MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
PCB-Anomaly-Detection
Abstract
저자들은 Momentum Constrast for Unsupervised Visual Representaion Learning(MoCo)를 제안하였다.
Queue와 moving-averaged encoder를 사용해서 거대하고 일관성있는dictionary를 만들수 있게 한다. 이 덕분에 encoder가 좋은 representation을 학습할 수 있다. dictionary는 encoder를 통과하여 얻은 representation의 모음이라고 생각하면 된다.
Introduction
Method
3.1. Contrastive Learning as Dictionary Look-up
저자는 MoCo가 사용하는 Contrastive Loss를 사전을 찾아보는 것으로 비유한다. mini-batch들이 합쳐져 만들어진 dictionary에서 query와 같은 쌍인 Positive key를 가장 유사도가 높게하는 것이 목적이기 때문임
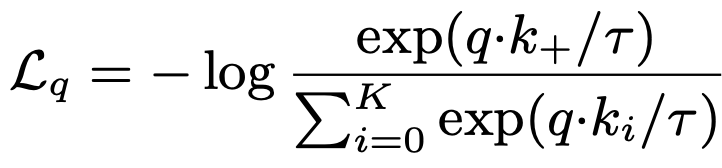
q : query (image representation)
k : key (key encoder에서 뽑아낸 representation)
k+ : q와 같은 쌍의 이미지
분모: Positive pair의 유사도를 높여야 함.
분자: negative pair들과는 낮게 만들어야 한다.
k+1개의 후보지를 가지고 sofrmax를 하는것과도 크게 다르지 않다.
그리고 query encoder와 key encoder는 아예 같은 구조를 사용하기도 하고, 구조의 일부만 공유하기도 하고, 아예 다르기도 하다고 합니다. 물론 여기서는 query encoder의 weight를 key encoder에 흘려줘야하니 같은 구조를 사용할 것 입니다.
3.2. Momentum Contrast
-
Dictionary as a queue
MoCo에서는 Key encoder를 업데이트 하면서 dictionary의 일관성을 유지 함. 여러개의 mini-batch를 누적해서 dictionary를 만든다. 그런데 queue가 다 찼다는 가정 하에 가장 오래된 mini-batch를 dequeue하고 새로운 mini-batch를 enqueue한다. dictionary size를 무한정으로 키울 수 없어서 이런 방식을 사용한다. 그리고 key encoder가 바뀌면서 쌓인지 오래된 mini-batch와는 consistency가 유지되기 힘들기 때문도 있다. -
Momentum update
Key encoder의 weight는 아래와 같은 방식으로 업데이트 한다.
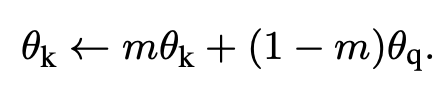
key encoder의 weight와 query encoder의 weight를 m:(1-m) 비율로 섞어서 key encoder의 weight를 업데이트 하는 것이다. m을 0.9 ~ 0.9999정도로 설정함.
- relations to previous mechanism
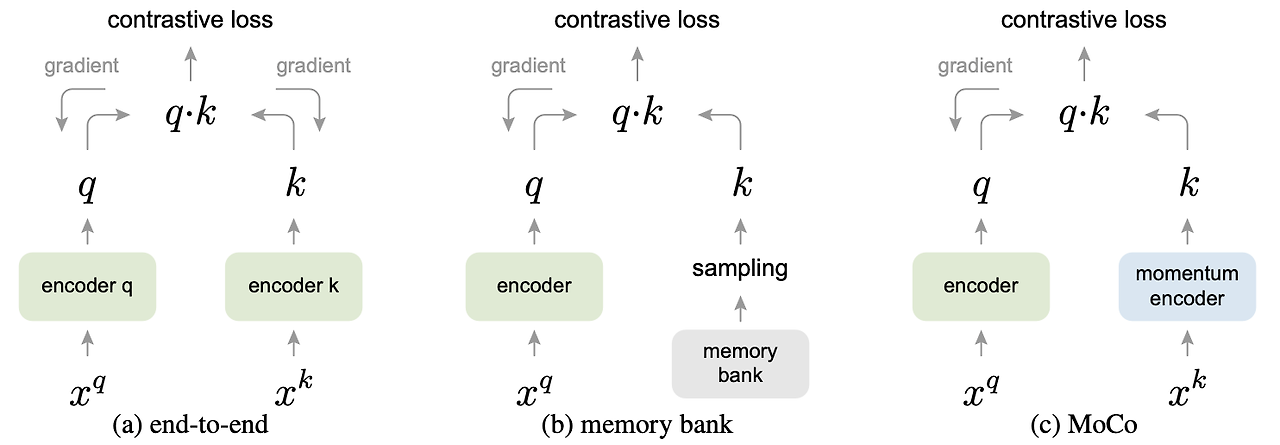
contrastive를 양쪽 encoder에 모두 흘려서 학습 시킨다. encoder k가 지속적으로 크게 바뀌어서 dictionary size를 mini-batch만큼으로 해야만 한다.
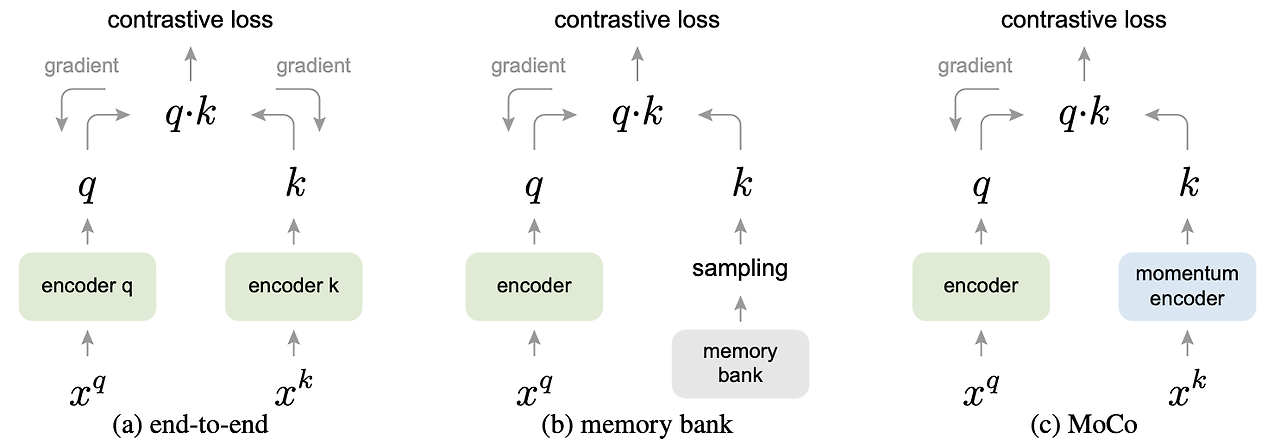
Memory bank의 sample은 epoch를 돌아서 새롭게 forward가 됐을 때 업데이트 된다.
memory bank내부 원소들의 업데이트 주기가 길어져서 representation의 일관성을 유지하기 어려워 진다.
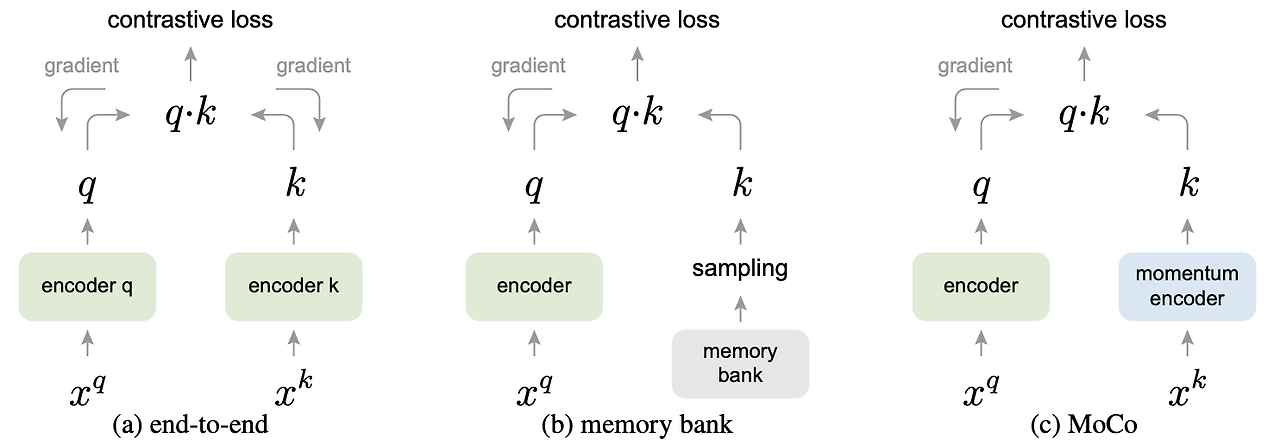
몇 개의 mini-batch를 쌓아두는 momentum encoder사용
Experiments
ImageNet-1M, Instagram-1B를 학습에 사용.
Backbone(encoder): ResNet50 사용
Reference
