Data-efficient and weakly supervised computational pathology on whole-slide images
Paper review
Multiple instance learning을 적용한 CLAM 모델 논문.
CLAM 모델 구조에 대해서 좀더 자세하게 파악하기 위한 논문 리뷰. (나중에 리뷰할 CLAM을 활용한 멀티모달을 이해하기 위해)
(https://www.nature.com/articles/s41551-020-00682-w#Sec9)
CLAM (Cluster-based Learning of Attention Maps)은 WSI에 대한 weakly supervised classification 작업을 해결하기 위해 고안된 모델이다. 모델은 각 WSI를 'Bag'으로 보고, 이 bag 안에 수천에서 수십만 개에 달하는 패치('Instance')들이 포함되어 있다고 간주하는 MIL 프레임워크를 기반으로 한다. MIL에서는 슬라이드 하나가 양성 클래스의 패치를 적어도 하나 이상 포함하고 있다면 그 슬라이드를 양성으로 분류하고, 모든 패치가 음성 클래스에 속한다면 슬라이드를 음성으로 분류하는 가정을 하는데, 이러한 가정은 이는 멀티클래스 분류나 양성/음성 가정을 할 수 없는 이진 분류 문제에는 적합하지 않음.
그렇기 때문에 CLAM은 멀티클래스 분류에 일반적으로 적용 가능하며, 학습 가능하고 해석 가능한 attention-based pooling 함수를 사용하여 각 클래스에 대한 패치 수준 표현에서 슬라이드 수준 표현으로 집계함.
CLAM의 설계에서 주목할 점은 multiclass attention pooling이며, 여기서 attention network는 N개의 클래스 각각에 대응하는 N개의 attention score set를 예측함. 이를 통해 네트워크는 어떤 형태학적 특징이 각 클래스에 대한 positive인지 또는 negative인지를 명확하게 학습할 수 있음.
Overview
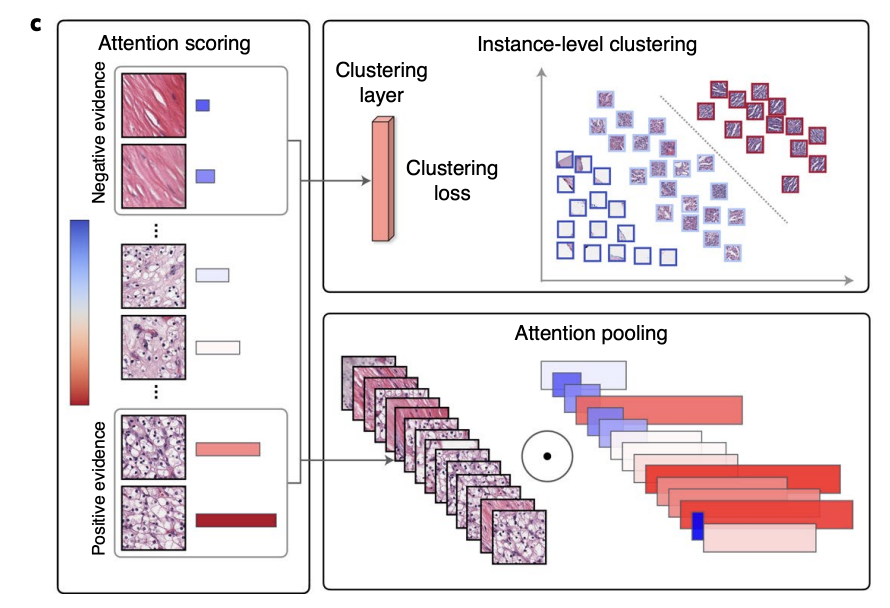
우선은 간략하게 전체적인 flow에 대해서 우선은 살펴보고 넘어가면, CLAM은 attention pooling과 instance-level clustering 기법을 활용하여 학습을 진행하는 모델이다.
- Step 1: 모델의 attention network는 슬라이드 내의 각 패치 순위를 매기고, 상대적 중요도에 기반하여 각 영역에 attention score를 할당함. 이 점수는 해당 영역이 전체 슬라이드 진단에 얼마나 기여하는지를 나타냄.
- Step 2: 이러한 attention score를 사용하여, 각 패치에 가중치를 부여함. 가중치가 부여된 패치들의 특성들을 집약해서, 패치 수준의 특성들을 슬라이드 수준의 표현으로 요약함. 이 과정은 모델이 슬라이드 전체에 걸쳐 중요한 패턴과 정보를 효과적으로 포착할 수 있도록 돕는 것.
- Step 3: 훈련 중, 주어진 ground-truth 라벨을 바탕으로, attention score가 높은 부분과 낮은 부분을 대표 샘플로 사용하여 클러스터링 레이어를 감독함. 이는 모델이 패치 수준의 특성 공간을 학습하도록 하여, 각 클래스의 positive, negative instance 사이에서 구분될 수 있도록 함.
이렇게 attention pooling & instance level clustering을 결합해 모델이 좀더 정확하고 해석 가능한 방식으로 복잡한 패턴 학습할 수 있도록 하는 것.
Attention pooling
그래서 attention pooling이 무엇인지 살펴보면:
-
Instance level embedding: 각 k번째 패치에 대한 instance-level embedding을 zk을 R^1024에서 512차원 벡터 hk=W1zk로 압축한다. W1은 R^512x1024의 첫번째 fully-connected layer가 된다.
-
Attention score: k 번째 패치에 대한 i번째 클래스의 attention score ai,k는 아래의 수식으로 계산.
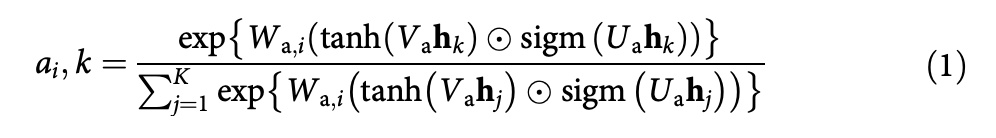
수식에서 Wa,i , Va, Ua는 attention score를 계산하기 위해 사용되는 네트워크의 여러 fully connected layer를 의미.
- Wa,i: 이것은 i번째 클래스에 대한 attention score를 계산할 때 사용되는 fully-connected layer. i는 특정 클래스를 나타내고, 이 layer는 입력된 패치의 특성 hk에 대해서 해당 패치가 i번째 클래스와 얼마나 연관성이 있는지 평가
- Va, Ua: 패치의 특성 hk를 변환하기 위해서 사용되는 두개의 fully-connected layer. 패치의 특성을 변환해서 attention score 계산을 위해서 새로운 표현 공간에 매핑하여 모델이 각 패치의 중요도를 더 잘 이해할 수 있도록 평가할 수 있도록 도와줌. 식에서 사용되는 tanh, 시그모이드 함수를 통해서 특성을 비선형적으로 변환해서 네트워크가 복잡한 관계를 더 잘 포착할 수 있도록 하는 것이다.
-
Slide level representation:
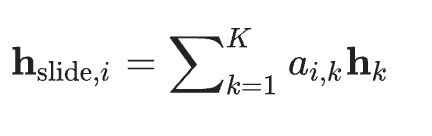
attention score distribution을 사용해서 위와 같이 계산. 즉, 이 과정은 WSI에서 추출된 정보를 요약해서 나타내는 고차원 벡터. CLAM 모델에서 표현은 슬라이드 내의 개별 패치들로부터 중요한 정보를 집계하여 생성됨. 그렇기에 이 과정은 각 패치의 중요도를 평가하고, 이를 바탕으로 전체 슬라이드에 대한 종합적인 특성을 구성하는 것을 목표로 하는 것. -
Slide level score: Classifier layer를 통해서 해당하는 정규화되지 않은 슬라이드 점수에 대해서 계산. WSI에 대한 최종 예측 점수를 나타내는 것으로, 이 점수는 특정 클래스 i에 대한 슬라이드의 소속 확률 또는 관련성을 수치적으로 표현한 것. Classifier layer를 통과함으로 slide-level representation을 이제 예측 점수로 출력.
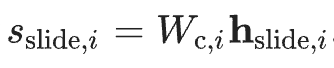
이처럼 CLAM의 multiclass attention pooling 설계가 주목받는 이유는, 이 접근 방식이 네트워크에 각 클래스에 대해 구별 가능한 형태학적 특징을 명확하게 학습할 수 있는 능력을 제공하기 때문.
Instance-level clustering
각 N개의 클래스에 대해, 첫 번째 layer W1 다음에 fully connected layer를 배치하고, 이를 통해 각 패치에 대한 클러스터 할당 점수를 예측. 이 과정은 패치 레벨 라벨이 없는 상황에서 attention network의 output을 사용하여 각 슬라이드에 대한 가상 라벨을 생성하고, 이를 클러스터링을 지도하는 데 사용하는 것.
핵심은:
- 각 클래스 i에 해당하는 클러스터링 레이어의 가중치 W(inst,i)를 사용해 k번째 패치의 클러스터 할당 점수 pi,k를 게산. 이 점수는 해당 패치가 특정 클래스에 속하는 클러스터에 할당되어야 하는지를 결정하는 데 사용
- 패치 레벨의 라벨이 없기 때문에, attention network output을 활용하여 훈련의 각 epochh마다 각 슬라이드에 대한 가상 라벨을 생성. 클러스터링은 슬라이드의 모든 패치가 아니라 attention score가 높은 영역과 낮은 집합에 대해서만 최적화.
- 가장 높은 점수를 받은 B개의 패치는 양성 클러스터 라벨을 받고, 가장 낮은 주의 점수를 받은 B개의 패치는 음성 클러스터 라벨을 받음
- 각 클래스의 강력한 특징 증거가 그의 부정적 증거로부터 선형적으로 분리될 수 있도록 함으로 직관적인 해석을 함.
이러한 instance labeling cluster에 적합한 loss function으로 smooth SVM loss를 사용함.
Training details
-
Training data sampling:
- 슬라이드는 무작위로 샘플링되며, 배치 크기 1로 모델에 제공됨.
- 멀티노미얼 샘플링 확률은 각 슬라이드의 ground-truth 클래스 빈도의 역비례로 설정. 즉, 대표성이 낮은 클래스의 슬라이드가 다른 것보다 더 자주 샘플링되고, 이는 훈련 세트의 클래스 불균형을 완화하는 목적. -
Initialization: attention module의 가중치와 bias parameter는 무작위로 초기화되며, 나머지 모델과 함께 end-to-end로 학습. Total loss는 slide level loss와 instance-level clustering loss의 합으로 계산됨.
모델의 전체적인 구조에 대한 리뷰. 자세한 학습 사항들은 논문을 확인하고, 다음 리뷰는 CLAM을 활용한 멀티모달 논문 리뷰하기
