Linear regression
-
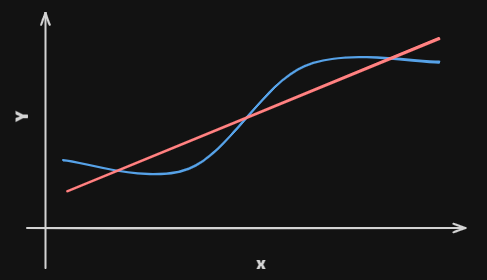
Linear regressionis a simple approach to supervised learning. It assumes that the dependence of
on islinear.True regression functions are never linear!
-
Although it may seem
overly simplistic,linear regressionis extremely useful bothconceptuallyandpractically.
Simple linear regression using a single predictor X
- We assume a model
where and are two
unkown constantsthat represent theinterceptandslope, also known ascoefficientsorparameters, and is theerror term - Where indicates a prediction of on the basis of .
The symbol denotes an estimated value
Estimation of the parameters by least squares
- Let be the prediction for based on the th value of .
Then represents the th
residual - We define the
residual sum of squares(RSS)as
or
- The
least squares approachchooses and to minimize the .The minimizing values can be shown to be
where the are the
sample means
Assessing the Accuracy of the Coefficient Estimates
-
The
standard errorof an estimator reflects how itvariesunder repeated sampling. -
These
standard errorscan be used to computeconfidence intervals -
A 95% confidence interval is defined as a range of values such that with 95% probability, the range will contain the true unknown value of the
parameter. It has the formThere is approximately a
95%chance that the intervalIt will contain the
true valueof -
For example, for the advertising data, the
95% confidence intervalfor is
Hypothesis testing
-
The most common
hypothesis testinginvolves testing thenull hypothesisofThere is no relationship between and versus the alternative hypothesisThere is some relationship between and -
Mathematically, this corresponds to testing
versus -
Since if then the model reduces to , and is not associated with
-
To test the
null hypothesis, we compute at-statistic, given by -
This will have a
t-distributionwithn-2degrees of freedom, assuming . -
p-value: probability of observing any value equal to or largerCoefficient Std. Error t-statistic p-value 7.0325 0.4578 15.36 <0.0001 0.0475 0.0027 17.67 <0.0001
Assessing the Overall Accuracy of the Model
-
We compute the
Residual Standard Errorwhere the
residual sum-of-squaresisRSS -
or fraction of variance explained is
where the
total sum of squares(TSS) -
It can be shown that in this simple
linear regressionsetting that , where is thecorrelationbetween and :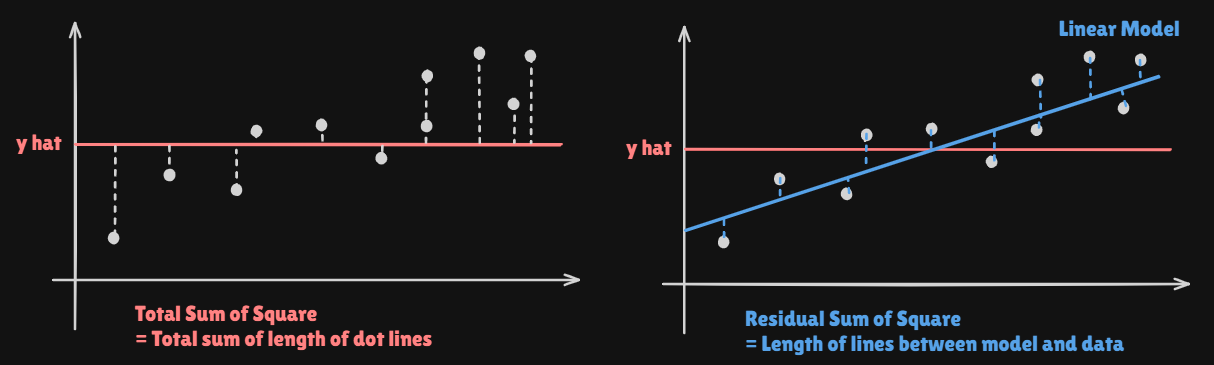
Multi Linear Regression
-
Here our model is
-
We interpret as the
averageeffect on of a one unit increase in , holding all other predictors fixed
Interpreting regression coefficients
- The ideal scenario is when the
predictorsareuncorrelated: a balanced design- Each
coefficientcan be estimated and tested separately
- Each
Correlationsamongstpredictorscause problems :- The
varianceof allcoefficientstends to increase, sometimes dramatically - Interpretations become
hazardous- when changes, everything else changes
- The
Claims of causalityshould be avoided for observational data
Estimation and Prediction for Multiple Regression
- Given estimates we can make
predictionsusing the formula - We estimate as the values that minimize the
sum of squared residuals
Some important questions
- Is
at least one of the predictorsuseful in predicting the response - Do all the predictors help to explain , or is only a
subsetof thepredictorsuseful? - How well does the model fit the data?
- Given a set of
predictorvalues, what response value should we predict, andhow accurateis our prediction?
Is at least one predictor useful?
- For the first question, we can use the
F-statistic - It decits how effective each predictor was or at least one effective
- At least on coefficient Effective?
- No Predictor Effective?
Deciding on the important variable
- The most direct approach is called
all subsetsorbest subsetsregression- We compute the
least squaresfit for all possiblesubsetsand then choose between them based on some criterion that balances training error with model size
- We compute the
- But, we can not invest resources for of them. We should find
optimized subsets
Forward Selection
- Begin with the
null model - Fit simple linear regression and
add to the null modelthe variable that result in the lowestRSS - Continue until some stopping
ruleis satisfied
Backward Selection
- Start with all variables in the model
Remove the variableswith thelargest p-value- The new variable model is fit, and the variable with the largest p-value is
removed - Continue until some stopping
ruleis reached
Other Considerations in the Regression Model
Qualitative Predictors
- Some predictors are not
quantitativebut thequalitative, taking adiscrete setof values - These are also called
categoricalpredictors orfactorvariables - We can express these
qualitative predictorslike this
Qualitative predictors with more than two levels
-
With more than two levels, we create additional
dummy variables -
There will always be one fewer dummy variable than the number of levels
-
Baseline: What do you want to set asinterceptis very important
Extensions of the Linear Model
- Removing the additive assumption :
interactionsandnonlinearity
Interactions
- In out previous analysis of the
Advertisingdata, we assumed that the effect onsalesof increasing one advertising medium isindependentof the amount spent on the other media - But suppose that spending money on rdio advertising actually increases the effectiveness of TV advertising
- In marketting, this is known as a
synergy effect, and in statistics it is referred to as aninteraction effect - Then we can deal with this problem by transforming the formula
Hierarchy
- Sometimes it is the case that an
interactionterm has a very smallp-value, but the associatedmain effectsdo not - The
hierarchy principle:- If we include an interaction in a model, we should also include the main effects, even if the p-values associated with their coefficients are not significant
- The rationale for this principle is that
interactionsare hard to interpret in a model withoutmain effects - Specifically, the
interactionterms also containmain effects, if the model has no main effect terms
Interactions between qualitative and quantitative variables
- Without an
interactionterm, the model takes the form - With
interactions, it takes the form
- Same Slope
No interaction - Different Slope
With an interaction
- Same Slope
Non-Linear effects of predictors
- Some
Non-Linearstructure might be more effective
What we did not cover
OutliersNon-constant varianceof error termsHigh leverage pointsCollinearity
Next : Generalization of the Linear Model
Classification problems:logistic regression,support vector machinesNon-linearity:kernal smoothing,splinesand generalizedadditive models: nearest neighbor methodsInteractions:Tree-based methods,bagging,random forestsandboosting- These also capture
non-linearities
- These also capture
Regularized fitting:Ridgeregression andLasso
