계층과 Pooling 계층을 모두 거친 뒤, Dense에 연결하기 전 딱 한 번 사용한다. -
Pooling 계층
보통 MaxPooling은 그 위치에서만 기울기 전달
e.g., Max 값 위치에만 오차 전달, 나머지는 0 -
Conv 계층
필터 가중치에 대한 기울기 계산
입력 이미지에 대한 기울기도 계산해서 더 전파
이렇게 결국 CNN도 역전파 구조는 ANN과 같은 원리지만, 구조적 차이(필터, 패딩, 스트라이드 등)로 계산 방식이 달라진다.
즉 전체를 다시 정리하면 다음과 같다.
⭐ CNN 내부 연산 흐름
입력 이미지 (예: 28x28x1)
└─> 픽셀값 정규화 (보통 0~1)[Conv Layer: 합성곱 계층]
└─> 여러 개의 필터가 이미지 위를 슬라이딩하면서,
└─> 특징(feature)을 추출 (예: 엣지, 질감 등)
└─> 결과: feature map (예: 26x26x32)[ReLU 활성화 함수]
└─> 음수를 0으로 바꾸고 비선형성 부여[Pooling Layer: 풀링 계층]
└─> 공간 정보를 줄임 (예: MaxPooling)
└─> 예: 26x26x32 → 13x13x32(필요하면 Conv → ReLU → Pooling 반복)
[Flatten]
└─> 3D 데이터를 1D 벡터로 펼침
└─> 예: 13x13x32 → 5408[Dense Layer: 완전 연결층]
└─> 전체 뉴런 연결해서 classification 수행[Output Layer: Softmax]
└─> 클래스별 확률 출력 (예: [0.1, 0.2, 0.7])학습과정
- 위 흐름에 따라 순전파(forwoard propagation)을 하고
- 예측 결과와 실제 정답을 비교해서 Loss를 계산하고,
- Loss를 기준으로 역전파(backpropagation)를 진행하고,
- 각 계층의 기울기를 계산하여 -> 가중치 업데이트
2. 패션 MNIST
앞서 해봤던 패션 MNIST 데이터셋을 이용하여 실습해보자.
2.1. 데이터 분할 및 전처리
(X_train, Y_train), (X_test, Y_test)=keras.datasets.fashion_mnist.load_data()
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))흑백 이미지(28x28)가 60000개와 10000개로 각각 train, test로 나뉘어졌다.
# 10개의 레이블값
for i in range(10):
print(Y_train[i], end=' ')
fig, ax=plt.subplots(1, 10, figsize=(10,10))
# 10개만 뽑아보면
for i in range(10):
ax[i].imshow(X_train[i], cmap='gray_r')
ax[i].axis('off')
plt.show()9 0 0 3 0 2 7 2 5 5 
np.unique(Y_train, return_counts=True)(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
ANN에서는 1차원으로 펴주는데, CNN은 먼저 3차원을 4차원으로 바꿔주며 정규화 해줘야한다.
원래 Fashion MNIST의 이미지는 2차원 형태인 (28, 28)이지만, CNN에서는 채널 축까지 필요하므로 (28, 28, 1)로 변환한다.
이후 CNN 학습을 위해 배치 처리를 해야 하므로 N x 28 x 28 x 1 의 4차원으로 변환해야한다.
즉 X_train.shape = (60000, 28, 28) 의 원본이 CNN 입력용으로는
X_train = X_train.reshape(-1, 28, 28, 1) 이와 같이 변환된다.
(여기서 -1은 자동으로 맞춰주는 것으로 X_train이 (60000, 28, 28)이면
-1 자리에 60000이 들어가서 (60000, 28, 28, 1)이 된다.
그래서 reshape할 때 -1은 전체 샘플 수가 무엇이든 자동으로 맞춰준다.)
# (샘플수, 높이, 너비, 채널수 (흑백 1, 컬러 3)) / 255.0 (for 0~1 사이값)
X_train_scaled=X_train.reshape(-1, 28, 28, 1) / 255.0
X_test_scaled=X_test.reshape(-1, 28, 28, 1) / 255.0
# 크기와 정규화가 잘 되었는지 확인
print(X_train_scaled.shape, np.max(X_train_scaled), np.min(X_train_scaled))
print(X_test_scaled.shape, np.max(X_test_scaled), np.min(X_test_scaled))(60000, 28, 28, 1) 1.0 0.0
(10000, 28, 28, 1) 1.0 0.02.2. 모델 구성 및 학습
- Conv1D (1차원 합성곱): 시계열 데이터, 자연어 처리 -> (시퀀스 길이, 특성 수) -> (100, 1)
- Conv2D (2차원 합성곱): 이미지 처리 -> (높이, 너비, 채널) -> (28, 28, 1)
- Conv3D (3차원 합성곱): 비디오 -> (깊이, 높이, 너비, 채널) -> (10, 64, 64, 1)
MaxPolling의 경우도 1, 2, 3에 맞춰야함
model=keras.Sequential()
# 입력층
model.add(keras.layers.Input(shape=(28, 28, 1)))
# 은닉층
# layer 1
model.add(keras.layers.Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu')) # 28, 28, 32, 이때 32는 커널 개수 = 출력 채널 수
model.add(keras.layers.MaxPooling2D(pool_size=(2, 2))) # 14, 14, 32
# layer 2
model.add(keras.layers.Conv2D(64, kernel_size=3, padding='same', activation='relu')) # 14, 14, 64
model.add(keras.layers.MaxPooling2D(pool_size=2)) # 7, 7, 64
# 1차원으로
model.add(keras.layers.Flatten()) # 7 * 7 * 64 = 3136
# 출력층
model.add(keras.layers.Dense(100, activation='relu')) # 파라미터: 3136 * 100 * 100(절편) = 313700 / 출력: 100
model.add(keras.layers.Dropout(0.4)) # 40% 뉴런을 랜덤으로 잠시 꺼서 과적합을 방지하고, 일반화 성능을 향상시키는 정규화
model.add(keras.layers.Dense(10, activation='softmax')) # 파라미터: 100 * 10 + 10 = 1010 / 출력: 10
model.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ conv2d (Conv2D) │ (None, 28, 28, 32) │ 320 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 14, 14, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_1 (Conv2D) │ (None, 14, 14, 64) │ 18,496 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 7, 7, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten (Flatten) │ (None, 3136) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 100) │ 313,700 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 100) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 10) │ 1,010 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 333,526 (1.27 MB)
Trainable params: 333,526 (1.27 MB)
Non-trainable params: 0 (0.00 B)# 출력
def on_epoch_end_function(epoch, logs):
if(epoch + 1) % 3 == 0: # 3번에 1번씩 진행 상황 출력
print(f"Epoch {epoch + 1}: loss={logs['loss']:.4f}, accuracy={logs['accuracy']:.4f}",
f"val_loss={logs['val_loss']:.4f}, val_accuracy={logs['val_accuracy']:.4f}")
print_callback = LambdaCallback(on_epoch_end=on_epoch_end_function)
# 학습 중단
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=2, verbose=1, restore_best_weights=True)
# 모델의 성능이 향상될 때만 저장
check_pointer=keras.callbacks.ModelCheckpoint(filepath='deep_result/cnn.keras', monitor='val_loss', save_best_only=True)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])2.3. 학습 및 평가
history=model.fit(X_train_scaled, Y_train, epochs=5, batch_size=32, validation_split=0.2, verbose=0,
callbacks=[print_callback, early_stopping_callback, check_pointer])Epoch 3: loss=0.2938, accuracy=0.8950 val_loss=0.2784, val_accuracy=0.8941
Restoring model weights from the end of the best epoch: 5.model.evaluate(X_test_scaled, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 6ms/step - accuracy: 0.9085 - loss: 0.2638
[0.25770804286003113, 0.9075000286102295]⭐ 참고로 evaluate의 결과를 보면, loss값과 accuracy가 나왔는데,
evaluate는 기본적으로 [loss, metric1, metric2, ...]형식의 리스트를 반환한다. 그런데 compile에서 metrics를 accuracy로 줬기 때문에 loss값과 accuracy가 반환된 모습이다.
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='validation loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()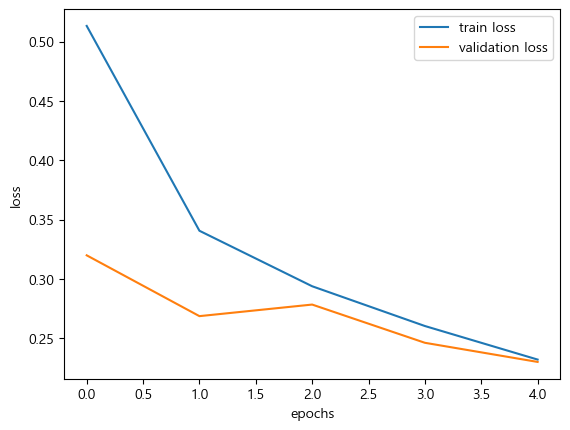
pred_prob=model.predict(X_test_scaled)
pred=np.argmax(pred_prob, axis=1)
pred[0][1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 5ms/step
np.int64(9)print(metrics.classification_report(Y_test, pred))precision recall f1-score support
0 0.88 0.84 0.86 1000
1 0.99 0.98 0.99 1000
2 0.83 0.88 0.85 1000
3 0.92 0.90 0.91 1000
4 0.86 0.84 0.85 1000
5 0.98 0.98 0.98 1000
6 0.72 0.75 0.73 1000
7 0.94 0.98 0.96 1000
8 0.98 0.98 0.98 1000
9 0.99 0.94 0.96 1000
accuracy 0.91 10000
macro avg 0.91 0.91 0.91 10000
weighted avg 0.91 0.91 0.91 100006번을 잘 분류하지 못했는데 전반적으로는 잘 예측했다.
이미지를 찍어보면 다음과 같다.
plt.figure(figsize=(2,2))
plt.imshow(X_test_scaled[0].reshape(28, 28), cmap='gray_r') # 원상태로 reshape
plt.title(f"Pred:{pred[0]}, Real:{Y_test[0]}")
plt.show()
그리고 이미지의 경우는 상당히 오래걸리기 때문에 앞으로는 모델 저장을 자주 해놓는게 좋다.
# 가중치 저장
model.save_weights('deep_result/cnn.weights.h5')
# 불러오기
model_fmnist_load=load_model('deep_result/cnn.keras')
#model_fmnist_load.summary()
model_fmnist_load.load_weights('deep_result/cnn.weights.h5')
model_fmnist_load.evaluate(X_test_scaled, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 6ms/step - accuracy: 0.9085 - loss: 0.2638
[0.25770804286003113, 0.9075000286102295]3. CIFAR-10
이번에는 컬러 이미지의 경우를 진행해보자.
총 60,000장의 컬러 이미지 중 훈련이 5만, 테스트가 1만이며, 정답 클래스는 10개다.
3.1. 모델 분할 및 전처리
(X_train, Y_train), (X_test, Y_test) = keras.datasets.cifar10.load_data()
X_train.shape, Y_train.shape, X_test.shape, Y_test.shapeDownloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
[1m170498071/170498071[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m530s[0m 3us/step
((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))원본 데이터 구조가 Fashion MNIST와 다르게 이미 4차원으로 준비되어 있다.
이번에는 컬러이기 때문에 이미지에 손상이 가해지면 안되기에 이전 패션 MNIST에서 진행했던
# (샘플수, 높이, 너비, 채널수 (흑백 1, 컬러 3)) / 255.0 (for 0~1 사이값)
X_train_scaled=X_train.reshape(-1, 28, 28, 1) / 255.0
X_test_scaled=X_test.reshape(-1, 28, 28, 1) / 255.0
# 크기와 정규화가 잘 되었는지 확인
print(X_train_scaled.shape, np.max(X_train_scaled), np.min(X_train_scaled))
print(X_test_scaled.shape, np.max(X_test_scaled), np.min(X_test_scaled))이 reshape를 진행하지 않고, 정규화만 진행한다.
이미지의 픽셀값이 0~255 범위기 때문에, 0~1 번위로 정규화하여 학습을 안정화시키기위해 입력 데이터가 어떤 구조든 항상 필요한 전처리인 / 255.0을 진행해준다.
np.unique(Y_train, return_counts=True)(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000, 5000]))
for i in range(10):
print(Y_train[i], end=' ')
fig, ax=plt.subplots(1, 10, figsize=(10, 10))
for i in range(10):
ax[i].imshow(X_train[i])
ax[i].axis('off')
plt.show()[6] [9] [9] [4] [1] [1] [2] [7] [8] [3] 
X_train=X_train/255.0
X_test=X_test/255.0
X_train.shape, X_test.shape((50000, 32, 32, 3), (10000, 32, 32, 3))3.2. 모델 구성 및 학습
model=keras.Sequential()
model.add(keras.layers.Input(shape=(32,32,3))) # 가로, 세로, 컬러
model.add(keras.layers.Conv2D(32, kernel_size=3, padding='same', activation='relu')) # 32 32 32
model.add(keras.layers.MaxPooling2D(pool_size=2)) # 16 16 32
model.add(keras.layers.Conv2D(64, kernel_size=3, padding='same', activation='relu')) # 16 16 64
model.add(keras.layers.MaxPooling2D(pool_size=2)) # 8 8 64
model.add(keras.layers.Conv2D(64, kernel_size=3, padding='valid', activation='relu')) # 6 6 64 / padding default: valid
model.add(keras.layers.Flatten()) # 36,928
model.add(keras.layers.Dense(64, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()Model: "sequential"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ conv2d (Conv2D) │ (None, 32, 32, 32) │ 896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d (MaxPooling2D) │ (None, 16, 16, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_1 (Conv2D) │ (None, 16, 16, 64) │ 18,496 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_1 (MaxPooling2D) │ (None, 8, 8, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_2 (Conv2D) │ (None, 6, 6, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten (Flatten) │ (None, 2304) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 64) │ 147,520 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 10) │ 650 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 204,490 (798.79 KB)
Trainable params: 204,490 (798.79 KB)
Non-trainable params: 0 (0.00 B)
여기서 마지막 Conv 뒤에 Pooling을 안하는 이유는 이미 충분히 줄어들었기 때문이다.
이전 두 번의 MaxPooling으로 공간 크기가 이미 많이 줄어들었는데, 여기서 한 번 더 풀링하면 3x3이나 2x2가 되어 너무 작아져서 정보 손실이 생길 수 있다.
또, Flatten으로 펼치기 전에 특징 정보를 최대한 유지하려는 목적도 존재한다. 풀링은 정보를 요약하긴 하지만 동시에 버리기도 많이해서, 마지막 합성곱은 pool 없이 그대로 flatten으로 연결해서 더 많은 특징을 고해상 벡터로 전달하게 된다.
따라서 너무 많은 풀링은 성능을 저하시키고, 너무 적은 풀링은 연산량이 증가하여 학습이 어려워진다.
그래서 중간중간만 Pooling을 넣고, 마지막 Conv는 정보 손실 없이 그대로 넘긴 것이다.
참고로 후에 배우게 될 다른 구조인 VGG, RestNet 등에서는
Conv 여러 개 -> Pooling의 패턴을 사용한다.
반드시 Conv -> Pooling -> Conv -> Pooling만 고정된 것은 아니다.
3.3. 학습 및 평가
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 출력
def on_epoch_end_function(epoch, logs):
if(epoch + 1) % 5 == 0: # 5번에 1번씩 진행 상황 출력
print(f"Epoch {epoch + 1}: loss={logs['loss']:.4f}, accuracy={logs['accuracy']:.4f}",
f"val_loss={logs['val_loss']:.4f}, val_accuracy={logs['val_accuracy']:.4f}")
print_callback = LambdaCallback(on_epoch_end=on_epoch_end_function)
# 학습 중단
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=2, verbose=1, restore_best_weights=True)
# 모델의 성능이 향상될 때만 저장
check_pointer=keras.callbacks.ModelCheckpoint(filepath='deep_result/cnn_color.keras', monitor='val_loss', save_best_only=True)
history = model.fit(X_train, Y_train, epochs=5, batch_size=32, verbose=0, validation_split=0.2,
callbacks=[print_callback, early_stopping_callback, check_pointer])Epoch 5: loss=0.7521, accuracy=0.7372 val_loss=0.8752, val_accuracy=0.7024
Restoring model weights from the end of the best epoch: 5.model.evaluate(X_test, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 6ms/step - accuracy: 0.6940 - loss: 0.9030
[0.9001834988594055, 0.6969000101089478]fig, ax=plt.subplots(1,2,figsize=(10,4))
ax[0].plot(history.history['loss'], label='train loss')
ax[0].plot(history.history['val_loss'], label='validation loss')
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[0].legend()
ax[0].set_title('loss over epochs')
ax[1].plot(history.history['accuracy'], label='train accuracy')
ax[1].plot(history.history['val_accuracy'], label='validation accuracy')
ax[1].set_xlabel('epoch')
ax[1].set_ylabel('accuracy')
ax[1].legend()
ax[1].set_title('accuracy over epochs')
plt.show()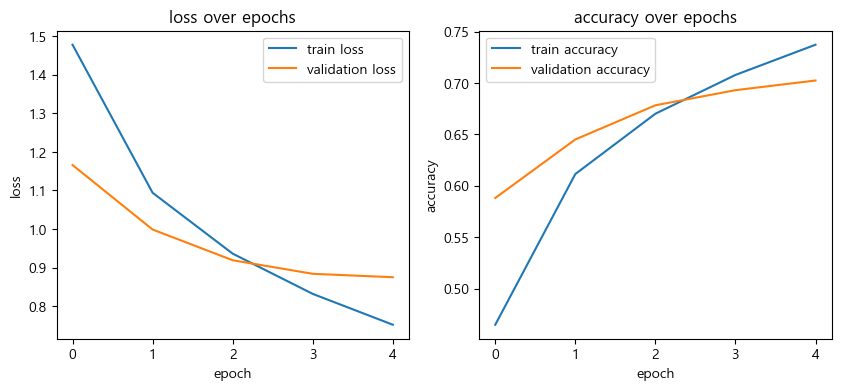
pred_prob=model.predict(X_test)
pred=np.argmax(pred_prob, axis=1)
pred[2][1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 5ms/step
np.int64(8)print(metrics.classification_report(Y_test, pred))precision recall f1-score support
0 0.77 0.70 0.73 1000
1 0.82 0.83 0.83 1000
2 0.59 0.56 0.57 1000
3 0.52 0.53 0.53 1000
4 0.66 0.62 0.64 1000
5 0.66 0.49 0.56 1000
6 0.64 0.86 0.73 1000
7 0.71 0.79 0.75 1000
8 0.77 0.84 0.81 1000
9 0.81 0.75 0.78 1000
accuracy 0.70 10000
macro avg 0.70 0.70 0.69 10000
weighted avg 0.70 0.70 0.69 10000plt.figure(figsize=(2,2))
plt.imshow(X_test[2])
plt.title(f"Pred:{pred[2]}, Real:{Y_test[2]}")
plt.show()
# 가중치 저장
model.save_weights('deep_result/cnn_color.weights.h5')
# 불러오기
model_cifar_load = load_model('deep_result/cnn_color.keras')
# model_cifar_load.summary()
model_cifar_load.load_weights('deep_result/cnn_color.weights.h5')
model_cifar_load.evaluate(X_test, Y_test)[1m313/313[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m2s[0m 6ms/step - accuracy: 0.6940 - loss: 0.9030
[0.9001834988594055, 0.6969000101089478]