
전이학습
- 학습에 필요한 데이터의 양이 충분하지 않아도 사전 훈련된 딥러닝 모델로 데이터의 일부만 재학습 시켜 원하는 목적에 필요한 모델을 만들어내는 기술
- Data Augmentation과 같이 데이터의 양이 많지 않을 때 효과적으로 사용
캐글 PetImage 데이터셋을 활용하여 실습 진행
캐글 데이터 colab에 불러오기
!pip install kaggle-
Kaggle Account에 들어가서 Create New API Token을 통하여 Token 생성하기
- https://www.kaggle.com//account
- 필자는 'kaggle.json'으로 파일 저장함
from google.colab import files
uploaded = files.upload() - 다운로드한 Token 업로드 하기
!chmod 600 /content/kaggle.json -
해당 파일의 소유자에 대하여 읽기 쓰기 권환을 부여하는 코드!!
-
이후 kaggle에서 각자 필요로 하는 데이터셋을 찾고 API를 복사해와 서 사용하면 된다.
-
필자는 PetImage 데이터셋을 필요로 하기에 다음과 같이 진행하였다.
Cats-vs_Dogs
-
!kaggle datasets download -d shaunthesheep/microsoft-catsvsdogs-datasetPetImage 데이터셋을 활용환 전이학습
1. 데이터 전처리
import os
import zipfile
zip_file_name = "microsoft-catsvsdogs-dataset.zip"
zip_file_path = f"/content/{zip_file_name}"
dataset_download_path = "/content/dataset"
# 다운로드한 압축 파일을 사용하여 데이터셋을 압축 해제
with zipfile.ZipFile(zip_file_path, "r") as zip_ref:
zip_ref.extractall(dataset_download_path)
# 압축 파일 삭제
os.remove(zip_file_path)
!ls $dataset_download_path
- zipfile로 이루어져 있어서 파일 압축 해제 후 내부 파일 확인
- PetImage 파일만 활용 예정
data_dir = "/content/dataset/PetImages"
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers, models
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import tensorflow as tf
path1 = '/content/dataset/PetImages/Cat/666.jpg'
path2 = '/content/dataset/PetImages/Dog/11702.jpg'
os.remove(path1)
os.remove(path2)
datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
train_generator = datagen.flow_from_directory(
data_dir,
target_size=(64, 64),
batch_size=32,
class_mode='binary',
subset='training'
)
validation_generator = datagen.flow_from_directory(
data_dir,
target_size=(64, 64),
batch_size=32,
class_mode='binary',
subset='validation'
)- ImgaeDataGenerator를 활용하여 Train, val data 생성
- 2개의 손상된 이미지 제거
2-1 CNN 모델링
- 전이학습 전 이전 시간에 진행했던 CNN으로 진행
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
# model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_generator, epochs=10, validation_data=validation_generator)
# 테스트 데이터로 모델 평가
test_loss, test_acc = model.evaluate(validation_generator)
print(f'Test accuracy: {test_acc}')
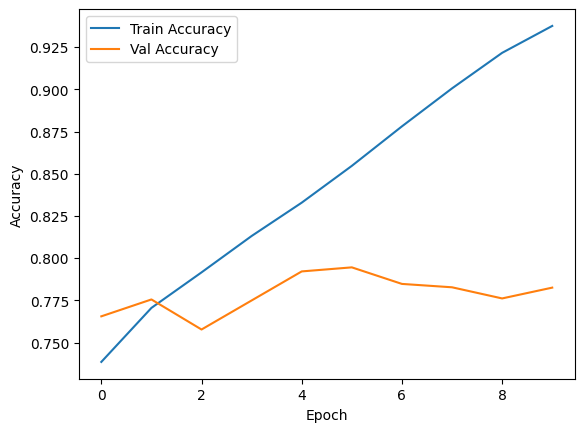 * Train/val의 정확도 차이가 큰걸 보아 과적합이 이루어 졌음 확인
* Train/val의 정확도 차이가 큰걸 보아 과적합이 이루어 졌음 확인
2-2 VGG16 모델링
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(64, 64, 3))
model = Sequential()
model.add(base_model)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(train_generator, epochs=10, validation_data=validation_generator)
test_loss, test_acc = model.evaluate(validation_generator)
print(f'Test accuracy: {test_acc}')
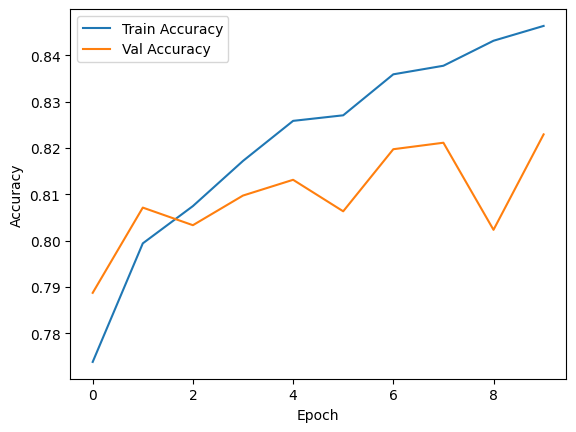 Train/val 정확도 차이가 줄어들고 val의 정확도 증가
Train/val 정확도 차이가 줄어들고 val의 정확도 증가
2-3 VGG16 모델링
-
2-2에서 optimizer='SGD'로 변경 후 진행
-
학습 속도가 느렸던 부분을 해결하기 위해 SGD로 진행
결과
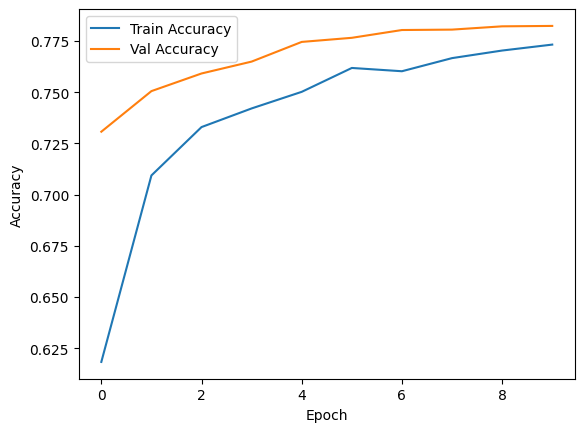
-
학습 속도는 생각했던 것처럼 눈에 띄게 향상되지 않았고 Val정확도에 큰 차이를 보이지 않는다.
-
Train / val 의 정확도 차이가 유의미하게 줄어는 것을 확인 할 수 있다.
작업 속도가 오래 걸려 많은 Epoch를 돌려보지 못하여 다음엔 추가로 돌려볼 예정이다.
