Classification
Qualitativevariables take values in anunordered set, such as- Given a
featurevector and aqualitativeresponse taking values in the setThe
Classificationtask is to build a function that takes as input thefeaturevector and predicts its value for - Often we are more interested in estimating the
probabilitiesthat belongs to each category in .

Can we use Linear Regression?
-
Suppose for the
Defaultclassification task that we code -
Can we simply perform a
linear regressionof on and classify asYesif ?- In this case of a
binary outcome,linear regressiondoes a good job as aclassifier, and if equivalent tolinear discriminant analysiswhich we discuss later - Since in the population , we might think that
regressionis perfect for this task - However,
linear regressionmight produce probabilitiesless than zeroorbigger than oneLogistic regressionis more appropriate

- In this case of a
-
Now suppose that
-
Linear regressionis not appropriate hereMulticlass Logistic RegressionorDiscriminant Analysisare more appropriate
Logistic Regression
- Let's write for short and consider using to predict .
Logistic regressionuses the form - is a mathematical constant [Euler's number]
- will have values between 0 and 1
- A bit of rearrangement gives :
log oddsorlogit
Maximum Likelihood
- This
likelihoodgives the probability of the observed zeros and ones in the data - We pick and to
maximizethelikelihoodof the observed data
Making Predictions
- What is estimated probability of for someone with a of $1000?
Logistic Regression with several variables
Logistic Regression with more than two classes
Multiclass logistic regressionis also referred to asmultinomial regression
Discriminant Analysis
- Here the approach is to model the distribution of in each of the classes separately, and then use
Bayes theoremto flip things around and obtain - When we use
NormalorGaussiandistributions for each class, this leads tolinearorquadratic discriminant analysis
Bayes theorem for classification
-
Bayes theorem -
One writes this slightly differently for
discriminant analysis:- is the
densityfor in class - is the
marginalorpriorprobability for class

- is the
-
When the
priorsare different, we take them into account as well, and compare . -
On the right, we favor the blue class - the decision boundary has shifted to the left
Why discriminant analysis?
- When the classes are
well-separated, the parameter estimates for thelogistic regression modelare surprisinglyunstable. But,Linear discriminant analysisdoes not suffer from this problem - If is small and the distribution of the predictors is approximately
normalin each of the classes, thelinear discriminant modelis again morestablethan thelogistic regression model Linear discriminant analysisis popular when we have more than two response classes, because it also provideslow-dimensionalviews of the data
Linear Discriminant Analysis when p = 1(Uncorrelated)
- The
Gaussian densityhas the form - Here is the
mean, and thevariance(in class ) - We will assume that all the are the same
- Plugging this into
Bayes formula, we got a rather complex expression for
Discriminant functions
- To classify at the value , we need to see which of the is largest
- Taking logs, and discarding terms that do not depend on , we see that this is equivalent to assigning to the class with the largest
discriminant score: - Note that is a
linearfunction of - If there are classes and , then one can see that the
decision boundaryis at - where is the usual formula for the estimated
variancein the th class
Linear Discriminant Anaysis when p > 1(Correlated)
- (Red :
linearin , other :constant) - Despite its complex form:
Fisher's Discriminant Plot
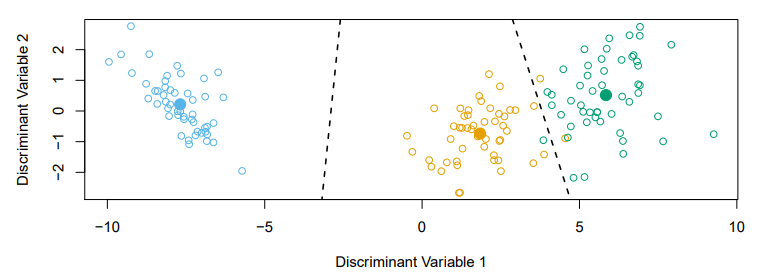
- When there are classes,
linear discriminant analysiscan be viewed exactly in a dimensional plotBecause it essentially classifies to the
closest centroidand they span aK-1dimensional plane - Even when , we can find the
best2-dimensional plance for visualizing the discriminant rule
From delta function to probabilities
- One we have estimates , we can turn these into estimates for class probabilities:
- So classifying to the largest amounts to classifying to the class for which is
largest - When , we classify to class if , else to class 1
Confusion Matrix
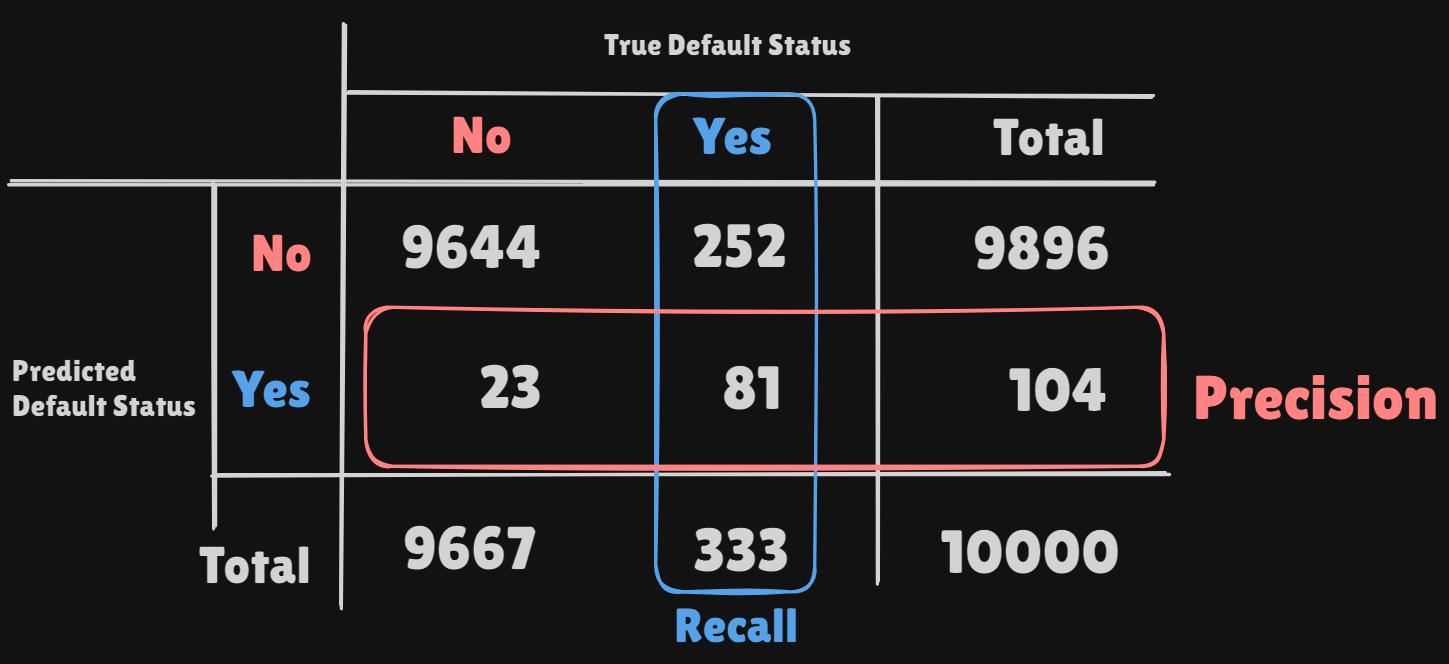
misclassification rate:precision:recall:False positive rate: The fraction ofnegativeexamples that are classified aspositive- in exampleFalse negative rate: The fraction ofpositiveexamples that are classified asnegative- in example- We produced this table by classifying to class if
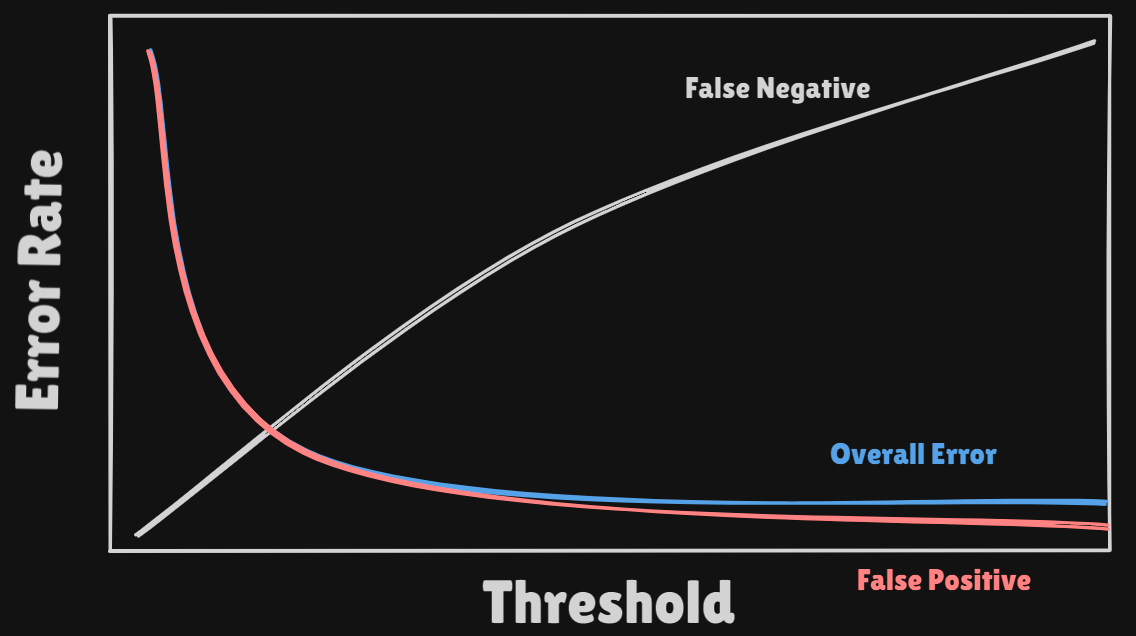
- Lower Threshold : Higher
False Positiveand LowerFalse Negative - Higher Threshold : Lower
False Positiveand HigherFalse Negative
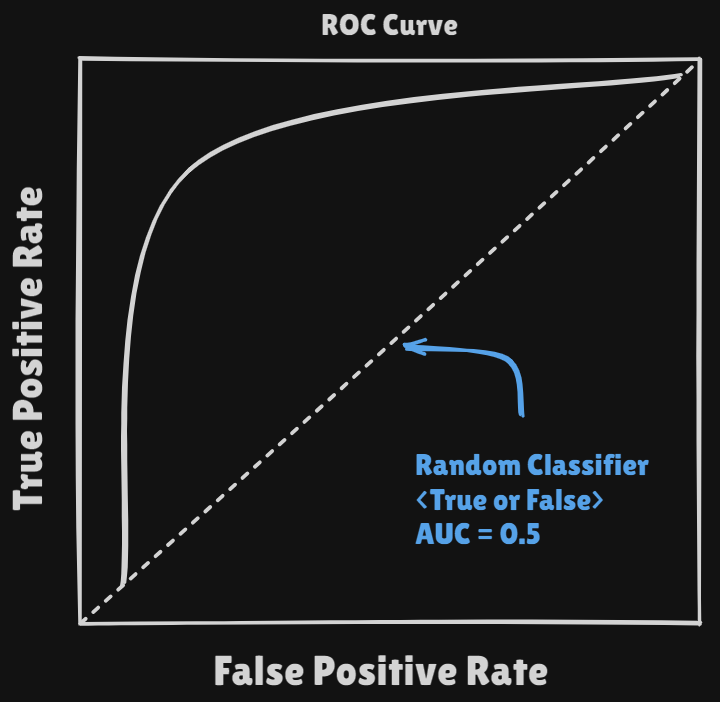
With controlling thethresholdwe can getROC Curve - If the
classifierhas good performance theAUCvalue goes near 1
- Lower Threshold : Higher
Other forms of Discriminant Analysis
- With
Gaussiansbut different in each class, we getquadratic discriminant analysis - With
Gaussiansand same in each class, we getlinear discriminant analysis - With (conditional independence model) in each class we get
naive Bayes. ForGaussianthis means the arediagonal- : Covariance Matrix
- : Covariance Matrix
Naive Bayes
- Assume features are
independentin each class - Useful when is large, and so multivariate methods like
QDAand evenLDAbreak down Gaussian naive Bayesassumes each is diagonal:- For
mixedfeature vectors(qualitative and quantitative)If is
qualitative, replace with probability mass function (histogram) over discrete categories
Logistic Regression versus LDA
- For a two-class problem, one can show that for
LDA - So it has same form as
logistic regression - The difference is in how the parameters are estimated
Logistic Regressionuses theconditional likelihoodbased on (discriminative learning)LDAuses thefull likelihoodbased on (generative learning)
Logistic Regressioncan also fitquadratic boundarieslikeQDA, by explicitly includingquadratic termsin the model
Multinomial Logistic Regression
- The simplest representation uses different linear functions for each class, combined with the
softmaxfunction to form probabilities - There is a rebundancy here; we really only need functions
- We fit by maximizing the
multinomial log likelihood(cross-entropy) - a generalization of the binomial
Generative Models and Naive Bayes
-
Logistic regressionmodels directly, via the logistic function -
Similarly the
multinomial logistic regressionuses thesoftmax function -
These all model the
conditional distributionof given -
By contrast
generative modelsstart with theconditional distributionof given , and then useBayes formulato turn things around: -
is the density of given
-
is the
marginal probabilitythat is in class -
LinearandQuadraticdiscriminant analysis derive fromgenerative models, where areGaussian -
Often useful if some classes are
well seperated- a situation wherelogistic regressionisunstable -
Naive Bayesassumes that the densities in each classFactor
-
Equivalently this assumes that the features are
independentwithin each class -
Then using
Bayes formula: -
: Probability that the value could be found by each distribution
Why independence assumption for naive bayes?
- Difficult to specify and model
high-dimensional densities. Much easier to specifyone-dimensional densities - Can handle
mixedfeatures- If feature is
quantitative, can model asunivariate Gaussian. We estimate and from the data, and then plug intoGaussian density formulafor - Alternatively, can use a
histogramestimate of the density, and directly estimate by the proportion of observations in the bin into which falls - If feature is
qualitative, can simply model the proportion in each category

- If feature is
Naive Bayes and GAMs
- Hence, the
Naive Bayesmodel takes the form of ageneralized additive modelfrom later Chapter
Generalized Linear Models
Generalized linear modelsprovide a unified framework for dealing with many different response types(non-negative responses, skewed distributions, and more)

- In left plot we see that the
variancemostly increases with themean - Taking log() alleviates this, but has its own problems: e.g.
predictionsare on the wrong scale, and some counts are zero
Poisson Regression Model
Poisson Distributionis useful for modeling counts:- - there is a mean/variance dependence
- With covariates, we modelor equivalently
- Model automatically gurantees that the
predictionsarenon-negative
Three GLMs
- We have covered three
GLMs:Gaussian,BinomialandPoisson - They each have a characteristic
linkfunction. This it the transformation of themeanthat is represented by alinear modellinear:logistic:Poisson regression:
- They also each have characteristic
variancefunctions - The modls are fit by
maximum-likelihood
