
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
해당 글은 혼자 공부하는 머신러닝+딥러닝 책의 실습 내용의 일부를 담고 있습니다.
먼저 지금까지 배운 내용을 조금 정리하자.
지금까지 배운 선형 회귀(Linear Regression)는 단일(단순) 선형 회귀와 다중 선형 회귀가 있었다.
단일 선형 회귀 (Simple Linear Regression)
- 에서,
y는 예측 값, x는 입력 값, w는 가중치(기울기), b는 절편이다.- 목표는 w와 b를 찾아서 예측된 y와 실제 y의 차이인 오차(cost)를 최소화하는 것인데,
이때 최소제곱법(Least Squares)을 사용하여 오차를 계산하고, 이를 최소화하는 최적의 w와 b를 찾는다.
- n은 데이터의 개수, 는 실제 값, 는 예측 값이다.
- 목표는 cost가 0에 가까워지도록 w와 b를 조정하는 것이다.
다중 선형 회귀(Multiple Linear Regression):
- 여러 개의 입력 변수()를 고려하는 선형 회귀다.
- 기본 형태는
그렇다면 이번에는 선형이 아닌 곡선일 때다.
1. 비선형 회귀(Non-linear Regression)
직선 외의 예측 (곡선 형태의 예측)
- 선형 회귀는 직선 형태의 예측이다.
즉 형태에서 x의 차원은 1차다.- 하지만 곡선 형태의 예측을 하려면 다항 회귀(Polynomial Regression) 라는 것을 사용한다.
이는 x의 제곱이나 세제곱 등을 사용하여 데이터를 모델링하는 방식이다.- 예를 들어 2차 다항 회귀에서는 다음과 같이 모델을 구성할 수 있다.
여기서 과 는 학습할 가중치이며, 는 2차 다항식임을 말한다.
이렇게 하면 직선이 아닌 곡선 형태의 예측을 할 수 있다.- 또 곡선의 형태를 더 복잡하게 만들려면 차수(degree)를 늘릴 수 있다.
예를 들어 3차 다항 회귀는 다음과 같은 형태다.
그리고 이때, 각 꺾이는 부분에 따라 차수가 하나씩 증가한다고 보면된다.
- 이런 곡선 형태를 잘 학습하려면 데이터의 분포를 충분히 반영할 수 있는 다항 차수를 선택해야 하는데, 너무 높은 차수를 사용하면 overfitting이 발생할 수도 있다.
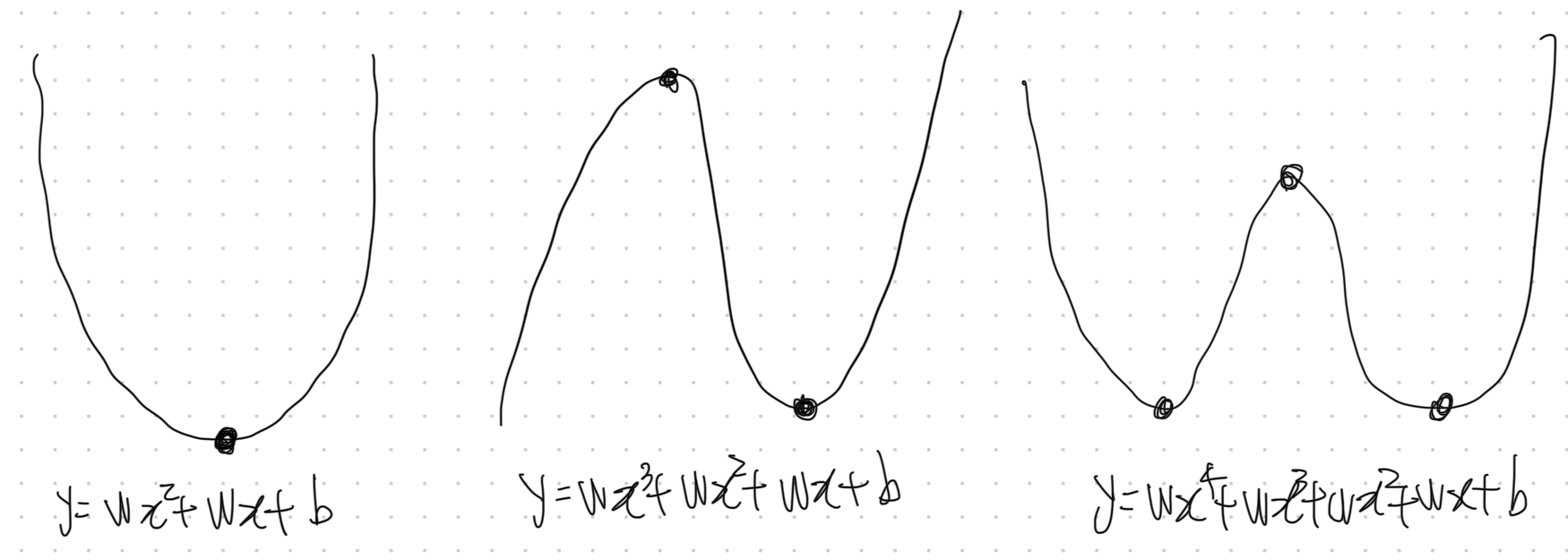
1.1. 다항 회귀(Polynomial Regression)
앞서 진행한 농어의 길이로 무게를 예측했을때 이를 선형으로 판단하고 진행했는데,
사실 scatterplot으로 그린결과가 직선보다는 곡선에 가까웠다.
따라서 선형이 아닌 경우에는 1차식으로 표현이 불가능하므로 2차식으로 변형하여 회귀 분석을 진행한다.
그런데 이 다항 회귀를 하는 클래스와 함수를 따로 지원하지 않는다.
여태까지 선형회귀나 다중선형회귀 같은 경우는 다 지원했는데, 이는 없다.
직접 해야한다.
#입력데이터: 농어 길이 (설명변수)
perch_length=np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0])
#정답데이터: 농어 무게 (목표변수)
perch_weight=np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0])sns.scatterplot(x=perch_length, y=perch_weight)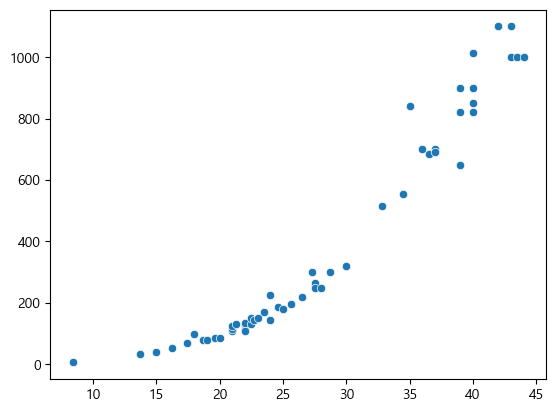
이렇게 나오는데 이는 곡선에 가깝다.
2차 방정식.
그리고 직선의 방정식으로 봤을때 예측이
학습은 0.939846333997604 테스트는 0.8247503123313558이 나왔다.
차이가 조금 났다.
그렇다면 2차로 바꿔서 확인해보자.
X_train, X_test, Y_train, Y_test=train_test_split(perch_length, perch_weight, random_state=42)이제 numpy의 column_stack 함수를 사용하는데,
a=np.array([1,2,3])
b=np.array([4,5,6])
result=np.column_stack((a,b))
resultarray([[1, 4],
[2, 5],
[3, 6]])이렇게 1차원 배열을 열 기준으로 결합해준다.
그래서 이를 이용하면,
X_train_poly=np.column_stack((X_train**2, X_train))
print(X_train_poly.shape)
print(X_train_poly[:5])(42, 2)
[[ 384.16 19.6 ]
[ 484. 22. ]
[ 349.69 18.7 ]
[ 302.76 17.4 ]
[1296. 36. ]]이렇게 계산하여 열을 추가하여 2차원형태로 반환해준다.
즉 이제 가 된다.
X_test_poly=np.column_stack((X_test**2, X_test))
print(X_test_poly.shape)
print(X_test_poly[:5])(14, 2)
[[ 70.56 8.4 ]
[324. 18. ]
[756.25 27.5 ]
[453.69 21.3 ]
[506.25 22.5 ]]그리고 만약 3차 방정식이라면
X_train_poly=np.column_stack((X_train ** 3, X_train ** 2, X_train))과 같이 된다.
학습은 동일하게 진행한다.
lr=LinearRegression()
lr.fit(X_train_poly, Y_train)
print("학습: ", lr.score(X_train_poly, Y_train))
print("일반화: ", lr.score(X_test_poly, Y_test))학습: 0.9706807451768623
일반화: 0.9775935108325121앞서 직선의 방정식으로 봤을때 예측이 학습은 0.939846333997604 테스트는 0.8247503123313558이 나왔다.
이는 학습점수가 너무 높은 과대적합(Overfitting)이었다.
그런데 이번에는 다항회귀의 2차방정식으로 봤더니 테스트 점수가 더 높은 과소적합(Underfitting)이다.
그러면 좋은 모델은 아닌 것이다.
어찌됐든 예측을 보자면, 입력과 마찬가지로 X1, X2, 2개를 넣어준다.
lr.predict([[50**2,50]]) # X1(50**2), X2(50)array([1573.98423528])회귀계수를 보면,
print(lr.coef_, lr.intercept_)[ 1.01433211 -21.55792498] 116.05021078278259기울기는 이렇게 두개가 나온다.
각각 [W1, W2]가 되는 것이다.
이를 이제 시각화하면,
이 기울기와 절편을 이용할 수 있다.
sns.scatterplot(x=X_train, y=Y_train) # 훈련 데이터
sns.scatterplot(x=[50], y=[1573], marker="^") # 예측값
# 2차 방정식 그래프
point=np.arange(15,50) # x축에 맞게 그리기 위해
sns.lineplot(x=point, y=1.0 * point ** 2 - 21.6 * point + 116.05, c="red") #y=1.0x^2-21.6x+116.05
plt.xlabel("length")
plt.ylabel("weight")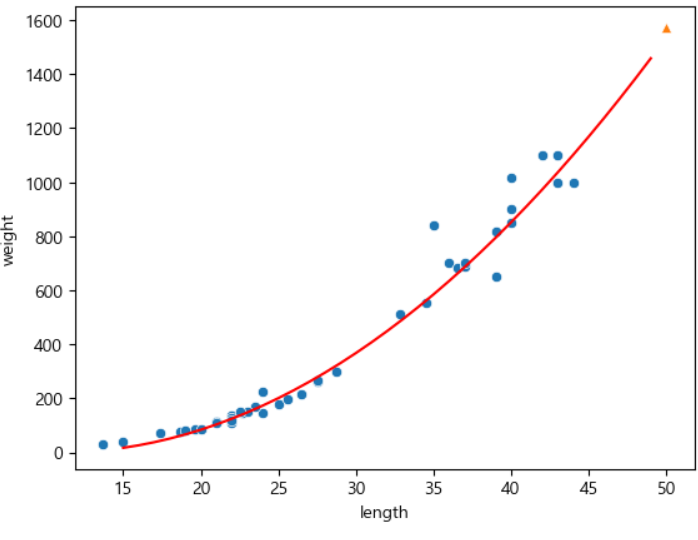
1.2. 사이킷런 변환기
곡선을 그릴때 방정식에 맞게 **를 붙여줘야 하는 불편함을 해소해주는 방법이 있다.
계속해서 **를 붙여서 하는 게 아닌, 이들을 대신해주는 사이킷런의 변환기가 있다.
from sklearn.preprocessing import PolynomialFeaturesdata=[[2,3]]
poly=PolynomialFeatures()
poly.fit(data)
poly.transform(data) # 다변수 다항식으로 바뀜 array([[1., 2., 3., 4., 6., 9.]])이때 각각 설명하자면 다음과 같다.
1: 절편 / 2: 데이터(data[0][0]) / 3: 데이터(data[0][1]) / 4: / 6: 2*3(특성끼리 곱) / 9:
그런데 이때 이 절편인 1은 없어서 1이 나온 것이다.
따라서 이는 버리고 LinearRegression을 사용해면 W와 B가 나오기 때문에 거기서 나온 절편을 사용한다.
data=[[2,3]]
poly=PolynomialFeatures(include_bias=False)
poly.fit(data)
poly.transform(data) array([[2., 3., 4., 6., 9.]])bias는 절편으로 절편을 False로 해줘 사용하지 않는다는 뜻이다.
1.3. 농어 무게 예측 - 다항
Polynomial을 이용하여 변환할때 default는 2로, 2차 방정식이다.
그래서 이 degree를 변경하는 방법이 있다.
농어의 길이와 높이와 두께를 이용해서 무게를 구해보자.
먼저 데이터를 불러오자.
perch_df=pd.read_csv("./data/perch_full.csv")
perch_df.shape(56, 4)perch_df.head()| length | height | width | weight | |
|---|---|---|---|---|
| 0 | 8.4 | 2.11 | 1.41 | 5.9 |
| 1 | 13.7 | 3.53 | 2.00 | 32.0 |
| 2 | 15.0 | 3.82 | 2.43 | 40.0 |
| 3 | 16.2 | 4.59 | 2.63 | 51.5 |
| 4 | 17.4 | 4.59 | 2.94 | 70.0 |
perch_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 56 entries, 0 to 55
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 length 56 non-null float64
1 height 56 non-null float64
2 width 56 non-null float64
3 weight 56 non-null float64
dtypes: float64(4)
memory usage: 1.9 KBperch_df.isna().sum()length 0
height 0
width 0
weight 0
dtype: int64perch_df.describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| length | 56.0 | 27.892857 | 9.021668 | 8.40 | 21.825 | 25.300 | 36.625 | 44.00 |
| height | 56.0 | 7.862143 | 2.878343 | 2.11 | 5.690 | 6.920 | 10.850 | 12.80 |
| width | 56.0 | 4.745536 | 1.775006 | 1.41 | 3.520 | 4.155 | 6.450 | 8.14 |
| weight | 56.0 | 382.239286 | 347.617717 | 5.90 | 120.000 | 207.500 | 692.500 | 1100.00 |
이를 보니 곡선으로 비선형 형태임을 볼 수 있다.
따라서 선형회귀가 아닌 2차방정식이나 3차방정식 등을 사용해야한다.
이제 이를 이용하여 상관성을 보기위해 heatmap을 찍어보자.
sns.heatmap(perch_df.corr(), annot=True)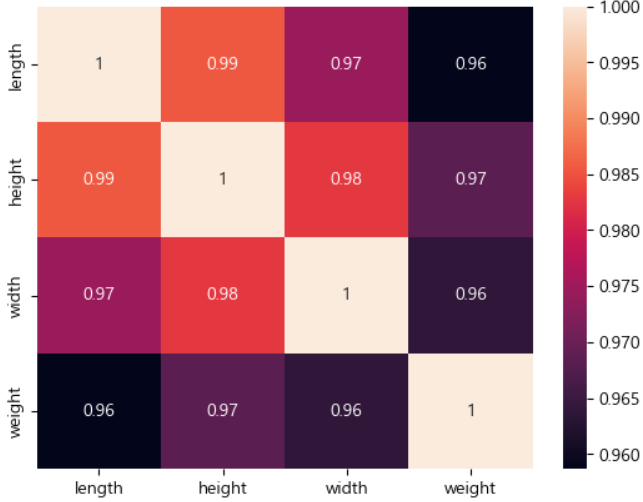
1.3.1. 데이터 전처리
먼저 설명변수와 목표변수를 나눠주자.
perch=perch_df[["length", "height", "width"]]
weight=perch_df["weight"]
print(perch.shape, type(perch))
print(weight.shape, type(weight))(56, 3) <class 'pandas.core.frame.DataFrame'>
(56,) <class 'pandas.core.series.Series'>이미 2차원 DF이기 때문에 따로 fit을 위한 변환이 필요없다.
훈련 세트와 테스트 세트를 나눠보자.
X_train, X_test, Y_train, Y_test=train_test_split(perch, weight, random_state=42)이제 원래라면 StandardScaler로 표준화를 진행하겠지만,
이번에는 다항식이 먼저 선행되어야 한다.
Polynomial을 사용한다.
poly=PolynomialFeatures(include_bias=False)
poly.fit(X_train)
이렇게 fit을 통해 학습을 시켜서
다항식 차수(default 2차)에 따라 변환할 특성들을 결정했고,
transform을 통해 데이터를 실제로 다항식 특성으로 변환하면
X_train_poly=poly.transform(X_train)
print(X_train_poly.shape)
print(X_train_poly[:3])
print(poly.get_feature_names_out())(42, 9)
[[ 19.6 5.14 3.04 384.16 100.744 59.584 26.4196 15.6256
9.2416]
[ 22. 5.88 3.52 484. 129.36 77.44 34.5744 20.6976
12.3904]
[ 18.7 5.2 3.12 349.69 97.24 58.344 27.04 16.224
9.7344]]
['length' 'height' 'width' 'length^2' 'length height' 'length width'
'height^2' 'height width' 'width^2']
test도 바꿔보자.
X_test_poly=poly.transform(X_test)
X_test_poly.shape(14, 9)이제 표준화를 진행하자.
scaler=StandardScaler()
scaler.fit(X_train_poly)
X_train_scaled=scaler.transform(X_train_poly)
X_test_scaled=scaler.transform(X_test_poly)1.3.2. 학습 및 평가
이제 표준화를 완료했으니 이를 학습시키고,
lr=LinearRegression()
lr.fit(X_train_scaled, Y_train)
평가지수를 보면,
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 0.9903183436982124
일반화: 0.9714559911594136이렇게 잘 됐음을 알 수 있다.
기울기와 절편을 확인해보자.
print(lr.coef_, lr.intercept_)[ 303.79797864 -254.82826832 -321.53684302 -1191.04767776
1407.14218929 908.51794857 1374.63985081 -3567.76517863
1696.94993949] 400.833333333334
이렇게 WX1+WX2+...+WX9 까지 총 9개의 기울기와 절편이 나온다.
이전에는 2차방정식인거 같아 라고 정하고나서 직접 **를 사용했는데,
사이킷런에는 PolynomialFeatures를 통해 다항식을 제공한다.
그래서 똑같이 설명변수와 목표변수를 나누고, 훈련세트와 테스트세트로 나누고,
비선형이니까 다항식으로 변환을 한 후 표준화를 진행하고 학습을 시켜줘서
내부적으로 가장 최적의 기울기와 절편을 구한 것이다.
1.4. degree 변경
방금은 default인 2차로 진행했는데, 이 차수를 3차, 4차와 같이 조절할 수 있다.
degree값을 변경해주면 되는데, 이때 주의해야할 점이 있다.
선형에서는 점들이 있고 직선을 그어서 cost값이 0에 가까우면 좋았다.
근데 비선형으로 가면 곡선이 차수에 맞게 꺾이는데,
이렇게 차수가 늘어날수록 자주 꺾이면서 모든 점들에 맞게되어 버린다.
완전히 최적화된 그래프가 된다.
그렇게 해서 학습시키면 트레이닝 데이터로 완전히 100퍼센트 맞춰버리게 되며,
따라서 테스트 데이터가 오면 예측율이 현저히 떨어지게 된다.
그래서 이렇게 degree를 변경할 수 있는데 이에 규제도 존재한다.
X_train, X_test, Y_train, Y_test=train_test_split(perch, weight, random_state=42)
poly=PolynomialFeatures(include_bias=False, degree=5) # 5차 다항식
poly.fit(X_train)
X_train_poly=poly.transform(X_train)
X_test_poly=poly.transform(X_test)
X_train_poly.shape, X_test_poly.shape((42, 55), (14, 55))이렇게 55개가 나와버린다.
우선 나머지를 그냥 진행해보면,
scaler=StandardScaler()
scaler.fit(X_train_poly)
X_train_scaled=scaler.transform(X_train_poly)
X_test_scaled=scaler.transform(X_test_poly)lr=LinearRegression()
lr.fit(X_train_scaled, Y_train)
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 1.0
일반화: -358.85068834475675이렇게 학습은 100퍼센트, 테스트는 현저히 떨어지게된다.
선형회귀의 큰 목표는 결국은 Y값이라는 실제값과 Y헷이라는 예측값이 있을때
둘을 빼서 오차를 줄이는 것이 목표다.
최대한 이 cost가 0에 가깝게.
그렇게 0에 가까운 w와 b를 구해서 데이터를 뿌려서 예측하는 거였는데,
그런데 지금 보면 cost가 0에 완전히 가까워서 학습이 1.0이 나왔다.
그러니 규제를 통해서 cost값을 약간 벌려줄 수 있다.
즉 규제는 훈련세트를 너무 과도하게 학습(Overfitting)하지 못하도록 하는 것이다.
이 규제 모델에는 크게 3가지가 있는데, Ridge Regression(L2), Lasso Regression(L1), Elastic Net(L2 + L1)이 있다.
⭐ 규제 모델
Ridge 회귀는 L2규제라고 한다.
이는 기울기의 제곱을 취하는 것이다.수식은 다음과 같다.
여기서 MSE는 오차의 제곱의 평균인, 되고,
는 규제값,
는 기울기를 말한다.그러면 이제 결국에 MSE가,
에서
는 실제값, 는 예측값인데,
이를 내려줘서 COST, 비용함수가 0에 가까우면 좋은 것이었는데, 완전히 0이면 안되니까, COST를 올려야하는 것이다.이때, 라는 규제를 써서 COST를 올려주는데, 다음과 같다.
만약 공부시간 별 점수의 예측이라고 할떄,
공부시간 실제 점수 예측 점수 오차 1 50 10(1) + 40 = 50 50 - 50 = 0 2 60 10(2) + 40 = 60 60 - 60 = 0 3 72 10(3) + 40 = 70 72 - 70 = 2 4 95 10(4) + 40 = 80 95 - 80 = 15
는 규제값이 0.1일때,
이므로,
67.25가 된다.
만약 값이 1.0이라면, 167.25가 된다.그렇다면, Lasso 회귀는? L1규제라고 하며, 절대값을 취하는 것이다.
만약 값이 1.0이라면, 이므로
67.25가 된다.이렇게해서 Ridge는 큰 값을 줄이는 것이고, 값이 커지면 규제 강도가 강해진다.
그리고 Lasso는 전체적으로 값을 내려서 0이 되는 경우도 있으며, 값이 커지면 규제 강도가 강해진다.그리고 Elastic Net 회귀는 F2 + F1 규제라고 하며, 회귀식은 다음과 같다.
요약
- Ridge 회귀: 모든 가중치가 0에 가까워지도록 하지만, 완전히 0은 되지 않는다.
- Lasso 회귀: 가중치가 일부 0이 되도록 하여 불필요한 변수들을 제거한다. 변수 선택을 할 수 있다.
이제 각각 코드로 살펴보자.
먼저 필요한 라이브러리 import가 필요하다.
from sklearn.linear_model import Ridge, Lasso, ElasticNet1.5. Ridge Regression - L2 규제
ridg=Ridge() # 규제값 default: 1.0
ridg.fit(X_train_scaled, Y_train)
print("학습: ", ridg.score(X_train_scaled, Y_train))
print("일반화: ", ridg.score(X_test_scaled, Y_test))학습: 0.9896101671037343
일반화: 0.9790693977615386이렇게 조절이 좀 됐다.
1.5.1. Hyper Parameter
그렇다면 가장 좋은 비용함수를 찾기위해 규제값들을 조절해서 하이퍼 파라미터를 찾아보자.
alpha_list=[0.001, 0.01, 0.1, 1, 10, 100]
for i in alpha_list:
ridg=Ridge(alpha=i)
ridg.fit(X_train_scaled, Y_train)
print(f"{i} 의 경우")
print("학습: ", ridg.score(X_train_scaled, Y_train))
print("일반화: ", ridg.score(X_test_scaled, Y_test), "\n")0.001 의 경우
학습: 0.9930455252088589
일반화: 0.9569388961572401
0.01 의 경우
학습: 0.9917809981250533
일반화: 0.9800187936873217
0.1 의 경우
학습: 0.9903815817570368
일반화: 0.9827976465386896
1 의 경우
학습: 0.9896101671037343
일반화: 0.9790693977615386
10 의 경우
학습: 0.988728468997471
일반화: 0.9725329582461569
100 의 경우
학습: 0.9841843235774494
일반화: 0.9627042641050291 이렇게 보니 0.1의 경우가 가장 좋다.
ridg=Ridge(alpha=0.1)
ridg.fit(X_train_scaled, Y_train)
print("학습: ", ridg.score(X_train_scaled, Y_train))
print("일반화: ", ridg.score(X_test_scaled, Y_test))학습: 0.9903815817570368
일반화: 0.98279764653868961.6. Lasso Regression - L1 규제
L2 규제와 똑같으며 절대값이란 점만 다르다.
lasso=Lasso() # 규제값(alpha) default: 1.0
lasso.fit(X_train_scaled, Y_train)
print("학습: ", lasso.score(X_train_scaled, Y_train))
print("일반화: ", lasso.score(X_test_scaled, Y_test))학습: 0.989789897208096
일반화: 0.98005936984218841.6.1. Hyper Parameter
이번에도 하이퍼파라미터를 찾아보자.
alpha_list=[0.001, 0.01, 0.1, 1, 10, 100]
for i in alpha_list:
lasso=Lasso(alpha=i)
lasso.fit(X_train_scaled, Y_train)
print(f"{i} 의 경우")
print("학습: ", lasso.score(X_train_scaled, Y_train))
print("일반화: ", lasso.score(X_test_scaled, Y_test), "\n")0.001 의 경우
학습: 0.990856843502147
일반화: 0.9836870822242811
0.01 의 경우
학습: 0.9907921500205304
일반화: 0.9836730006301537
0.1 의 경우
학습: 0.990137631128448
일반화: 0.9819405116249365
1 의 경우
학습: 0.989789897208096
일반화: 0.9800593698421884
10 의 경우
학습: 0.9888067471131867
일반화: 0.9824470598706695
100 의 경우
학습: 0.9078632190121445
일반화: 0.9089071866576978 이 Lasso의 경우는 절대값에 의해서 작아진다.
사실 지금까지 예시를 기울기를 10, 20과 같이 줬는데, 실제로는 이 기울기 값이 작다.
그래서 계산할때, 작은 값들이 사라진다. 0이 된다.
그래서 연산을 못하기에 에러가 나온다.
그래서 이럴때는 tol을 붙여준다.
lasso=Lasso(alpha=i, tol=0.01) 과 같이 쓰면 tol=0.0001까지 맞춰준다.
alpha_list=[0.001, 0.01, 0.1, 1, 10, 100]
for i in alpha_list:
lasso=Lasso(alpha=i, tol=0.01)
lasso.fit(X_train_scaled, Y_train)
print(f"{i} 의 경우")
print("학습: ", lasso.score(X_train_scaled, Y_train))
print("일반화: ", lasso.score(X_test_scaled, Y_test), "\n")0.001 의 경우
학습: 0.9895887652971921
일반화: 0.9791639863640221
0.01 의 경우
학습: 0.9895859983177738
일반화: 0.9791764660209303
0.1 의 경우
학습: 0.9895821979373867
일반화: 0.9793294780259653
1 의 경우
학습: 0.9896113508418363
일반화: 0.979381678280601
10 의 경우
학습: 0.9887771640090557
일반화: 0.9814967081245412
100 의 경우
학습: 0.9078675125788189
일반화: 0.9122608061027394 이렇게 보니 10의 경우가 가장 좋다.
lasso=Lasso(alpha=10)
lasso.fit(X_train_scaled, Y_train)
print("학습: ", lasso.score(X_train_scaled, Y_train))
print("일반화: ", lasso.score(X_test_scaled, Y_test))학습: 0.9888067471131867
일반화: 0.9824470598706695다항회귀 -> 너무 잘맞춤 -> 좀 평평하게 펴주자.
L2 나옴 -> 큰값만 제어 잘함
작은값도 필요한데 -> L1
이 둘을 합치자.
1.7. Elastic Net Regression - L2 + L1 규제
elastic_net=ElasticNet()
elastic_net.fit(X_train_scaled, Y_train)
print("학습: ", elastic_net.score(X_train_scaled, Y_train))
print("일반화: ", elastic_net.score(X_test_scaled, Y_test))학습: 0.9878525957972832
일반화: 0.96876069376052811.7.1 Hyper Parameter
alpha_list=[0.001, 0.01, 0.1, 1, 10, 100]
for i in alpha_list:
elastic_net=ElasticNet(alpha=i, tol=0.01)
elastic_net.fit(X_train_scaled, Y_train)
print(f"{i} 의 경우")
print("학습: ", elastic_net.score(X_train_scaled, Y_train))
print("일반화: ", elastic_net.score(X_test_scaled, Y_test), "\n")0.001 의 경우
학습: 0.9895837543906777
일반화: 0.9792094872705828
0.01 의 경우
학습: 0.9897136092785505
일반화: 0.9799404329395662
0.1 의 경우
학습: 0.9894568298400469
일반화: 0.9783438743730399
1 의 경우
학습: 0.9874721717922743
일반화: 0.9664988885767642
10 의 경우
학습: 0.9758820208857515
일반화: 0.9609683886122534
100 의 경우
학습: 0.678962151998775
일반화: 0.6869802186891522 2. fit과 transform
⭐내가 헷갈려서 하는 정리
- fit
- StandardScaler: 트레이닝 데이터에서 평균과 표준편차를 계산함
- PolynomialFeatures: 주어진 데이터에 대해 다항식 차수에 따라 변환할 특성들을 결정함
- LinearRegression: 주어진 데이터에 대해 회귀 계수를 계산하여 모델을 학습시킴
- transform
- StandardScaler: 트레이닝 데이터에서 계산한 평균과 표준편차를 사용해 새로운 데이터를 표준화함
- PolynomialFeatures: 트레이닝 데이터에서 정의된 다항식 변환 규칙을 사용하여 새로운 특성을 생성함
- LinearRegression: 학습한 모델을 사용해 예측값을 계산함
- fit과 transform의 순서:
- fit → 학습 (규칙을 찾음)
- transform → 변환 (학습한 규칙을 바탕으로 실제 데이터 변환)
- fit_transform:
- fit과 transform을 한 번에 호출하고 싶을 때 fit_transform을 사용할 수 있음
- 단순화된 방법으로, 학습과 변환을 한 번에 처리할 수 있게 도와줌
- 정리
- fit은 학습을 담당하고, transform은 변환을 담당
- 새로운 데이터를 변환할 때는 학습한 객체 (scaler, poly, 모델 등)를 사용하여 transform 또는 predict를 호출함
- 트레이닝 데이터에서 학습한 규칙을 바탕으로 테스트 데이터나 새로운 데이터를 변환하는 방식
