
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
해당 글은 혼자 공부하는 머신러닝+딥러닝 책의 실습 내용의 일부를 담고 있습니다.
지금까지 K 최근접 이웃을 KNN으로 분류(문자), KNR으로 회귀(숫자)로,
그리고 선형회귀와 비선형회귀까지 진행했는데,
이번에는 이 선형회귀에 로지스틱 회귀라는 것이 있는데,
이는 사실 선형회귀의 분류라고 한다.
즉 선형회귀안에 분류와 회귀가 있는 것이고, 이 로지스틱 회귀는 분류하는 문제이다.
1. 로지스틱 회귀(Logistic Regression)
선형회귀의 분류모델이다.
이는 이진 분류와 다중 분류로 나뉘는데 먼저 이진 분류에 대해 알아보자.
필요한 라이브러리를 import하자.
# 기본적인 부분
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
# 데이터 전처리
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 학습 알고리즘
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from scipy.special import expit, softmax1.1. 이진 분류 - Sigmoid 함수
Sigmoid 함수를 사용하여 0~1사이의 확률로 변환
다중 선형 방정식은
y = wx1 + wX2 + ... + wxn + b였다.
이를 이용하는데, 시그모이드 함수와 동일한 로지스틱 함수에 이를 적용시키는 것이다.
시그모이드 함수 다음과 같다.
로지스틱 함수는,
여기서 x는 입력 값, e는 자연상수다. (대략 2.718)
이제 y는
일때,
가 된다.
그리고 는
(대략)
그래서 로지스틱 함수 는,
(대략)
이렇게 나온다.
따라서 시그모이드 함수 그래프와 도미와 빙어로 분류할때,
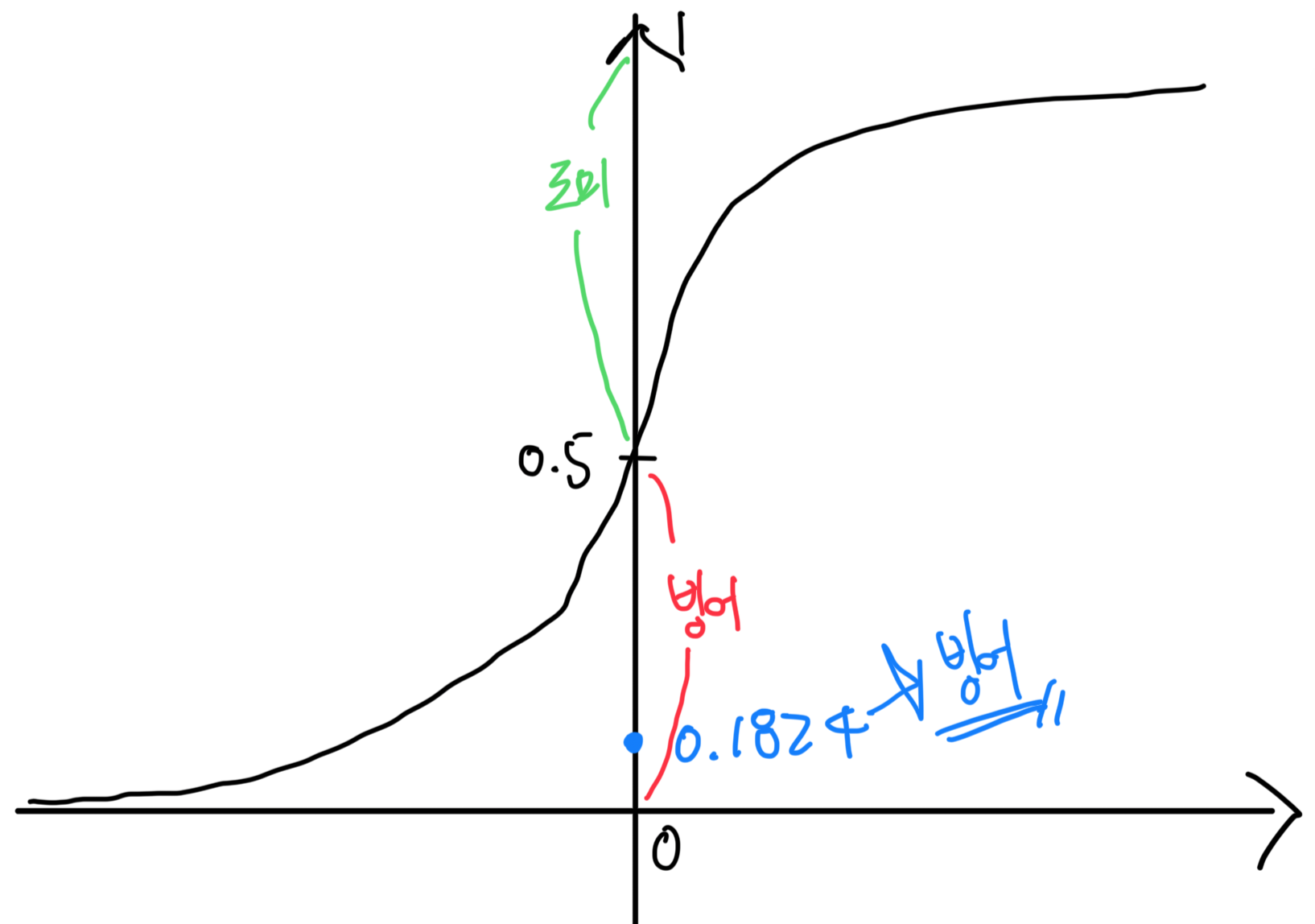
이처럼 빙어로 분류하는 것이다.
1.1.1. 데이터 전처리
이제 데이터를 가져오자.
fish=pd.read_csv("./data/fish_data.csv")
fish.shape(159, 6)fish.head()| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
fish.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 159 entries, 0 to 158
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Species 159 non-null object
1 Weight 159 non-null float64
2 Length 159 non-null float64
3 Diagonal 159 non-null float64
4 Height 159 non-null float64
5 Width 159 non-null float64
dtypes: float64(5), object(1)
memory usage: 7.6+ KBfish.isna().sum()Species 0
Weight 0
Length 0
Diagonal 0
Height 0
Width 0
dtype: int64fish.describe()| Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|
| count | 159.000000 | 159.000000 | 159.000000 | 159.000000 | 159.000000 |
| mean | 398.326415 | 28.415723 | 31.227044 | 8.970994 | 4.417486 |
| std | 357.978317 | 10.716328 | 11.610246 | 4.286208 | 1.685804 |
| min | 0.000000 | 8.400000 | 8.800000 | 1.728400 | 1.047600 |
| 25% | 120.000000 | 21.000000 | 23.150000 | 5.944800 | 3.385650 |
| 50% | 273.000000 | 27.300000 | 29.400000 | 7.786000 | 4.248500 |
| 75% | 650.000000 | 35.500000 | 39.650000 | 12.365900 | 5.584500 |
| max | 1650.000000 | 63.400000 | 68.000000 | 18.957000 | 8.142000 |
이렇게 결측치와 이상치도 없다.
그리고 종류를 보면 다음과 같다.
fish["Species"].value_counts()Species
Perch 56
Bream 35
Roach 20
Pike 17
Smelt 14
Parkki 11
Whitefish 6
Name: count, dtype: int64이들중에 이제 이진 분류이기 때문에, 여기서 도미와 빙어의 데이터를 가져오자.
condition=(fish["Species"]=="Bream") | (fish["Species"]=="Smelt")
bream_smelt_fish=fish[condition]
bream_smelt_fish.shape(49, 6)bream_smelt_fish["Species"].value_counts()Species
Bream 35
Smelt 14
Name: count, dtype: int64bream_smelt_fish.info()<class 'pandas.core.frame.DataFrame'>
Index: 49 entries, 0 to 158
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Species 49 non-null object
1 Weight 49 non-null float64
2 Length 49 non-null float64
3 Diagonal 49 non-null float64
4 Height 49 non-null float64
5 Width 49 non-null float64
dtypes: float64(5), object(1)
memory usage: 2.7+ KB역시나 결측치는 없고, 기술통계량을 확인해보자.
bream_smelt_fish.describe()| Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|
| count | 49.000000 | 49.000000 | 49.000000 | 49.000000 | 49.000000 |
| mean | 444.500000 | 27.055102 | 31.120408 | 11.476400 | 4.259751 |
| std | 328.143233 | 10.242804 | 12.097296 | 6.150976 | 1.967686 |
| min | 6.700000 | 9.800000 | 10.800000 | 1.728400 | 1.047600 |
| 25% | 19.700000 | 14.300000 | 15.200000 | 2.872800 | 1.879200 |
| 50% | 500.000000 | 31.000000 | 36.200000 | 14.179500 | 5.072800 |
| 75% | 700.000000 | 34.500000 | 39.700000 | 15.633000 | 5.589000 |
| max | 1000.000000 | 41.000000 | 46.500000 | 18.957000 | 6.749700 |
이도 문제가 없는거 같다.
시각화를 해보자.
sns.pairplot(bream_smelt_fish, hue="Species")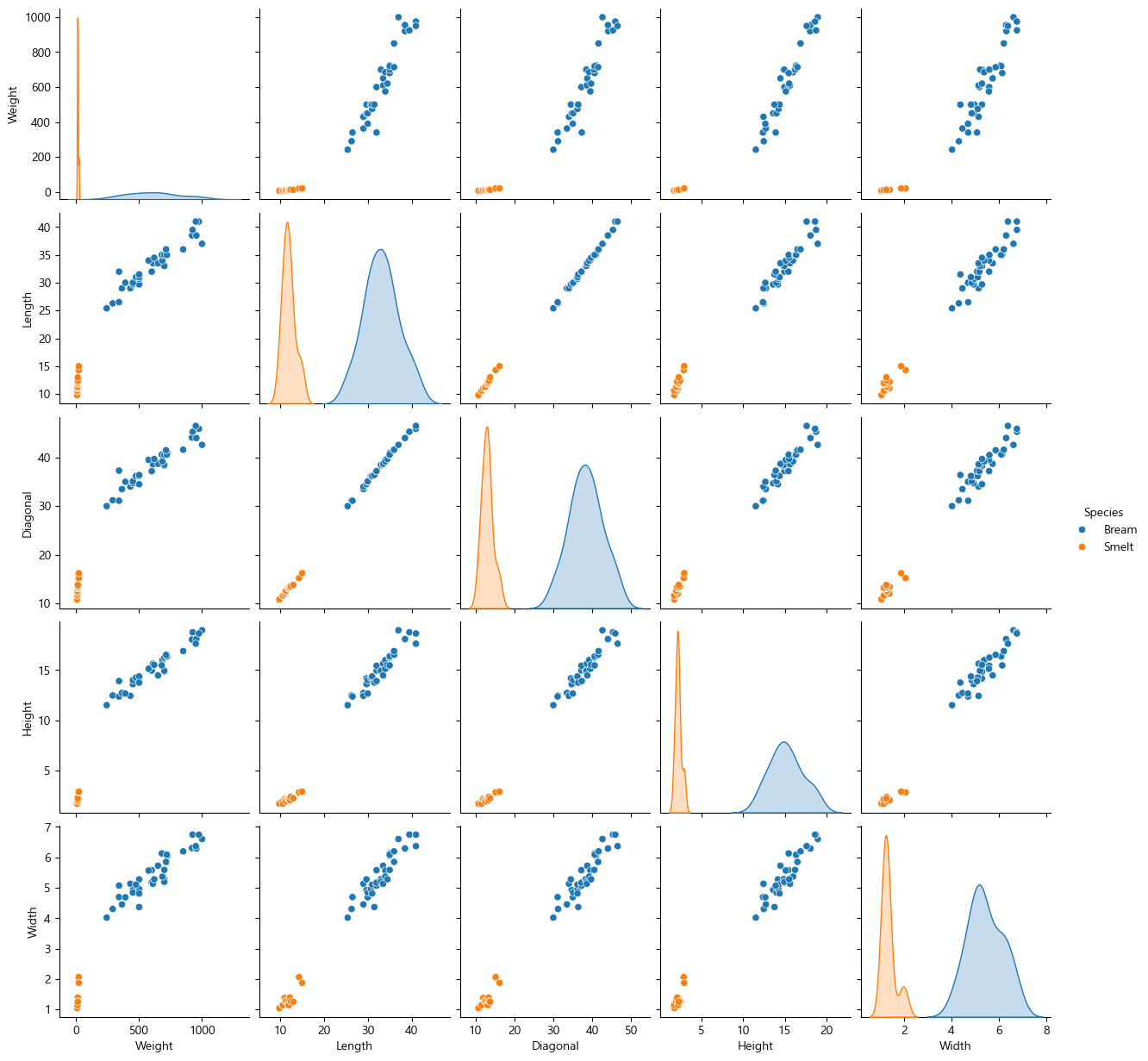
예측이 잘 될거 같다.
이제 각각 X와 Y를 설정해줘야한다.
bream_smelt_fish.head()| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
1.1.2. 훈련 및 평가
이제 표준화를 진행하자.
X_train, X_test, Y_train, Y_test=train_test_split(X, Y, random_state=42)
scaler=StandardScaler()
scaler.fit(X_train)
X_train_scaled=scaler.transform(X_train)
X_test_scaled=scaler.transform(X_test)이제 모델이 들어오면 되는데 Logistic이다.
lr=LogisticRegression()
lr.fit(X_train_scaled, Y_train)
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 1.0
일반화: 1.0평가지표를 확인해보자.
정확도, 정밀도, 재현율, f1-score
Y_test_pred=lr.predict(X_test_scaled)
print(classification_report(Y_test, Y_test_pred)) precision recall f1-score support
Bream 1.00 1.00 1.00 10
Smelt 1.00 1.00 1.00 3
accuracy 1.00 13
macro avg 1.00 1.00 1.00 13
weighted avg 1.00 1.00 1.00 13회귀계수를 보자.
print("기울기: ", lr.coef_)
print("절편: ", lr.intercept_)기울기: [[-0.57717269 -0.79233938 -0.82533982 -0.86579233 -0.82205625]]
절편: [-2.38186126]스케일을 조절한 것이기 때문에 기울기가 값이 위와같이 나온다.
즉 z= -0.57 Weight -0.79 Length -0.82 Diagonal -0.86 Height -0.82 * Width -2.38이다.
그렇다면 스케일 조절이 되지 않은 값들을 보려면,
decision_fuction이라는 함수를 사용하면된다.
z 값들을 보면 된다.
d=lr.decision_function(X_test_scaled[:5])
expit(d)array([0.01840178, 0.95009904, 0.90701723, 0.95104955, 0.00684335])따라서, 각각 bream, smelt, smelt, smelt, bream 으로 분류가 된다.
1.2. 다중 분류 - Softmax 함수
클래스에 속할 확률을 나타내는 확률 분포
Sigmoid함수는 하나의 선형 방정식의 출력값을 0~1 사이로 나타냈는데,
이는 여러 개의 선형 방정식의 출력값을 0~1 사이로 나타내고, 그 합이 1이 되도록 한다.
함수는 다음과 같다.
이제 가, 일때,
y는, 가 된다.
이제 SoftMax함수를 사용하여 각 클래스에 속할 확률을 계산하면 다음과 같다.
먼저 각 클래스의 지수 함수는,
(대략)
(대략)
(대략)
그리고 이제 함수를 사용하여 각 클래스에 속할 확률을 계산하면,
이렇게하여 이되며, 제일 높은 0.659로 분류하게 된다.
이를 활용하여 이번에는 모든 종을 분류해보자.
1.2.1. 데이터 전처리
fish.shape(159, 6)fish.describe(include="object")| Species | |
|---|---|
| count | 159 |
| unique | 7 |
| top | Perch |
| freq | 56 |
fish["Species"].value_counts()Species
Perch 56
Bream 35
Roach 20
Pike 17
Smelt 14
Parkki 11
Whitefish 6
Name: count, dtype: int64총 7개의 어종이 있으며, Perch가 가장 많다.
시각화해보면 다음과 같다.
sns.pairplot(data=fish, hue="Species")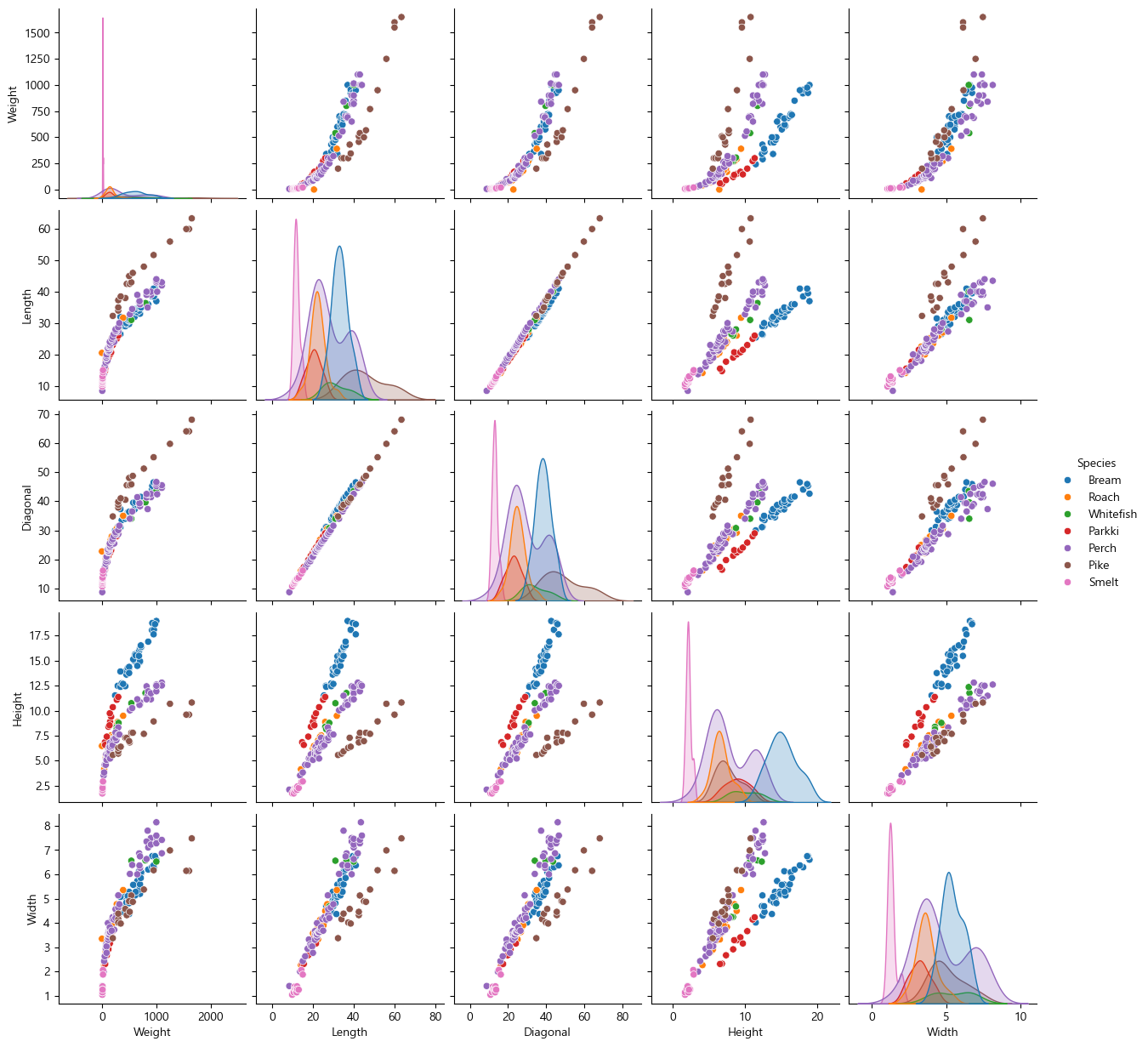
1.2.2. 학습 및 평가
이제 X와 Y를 나눠주자.
fish.head()| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
X=fish.iloc[:, 1:6]
Y=fish["Species"]
print(X.shape, type(X))
print(Y.shape, type(Y))(159, 5) <class 'pandas.core.frame.DataFrame'>
(159,) <class 'pandas.core.series.Series'>X_train, X_test, Y_train, Y_test=train_test_split(X, Y, random_state=42)
scaler=StandardScaler()
scaler.fit(X_train)
X_train_scaled=scaler.transform(X_train)
X_test_scaled=scaler.transform(X_test)정규화를 마쳤으니 학습시키자.
lr=LogisticRegression()
lr.fit(X_train_scaled, Y_train)
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 0.8067226890756303
일반화: 0.85이를 보니 테스트 점수가 더 높다.
즉 좋은 모델이 아니다.
그래서 이럴때 로지스틱 회귀에서 규제를 줄 수 있다.
LogisticRegression()의 내부를 보면, C라는 부분과 l1_ratio라는 것이 있는데,
이게 바로 C는 L2 규제이며, l1_ratio가 L1규제다.
릿지와 라쏘와 똑같이 하면된다.
현재 C값이 default로 1.0이, l1_ratio는 None이다.
단, L2는 alpha값이 커질수록 규제가 강해지고, 비용함수의 값이 커지는데, C는 그 반대이다.
즉 alpha값이 작을수록 규제가 커진다.
lr=LogisticRegression(C=20)
lr.fit(X_train_scaled, Y_train)
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 0.9327731092436975
일반화: 0.925이렇게 over나 under fitting일때, 비용함수를 조절해서 맞출 수 있다.
이제 전체적인 예측을 해보자.
Y_test_pred=lr.predict(X_test_scaled)
print(classification_report(Y_test,Y_test_pred)) precision recall f1-score support
Bream 1.00 1.00 1.00 11
Parkki 1.00 1.00 1.00 2
Perch 0.92 1.00 0.96 12
Pike 1.00 1.00 1.00 4
Roach 0.60 1.00 0.75 3
Smelt 1.00 1.00 1.00 5
Whitefish 0.00 0.00 0.00 3
accuracy 0.93 40
macro avg 0.79 0.86 0.82 40
weighted avg 0.87 0.93 0.89 40이때 경고메세지가 나타난다면 데이터가 작아서 나타날 수 있다.
이제 회귀계수를 보자.
print("기울기: ", lr.coef_)
print("절편: ", lr.intercept_)기울기: [[-1.50605454 -1.03747913 2.60919714 7.69422736 -1.1860334 ]
[ 0.19200048 -1.99988811 -3.79617726 6.50312639 -2.00022756]
[ 3.55793539 6.36988929 -8.52233732 -5.75397234 3.79233439]
[-0.11453307 3.61060121 3.94464503 -3.62243903 -1.75981681]
[-1.40843715 -6.0924219 5.28629633 -0.86696568 1.84518453]
[-1.33419959 1.48153394 1.38217548 -5.6602348 -4.39228961]
[ 0.61328848 -2.33223529 -0.9037994 1.70625808 3.70084847]]
절편: [-0.10345042 -0.27281216 3.24444852 -0.1756507 2.64960026 -6.72042857
1.37829307]분류해줘야할 종류는 총 7개다.
그래서 X1, X2, ... X5의 7개의 w, b값들이 나온 것이다.
그렇다면 이제 스케일을 맞춰서 5개 정도의 z값을 보면 다음과 같다.
d=lr.decision_function(X_test_scaled[:5])
darray([[ -6.50722809, 1.03902668, 5.16819137, -2.75730348,
3.33655199, 0.34625855, -0.62549702],
[-10.87900742, 1.94410613, 4.77600605, -2.42306184,
2.98748716, 7.8417137 , -4.24724377],
[ -4.33809952, -6.2369028 , 3.16746647, 6.48091389,
2.36412675, 2.43431895, -3.87182375],
[ -0.6914399 , 0.44628535, 2.64291145, -1.21457287,
3.2612452 , -5.70143409, 1.25700486],
[ -6.40138606, -1.99137621, 5.81526371, -0.13464403,
3.49905132, -0.08753489, -0.69937384]])이제 각 행을 softmax로 계산하면,
proba=softmax(d, axis=1)
np.round(proba, 3)array([[0. , 0.014, 0.842, 0. , 0.135, 0.007, 0.003],
[0. , 0.003, 0.044, 0. , 0.007, 0.946, 0. ],
[0. , 0. , 0.034, 0.934, 0.015, 0.016, 0. ],
[0.011, 0.034, 0.305, 0.006, 0.567, 0. , 0.076],
[0. , 0. , 0.904, 0.002, 0.089, 0.002, 0.001]])이렇게 5개의 행에서 가장 큰 값들로 분류되는 것이다.
이 각 어종은 알파벳 순서대로,
'Bream', 'Parkki', 'Perch', 'Pike', 'Roach', 'Smelt', 'Whitefish' 이므로,
0번쨰 행은 Perch가 되는 것이다.
#fish["Species"].unique()
lr.classes_array(['Bream', 'Parkki', 'Perch', 'Pike', 'Roach', 'Smelt', 'Whitefish'],
dtype=object)각 클래스 정보를 보려면 이렇게 사용하면 된다.
이에 대해 좀 더 설명하자면,
fish["Species"].value_counts()Species
Perch 56
Bream 35
Roach 20
Pike 17
Smelt 14
Parkki 11
Whitefish 6
Name: count, dtype: int64DataFrame에서는 valuecounts()를 하면 개수로 내림차순 해주는데,
y값이 머신러닝에 들어갈때는 알파벳 순서의 오름차순으로 들어간다.
그래서 lr.classes를 사용해서 확인할때,
lr.classes_array(['Bream', 'Parkki', 'Perch', 'Pike', 'Roach', 'Smelt', 'Whitefish'],
dtype=object)
이렇게 나오는데 이게 사실 내부적으로는 원핫인코딩으로 들어간다.
1 0 0 0 0 0 0
0 1 0 0 0 0 0
...
이런식으로 들어가기 때문에 0번째 행은 Perch가 되는 것이다.
그래서 이를 찍어보면,
Y_test_pred=lr.predict(X_test_scaled)
Y_test_predarray(['Perch', 'Smelt', 'Pike', 'Roach', 'Perch', 'Bream', 'Smelt',
'Roach', 'Perch', 'Pike', 'Bream', 'Perch', 'Bream', 'Parkki',
'Bream', 'Bream', 'Perch', 'Perch', 'Perch', 'Bream', 'Smelt',
'Bream', 'Bream', 'Bream', 'Bream', 'Perch', 'Perch', 'Roach',
'Smelt', 'Smelt', 'Pike', 'Perch', 'Perch', 'Pike', 'Bream',
'Perch', 'Roach', 'Roach', 'Parkki', 'Perch'], dtype=object)2.1. Kaggle 피마 인디언 당뇨병 예측
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database
설명변수들을 이용하여 목표변수인 Outcome을 에측하는 문제다.
2.1.1. 데이터 전처리
df=pd.read_csv("./data/diabetes.csv")
df.shape(768, 9)df.head()| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB총 9개의 변수들 중 목표변수 Outcome을 예측하는 문제다.
이상치는 없고 기술통계량을 확인해 이상치가 있는지 보자.
df.describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Pregnancies | 768.0 | 3.845052 | 3.369578 | 0.000 | 1.00000 | 3.0000 | 6.00000 | 17.00 |
| Glucose | 768.0 | 120.894531 | 31.972618 | 0.000 | 99.00000 | 117.0000 | 140.25000 | 199.00 |
| BloodPressure | 768.0 | 69.105469 | 19.355807 | 0.000 | 62.00000 | 72.0000 | 80.00000 | 122.00 |
| SkinThickness | 768.0 | 20.536458 | 15.952218 | 0.000 | 0.00000 | 23.0000 | 32.00000 | 99.00 |
| Insulin | 768.0 | 79.799479 | 115.244002 | 0.000 | 0.00000 | 30.5000 | 127.25000 | 846.00 |
| BMI | 768.0 | 31.992578 | 7.884160 | 0.000 | 27.30000 | 32.0000 | 36.60000 | 67.10 |
| DiabetesPedigreeFunction | 768.0 | 0.471876 | 0.331329 | 0.078 | 0.24375 | 0.3725 | 0.62625 | 2.42 |
| Age | 768.0 | 33.240885 | 11.760232 | 21.000 | 24.00000 | 29.0000 | 41.00000 | 81.00 |
| Outcome | 768.0 | 0.348958 | 0.476951 | 0.000 | 0.00000 | 0.0000 | 1.00000 | 1.00 |
그럼 전체를 시각화해서 보자.
sns.pairplot(data=df, hue="Outcome")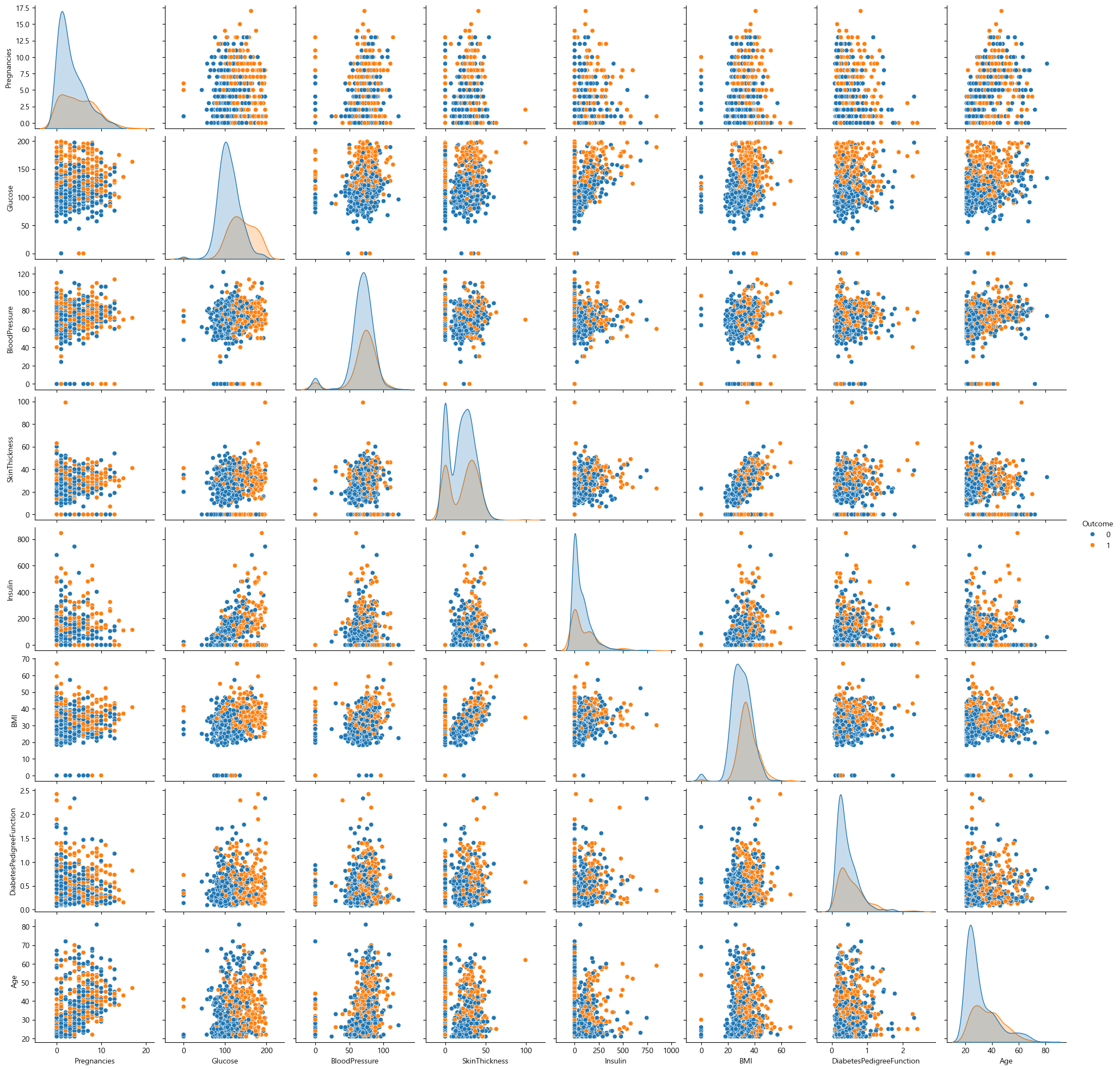
그런데 보면 데이터들이 너무 퍼져있어서 예측이 잘 안나올거 같다.
KNN이 더 좋을 수도 있다.
상관관계도 보자.
df.corr().round(2)| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| Pregnancies | 1.00 | 0.13 | 0.14 | -0.08 | -0.07 | 0.02 | -0.03 | 0.54 | 0.22 |
| Glucose | 0.13 | 1.00 | 0.15 | 0.06 | 0.33 | 0.22 | 0.14 | 0.26 | 0.47 |
| BloodPressure | 0.14 | 0.15 | 1.00 | 0.21 | 0.09 | 0.28 | 0.04 | 0.24 | 0.07 |
| SkinThickness | -0.08 | 0.06 | 0.21 | 1.00 | 0.44 | 0.39 | 0.18 | -0.11 | 0.07 |
| Insulin | -0.07 | 0.33 | 0.09 | 0.44 | 1.00 | 0.20 | 0.19 | -0.04 | 0.13 |
| BMI | 0.02 | 0.22 | 0.28 | 0.39 | 0.20 | 1.00 | 0.14 | 0.04 | 0.29 |
| DiabetesPedigreeFunction | -0.03 | 0.14 | 0.04 | 0.18 | 0.19 | 0.14 | 1.00 | 0.03 | 0.17 |
| Age | 0.54 | 0.26 | 0.24 | -0.11 | -0.04 | 0.04 | 0.03 | 1.00 | 0.24 |
| Outcome | 0.22 | 0.47 | 0.07 | 0.07 | 0.13 | 0.29 | 0.17 | 0.24 | 1.00 |
너무 정신없으니까 Outcome을 기준으로 절대값(음의상관관계도 상관없이)을 붙여서 보자.
corr_df=df.corr().round(2)["Outcome"].abs()
corr_sort=corr_df.sort_values(ascending=False)
corr_sortOutcome 1.00
Glucose 0.47
BMI 0.29
Age 0.24
Pregnancies 0.22
DiabetesPedigreeFunction 0.17
Insulin 0.13
SkinThickness 0.07
BloodPressure 0.07
Name: Outcome, dtype: float64가장 위 Outcome은 자기 자신이니까 제외하고 보면,
전체적으로 좋지는 않다.
이제 설명변수X와 목표변수Y를 나눠줘야한다.
Y는 Outcome이니까 X형태를 fit을 위해 2차원 형태로 바꿔놓자.
이때 0.07과 같은 건 의미가 없으니까 제외하자.
corr_sort.indexIndex(['Outcome', 'Glucose', 'BMI', 'Age', 'Pregnancies',
'DiabetesPedigreeFunction', 'Insulin', 'SkinThickness',
'BloodPressure'],
dtype='object')X=df[['Glucose', 'BMI', 'Age', 'Pregnancies', 'DiabetesPedigreeFunction', 'Insulin']]
Y=df["Outcome"]
print(X.shape, type(X))
print(Y.shape, type(Y))(768, 6) <class 'pandas.core.frame.DataFrame'>
(768,) <class 'pandas.core.series.Series'>2.1.2. 학습 및 평가
학습과 테스트 데이터 셋을 나눠주자.
X_train, X_test, Y_train, Y_test=train_test_split(X, Y, random_state=42)나눠줬으니 먼저 표준화 작업을 진행하고,
scaler=StandardScaler()
scaler.fit(X_train)
X_train_scaled=scaler.transform(X_train)
X_test_scaled=scaler.transform(X_test)이제 로지스틱 회귀를 이용해서 학습시키자.
lr=LogisticRegression()
lr.fit(X_train_scaled, Y_train)
이제 학습을 시켰으니 정확도를 평가를 해보면,
print("학습: ", lr.score(X_train_scaled, Y_train))
print("일반화: ", lr.score(X_test_scaled, Y_test))학습: 0.7725694444444444
일반화: 0.734375상관성이 높은 편은 아니였는데, 77점 정도면 괜찮게 나왔다.
Over나 Undder fitting도 아니다.
그러면 이제 정확도, 재현율 등을 확인하자.
Y_test_pred=lr.predict(X_test_scaled)
print(classification_report(Y_test, Y_test_pred)) precision recall f1-score support
0 0.79 0.80 0.79 123
1 0.63 0.62 0.63 69
accuracy 0.73 192
macro avg 0.71 0.71 0.71 192
weighted avg 0.73 0.73 0.73 1921을 좀 잘 못맞췄다.
60퍼센트 정도면 그렇게 좋은 모델은 아니다.
이제 회귀계수를 보자.
print("기울기: ", lr.coef_)
print("절편: ", lr.intercept_)
print("클래스: ", lr.classes_)기울기: [[ 1.10311335 0.73208695 0.38045505 0.18911578 0.17847568 -0.15156385]]
절편: [-0.89655917]
클래스: [0 1]⭐ 그런데 이를 보니
로지스틱 회귀를 보니까 회귀선을 이용해서 분류를 해주는 건데,
y = w1x1 + w2x2 + ... + w6x6 + b가 되는데,w1=1.10이 될 것이고,
w2=0.73, ..., w6=-0.15가 될 것이다.오케이 알겠는데 원칙적으로 따지면,
분류하려고 하는 애는 0과 1인데,
0에도 w1x1부터 w6x6이 있을 것이고, 1도 마찬가진데,
그러면 기울기와 절편이 0의 입장과 1의 입장으로 2개씩이 나와야한다.전에 다중분류인 softmax를 살펴보면,
학습을 할때를 보면, 5개의 열을 넣었고, 분류는 7개로 했었다.
그러면 각각 7개의 분류당 w1x1 + w2x2 + ... + w5x5 + b가 반복되어야 했다.
그래서 결과값도 딱 맞게 떨어졌다.
(lr.coef와 lr.intercept_ 부분)7개의 분류에 대해 5개의 기울기와 1개의 절편이 반복됐다.
그러니까 얘도 0과 1이니까
0에 대한 기울기6개와 절편1개,
1에 대한 기울기6개와 절편1개가 나와야하는데,하나에 대해서만 나왔다.
그 이유는 로지스틱회귀 이진분류의 출력(기울기, 절편)은 "양성(1)"의 값만 출력이 되기 때문 이다.
이제 확률을 계산하기 위해 결정 함수를 사용하고
시그모이드 함수에 넣어보자.
d=lr.decision_function(X_test_scaled[:5])
expit(d)array([0.23474285, 0.19864747, 0.11941522, 0.1843502 , 0.53764491])그러면 이제 로지스틱 회귀 모델이 예측한 클래스 레이블을 보면,
Y_test_pred[:5]array([0, 0, 0, 0, 1])이렇게 0.5보다 높은 마지막꺼만 1이나온 것이다.
그리고 앞서 KNN이 더 나을거 같다고 이야기 했으니 KNN일때는 어떤지 확인하자.
from sklearn.neighbors import KNeighborsClassifier
for i in range(3,15,2):
knn=KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train_scaled, Y_train)
print("학습: ", knn.score(X_train_scaled, Y_train))
print("일반화: ", knn.score(X_test_scaled, Y_test), "\n")학습: 0.8524305555555556
일반화: 0.6927083333333334
학습: 0.8298611111111112
일반화: 0.6927083333333334
학습: 0.8159722222222222
일반화: 0.671875
학습: 0.8107638888888888
일반화: 0.71875
학습: 0.8090277777777778
일반화: 0.7291666666666666
학습: 0.8038194444444444
일반화: 0.71875 이를 보니 학습은 잘나오나 일반화는 잘 안나오는 Underfitting의 경우가 많다.
따라서 이럴때는 그냥 로지스틱을 사용하는게 낫다.
재현율도 보면,
Y_test_pred=knn.predict(X_test_scaled)
print(classification_report(Y_test, Y_test_pred)) precision recall f1-score support
0 0.77 0.80 0.79 123
1 0.62 0.57 0.59 69
accuracy 0.72 192
macro avg 0.69 0.69 0.69 192
weighted avg 0.71 0.72 0.72 192