Background
Contrastive Learning이란?
1. No decoder
2. Contrastive loss(InfoNCE loss)
3. Positive와 Negative sample를 비교하면서 학습을 진행.
4. Augmentation 활용
Method
- X라는 데이터셋을 각각 2번 augmentation 시켜서 xi, xj를 얻는다.
- 각각 xi와 xj에 f(x)를 적용한다.
- f(x)는 보통 ResNet-50이다.
- 그 다음 Projection head라고 불리는 g(x)를 적용한다.
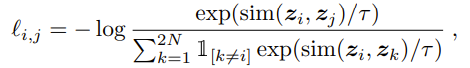
- Projection head에서 나온 embedding을 값을 InfoNCE(Contrastive loss)를 이용해서 서로의 유사도를 계산해서 loss function을 계산한다.
- 분자 부분은 positive pair의 서로의 유사도, 분모는 전체 데이터셋 (positive sample + negative sample)에 대한 유사도의 총합을 이용해서 Probability를 계산함.
- 실제 코드에서는 Cross_Entropy loss를 사용함 (Cross_Entropy의 x에 similarity 대입한 것과 같음)
Experiments
단일 augmentation을 이용했을 때 성능이 가장 좋지 않았다.
Color + Crop 조합을 이용했을 때 가장 성능이 좋다는 것을 확인할 수 있다.
Color distortion을 사용해야, deep learning의 shortcut학습을 방지할 수 있음을 증명했다.
Training Epoch와 Batch Size가 클수록 성능이 좋다는 것을 확인하였다.
- Computational cost에 대한 한계 존재, negative sample에 대한 의존 성이 높음
Reference
- [SimCLR paper]([2002.05709] A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org))
- [SimCLR github](GitHub - sthalles/SimCLR: PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations)

개인 공부 기록용